一种自适应FCM车牌定位方法及系统与流程
本发明涉及图像处理技术领域,特别是涉及一种自适应fcm车牌定位方法及系统。
背景技术:
车牌识别系统主要由车牌定位(lpl)、字符分割(cs)和字符识别(cr)三大部分组成,由于现实生活中车辆的抓拍照片会受到周围环境、光照、拍摄角度的影响,因此车牌定位(lpl)比较困难,正确而可靠的检测出车牌区域是提高系统识别率的关键,是车牌识别的核心技术和研究热点。
图像信息中的颜色特征是进行车牌分割的重要依据,当前基于颜色特征的定位方法有很好的发展前景,采取的方法主要有1)应用神经网络对图像进行颜色分割,然后根据车牌的结构特征来定位;2)采用彩色边缘检测与区域生长相结合的方法来定位车牌;3)基于边缘颜色对检测,利用车牌字符边缘颜色搭配特征定位车牌4)基于fcm颜色聚类的车牌定位方法等。这些研究改善了车牌的定位效果,能很好的解决对比度较小、有类似车牌结构和纹理特征干扰或车牌图像模糊、字符边界不清等情况的车牌定位问题。但是这些算法虽考虑了车牌底色的颜色信息,却没有能够充分利用车牌的颜色特征,基于fcm颜色聚类的算法考虑到了车牌底色和字符颜色的固定搭配,但对初始聚类中心数据点敏感,易陷入局部极小而得不到全局最优解,影响了颜色聚类结果的精度和车牌定位的准确性和鲁棒性。
为解决fcm容易得到局部鞍点的问题,研究者提出了一种全局模糊c-均值聚类算法(gfcm),采用增量聚类的方式,不依赖于任何初始条件,通过确定性的全局搜索过程得到模糊j-划分的最优解。
通过分析gfcm算法的误差成因,该算法对隶属度的计算由模式到模式原型的距离决定,而和模式在特征空间分布特性无关,出现隶属度信息与图像本身的特征分布不符的现象,这在一定程度上降低了聚类精度。
通过分析gfcm算法的收敛速度,该算法执行j×n次fcm算法,计算量过大,而且该算法聚类初始中心的全局搜索仅仅以样本对于模式原型的距离为约束,与图像处理中一般聚类中心聚焦在特征分布曲线的极值点的现象不符,不合适的初始值导致聚类过程很慢,收敛速度不能较好的满足实时性。
技术实现要素:
基于此,本发明的目的是提供一种自适应fcm车牌定位方法及系统,以提高车牌定位的准确性和可靠性。
为实现上述目的,本发明提供了一种自适应fcm车牌定位方法,所述方法包括:
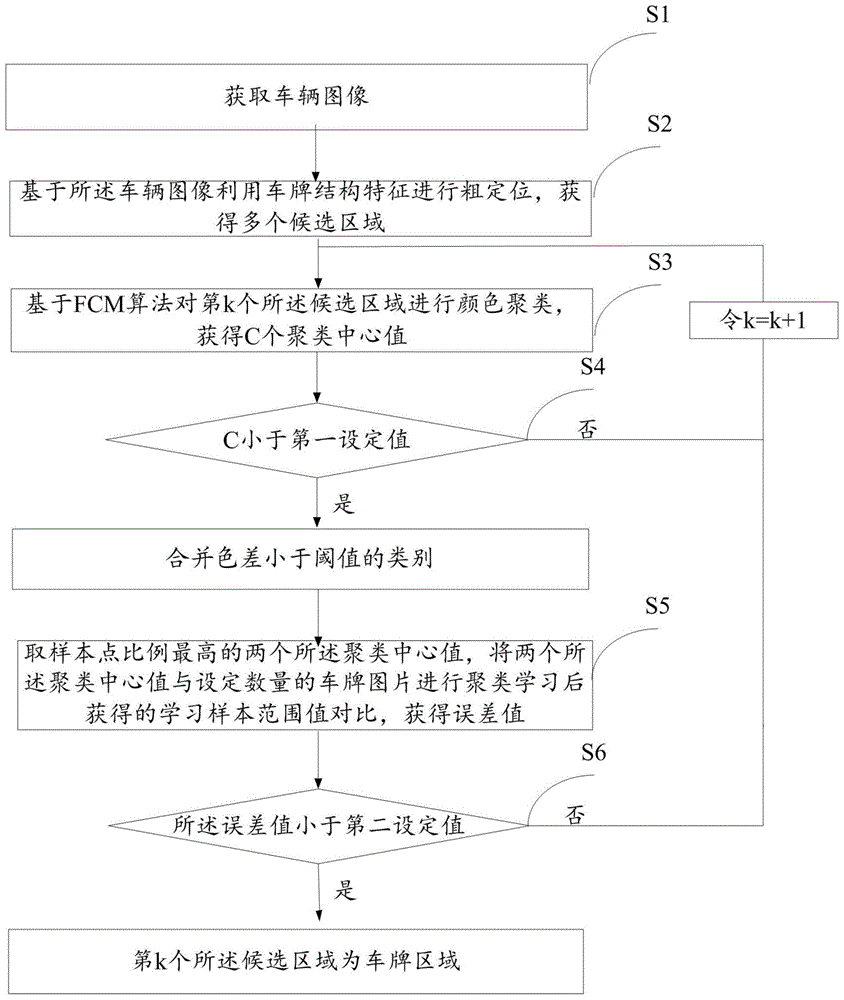
步骤s1:获取车辆图像;
步骤s2:基于所述车辆图像利用车牌结构特征进行粗定位,获得多个候选区域;
步骤s3:基于fcm算法对第k个所述候选区域进行颜色聚类,获得c个聚类中心值;
步骤s4:判断聚类中心值的个数c是否小于第一设定值;如果所述聚类中心值的个数c大于或等于第一设定值,则令k=k+1,返回“步骤s3”;如果所述聚类中心值的个数c小于第一设定值,则合并色差小于阈值的类别;
步骤s5:取样本点比例最高的两个所述聚类中心值,将两个所述聚类中心值与设定数量的车牌图片进行聚类学习后获得的学习样本范围值对比,获得误差值;
步骤s6:判断所述误差值是否小于第二设定值;如果所述误差值小于第二设定值,则第k个所述候选区域为车牌区域;如果所述误差值大于或等于第二设定值,则令k=k+1,返回“步骤s3”。
可选的,所述基于所述车辆图像利用车牌结构特征进行粗定位,获得多个候选区域,具体包括:
步骤s21:对所述车辆图像进行预处理,获得预处理图像;
步骤s22:基于采用形态学中的闭运算确定所述预处理图像中的多个连通域图像;
步骤s23:根据所述连通域图像的填充度和面积确定阈值;
步骤s24:根据所述阈值剔除所述连通域图像中不符合车牌结构的特征区域,获得多个候选区域。
可选的,所述基于fcm算法对第k个所述候选区域进行颜色聚类,获得c个聚类中心值,具体包括:
步骤s31:基于fcm算法构建目标函数;
步骤s32:初始化,令类别j=1,k=1;
步骤s33:采用所述目标函数确定聚类中心向量;
步骤s34:令类别j=j+1,将所述聚类中心向量和样本集带入所述分布势函数,确定聚类初始中心;
步骤s35:将所述聚类初始中心和所述聚类中心向量带入所述目标函数,确定最优聚类中心向量;
步骤s36:确定所述最优聚类中心向量中第j个聚类中心值的灰度比例值;
步骤s37:判断所述灰度比例值是否小于第三设定值;如果所述灰度比例值小于第三设定值,则聚类中心值的总个数c=j;如果所述灰度比例值大于或等于第三设定值,则返回“步骤s34”。
可选的,所述预处理包括:高斯差分二值化处理和中值滤波处理。
可选的,所述车牌结构为标准车牌的前部车辆宽、高比的范围取值为1.3~3.5内任意值。
本发明还提供一种自适应fcm车牌定位系统,所述系统包括:
获取模块,用于获取车辆图像;
候选区域定位模块,用于基于所述车辆图像利用车牌结构特征进行粗定位,获得多个候选区域;
聚类模块,用于基于fcm算法对第k个所述候选区域进行颜色聚类,获得c个聚类中心值;
第一判断模块,用于判断聚类中心值的个数c是否小于第一设定值;如果所述聚类中心值的个数c大于或等于第一设定值,则令k=k+1,返回“聚类模块”;如果所述聚类中心值的个数c小于第一设定值,则合并色差小于阈值的类别;
误差值确定模块,用于取样本点比例最高的两个所述聚类中心值,将两个所述聚类中心值与设定数量的车牌图片进行聚类学习后获得的学习样本范围值对比,获得误差值;
第二判断模块,用于判断所述误差值是否小于第二设定值;如果所述误差值小于第二设定值,则第k个所述候选区域为车牌区域;如果所述误差值大于或等于第二设定值,则令k=k+1,返回“聚类模块”。
可选的,所述候选区域定位模块,具体包括:
预处理单元,用于对所述车辆图像进行预处理,获得预处理图像;
连通域图像确定单元,用于基于采用形态学中的闭运算确定所述预处理图像中的多个连通域图像;
阈值确定单元,用于根据所述连通域图像的填充度和面积确定阈值;
候选区域确定单元,用于根据所述阈值剔除所述连通域图像中不符合车牌结构的特征区域,获得多个候选区域。
可选的,所述聚类模块,具体包括:
目标函数构建单元,用于基于fcm算法构建目标函数;
初始化单元,用于初始化,令类别j=1,k=1;
聚类中心向量确定单元,用于采用所述目标函数确定聚类中心向量;
聚类初始中心确定单元,用于令类别j=j+1,将所述聚类中心向量和样本集带入所述分布势函数,确定聚类初始中心;
最优聚类中心向量确定单元,用于将所述聚类初始中心和所述聚类中心向量带入所述目标函数,确定最优聚类中心向量;
灰度比例值确定单元,用于确定所述最优聚类中心向量中第j个聚类中心值的灰度比例值;
判断单元,用于判断所述灰度比例值是否小于第三设定值;如果所述灰度比例值小于第三设定值,则聚类中心值的总个数c=j;如果所述灰度比例值大于或等于第三设定值,则返回“聚类初始中心确定单元”。
可选的,所述预处理包括:高斯差分二值化处理和中值滤波处理。
可选的,所述车牌结构为标准车牌的前部车辆宽、高比的范围取值为1.3~3.5内任意值。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明提供了一种自适应fcm车牌定位方法及系统,所述方法包括:基于所述车辆图像利用车牌结构特征进行粗定位,获得多个候选区域;基于fcm算法对第k个所述候选区域进行颜色聚类,获得c个聚类中心值;判断最优聚类中心向量中各个所述聚类中心值是否小于第一设定值;如果所述聚类中心值大于或等于第一设定值,则令k=k+1,返回重新确定聚类中心值;如果所述聚类中心值小于第一设定值,则合并色差小于第一设定值的类别;取样本点比例最高的两个所述聚类中心值,将两个所述聚类中心值与学习样本范围值对比,获得误差值;基于所述误差值确定车牌区域;上述方法不仅提高了收敛速度,还提高了车牌定位的准确性和可靠性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例自适应fcm车牌定位方法流程图;
图2为本发明实施例自适应fcm车牌定位系统结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种自适应fcm车牌定位方法及系统,以提高车牌定位的准确性和可靠性。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明实施例自适应fcm车牌定位方法流程图,如图1所示,本发明提供一种自适应fcm车牌定位方法,所述方法包括:
步骤s1:获取车辆图像。
步骤s2:基于所述车辆图像利用车牌结构特征进行粗定位,获得多个候选区域。
步骤s3:基于fcm算法对第k个所述候选区域进行颜色聚类,获得c个聚类中心值。
步骤s4:判断聚类中心值的个数c是否小于第一设定值;如果所述聚类中心值的个数c大于或等于第一设定值,则令k=k+1,返回“步骤s3”;如果所述聚类中心值的个数c小于第一设定值,则合并色差小于阈值的类别。
步骤s5:取样本点比例最高的两个所述聚类中心值,将两个所述聚类中心值与设定数量的车牌图片进行聚类学习后获得的学习样本范围值对比,获得误差值。
步骤s6:判断所述误差值是否小于第二设定值;如果所述误差值小于第二设定值,则第k个所述候选区域为车牌区域;如果所述误差值大于或等于第二设定值,则令k=k+1,返回“步骤s3”。
下面对各个步骤进行详细论述:
对某个候选区,设样本集
步骤s2:基于所述车辆图像利用车牌结构特征进行粗定位,筛选出与车牌区域结构特征相似的所有候选区域(包含车牌区域),获得多个候选区域,具体包括:
步骤s21:对所述车辆图像进行预处理,获得预处理图像。所述预处理包括:高斯差分二值化处理和中值滤波处理。
步骤s22:基于采用形态学中的闭运算确定所述预处理图像中的多个连通域图像。
步骤s23:根据所述连通域图像的填充度和面积确定阈值。
步骤s24:根据所述阈值剔除所述连通域图像中不符合车牌结构的特征区域,获得包括车牌区域在内的多个候选区域;所述车牌结构为标准车牌的前部车辆宽、高比的范围取值为1.3~3.5(考虑到倾斜等原因)内任意值。
步骤s3:基于fcm算法对第k个所述候选区域进行颜色聚类,获得c个聚类中心值,k为大于等于1且小于等于k的正整数,k为候选区域的总个数。
原始fcm算法以最小类内平方误差和为聚类准则,计算每个样本属于各模糊子集(聚类)的隶属度。该算法提供的隶属度信息通常会出现与图像本身的特征分布不符的现象,这在一定程度上降低了图像处理的精度。
为此结合模式对模式原型的类别相似度特征,将特征分布概率特性作为隶属函数的高度调整因子,对样本xi,在特征分布上的模式类别相似性大,其隶属特性具有增强作用,而对模式类别相似性小的样本值,其隶属特性具有抑制作用,对断点、离散点和小概率的样本值,则因发生概率太小,隶属特性会被严重抑制,突出了车牌的底色和字符区域,去除了不正常像素点对隶属度的干扰,更符合车牌图像处理的先验知识。
对图像处理中的模糊聚类问题,x表示像素的特征值,0<v1<v2<…<vj≤n表示聚类过程中j个模式原型,gij表示样本xi在特征分布上同各聚类中心值vj的差异,则类别相似度pij定义为:
由于数字图像的离散特征空间特性,gij可以理解为在分布曲线上各模式到模式原型所经历的梯度变化之和,其计算公式如下:
传统的fcm算法没有考虑各模式类别在分布上的差异,把它们的概率分布看作是相同的,直接在直方图上分析,dij是在横轴上对聚类相似性的一种度量,pij是从模式本身的角度在纵轴上对相似性的一种度量,因此结合两种特征属性对聚类性能的影响因素,因此步骤s31:基于fcm算法构建目标函数,具体公式为:
其中,μij表示第i个样本对第j个类别的隶属度;pij表示第i个样本对第j个类别的类别相似度;dij=||xi-vj||表示第i个样本xi与第j个聚类中心值vj的距离,||·||为rs中由内积诱导出的范数,m为一个加权指数,n表示第k个候选区的样本总个数,c表示第k个候选区颜色划分的最佳类数。
i=1,…,n;j=1,…,c
步骤s32:初始化,令类别j=1,k=1。
步骤s33:采用所述目标函数确定聚类中心向量。
模糊fcm聚类方法是基于目标函数的非线性迭代优化方法,聚类结果的好坏及聚类的收敛速度对初始值的选择比较敏感,不合适的初始值可能导致结果收敛到一个不合适的极小点或者导致聚类过程很慢。
车牌的颜色特征是车牌背景和字符颜色对比强烈,具有固定颜色搭配,且各颜色像素所占比例有一定的范围。车牌区域类数较少,像元在特征空间中聚集在少数几个子区域中,一般认为每个聚类中心值所在的地方一个是直方图的局部峰值点。
当车牌图像质量严重褪色,底色不均匀,或部分颜色信息丢失的时候,自适应全局搜索各聚类初始化中心的聚类原则如果只考虑样本到聚类中心的距离这一外在特征,会严重影响聚类初始中心的正确选取,很多不正常的像素点因为距离差异大而被识别为合适的聚类初始中心,造成很大的误差。因此当1-划分聚类中心v1已知的情况下,再全局搜索j-划分聚类初始中心的时候,搜索准则不仅表现在与v1的距离测度上,还应表现在特征分布的特征值测度上。
全局搜索聚类初始中心的方式,对于所有聚类初始中心,不是随机选择初始值,而是以增量的方式搜索,试图在每个阶段计算所有样本点xi(i=1,2,...,n)的分布势函数值来优化一个新的聚类初始中心,具体步骤如下:
步骤s34:令类别j=j+1,将所述聚类中心向量和样本集带入所述分布势函数,确定聚类初始中心;所述分布势函数的具体公式为:
其中,样本集x={x1,x2,...xn},h(xi)表示直方图第i个样本发生的频率,v={v1,v2,...,vj-i}表示聚类中心向量,vc∈v,||·||为rs中由内积诱导出的范数,m为一个加权指数,n表示第k个候选区的样本总个数。
步骤s35:将所述聚类初始中心和所述聚类中心向量带入所述目标函数,确定最优聚类中心向量vj={v1,v2,...,vj}。
在处理候选区域之前每个不同的候选区颜色被划分成多少类别才是最佳的,这个数据很难在划分之前就确定,那么这种情况就需要算法在多次聚类的过程中自动的确定最佳分类数c,然后进行图像划分,实现自适应性。具体做法如下:
选取合适的阈值ε,当j-划分的第j个聚类初始中心值vj的δj值小于阈值ε,则停止分类,令c=j,自适应确定最佳分类数c值。
具体步骤如下:
步骤s36:确定所述最优聚类中心向量中第j个聚类中心值的灰度比例值,具体公式为:
δj=h(vj)/max(h(g),g∈{0,1,2,...,g-1})(6)
其中,δj为所述最优聚类中心向量中第j个聚类中心值的灰度比例值,g为某候选区的灰度级,max(h(g)为该候选区域的直方图最大峰值,h(vj)为第j个聚类中心所代表的样本点在直方图中发生的频率,g为该峰值对应的样本点灰度。
步骤s37:判断所述灰度比例值是否小于第三设定值ε;如果所述灰度比例值小于第三设定值ε,则聚类中心值的总个数c=j;如果所述灰度比例值大于或等于第三设定值ε,则返回“步骤s34”。
由于车牌区域的颜色种类较少,最大分类不超过c=6,自适应确定最佳分类数c值后,比较所有候选区的c值,可以快速剔除c>6的候选区域为伪车牌区域,减少了候选区域的个数,降低计算复杂度,因此将第一设定值设置为6,因此步骤s4具体如下:
步骤s4:判断聚类中心值的个数c是否小于6;如果所述聚类中心值的个数c大于6,则令k=k+1,返回“步骤s3”;如果所述聚类中心值的个数c小于或等于6,则合并色差小于阈值的类别。
本发明公开的自适应fcm车牌定位方法(rafcm-csc,fastincrementalfcmbasedonclassificationsimilaritycharacteristics)融合车牌结构和车牌颜色等多种图像特征对车牌进行定位,rafcm-csc基于颜色聚类算法和自适应全局搜索确定最佳分类数和聚类初始中心,兼顾样本到聚类中心的距离和样本到聚类中心的特征分布相似性因素,得到颜色聚类最优解,最后基于颜色聚类最优解确定车牌区域。本发明将(模糊c均值聚类算法fuzzyc-means,简称fcm)的执行次数从j×n降低到j,明显提高了收敛速度,基于类别相似度的聚类原则,提高了模糊聚类的鲁棒性。另外,本发明公开的方法还能有效解决车牌底色与车牌周围颜色相近及车牌图像质量严重退化、部分颜色信息丢失或车牌底色不均情况下的车牌定位问题,提高了车牌定位的准确性和可靠性。
图2为本发明实施例自适应fcm车牌定位系统结构图,如图2所示,本发明还提供一种自适应fcm车牌定位系统,所述系统包括:
获取模块1,用于获取车辆图像。
候选区域定位模块2,用于基于所述车辆图像利用车牌结构特征进行粗定位,获得多个候选区域。
聚类模块3,用于基于fcm算法对第k个所述候选区域进行颜色聚类,获得c个聚类中心值。
第一判断模块4,用于判断聚类中心值的个数c是否小于第一设定值;如果所述聚类中心值的个数c大于或等于第一设定值,则令k=k+1,返回“聚类模块”;如果所述聚类中心值的个数c小于第一设定值,则合并色差小于阈值的类别。
误差值确定模块5,用于取样本点比例最高的两个所述聚类中心值,将两个所述聚类中心值与设定数量的车牌图片进行聚类学习后获得的学习样本范围值对比,获得误差值。
第二判断模块6,用于判断所述误差值是否小于第二设定值;如果所述误差值小于第二设定值,则第k个所述候选区域为车牌区域;如果所述误差值大于或等于第二设定值,则令k=k+1,返回“聚类模块”。
作为一种实施方式,本发明所述候选区域定位模块2,具体包括:
预处理单元,用于对所述车辆图像进行预处理,获得预处理图像。
连通域图像确定单元,用于基于采用形态学中的闭运算确定所述预处理图像中的多个连通域图像。
阈值确定单元,用于根据所述连通域图像的填充度和面积确定阈值。
候选区域确定单元,用于根据所述阈值剔除所述连通域图像中不符合车牌结构的特征区域,获得多个候选区域。
作为一种实施方式,本发明所述聚类模块3,具体包括:
目标函数构建单元,用于基于fcm算法构建目标函数;
初始化单元,用于初始化,令类别j=1,k=1。
聚类中心向量确定单元,用于采用所述目标函数确定聚类中心向量;
聚类初始中心确定单元,用于令类别j=j+1,将所述聚类中心向量和样本集带入所述分布势函数,确定聚类初始中心。
最优聚类中心向量确定单元,用于将所述聚类初始中心和所述聚类中心向量带入所述目标函数,确定最优聚类中心向量;
灰度比例值确定单元,用于确定所述最优聚类中心向量中第j个聚类中心值的灰度比例值。
判断单元,用于判断所述灰度比例值是否小于第三设定值;如果所述灰度比例值小于第三设定值,则聚类中心值的总个数c=j;如果所述灰度比例值大于或等于第三设定值,则返回“聚类初始中心确定单元”。
作为一种实施方式,本发明所述预处理包括:高斯差分二值化处理和中值滤波处理。
作为一种实施方式,本发明所述车牌结构为标准车牌的前部车辆宽、高比的范围取值为1.3~3.5内任意值。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!