一种利用风场数据集获取不同地方时风场分布的方法与流程
本发明涉及全球气候研究领域,具体涉及一种利用风场数据集获取不同地方时风场分布的方法。
背景技术:
风作为描述大气运动的基本要素,是研究大气动力学和气候学的重要参量。对于风场的研究,广泛应用在土壤风蚀评估、沙尘暴预测、生态环境改善、大气污染评价、风能资源评估等领域,一直以来都是学者们的研究热点。而研究风的日变化,尤其是其地方时变化,对于研究物质循环、区域气候、气象预报等有重要意义。
目前测风的手段多种多样,常见的如测风塔、散射计、辐射计、合成孔径雷达等等。但是这些手段各自都有其缺点:测风塔站点分布不均,部分地区出现数据空白;散射计和辐射计反演结果分辨率不足,有些无法实现全球覆盖;sar反演方法复杂。为了解决这些问题,逐渐出现了再分析风场数据,如ncep、ccmp、era-interim、cfsr等。然而这些数据集的时间基准都是世界时,无法满足对风场的地方时变化研究。目前对于风的地方时变化研究只局限于局部区域,而对于全球风场的地方时变化的研究则较少。
技术实现要素:
本发明的目的在于克服上述技术缺陷,提出了一种利用风场数据集进行不同地方时风场分布研究的方法,其具有全球化、模块化、兼容各种风场数据集等特点。利用本发明的方法,可以在现有数据集的基础上,以及在不增加任何等本和观测条件的基础上获取到不同等压面全球风场的气候特征,对风场预报和风能资源的调查和评价有重要贡献。
为实现上述目的,本发明的实施例1提供了一种利用风场数据集获取不同地方时风场分布的方法,所述方法包括:
对风场数据集进行收集和汇总,得到以世界时为基准的全球风场数据;
将以世界时为基准的全球风场数据,转换为以指定地方时为基准的全球风场数据;
以任意相邻三天的以世界时为基准的全球风场数据为原始数据集,采用邻近点内插得到其中第二天的一小时间隔的全球降雨数据,由此得到以指定地方时为基准的网格化的一小时间隔的全球风场数据;
根据该地方时的所有天数的全球风场数据,计算该地方时的风场分布。
作为上述方法的一种改进,所述以世界时为基准的全球风场数据包括距离地面10m的每个格网点的东西方向的风速矢量u10分量和南北方向的风速矢量v10分量,其中格网点按照分辨率0.25°×0.25°进行划分。
作为上述方法的一种改进,所述将以世界时为基准的全球风场数据,转换为以指定地方时为基准的全球风场数据;具体为:
lt=(utc-12)+lon/15°
其中,lt代表地方时,utc代表世界时,lon代表格网点所在地理位置的经度。
作为上述方法的一种改进,所述根据该地方时的所有天数的全球风场数据,计算该地方时的风场分布;具体包括:
将指定地方时的第i个格网点的u10分量u10i,j和v10分量v10i,j,合成为风速数据:
其中,j=1,2,3,…,n为时间序列,n为总天数,wij合成后的风速值;
将指定地方时的第i个格网点的风速值按总天数进行平均处理:
其中,
采用矢量法计算第i个格网点的平均风向:
其中,ai为第i个格网点的平均风向,
本发明的实施例2提供了一种利用风场数据集获取不同地方时风场分布的方法,所述方法包括:
对风场数据集进行收集和汇总,得到以世界时为基准的全球风场数据;
对时间分辨率不为1小时的全球风场数据进行时间权重线性插值,从而获得全天每一小时的纬向和经向风分量数据;
将以世界时为基准的全球风场数据,转换为以指定地方时为基准的全球风场数据;
以任意相邻三天的以世界时为基准的全球风场数据为原始数据集,采用邻近点内插得到其中第二天的一小时间隔的全球降雨数据,由此得到以指定地方时为基准的网格化的一小时间隔的全球风场数据;
根据该地方时的所有天数的全球风场数据,计算该地方时的风场分布。
作为上述方法的一种改进,所述以世界时为基准的全球风场数据包括每个格网点的纬向风分量u-wind和经向分风量v-wind,其中格网点按照分辨率2.5°×2.5°进行划分。
作为上述方法的一种改进,所述对时间分辨率不为1小时的全球风场数据进行时间权重线性插值,从而获得全天每一小时的纬向和经向风分量数据;具体为:
对每个格网点的风场数据进行时间权重插值,具体公式如下:
uinterp=pbefore*ubefore+pafter*uafter
vinterp=pbefore*vbefore+pafter*vafter
其中,uinterp和vinterp分别是线性插值后的纬向风分量和经向风分量,pbefore和pafter分别代表所需插值时间点tinterp前一个已知时间tbefore和后一个已知时间tafter的时间权重,ubefore和vbefore分别是时间点tbefore的纬向风分量和经向风分量,uafter和vafter分别是时间点tafter的纬向风分量和经向风分量。
作为上述方法的一种改进,所述根据该地方时的所有天数的全球风场数据,计算该地方时的风场分布;具体包括:
将指定地方时的第i个格网点的u-wind分量ui,j和v-wind分量vi,j,合成为该地方时刻的风速数据:
其中,j=1,2,3,…,n为时间序列,n为总天数,wij为合成后的风速值;
将指定地方时刻的第i个格网点的风速值按总天数进行平均处理:
其中,
采用矢量法计算第i个格网点的平均风向:
其中,ai为第i个格网点的平均风向,
本发明的技术优势在于:
1、本发明的方法具备操作简便易实施、兼容各种风场数据集等优点,能够满足任意地方时刻不同等压面的风场信息提取的需求;
2、本发明的方法具有全球化和区域模块化的优点,可以兼容各种风场数据集;
3、本发明方法采用时间权重插值法,可以对时间分辨率不足1小时的数据集进行分辨率提升,方便对指定任意地方时刻的风场数据的计算;
4、本发明的方法采用最邻近点内插法,简单方便易实施;
5、通过本发明的方法,可以利用现有的各种长期的基于utc时间的风场数据集,在不增加任何成本和观测的条件下,获取到全球风速和风向的地方时变化特征,对风气候研究领域具有重要贡献。
附图说明
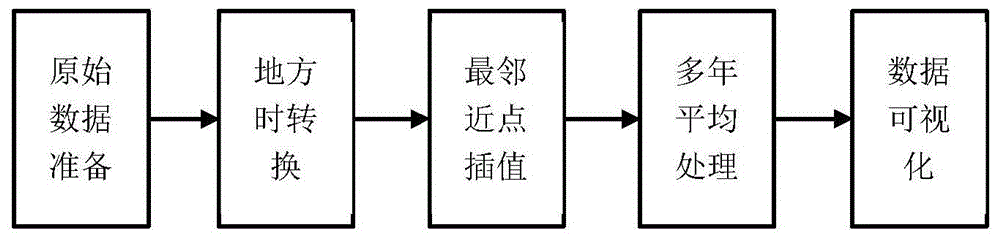
图1为本发明的实施例1的利用风场数据集获取不同地方时全球风场分布的方法的流程图;
图2为本发明采用2013-2018年的era5再分析资料距离地面10m处的风场数据计算出的全球各个地方时年均风速和风向分布图,其中:(a)0000lt、(b)0300lt、(c)0600lt、(d)0900lt、(e)1200lt、(f)1500lt、(g)1800lt、(h)2100lt;
图3为本发明的实施例2的利用风场数据集获取不同地方时全球风场分布的方法的流程图。
具体实施方式
下面结合附图对本发明的技术方案作进一步详细描述。
实施例1
如图1所示,本发明的实施例1提供了一种利用风场数据集获取不同地方时风场分布的方法,其具体实施方式主要由原始数据准备、地方时转换、最邻近点内插、多年平均处理、数据可视化五大步骤组成。在本实施例中由于下载的数据集时间分辨率为1小时,所以不需要进行时间权重插值,故此步骤省去。
本实施例步骤一中,原始数据准备。数据主要采用了2013-2018年以小时估计的era5再分析格网数据,包括距离地面10m的u分量(东西方向)和v分量(南北方向)数据,水平分辨率均为0.25°×0.25°。era5再分析资料是由欧洲中期天气预报中心(ecmwf)所发布的era5第五代全球再分析资料,并通过哥白尼气候变化服务(c3s)近实时并持续开发的,涵盖1950年至今时间段(滞后三个月)的数据,是目前技术上最领先的再分析产品。era5数据的处理是通过使用由ecmwf开发的,周期标记为41r2的集成预报系统(ifs),采用四维变分同化(4d-var)方法来进行的,其全球空间分辨率为31km,垂直分为137模式层,顶层为0.01hpa,每小时分析一次,快速辐射传输模式则为rttov-11,可适用于全天候的各种变量。在变分偏差校正方面,除了采用卫星辐射数据之外,还包括臭氧、飞机和地面气压数据来校正。此外era5数据共包含240种变量,可供人们免费下载和使用。本实施例中使用的主要变量为10mu-componentofwind和10v-componentofwind(分别简称为u10、v10),分别以m/s为单位,文件格式为实验性的netcdf格式。其中u10代表高于地面10米处的东矢量风速,v10代表高于地面10米处的北矢量风速。
本实施例中步骤二,地方时转换。将下载好的2013-2018年的era5再分析数据u10和v10数据的时间基准由世界时转换为地方时,所采用的地方时转换公式如下:
lt=(utc-12)+lon/15°
其中,lt代表地方时,utc代表世界时,lon代表格网点所在地理位置的经度。
本实施例中步骤三,最邻近点插值处理,是指对所需知某地方时刻的风场信息的区域,选取其以世界时为基准时间的前后三天(昨天、当天和明天)共72小时的u10分量和v10分量数据来进行最邻近点内插。首先选择典型地方时分别为0000lt、0300lt、0600lt、0900lt、1200lt、1500lt、1800lt、2100lt,其次运用最邻近点内插法结合地方时转换公式计算每个典型地方时时刻下各个格网点的u10分量和v10分量值。具体执行过程为:由于era5再分析数据水平分辨率为0.25°,所以先以0.25°为间隔,将全球划分为721个经度带;其次为把全球每一个经度带都统一为一个地方时,针对不同的经度带,对当天的某个utc时选取其对应原始数据集前后三天(昨天、当天和明天)来采用邻近点内插寻找其对应地方时刻的u10分量和v10分量数据。
本实施例中步骤四,多年平均处理。首先将步骤三得到的地方时分别为0000lt、0300lt、0600lt、0900lt、1200lt、1500lt、1800lt、2100lt的u10分量和v10分量风速数据合成为各个地方时刻的风速数据,具体所用公式如下:
其中,j=1,2,3,…,n为时间序列,n为总天数,wj为u10j和v10j合成后的风速值。其次将得到的各个地方时刻的每个格网点的风速值按总天数进行平均处理,所用公式如下:
其中,j=1,2,3,…,n为时间序列,n为总天数,
其中,ai为第i个格网点的平均风向,
本实施例中步骤五,数据可视化处理。具体是指对步骤四中得到的八个地方时的平均风速和平均风向数据,利用计算机程序将其可视化,以便于人们直观阅读和分析。
采用本方法可以获取到2013-2018年全球1038240个点的平均风速和平均风向在0000lt、0300lt、0600lt、0900lt、1200lt、1500lt、1800lt、2100lt时的分布结果,如图2所示,其中:(a)0000lt、(b)0300lt、(c)0600lt、(d)0900lt、(e)1200lt、(f)1500lt、(g)1800lt、(h)2100lt,图中为了方便观察将平均风向的结果进行了分单元平均,每个数据单元为20x20个点,将风速颜色栏显示范围调整到0-14m/s。
实施例2
如图3所示,本发明的实施例2提供了一种利用风场数据集获取不同地方时风场分布的方法,其具体实施方式主要包括原始数据准备、时间权重插值、地方时转换、最邻近点内插、多年平均处理、数据可视化六大步骤。
本实施例中步骤一,原始数据准备。数据采集主要采用2013-2018年的ncep-doereanalysis2的20mb等压面的风场数据,其水平分辨率为2.5°×2.5°,空间覆盖范围为90n-90s、0e-357.5e,文件格式为netcdf。ncep-doereanalysis2是ncepreanalysis1的改进版,它修改了一些固有的错误,以及更新了参数化的物理过程,目前数据集的覆盖时间段为1979.01-2020.02。本实施例中所使用数据集的主要变量为u-wind和v-wind,其中u-wind代表风的纬向分量,v-wind代表风的经向分量,每天共有四次观测时刻,分别是00、06、12、18utc。
本实施例中步骤二,时间权重插值。由于下载的ncep-doereanalysis2数据集时间分辨率不足1小时,所以需要进行时间权重插值将数据的时间分辨率提升至一小时。对每个格网点的u-wind和v-wind数据进行时间权重插值,首先设需要进行插值的时间点为tinterp,插值得到的u分量和v分量值设为uinterp和vinterp。则具体的计算公式如下:
uinterp=pbefore*ubefore+pafter*uafter
vinterp=pbefore*vbefore+pafter*vafter
其中,uinterp和vinterp分别是线性插值后的纬向和经向风分量,pbefore和pafter分别代表所需插值时间点tinterp前一个已知时间(tbefore)和后一个已知时间(tafter)的时间权重,ubefore和vbefore分别是时间点tbefore的纬向和经向风分量,uafter和vafter则分别是时间点tafter的纬向和经向风分量。根据上述公式对未被观测的小时时刻的u-wind和v-wind分量值进行线性插值,与原始数据重组成为一组新的时间分辨率为1小时的数据集。
本实施例中步骤三,地方时转换。将第二步获得的新时间分辨率的u-wind和v-wind数据集进行地方时转换,具体转换公式如下:
lt=(utc-12)+lon/15°
其中,lt代表地方时,utc代表世界时,lon代表每个格网点所在地理位置的经度。
本实施例中步骤四,最邻近点插值处理,是指对所需知某地方时刻的风场信息的区域,选取其以世界时为基准时间的前后三天(昨天、当天和明天)共72小时的u-wind分量和v-wind分量数据来进行最邻近点内插。首先指定要计算的地方时,其次运用最邻近点内插法结合地方时转换公式计算指定地方时刻下各个格网点的u-wind分量和v-wind分量值。具体执行过程为:按照ncep-doereanalysis2数据的水平分辨率为2.5°,所以先以2.5°为间隔,将全球划分为73个经度带;其次为把全球每一个经度带都统一为一个地方时,针对不同的经度带,对当天的某个utc时选取其对应原始数据集前后三天(昨天、当天和明天)来采用邻近点内插寻找其指定地方时刻的u-wind分量和v-wind分量值。
本实施例中步骤五,多年平均处理。首先将步骤四得到的指定地方时刻的u-wind分量和v-wind分量风速数据合成为该地方时刻的风速数据,具体所用公式如下:
其中,j=1,2,3,…,n为时间序列,n为总天数,wj为u-wind和v-wind合成后的风速值。其次将得到的各个地方时刻的每个格网点的风速值按总天数进行平均处理,所用公式如下:
其中,j=1,2,3,…,n为时间序列,n为总天数,
其中,ai为第i个格网点的平均风向,
本实施例中步骤六,数据可视化。具体是指对步骤五中得到指定地方时的年平均风速和平均风向数据,利用计算机程序将其可视化。
采用本方法可以获取到20mb等压面处从2013到2018年全球10512个点的年平均风速和平均风向在所指定地方时刻的分布结果。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!