基于深度学习的多学生个体分割及状态自主识别方法与流程
本发明涉及机器学习及机器视觉的技术领域,具体涉及基于深度学习的多学生个体分割及状态自主识别方法。
背景技术:
近年来,智慧课堂的概念已初露头角,它是一种将先进信息采集与传输技术,各种智能传感技术,以及计算机处理技术高效整合到教育领域的新兴理念。而课堂是教育的核心,学生的听课状态是课堂效率最直接有效的体现,现有的课堂教学反馈还停留在主观的人工分析阶段,耗费精力,效率低,且不能全面地监测每位学生的状态。目标分割是视觉分析的基础,利用卷积神经网络实现对图像中每个像素精细标注,从而确定图像中各物体的位置与类别信息,目前已应用于自动驾驶、图像检索、医学检测等领域,随着技术的发展,目标分割在未来的智慧课堂中也将占有一席之地。随着人工智能的发展,实现学生听课状态自主识别与评估反馈已成为智慧课堂的趋势所在。
目前提出的学生听课状态识别方法较少,有基于人体特征点识别、基于压力传感器数据采集等方法,这些方法仍存在一些不可避免的缺陷,主观性较强,准确率较低,成本较高。本发明为实现学生听课状态自主识别及听课效率的判别提供解决方法,具有速度快、识别率高、环境适应能力强的优点。
技术实现要素:
本发明的目的是提供一种运算速度快、识别率高、环境适应能力强的基于深度学习的多学生个体分割及状态自主识别方法。
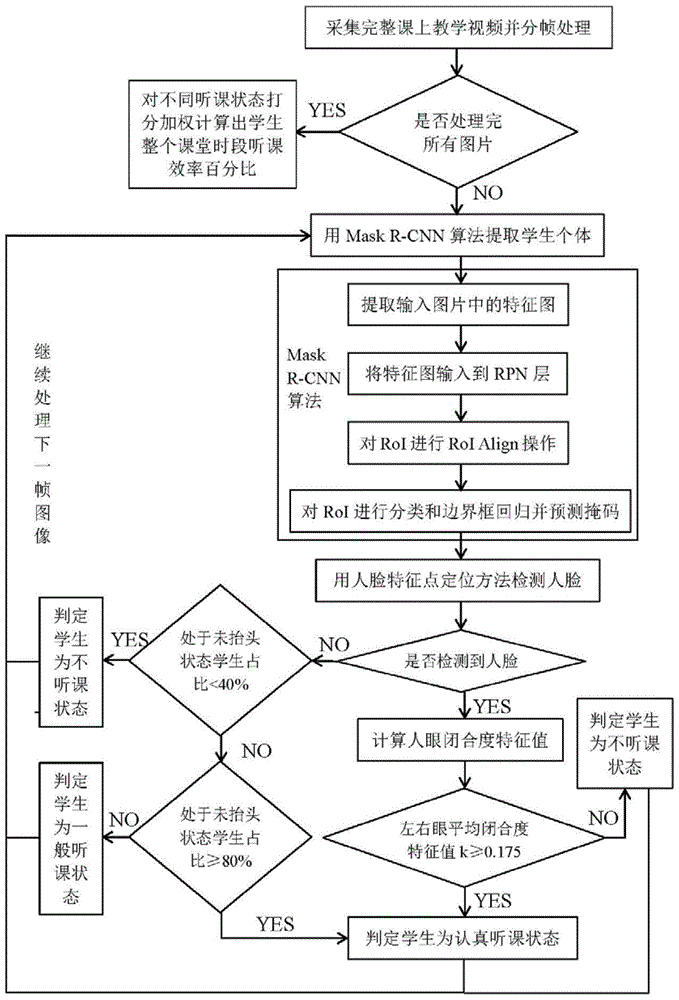
为实现上述目的,本发明采用了如下技术方案:所述的基于深度学习的多学生个体分割及状态自主识别方法,包括以下步骤:
步骤1:采集正常上课视频,对所采集的视频进行分帧处理,得到每10秒一张待处理的图像,将得到的所有图像合帧,得到课堂视频的连续帧图像;
步骤2:利用基于maskr-cnn(maskregion-convolutionalneuralnetwork,掩模区域卷积神经网络)的多学生个体分割方法分割出课堂视频的连续帧图像中的学生个体和非学生个体,并将不同学生个体标记为不同颜色的掩码,得到标记学生掩码的课堂连续帧图像;
步骤3:利用步骤2得到的标记学生掩码的课堂连续帧图像,通过人脸特征点定位方法【经典的adaboost算法,可参考王一轲.人脸检测与人脸特征点定位方法的设计与实现,电子科技大学,硕士学位论文,2015,pp.29-39】找到每个学生个体的人眼特征点,利用人眼特征点计算每个学生个体的人眼闭合度特征值,通过人眼闭合度特征值判断每个学生个体当前是否处于听课状态;
步骤4:利用人脸特征点定位方法判断所有学生个体是否检测到人脸,根据所有学生个体中未检测到人脸的个数占所有学生个体的比例,判断学生个体的听课状态等级;
步骤5:根据上述步骤处理完所有课堂视频的连续帧图像后,结合每个学生个体是否处于听课状态及每个学生个体是否处于未抬头状态,设计整个课堂时段学生听课效率评估方法,通过对不同听课状态打分加权计算出学生整个课堂时段听课效率百分比。
进一步地,所述步骤1包括:
步骤1.1:录制整个课堂时段的全体学生正面视频,将所录制的视频保存至计算机;
步骤1.2:获得整个课堂时段的全体学生正面视频总帧数,得到每十秒的帧数,设置每十秒的帧数取一次帧,将每次取得的帧转化为每10秒一张待处理的图像输出保存至计算机;
步骤1.3:对得到的每10秒一张待处理的图像合并,得到课堂视频的连续帧图像。
进一步地,步骤2包括:
步骤2.1:使用卷积神经网络提取课堂视频的连续帧图像中的特征图,用于后续maskr-cnn中的rpn(regionproposalnetwork,区域生成网络)层和全连接层;
步骤2.2:将得到的特征图输入到rpn层,完成从特征图中提取roi(regionofinterest,感兴趣的区域);
步骤2.3:对rpn层的输出结果进行roialign(roi对齐)操作,使不同输入尺寸的roi得到固定尺寸的输出;
步骤2.4:将步骤2.3处理后的roi分别送入到fastr-cnn(fastregion-convolutionalneuralnetwork,快速区域卷积神经网络)【可参考赵锟.基于深度卷积神经网络的智能车辆目标检测方法研究,国防科学技术大学,硕士学位论文,2015,pp.11-18】和fcn(fullyconvolutionalnetwork,全卷积神经网络)【可参考翁健.基于全卷积神经网络的全向场景分割研究与算法实现,山东大学,硕士学位论文,2017,pp.17-24】两个分支,fastr-cnn对roi进行分类和边界框回归,fcn为每个roi预测掩码。
进一步地,步骤2.1包括:
卷积层是卷积神经网络最核心的组成部分,卷积层对课堂视频的连续帧图像进行特征提取,其特征提取的具体实现是通过卷积核对感受野区域进行卷积所实现的,在这里,特征图的每个神经元将输入层中相邻区域的神经元连接在一起,这一区域被称为输入层特征图的感受野。卷积运算的过程为:
其中,i表示卷积运算的输入,a,b分别为卷积运算的输入的横坐标及纵坐标,k表示卷积核,s表示得到的特征映射,c,d分别为得到的特征映射的横坐标及纵坐标;
经过卷积操作后得到的特征图中,某一特征与其相邻区域内的很多特征将会非常相似,因此需要进一步整合,通过池化层的池化操作将得到的特征图内某一位置及其相邻位置的特征值进行统计汇总,并将汇总后的结果作为这一位置在所述特征图内的值,进一步缩小卷积操作后的特征映射图,避免了对相似特征的重复计算。池化分为最大池化与平均池化两种,较常使用的是最大池化法,即输出层中每一位元素值均为移动池化核大小范围内的最大值。
激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中,使用常见的relu函数作为激活函数:
其中,x表示激活函数的自变量。
进一步地,所述步骤2.2包括:
步骤2.2.1:rpn层首先为特征图(大小约为60*40)上的每个像素生成9个不同大小的锚箱(anchorbox),这9种锚箱包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1:1,1:2,2:1);
步骤2.2.2:对生成的锚箱进行裁剪过滤,rpn层中包含分类分支和边框回归分支。通过分类分支(softmax分类器)判断锚点属于前景还是背景,即是学生个体还是教室背景,通过边框回归分支(boundingboxregression)回归修正没有被排除的锚箱,实现更加精确的推荐。
步骤2.2.3:在rpn层末端,对分类分支及边框回归分支的结果进行汇总,实现对锚箱的初步筛除(分类分支结果)和初步偏移(边框回归分支结果)后,得到的输出称为候选框,将候选框映射到特征图上即为roi。
进一步地,所述步骤2.2.2包括:
softmax函数的本质就是将一个任意维数的任意实数向量映射成另一个相同维数的实数向量,其中向量中的每个元素取值都介于(0,1)之间,各元素之和等于1。在softmax的作用下每个样本所属不同类别的概率值都会被计算出来,由于所有情况出现的概率总和为1,经运算后,在同等条件下,正确类别出现的概率将会更高,同理,错误类别的出现的概率更低,softmax分类器具有学习率高,准确率高的优点。
对上一层输出的第m个元素,其softmax值sm为:
损失函数lm为:
lm=-logsm
其中,m为元素的序号,sm为第m个元素的softmax值,e为自然对数的底数,j为求和项的序数,outl、outw分别为上一层输出矩阵的长和宽,lm为第m个元素的损失函数值。
通过对分类类别的损失函数值进行比较,得出判断正确时的概率损失值,通过上述过程训练softmax分类器,将前景与背景分为两类,训练好softmax分类器后,将待检测特征图作为输入,即可自动识别待检测特征图所属的类别。
过滤和标记规则如下,首先去除掉超过原图边界的锚箱,即去除掉不需要被检测的背景,然后判断剩下的锚箱与真值(groundtruth)的交并比iou
进一步地,步骤2.3包括:
步骤2.3.1:使用已有的vgg16网络,选取步长为32做卷积层,则图片缩小为原输入图像的1/32,经过所述步长为32的卷积层后的区域方案映射到特征图中的大小也为原来的1/32;
步骤2.3.2:设定映射后的特征图大小为n*n,n不取整,经池化后固定成7*7大小的特征图,则将特征图上映射的n*n的区域方案划分成49个同等大小的小区域,每个小区域的大小(n/7)*(n/7);
步骤2.3.3:设定采样点数为4,即表示对于每个(n/7)*(n/7)的小区域平分成四份,每一份取其中心点位置的像素,采用双线性插值法进行计算得到四个点的像素值;
步骤2.3.4:取四个像素值中最大值作为这个小区域的像素值,如此类推,同样是49个小区域得到49个像素值,组成7*7大小的特征图,实现了将特征图上的roi固定成特定大小。
进一步地,所述步骤2.3.3包括:
双线性插值算法就是在两个方向分别进行一次线性插值,已知每个小区域左下角、右下角、左上角、右上角四个点的像素值,则可计算中间点位置的像素p:
其中,p1、p2、p3、p4、pp分别表示左下角、右下角、左上角、右上角四点及所求点的像素值,(uu,vv)为所求点的横坐标及纵坐标,(u1,v1)、(u2,v1)、(u1,v2)、(u2,v2)分别为左下角、右下角、左上角、右上角四点的横坐标及纵坐标。
进一步地,所述步骤2.4包括:
使用多任务损失来对分类和边界框进行联合优化训练:
l(p,u,tu,v)=lcls(p,u)+λ[u≥1]lloc(tu,v)
其中,l(p,u,tu,v)表示roi的多任务损失函数,p表示roi中包含目标的概率,u表示实际物体的标签信息,tu=(tux,tuy,tuw,tuh)为边界框通过神经网络算出的参数,tux,tuy,tuw,tuh分别表示边界框的横坐标、纵坐标、宽度、高度数据,v=(vx,vy,vw,vh)为人为标定的真实边界框的参数,vx,vy,vw,vh分别表示真实边界框的横坐标、纵坐标、宽度、高度数据,lcls(p,u)=-log[p*u+(1-p)(1-u)]为真实类别的对数损失,λ为超参数,设置为1,lloc(tu,v)为边界框的损失函数。
其中:
其中,x,y,w,h分别表示边界框的横坐标、纵坐标、宽度、高度,i表示边界框的序号,
训练好的网络即可用于对roi的分类和边界框回归。
fcn由卷积层、池化层、上采样层和softmax分类器组成,从图像级别的分类进一步延展到像素级别的分类,即从单目标分类变成多目标分类,其中,全卷积神经网络使用反卷积方法进行上采样,上采样层使特征图恢复到输入图像相同的尺寸,从而可以对每一个像素产生一个预测,并保留原始输入图像中的空间信息,最后再于上采样的图片上进行逐像素分类,得到最终的分割结果,从而实现对输入图像的准确分割,实现对每个roi中掩码的准确预测。
进一步地,所述步骤3包括:
步骤3.1:利用经典的adaboost算法,检测出每个学生个体的人脸所在位置;
步骤3.2:检测到每个学生个体的人脸所在位置后,通过人脸特征点定位到每个学生个体的人眼特征点;
步骤3.3:利用每个学生个体的人眼特征点计算每个学生个体的人眼闭合度特征值,公式如下:
其中,xt为眼睛位置的横坐标,yt为眼睛位置的纵坐标,k1为左眼闭合度特征值,k2为右眼闭合度特征值,k为左右眼的平均闭合度特征值。
xt、yt的下标t代表的数字为所有人眼特征点的序号,k1、k2分母几乎不变,当学生感到疲劳或打瞌睡时,人眼趋于闭合状态,特征点2即p2与特征点6即p6趋近重合,(p3与p5,p8与p12,p9与p11同理),k值会显著减小。根据k值大小,判断检测到的学生个体是否处于听课状态:
如果k值大于等于0.175,则学生个体被识别为认真听课状态;
如果k值小于0.175,则学生个体被识别为不听课状态。
步骤4包括:
利用经典的adaboost算法检测人脸,未检测到人脸则判定该学生个体未抬头,根据所有学生个体中未检测到人脸的个数占所有学生个体的比例,判断学生个体的听课状态等级:
如果一帧图像中大于等于80%的学生都处于未抬头状态,则判定此时学生收到教师的统一指令,都在记笔记或做习题,判定所有未抬头学生为认真听课状态;
如果一帧图像中大于等于40%小于80%的学生处于未抬头状态,则判定此时部分学生处于看书状态,判定所有未抬头学生为一般听课状态;
如果一帧图像中小于40%的学生处于未抬头状态,则判定未抬头学生处于不听课状态。
进一步地,步骤5包括:
通过对不同听课状态打分加权计算出学生整个课堂时段听课效率百分比:
对步骤3及步骤4中判别出的处于认真听课状态的学生个体,每检测到一次打1分;
对步骤4中判别出的处于一般听课状态的学生个体,每检测到一次打0.6分;
对步骤3及步骤4中判别出的处于不听课状态的学生个体,每检测到一次打0分;
最终每个学生个体的得分计算公式为:
其中,p为学生个体的得分,r为学生个体处于认真听课状态的总帧数,s为学生个体处于一般听课状态的总帧数,n为得到课堂视频的连续帧图像总帧数。
通过上述技术方案的实施,本发明的有益效果是:(1)提供了视频分帧处理方法,选取合适的时间间隔,保证符合实际情景的同时大大提高检测效率;(2)提供了基于maskr-cnn的多学生个体分割方法,完成学生个体的精准检测,检测率高,准确区分前景与背景,抑制复杂背景环境对学生个体检测的干扰影响;(3)提供了结合人脸特征点检测及人眼闭合度算法判断学生听课状态,实现多学生个体听课状态自主识别且识别率高;(4)用视觉传感器代替硬件传感器,实现对学生的无感识别,舒适度高,成本低;(5)运算速度快,识别率高,环境适应能力强。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
图1是本发明所述的基于深度学习的多学生个体分割及状态自主识别方法的流程框图。图2是本发明所述的maskr-cnn网络结构图。
图3是本发明所述的双线性插值算法示意图。
图4是本发明所述的人眼部12个特征点对应序号及位置图。
图5是本发明具体实施例中结合人眼闭合度特征值随机抽取某一帧图像中学生个体的标识及听课状态识别图。
图6是本发明具体实施例中处理完整段视频后每个学生个体的听课效率统计图。
具体实施方式
在本实施例中,以每10s一帧,提取50帧图像的听课实验视频为例,对完整课堂时段中学生个体检测及听课状态自主识别方法进行说明;
参照图1,为本发明实施例提供的基于深度学习的多学生个体分割及状态自主识别方法的工作流程示意图,包括以下步骤:
步骤1:采集正常上课视频,对所采集的视频进行分帧处理,得到每10秒一张待处理的图像,将得到的所有图像合帧,得到课堂视频的连续帧图像;
步骤2:利用基于maskr-cnn的多学生个体分割方法分割出课堂视频的连续帧图像中的学生个体和非学生个体,并将不学生生个体标记为不同颜色的掩码,得到标记学生掩码的课堂连续帧图像;
步骤3:利用步骤2得到标记学生掩码的课堂连续帧图像,通过人脸特征点定位方法找到每个学生个体的人眼特征点,利用人眼特征点计算每个学生个体的人眼闭合度特征值,通过人眼闭合度特征值判断每个学生个体当前是否处于听课状态;
步骤4:利用人脸特征点定位方法判断所有学生个体是否检测到人脸,根据所有学生个体中未检测到人脸的个数占所有学生个体的比例,判断学生个体的听课状态等级;
步骤5:根据上述步骤处理完所有课堂视频的连续帧图像后,结合每个学生个体是否处于听课状态及每个学生个体是否处于未抬头状态设计了整个课堂时段学生听课效率评估方法,通过对不同听课状态打分加权计算出学生整个课堂时段听课效率百分比。
下面结合附图和具体实施例对本发明作进一步说明。
在本发明实施例中,采用的是基于深度学习的多学生个体分割及状态自主识别方法,其中用到的主要神经网络maskr-cnn网络结构图如图2所示。
在本发明实施例中,所述步骤1包括:
步骤1.1:录制整个课堂时段的全体学生正面视频,将所录制的视频保存至计算机;
步骤1.2:获得整个课堂时段的全体学生正面视频总帧数,得到每十秒的帧数,设置每十秒的帧数取一次帧,将每次取得的帧转化为每10秒一张待处理的图像输出保存至计算机;
步骤1.3:对得到的每10秒一张待处理的图像合并,得到课堂视频的连续帧图像。
在本发明实施例中,所述步骤2包括:
步骤2.1:使用一组基础的“卷积层+激活函数+池化层”提取课堂视频的连续帧图像中的特征图,用于后续maskr-cnn中的rpn层和全连接层;
步骤2.2:将得到的特征图输入到rpn层,完成从特征图中提取roi;
步骤2.3:对rpn层的输出结果进行roialign操作,使不同输入尺寸的roi得到固定尺寸的输出;
步骤2.4:将步骤2.3处理后的roi分别送入到fastr-cnn和fcn两个分支,fastr-cnn对roi进行分类和边界框回归,fcn为每个roi预测掩码。
在本发明实施例中,所述步骤2.1包括:
卷积层是卷积神经网络最核心的组成部分,该层对课堂视频的连续帧图像进行特征提取,其特征提取的具体实现是通过卷积核对感受野区域进行卷积所实现的,在这里,特征图的每个神经元将输入层中相邻区域的神经元连接在一起,这一区域被称为输入层特征图的感受野。卷积运算的过程为:
其中,i表示卷积运算的输入,a,b为卷积运算的输入的横坐标及纵坐标,k表示卷积核,s表示得到的特征映射,c,d为得到的特征映射的横坐标及纵坐标。
经过卷积操作后得到的特征图中,某一特征与其相邻区域内的很多特征将会非常相似,因此需要进一步整合,用池化操作将得到的特征图内某一位置及其相邻位置的特征值进行统计汇总,并将汇总后的结果作为这一位置在该特征图内的值,进一步缩小卷积操作后的特征映射图,避免了对相似特征的重复计算。池化分为最大池化与平均池化两种,较常使用的是最大池化法,即输出层中每一位元素值均为移动池化核大小范围内的最大值。
激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中,使用常见的relu函数作为激活函数:
其中,x表示激活函数的自变量。
在本发明实施例中,所述步骤2.2包括:
步骤2.2.1:rpn层首先为特征图(大小约为60*40)上的每个像素生成9个不同大小的锚箱(anchorbox),这9种锚箱包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1:1,1:2,2:1);
步骤2.2.2:对生成的锚箱进行裁剪过滤,rpn层中包含分类分支和边框回归分支。通过分类分支(softmax分类器)判断锚点属于前景还是背景,即是学生个体还是教室背景;通过边框回归分支(boundingboxregression)回归修正没有被排除的锚箱,实现更加精确的推荐。
步骤2.2.3:在rpn层末端,对分类分支及边框回归分支的结果进行汇总,实现对锚箱的初步筛除(分类分支结果)和初步偏移(边框回归分支结果)后,得到的输出称为候选框,将候选框映射到特征图上即为roi。
在本发明实施例中,所述步骤2.2.2包括:
softmax函数的本质就是将一个任意维数的任意实数向量映射成另一个相同维数的实数向量,其中向量中的每个元素取值都介于(0,1)之间,各元素之和等于1。在softmax的作用下每个样本所属不同类别的概率值都会被计算出来,由于所有情况出现的概率总和为1,经运算后,在同等条件下,正确类别出现的概率将会更高,同理,错误类别的出现的概率更低,softmax分类器具有学习率高,准确率高的优点。
对上一层输出的第m个元素,其softmax值为:
损失函数为:
lm=-logsm
其中,m为元素的序号,sm为第m个元素的softmax值,e为自然对数的底数,j为求和项的序数,outl、outw分别为上一层输出矩阵的长和宽,lm为第m个元素的损失函数值。
通过对分类类别的损失函数值进行比较,得出判断正确时的概率损失值,通过上述过程训练softmax分类器,将前景与背景分为两类,训练好softmax分类器后,将待检测特征图作为输入,即可自动识别待检测特征图所属的类别。
过滤和标记规则如下,首先去除掉超过原图边界的锚箱,即不需要被检测的背景,然后判断剩下的锚箱与真值(groundtruth)的交并比iou
在本发明实施例中,所述步骤2.3包括:
步骤2.3.1:使用已有的vgg16网络,选取步长为32做卷积层,则图片缩小为原输入图像的1/32,经过该步长为32的卷积层后的区域方案映射到特征图中的大小也为原来的1/32;
步骤2.3.2:假设映射后的特征图大小为n*n,n不取整,经池化后固定成7*7大小的特征图,则将特征图上映射的n*n的区域方案划分成49个同等大小的小区域,每个小区域的大小(n/7)*(n/7);
步骤2.3.3:假定采样点数为4,即表示对于每个(n/7)*(n/7)的小区域平分成四份,每一份取其中心点位置的像素,采用双线性插值法进行计算得到四个点的像素值;
步骤2.3.4:取四个像素值中最大值作为这个小区域的像素值,如此类推,同样是49个小区域得到49个像素值,组成7*7大小的特征图,实现了将特征图上的roi固定成特定大小。
在本发明实施例中,所述步骤2.3.3包括:
双线性插值算法就是在两个方向分别进行一次线性插值,已知每个小区域左下角、右下角、左上角、右上角四个点的像素值,则可计算中间点位置的像素:
其中,p1、p2、p3、p4、p分别表示左下角、右下角、左上角、右上角四点及所求点的像素值,(uu,vv)为所求点的横坐标及纵坐标,(u1,v1)、(u2,v1)、(u1,v2)、(u2,v2)分别为左下角、右下角、左上角、右上角四点的横坐标及纵坐标,可由图3直观看出。
在本发明实施例中,所述步骤2.4包括:
使用多任务损失来对分类和边界框进行联合优化训练:
l(p,u,tu,v)=lcls(p,u)+λ[u≥1]lloc(tu,v)
其中,l(p,u,tu,v)表示roi的多任务损失函数,p表示roi中包含目标的概率,u表示实际物体的标签信息,tu=(tux,tuy,tuw,tuh)为边界框通过神经网络算出的参数,tux,tuy,tuw,tuh分别表示边界框的横坐标、纵坐标、宽度、高度数据,v=(vx,vy,vw,vh)为人为标定的真实边界框的参数,vx,vy,vw,vh分别表示真实边界框的横坐标、纵坐标、宽度、高度数据,lcls(p,u)=-log[p*u+(1-p)(1-u)]为真实类别的对数损失,λ为超参数,设置为1,lloc(tu,v)为边界框的损失函数。
其中:
其中,x,y,w,h分别表示边界框的横坐标、纵坐标、宽度、高度,i表示边界框的序号,
训练好的网络即可用于对roi的分类和边界框回归。
fcn由卷积层、池化层、上采样层和softmax分类器组成,从图像级别的分类进一步延展到像素级别的分类,即从单目标分类变成多目标分类,其中,全卷积神经网络使用反卷积方法进行上采样,上采样层使特征图恢复到输入图像相同的尺寸,从而可以对每一个像素产生一个预测,并保留原始输入图像中的空间信息,最后再于上采样的图片上进行逐像素分类,得到最终的分割结果,从而实现对输入图像的准确分割,实现对每个roi中掩码的准确预测。
在本发明实施例中,所述步骤3包括:
步骤3.1:利用经典的adaboost算法,检测出每个学生个体的人脸所在位置;
步骤3.2:检测到每个学生个体的人脸所在位置后,通过人脸特征点定位到每个学生个体的人眼特征点,如图4所示;
步骤3.3:利用每个学生个体的人眼特征点计算每个学生个体的人眼闭合度特征值,公式如下:
其中,xt为眼睛位置的横坐标,yt为眼睛位置的纵坐标,k1为左眼闭合度特征值,k2为右眼闭合度特征值,k为左右眼的平均闭合度特征值。
在本发明实施例中,所述步骤3.3包括:
xt、yt的下标t代表的数字为所有人眼特征点的序号,k1、k2分母几乎不变,当学生感到疲劳或打瞌睡时,人眼趋于闭合状态,特征点2(p2)与特征点6(p6)趋近重合,(p3与p5,p8与p12,p9与p11同理),k值会显著减小。根据k值大小,判断检测到的学生个体是否处于听课状态:
如果k值大于等于0.175,则学生个体被识别为认真听课状态;
如果k值小于0.175,则学生个体被识别为不听课状态。如图5所示,为本发明实施例提供的基于深度学习的多学生个体分割及状态自主识别方法识别结果。
在本发明实施例中,所述步骤4包括:
利用经典的adaboost算法检测人脸,未检测到人脸可以判定该学生个体未抬头,根据所有学生个体中未检测到人脸的个数占所有学生个体的比例,判断学生个体的听课状态等级:
如果一帧图像中大于等于80%的学生都处于未抬头状态,则判定此时学生收到教师的统一指令,都在记笔记或做习题,判定所有未抬头的学生为听课状态;
如果一帧图像中大于等于40%小于80%的学生处于未抬头状态,则判定此时部分学生处于未抬头看书状态,判定所有未抬头学生为一般听课状态;
如果一帧图像中小于40%的学生处于未抬头状态,则判定这些学生处于不听课状态。
在本发明实施例中,所述步骤5包括:
如图6所示,为处理一段每帧10s,共50帧的视频结果,以被识别个体的“标号+当前听课状态+累计听课总次数+听课效率”形式显示出来,通过对不同听课状态打分加权计算出学生整个课堂时段学生听课效率百分比:
对步骤3及步骤4中判别出的处于认真听课状态的学生个体,每检测到一次打1分;
对步骤4中判别出的处于一般听课状态的学生个体,每检测到一次打0.6分;
对步骤3及步骤4中判别出的处于不听课状态的学生个体,每检测到一次打0分;
最终每个学生个体的得分计算公式为:
其中,p为学生个体的得分,r为学生个体处于认真听课状态的总帧数,s为学生个体处于一般听课状态的总帧数,n为得到课堂视频的连续帧图像总帧数。
通过上述技术方案的实施,本发明的优点是:(1)提供了视频分帧处理方法,选取合适的时间间隔,保证符合实际情景的同时大大提高检测效率;(2)提供了基于maskr-cnn的多学生个体分割方法,完成学生个体的精准检测,检测率高,准确区分前景与背景,抑制复杂背景环境对学生个体检测的干扰影响;(3)提供了人脸特征点定位方法及人眼闭合度特征值判断学生听课状态,实现多学生个体听课状态自主识别且识别率高;(4)用视觉传感器代替硬件传感器,实现对学生的无感识别,舒适度高,成本低;(5)运算速度快,识别率高,环境适应能力强。
本发明提供了基于深度学习的多学生个体分割及状态自主识别方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!