一种面向文件的海量数据分级存储方法与流程
本发明涉及计算机领域,主要涉及一种面向文件的海量数据分级存储方法。
背景技术:
随着网络技术的发展,数据呈现迅猛的增长态势,根据idc的调查报告显示,在目前的数据中80%的数据都是非结构化的数据,相较于结构化数据,非结构化数据的增长速度远远高于结构化数据的增长速度。对于激增的非结构化数据,上层应用提出了更高的存储和访问性能要求:高性能、低成本以及高可扩展。因此开发高性能、低价格、可扩展、可管理的存储系统成为一个亟待解决的问题。
在近几年的硬件技术发展中,新型存储设备不断出现,例如satassd、pciessd等,可以提供高性能的数据存储和数据访问,但其价格较高。相对而言,传统的硬盘(harddiskdevice)性能较差,但价格便宜。另外,许多针对大规模存储系统的研究表明,在所有文件中,只有1%的文件每天使用,而90%的文件几乎不被使用,即文件的访问具有局部性。因此,如果将所有的文件都存储在高性能的存储设备上,虽然可以保证文件的高性能存储和访问,但由于数据量巨大,会导致存储成本急剧上升;而如果将所有文件都存储在大容量的存储设备上,则不能保证系统的整体性能。
目前存在的主要问题:
(1)如果将所有文件都存储在大容量的存储设备上,则不能保证系统的整体性能;
(2)如果将所有的文件都存储在高性能的存储设备上,数据量巨大;
(3)无法区分不同价值区间的数据。
技术实现要素:
针对现有技术中存在的问题,本发明旨在发明一种面向文件的海量数据分级存储方法,其中:
一种面向文件的海量数据分级存储方法,包括以下步骤:
s1.迁移线程;
s2.接收i/o请求文件;
s3.判断i/o请求优先级;
s4.判断请求文件是否在迁移队列中;
s5.继续迁移;
其中,当请求文件在迁移队列中,步骤s4还包括以下子步骤:
s401.中断迁移;
s402.本地命中;
s403.访问结束;
s404.判断请求文件位置处于高性能存储服务器或低速存储服务器。
进一步的,当i/o请求优先级高,还包括以下子步骤:
s301.查询请求文件所在地址;
s302.发送访问请求。
进一步的,还包括与步骤s0,通过计算迁移速率判断文件迁移进行与否;系统监控着数据管理客户端中的i/o队列长度;当其中i/o队列长度比设置的阈值t要高时,则判定前端负载较高,i/o响应时间随着i/o队列的长度增长而增加;所述的迁移速率如下:
通过公式计算得到数据迁移应该等待的时间长度w,w的计算公式如下所示:
其中e是一个常数,l是i/o队列长度,t是设置的阈值。e和t的值是依据经验值得到的。
进一步的,当请求文件位置处于高性能服务器时,重新判断请求文件性质。
进一步的,所述的重新判断请求文件性质,当请求文件性质改变,判断请求文件的状态,请求文件处于正在迁移状态,终止迁移,并删除未完成迁移数据;请求文件处于等待迁移状态,终端将请求文件从迁移队列中删除。
本发明的有益效果:
(1)保证系统的整体性能;
(2)区分不同价值区间的数据;
(3)在业务场景下的数据自动评估方法,实现系统中数据的自动迁移。
附图说明
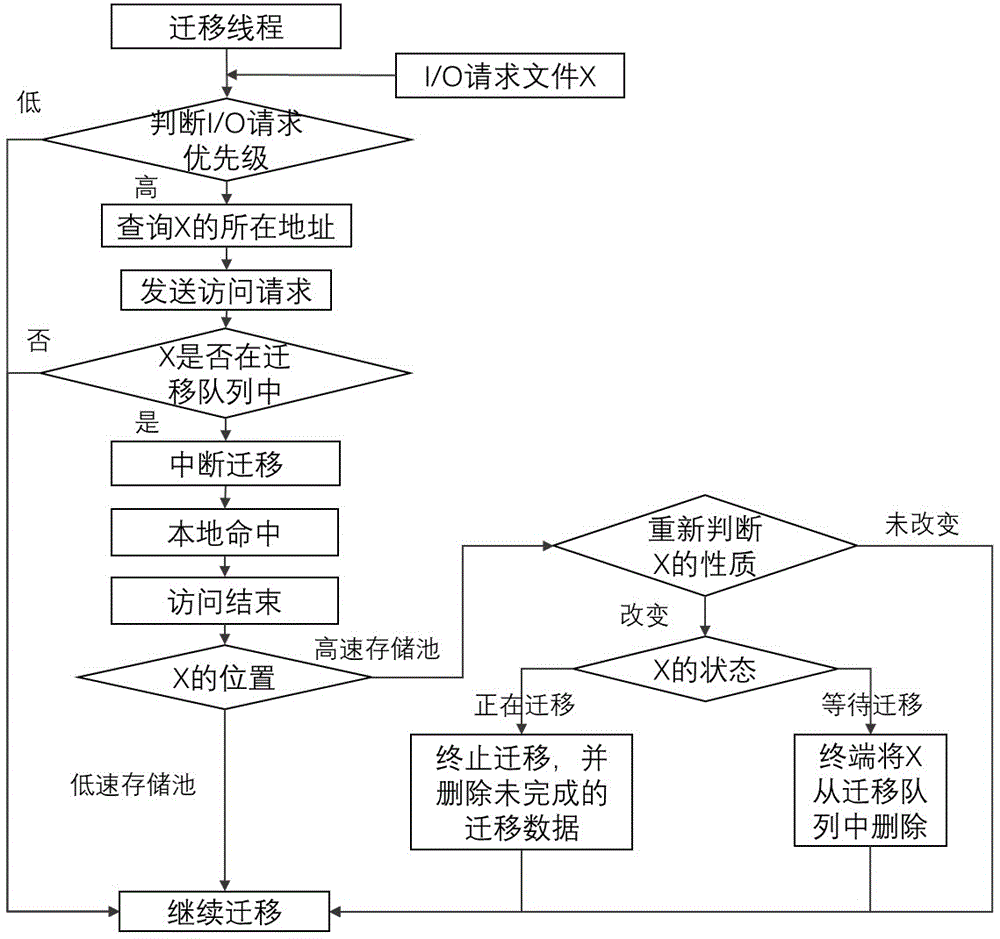
图1是本发明的数据迁移控制流程图;
图2是本发明的迁移速率控制图。
具体实施方式
针对现有技术中存在的问题,本发明旨在发明一种面向文件的海量数据分级存储方法,其中:一种面向文件的海量数据分级存储方法,包括以下步骤:
s1.迁移线程;
s2.接收i/o请求文件;
s3.判断i/o请求优先级;
s4.判断请求文件是否在迁移队列中;
s5.继续迁移;
其中,当请求文件在迁移队列中,步骤s4还包括以下子步骤:
s401.中断迁移;
s402.本地命中;
s403.访问结束;
s404.判断请求文件位置处于高性能存储服务器或低速存储服务器。
进一步的,当i/o请求优先级高,还包括以下子步骤:
s301.查询请求文件所在地址;
s302.发送访问请求。
进一步的,还包括与步骤s0,通过计算迁移速率判断文件迁移进行与否;系统监控着数据管理客户端中的i/o队列长度;当其中i/o队列长度比设置的阈值t要高时,则判定前端负载较高,i/o响应时间随着i/o队列的长度增长而增加;所述的迁移速率如下:
通过公式计算得到数据迁移应该等待的时间长度w,w的计算公式如下所示:
其中e是一个常数,l是i/o队列长度,t是设置的阈值。e和t的值是依据经验值得到的。
进一步的,当请求文件位置处于高性能服务器时,重新判断请求文件性质。
进一步的,所述的重新判断请求文件性质,当请求文件性质改变,判断请求文件的状态,请求文件处于正在迁移状态,终止迁移,并删除未完成迁移数据;请求文件处于等待迁移状态,终端将请求文件从迁移队列中删除。
为了对本发明的技术特征、目的和效果有更加清楚的理解,先对照附图说明本发明的具体实施方式。
以下结合附图描述根据本发明实施例的海量数据分级存储方法。
图1是根据本发明实例中,数据迁移的控制流程图。迁移队列中的数据状态主要包括等待迁移、正在迁移、已迁移三种状态。等待迁移是指数据以满足迁移条件,但是由于迁移队列已满或按迁移顺序还未轮到的状态;正在迁移是指数据处于迁移队列中,且正在从一级存储设备迁移至另一存储设备的过程中;已迁移是指数据已完全从原有设备中迁移出的状态。
分级存储中数据迁移的同时也会有来自应用程序端的i/o请求,为了保证数据迁移进程的正确执行需要正确处理这些i/o请求和数据的迁移。有来自前台的请求中断时,比较i/o请求与数据迁移进程的优先级,若优先级高,则需中断数据迁移并保护迀移进程现场,响应和处理i/o请求,处理结束后恢复被中断的数据迁移进程现场,继续执行被中断的数据迁移,反之,则不做任何处理。
图2是根据本发明实例中,迁移速率控制示意图。由于存储系统中i/o访问负载的不确定性,系统使用逻辑上开/关两种状态来调整数据迁移速度。文件迁移进行与否,是依据数据管理客户端中前端应用的负载来确定的。如果前端负载相对较低,则进行数据迁移,如果负载过高,则对文件迁移进行限制。
系统监控着数据管理客户端中的i/o队列长度。当其中i/o队列长度比设置的阈值t要高时,则判定前端负载较高。一般来说,i/o响应时间随着i/o队列的长度增长而增加。具体地,通过公式计算得到数据迁移应该等待的时间长度w,w的计算公式如下所示:
w=e×(l-t)
其中e是一个常数,l是i/o队列长度,t是设置的阈值。e和t的值是依据经验值得到的。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!