风控模型入模变量最小熵分箱方法与流程
本发明涉及风险控制技术领域,具体涉及风控模型入模变量最小熵分箱方法。
背景技术:
风控建模在现代金融的自动化风控中发挥着举足轻重的作用,当前,风控模型大多基于逻辑回归和决策树等机器学习模型,通过历史借贷样本的训练建立用户行为和信用之间的映射关系。风控模型从样本中学习的特性决定了样本集和入模变量是影响模型有效性的关键因素之一。
风控建模过程中,为了增强模型的稳定性和避免过拟合,同时增加模型结果的可解释性,通常会对模型入模变量中的连续变量离散化,即分箱。在常用的分箱方法中,等距分箱和等频分箱由于没有考虑变量本身的分布情况,通常分箱的效果不佳。卡方分箱需要人为设定卡方阈值,依赖专家经验,较为复杂。
技术实现要素:
针对现有技术的不足,本发明提供一种最小熵分箱方法,该方法以变量分箱后熵最小为目标,仅需要预设分箱数,并通过启发式搜索方法获取最优的分箱方案。最小熵的优化目标使变量分箱后箱内差异小和箱间差异大,从而最大程度保留了变量对于风控模型分类的价值,达到提升风控模型训练和预测效果的目的。
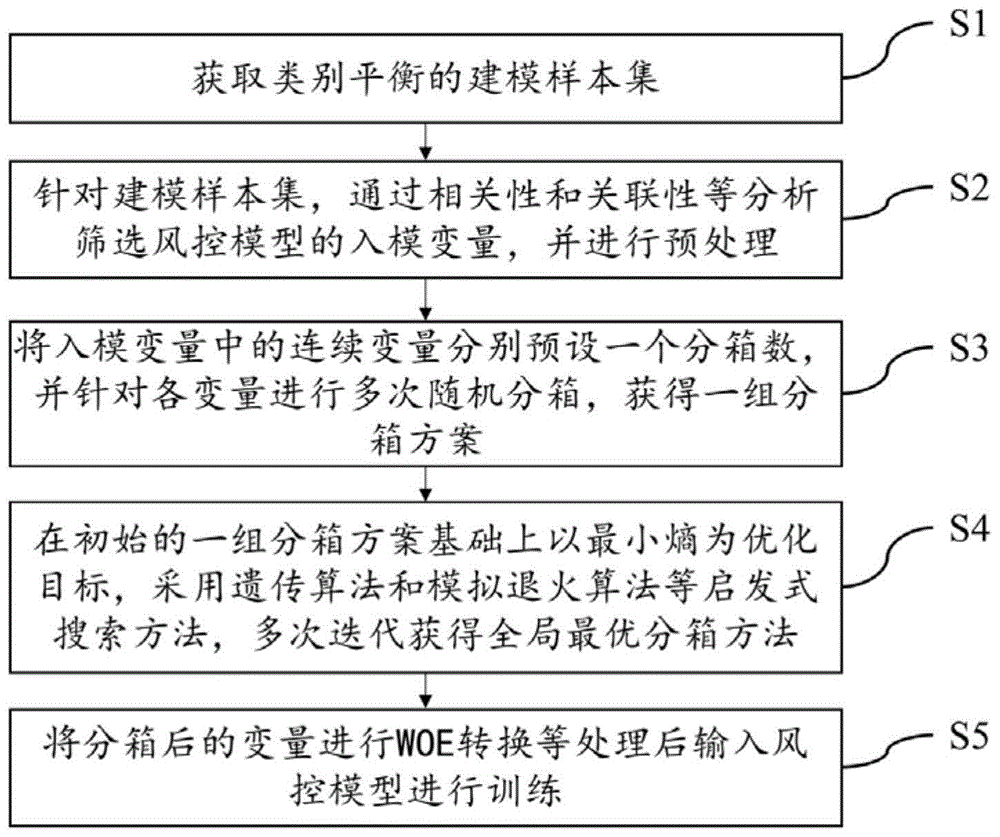
本发明提供一种风控模型入模变量最小熵分箱方法,包括如下步骤:
s1:获取类别平衡的建模样本集;
s2:针对建模样本集,通过相关性和关联性分析筛选风控模型的入模变量,并进行预处理;
s3:将入模变量中的连续变量分别预设一个分箱数,并针对各变量进行多次随机分箱,获得一组分箱方案;
s4:在初始的一组分箱方案基础上以最小熵为优化目标,采用遗传算法和模拟退火算法等启发式搜索方法,多次迭代获得全局最优分箱方法;
s5:将分箱后的变量进行woe转换等处理后输入风控模型进行训练。
优选地,所述步骤s1中的建模样本集,通过原始样本集的重采样获取。重采样包括欠采样和过采样两种方法,目的是使采样所得的建模样本集类别平衡,即样本集中不同类别样本比例大致相等。
优选地,所述步骤s2中通过相关性和关联性分析筛选风控模型的入模变量,并进行预处理,包括以下步骤:
s2.1在建模样本集的全变量中筛选出对类别变量影响最大的变量子集,作为风控模型的入模变量,其中变量对类别变量影响的衡量可以通过相关性和关联性分析。
s2.2对筛选出的变量子集进行缺失值填充、异常值替换和哑变量转换等预处理,变量类型包含名义变量、顺序变量和连续变量,预处理的方式根据变量类型和风控模型的输入要求而定。
优选地,所述步骤s3中针对各变量进行多次随机分箱,仅作用于入模变量中的连续变量,名义变量和顺序变量不参与分箱处理。
优选地,所述步骤s3中针对各变量进行多次随机分箱,包括以下步骤:
s3.1对于不同的连续变量分别预设一个分箱数,预设的分箱数不需要相等,实践中视变量的范围和分布而定。
s3.2针对每一个连续变量,根据预设的分箱数进行多次随机分箱,获得各变量一组初始的分箱方案,以作为进一步优化的基础,所谓随机分箱指在连续变量的取值范围内,分段的点随机选取。
优选地,所述步骤s4中在初始的一组分箱方案基础上以最小熵为优化目标,采用遗传算法和模拟退火算法等启发式搜索方法,多次迭代获得全局最优分箱方法,包括以下步骤:
s4.1评估该组多个分箱方案的优劣,其中评估的量化指标为分箱方案的熵,以熵最小为优,变量分箱的熵计算如公式(1)所示:
其中k表示预设的分箱数,ri为第i个分箱样本数占总样本数的比例,c为样本集的类别数,pij为第i个分箱内,类别为j的样本占该分箱样本数的比例。
s4.2以较优的分箱方案子集为基础,利用遗传算法和模拟退火算法通过迭代优化的方式获得最终的分箱方案,该方案通常为全局最优解或者近似全局最优解。
有益效果:本发明提供一种最小熵分箱方法,该方法以变量分箱后熵最小为目标,仅需要预设分箱数,并通过启发式搜索方法获取最优的分箱方案。最小熵的优化目标使变量分箱后箱内差异小和箱间差异大,从而最大程度保留了变量对于风控模型分类的价值,达到提升风控模型训练和预测效果的目的;采用本发明提供的方案,在实现自动化分箱的同时保证分箱的合理性,有利于提升风控模型的训练和预测精度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1是本发明的风控模型入模变量最小熵分箱方法的流程示意图。
图2是连续变量一组随机分箱方案的示意图。
图3是连续变量分箱以最小熵为优化目标,采用遗传算法为优化方法的分箱流程示意图。
具体实施方式
为使本发明目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
以下结合具体实施方式和附图1对本发明技术方案作进一步说明,
一种风控模型入模变量降维方法,包括以下步骤:
s1:获取类别平衡的建模样本集;其中建模样本通过原始样本的重采样获得,通常原始样本集规模过大且存在正常样本比例远大于逾期样本的情况,通过重采样筛选较优样本的同时获得类别平衡的建模样本集。
例如,样本集包含2个类别,分别为正常和逾期,如果原始样本集中正常样本的比例高达90%,而逾期样本仅为10%,则需要通过正常样本的欠采样或者逾期样本的重采样来提升逾期样本的比例,从而使正常和逾期样本在样本集的比例大致相当,作为用于训练风控模型的建模样本集。
s2:针对建模样本集,通过相关性和关联性等分析筛选风控模型的入模变量,并进行预处理;具体来说,对于s1步骤所得建模样本集,通常全变量数量较多且大部分变量和模型预测类别无关,因此需要根据相关性和关联性分析从建模样本中筛选出对模型预测影响最大的变量,作为模型的入模变量,再对筛选出的变量子集进行缺失值填充、异常值替换和哑变量转换等预处理。通常入模变量包括名义变量、顺序变量和连续变量三种类型,需要根据变量类型和风控模型的输入要求进行相应的预处理。
例如,建模样本集有2000个变量,通过相关性分析从全变量中筛选出15个变量{a1,a2,a3,a4,a5,b1,b2,b3,b4,b5,c1,c2,c3,c4,c5}作为入模变量,其中{a1,a2,a3,a4,a5}为名义变量,{b1,b2,b3,b4,b5}为顺序变量,{c1,c2,c3,c4,c5}为连续变量。对所有变量进行缺失值填充和异常值替换,同时对名义变量中的类别变量进行哑变量转换。
s3:将入模变量中的连续变量分别预设一个分箱数,并针对各变量进行多次随机分箱,获得一组分箱方案;具体来说,不同的连续变量取值范围和分布不同,需要针对具体的变量设定对应的分箱数。由于分箱数是人为设定的超参数,对同一个变量可以设定不同的分箱,在后续的处理中对比不同分箱数的效果。在分箱数设定之后,对同一个变量进行多次随机分箱,从而得到多个分箱方案,所谓随机分箱是指在变量的取值范围内随机选取分段点。随机所得的一组分箱方案作为后续优化的基础。
例如,如附图2所示,假设s2得到的入模变量其中一个连续变量为年龄,取值范围为16~70,假设预设分箱数为4,则其中一种示意的n个随机分箱方案为:{方案1:{[16,28),[28,45),[45,57),[57,70]},方案2:{[16,32),[32,50),[50,60),[60,70]},...,方案n:{[16,25),[25,35),[35,54),[54,70]}}。
s4:在初始的一组分箱方案基础上以最小熵为优化目标,采用遗传算法和模拟退火算法等启发式搜索方法,多次迭代获得全局最优分箱方法;具体来说,最终分箱方案在s3步骤中得到的一组随机分箱方案基础上优化获得,优化的目标为最小化分箱方案的熵,变量分箱的熵计算如公式(1)所示:
其中k表示预设的分箱数,ri为第i个分箱样本数占总样本数的比例,c为样本集的类别数,pij为第i个分箱内,类别为j的样本占该分箱样本数的比例。
优化方法可以采用遗传算法和模拟退火算法等启发式搜索方法,理论上在分箱数较多的情况下启发式搜索可能得到近似全局最优方案,实践中由于分箱数通常不大,绝大部分情况下可以得到全局最优解。
例如,采用遗传算法作为优化方法,对于步骤s3中得到的年龄变量的n个随机分箱方案,采用附图3所示的优化步骤。首先根据公式(1)计算n个随机分箱方案的熵,并将方案按熵的大小正向排序,取较优的方案(比如前4个)作为进一步优化的基础。然后以一定的概率pc让选择的分箱方案两两交叉,所谓交叉,可以是交换两个方案中的部分分段。然后以一定的概率pc让每一个分箱方案变异,其中变异可以为分段位置的移动,比如增加或者减少1。在交叉和变异后得到新的分箱方案,与最初选择的分箱方案合并,作为第2轮的初始分箱方案,进行[选择-->交叉-->变异]的过程,以此类推,在达到预定的迭代次数之后输出最优分箱方案。
s5:将分箱后的变量进行woe转换等处理后输入风控模型进行训练。具体而言,将步骤s4得到分箱后的入模变量,按照风控模型的输入要求作进一步的处理,得到最终的入模变量。
例如,风控模型为标准的逻辑回归评分卡二分类模型,需要将各变量进行woe转换,最后将各变量的对应woe值输入模型进行训练。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!