一种基于深度学习的吸烟行为实时检测方法与流程
本发明属于人工智能和行为检测技术领域,尤其涉及一种基于深度学习的吸烟行为实时检测方法。
背景技术:
人类行为识别是计算机视觉中一项基本任务,基于视觉的人类行为识别是使用动作标签标记图像序列的过程,解决此问题的可靠解决方案已在视频监控、视频检索、人机交互和视频理解等领域中得到应用,例如,基于行为识别的视频监控,可以应用在老年人的智能家居中,老人摔倒等问题。视频检索足球比赛中的铲球,新闻镜头中的握手或音乐视频中的典型舞步。交互式应用程序,例如人机交互或游戏中的应用程序。由于动作性能、录制设置和人际差异的变化,使得这项任务非常具有挑战性。
吸烟行为检测是人类行为检测类别的一种,目前关于吸烟行为检测已有部分研究,一种是特征提取算法从视频中提取特征,根据特征判断视频中是否存在吸烟行为;这种主要分为三步:识别视频流帧中内的移动区域,例如差分算法;搜索每个已识别区域内的烟雾特征,例如颜色直方图获取烟雾特征,像素分析算法获取烟的像素特征;根据提取的烟雾特征推断烟雾是否存在,比如建立高斯模型、隐马尔可夫模型来与吸烟行为进行匹配,或者svm分类器对特征进行分类。基于这种方式的算法,对于特征的提取单一,因此普遍具有很差的泛化能力,对于复杂环境下的吸烟行为识别准确率不高;模型的建立复杂,实际应用起来不具有很高的实时性。另一种是借助卷积神经网络从视频流图像中提取特征,定位图像中吸烟位置,并进行行为类别判断,该技术能够提取丰富的吸烟行为特征,具有比较好的准确度,而且深度学习算法普遍具有很高的实时性,但是由于缺乏相关数据集,因此研究不够深入,训练出的模型不具备良好的实际应用能力;而且对于卷积神经网络的应用也只是套用现有的网络,并没有根据吸烟特征来构建属于吸烟行为检测的专属网络。
技术实现要素:
鉴于上述问题,本发明的目的在于提供一种基于深度学习的吸烟行为实时检测方法,旨在解决上述问题。
本发明采用如下技术方案:
所述基于深度学习的吸烟行为实时检测方法,包括下述步骤:
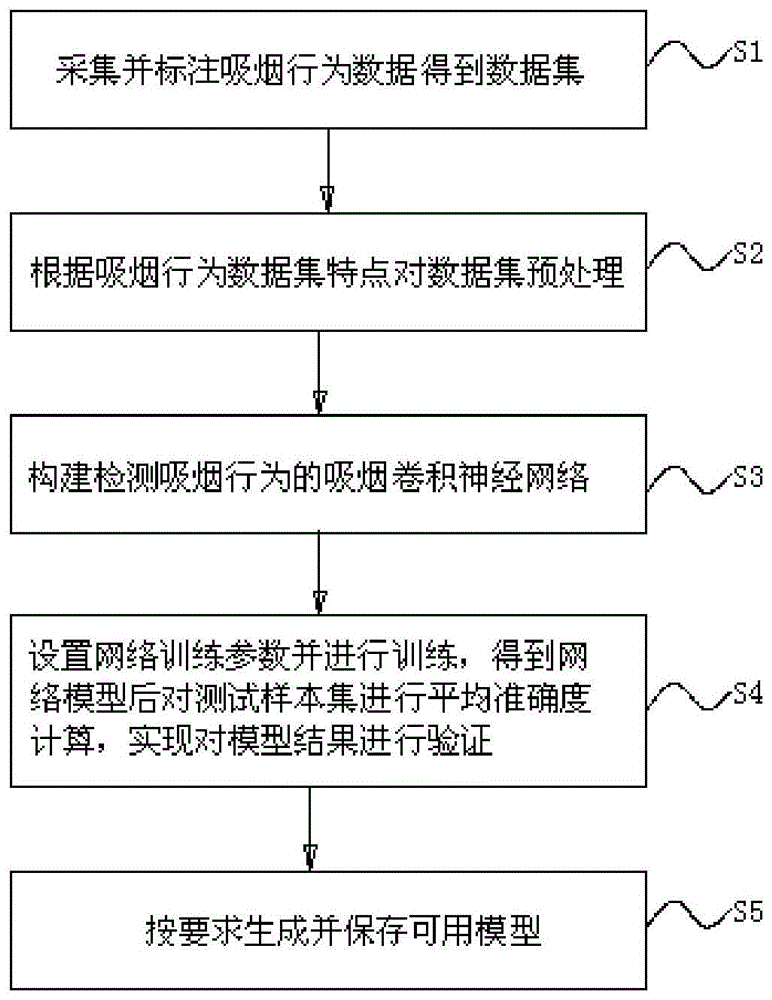
采集并标注吸烟行为数据得到数据集,包括训练样本集、验证样本集和测试样本集,每个样本集均分为正样本和负样本;
根据吸烟行为数据集特点对数据集预处理,包括数据增广处理、数据集标准化处理和数据集归一化处理;
结合深度学习并根据吸烟行为特点,构建检测吸烟行为的吸烟卷积神经网络;
设置吸烟卷积神经网络的网络训练参数并进行训练,得到网络模型后对测试样本集进行平均准确度计算,实现对模型结果进行验证;
按要求生成并保存可用模型,使用保存好的可用模型即可应用到吸烟行为检测现实场景中。
进一步的,所述数据增广处理具体过程如下:
对数据集中的每张图片随机翻转以扩增数据集图片数量,其中随机翻转包括水平翻转、垂直翻转和水平垂直翻转;
对经过随机翻转处理后的数据集图片采用伽马变换处理,以实现图片颜色增强;
对经过伽马变换处理后的数据集中正样本通过smote算法进行数据增广。
进一步的,所述吸烟卷积神经网络输入为样本rbg图片,吸烟卷积神经网络首先是包含2个卷积层的卷积网络,接着是多个残差模块,相邻残差模块之间为包含1个卷积层的降采样层,然后用3个卷积层作为全连接层,最后通过softmax进行分类。
进一步的,所述吸烟卷积神经网络头两层卷积层均设计有四种大小的卷积核,且卷积层中每条卷积路径还经过批量标准化处理和relu激活函数处理,其中批量标准化处理的公式如下:
其中t为每一个训练批次数据,e[t]为每一个训练批次数据t的均值,var[t]为每一个训练批次数据t的方差,,是为了避免除数为0时所使用的微小正数。φ是尺度因子,,是平移因子。
进一步的,所述残差模块包括两层卷积层,设残差模块的输入为u,经过两层卷积处理后,每层卷积还要经过批量标准化处理和relu激活函数处理,两层卷积记为f(·),则残差模块的输出为q(u)=u+f(u)。
进一步的,通过最小化损失函数来更新网络参数,其中损失函数计算如下:
其中,(xi,yi,wi,hi)是对数据集标注的参考标准groundtruth在图片中的位置以及大小,
进一步的,保存可用模型的保存方式有三种,分别为完整地保存整个模型、分别保存模型的结构和权重和保存模型图。
本发明的有益效果是:本发明通过采集并标注吸烟行为,能够完善吸烟行为检测数据集的制作流程,丰富吸烟行为检测数据集的种类和数量;而且设计针对吸烟行为检测的吸烟卷积神经网络,能够更加准确地提取检测对象的特征,而且结合批量标准化和relu激活函数处理,能够防止网络过拟合;此外,还采用了残差模块结构,能够抑制网络训练过程中的梯度弥散和梯度爆炸问题,提高网络性能;另外通过数据预处理,不仅增加了数据集的数量,还对数据集进行了统一处理,去除了大量噪声,提高网络训练效果。总之,本发明结合深度学习对吸烟行为进行检测,能够具备良好的准确度和检测实时性,解决了现有技术中对于吸烟行为检测的准确度不高、繁华能力不强等问题。
附图说明
图1是本发明实施例提供的基于深度学习的吸烟行为实时检测方法的流程图;
图2是构建的吸烟卷积神经网络的结构图;
图3是吸烟卷积神经网络的头两层卷积层的结构图;
图4是残差模块的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为了说明本发明所述的技术方案,下面通过具体实施例来进行说明。
如图1所示,本实施例提供的基于深度学习的吸烟行为实时检测方法包括下述步骤:
步骤s1、采集并标注吸烟行为数据得到数据集,包括训练样本集、验证样本集和测试样本集,每个样本集均分为正样本和负样本。
本步骤主要实现吸烟行为数据集的构建,通过采集标注吸烟数据,得到训练阶段的训练样本集和验证样本集,以及测试阶段的测试样本集。样本集分为正样本和负样本。这里正样本是吸烟行为的图片,负样本是无吸烟行为的图片。
对于制作正样本数据,正样本是包含吸烟行为的图片,为了保证数据的多样性,这样训练处的模型准确度更高。本实施例中,正样本图片具有以下特性:
a)图片应具有时间跨度,一天中的时间会影响图片画质;
t={t1、t2},t1∈白天、t2∈夜晚
b)图片应包含多种天气,天气情况会影响画面的光线;
w={w1、w2、w3、w4}
w1:晴天、w2:雨天、w3:雪天、w4:阴天。
c)图片应具有丰富的人群密度,包括人多、人少多种情况;
q={q1、q2、q3}
q≤q1:低人群密度图片,q≤q2:中人群密度图片,q≤q3:高人群密度图片。
d)图片应包含不同地理位置,使得图片具有丰富的背景;
l={l1、l2},l1∈乡村、l2∈城市
e)图片中目标对象距离应该不同,包括远、中、近多距离;
d={d1、d2、d3}
d≤d1:近距离图片,d≤d2:中距离图片,d≤d3:远距离图片。
f)图片质量清晰,不可损坏或模糊;
g)图片应该具有真实性,不应该有卡通、漫画等超现实内容;
h)图片大小适中,大小在416*416或512*512左右;
i)图片的数量应该与现有大型数据集同数量级,数量直接影响算法的泛化能力,正样本应该具有丰富数量的图片。
对于正样本数据的采集来源,主要是从网络中获取吸烟行为的图片或者视频,比如通过搜索引擎关键词搜索,具体地,可以使用如下关键词:cigarette、smoking、烟、吸烟等,可以使用爬虫软件从网页上爬取这些关键词搜索出来的图片;另外,也可以从视频观看器等频道录制网络吸烟视频;最后,可以使用手机、摄像机从室外录制相应自然吸烟行为或者拍摄演员演绎吸烟行为,也可以从吸烟室等场所的录像带中拷贝。当然如果条件允许,可以直接从现有吸烟行为数据集中整合出图片或者视频。
通过以上方式得到吸烟视频和吸烟图片后,使用标注工具进行标注,可以使用计算机视觉库opencv开发图片标注工具,该屏幕标注工具包含一个候选框,可以手动调整其大小,标注目标在图片中的左上角位置坐标以及右下角位置坐标,并保存到本地磁盘中。由于本实施例设计的卷积神经网络中的输入为正方形图片,因此,本实施例候选帧屏幕快照工具的应为正方形,保存的训练图片都是长宽比为1:1的所有图片,最后制作d1份吸烟行为正样本。
对于制作负样本数据,负样本是与正样本背景相近但不包含香烟目标的图片,本实施例中,负样本具有如下特性:
1、图片覆盖背景广泛不单一,并且应与正样本背景具有相似性;
2、图片质量清晰,不可损坏或模糊;
3、图片应该具有真实性,不应该有卡通、漫画等超现实内容;
4、图片大小适中,大小在416*416或512*512左右;
5、图片应该是rgb图像,不应该是黑白图片或cmyk图片;
6、图片数目充足,保证正负样本比例控制在1:3左右。
负样本来源可以从影视作品、网络视频提取帧,或者从网站搜取、从现有数据集中整合。另外在制作正样本过程中,保存无目标图片作为负样本。负样本中不包含吸烟行为,但是包含与正样本相近的图片,获取数量为d2的负样本。
经过上述要求进行吸烟数据采集和标注后,得到训练阶段的训练样本集和验证样本集,以及测试阶段的测试样本集。测试样本集既包含上述正样本,又包含上述负样本。训练阶段的图片数量与测试阶段的图片数量以4:1的比例随机分配,训练阶段的训练样本和验证样本以3:1的比例随机分配。即整个数据集的样本数量为d=d1+d2,将d分为三个部分:训练样本集、验证样本集、测试样本集,训练样本集数量为0.6*d,验证样本集数量为0.2*d,测试样本集数量为0.2*d。
步骤s2、根据吸烟行为数据集特点对数据集预处理,包括数据增广处理、数据集标准化处理和数据集归一化处理。
所述数据增广是指对数据集中的图片进行扩增,具体的,数据增广处理包括下述步骤:
s21、随机翻转。对数据集中的每张图片随机翻转以扩增数据集图片数量,其中随机翻转包括水平翻转、垂直翻转和水平垂直翻转。
本实施例采用随机翻转来扩增数据集的图片数目。本实施例数据集d中的每一张图片以1/3的概率进行三种形式之一的翻转:水平翻转、垂直翻转、水平垂直翻转。
水平翻转是指,沿着图片中垂线进行左右像素对称互换,具体地,对于一个rgb图片,水平翻转时,对某一通道上的像素矩阵变化公式如下:
a(x,y)=a(x,w-y)
其中w为图片宽度。
垂直翻转是指,图片沿着水平中心线进行上下像素对称互换,对于一个rgb图片,垂直翻转时,对某一通道上的像素矩阵变化公式如下:
a(x,y)=a(h-x,y)
其中h为图片的高。
水平垂直翻转是指,图片先沿着中垂线进行左右像素对称互换,然后再沿着水平中心线进行上下像素对称互换,生成一个新的图片,具体地,对于一个rgb图片,水平垂直翻转时,对某一通道上的像素矩阵变化公式如下:
a(x,y)=a(h-x,w-y)
一张图片以等概率的方式进行以上3种方式随机翻转,从而生成新的图片。
s22、颜色增强。对经过随机翻转处理后的数据集图片采用伽马变换处理,以实现图片颜色增强。
本步骤采用伽马变换来变换图片的亮度,对于一个rgb图片采用如下方式转换为灰度图像:
bgrey(x,y)=0.2989*ar(x,y)+0.5870*ag(x,y)+0.1140*ab(x,y)
其中,ar(x,y)是r通道上的像素矩阵,ag(x,y)是g通道上的像素矩阵,ab(x,y)是b通道上的像素矩阵,经计算后得到一个单维度的二维矩阵bgrey(x,y),即为该图片的灰度值。
对获取的灰度图像的像素归一化到[0,1]范围,采用如下伽马变换公式:
cgamma(x,y)=bgrey(x,y)γ
其中γ大于1时,图像整体变暗;γ小于1时,图像整体变亮;不断变化γ即可获取不同亮度的图片。
s23、通过smote算法增加图片数量。对数据集中的正样本实行smote算法进行数据增广。具体过程如下:
1)从正样本中随机抽取若干样本形成子样本集,对子样本集中的每一个样本x,通过如下公式计算它到子样本集中所有其它样本的距离:
其中,(xi1,yi1)是样本x在r、g、b三个通道上的像素值,(xi2,yi2)是其它样本在r、g、b三个通道上的像素值。选取距离样本x最近的k个样本,从k个近邻样本中随机选取n个样本。
2)对于随机选出的n个近邻样本,分别与原样本x按照如下公式构建新的样本并添加到数据集中:
y=x+rand(0,1)*||x=xn||
其中rand(0,1)为0到1区间的一个随机数,xn为从k个近邻样本中当前随机选取的样本,y为构建后的新样本。
经过上述数据增广处理后,数据集得到一定数量的扩增,得到新的数据集m,然后对数据集m进行标准化处理和归一化处理。
数据集m进行标准化采用如下公式:
其中,x表示图片矩阵,μ是图片的均值,σ是图片的标准差,n是图片x的像素数目。
数据集m进行归一化采用如下公式:
其中,xi表示图片像素点值。
步骤s3、结合深度学习并根据吸烟行为特点,构建检测吸烟行为的吸烟卷积神经网络。
本步骤结合深度学习的方法,根据吸烟行为的特点,构建了一个针对吸烟行为检测的吸烟卷积神经网络smokingnet。如图2所示,本实施例中,吸烟卷积神经网络smokingnet输入为样本rgb图片,本实施例为416*416的rgb图片,吸烟卷积神经网络首先包含2个卷积层的卷积网络;接着是5个残差模块residualblock,5个残差模块的长度分别是:1、2、4、4、2;残差模块之间,包含1个卷积层,可以视为降采样层,使得特征维度下降,总共4个这样降采样层;然后用3个卷积层当做全连接层,其中最后一层全连接层特征图谱的数目为:
featuremaps=(classes+1+coords)*anchors_mum
其中,classes是目标类别,coords值为4,anchors_num值为3。
最后,通过softmax进行分类。
结合图2、3所示,吸烟卷积神经网络smokingnet的头两层为两层卷积层,卷积层的卷积核用于提取给定图像的局部特征,本步骤为了提高对吸烟行为的检测,采用多卷积核的吸烟卷积神经网络。经典的卷积核为正方形,而香烟为条形,因此本实施例根据香烟的形状特征,使用长卷积核,在吸烟卷积神经网络smokingnet的第一层卷积层中设计四种大小的卷积核,如图2、3所示,四种大小的卷积核分别为:3*3像素的小卷积核、5*5像素的大卷积核、7*3长卷积核、3*7长卷积核,分成4条路径进行卷积。具体的,第一条路径是滤波器filter数目为8的5*5卷积,使用2*2填充padding,步长为1*1;第二条路径是filter数目为8的3*7卷积,使用1*3padding,步长为1*1;第三条路径是filter数目为8的3*3卷积,使用1*1padding,步长为1*1;第四条路径的filter数目为8的7*3卷积,使用3*lpadding,步长为1*1;最后将四条路径卷积后的特征图谱featuremap整合,得到416*416*32的输出。
吸烟卷积神经网络smokingnet的第二层卷积层中同样设计四种大小的卷积核,分别为2*2像素的小卷积核、6*6像素的大卷积核、6*2长卷积核、2*6长卷积核,分成4条路径进行卷积。具体的,第一条路径是filter数目为12的6*6卷积,使用2*2padding,步长为2*2;第二条路径是filter数目为12的2*6卷积,使用0*2padding,步长为2*2;第三条路径是filter数目为12的卷积,使用0*0padding,步长为2*2;第四条路径的filter数目为12的6*2卷积,使用2*0padding,步长为2*2;最后将四条路径卷积后的特征图谱featuremap整合,得到208*208*64的输出。
进一步作为一种优选方式,如图3所示,头两层卷积层中还增加bn(batchnormalization,批量标准化)和relu激活函数,即图示中每条卷积路径还经过rn+relu处理。
批量标准化算法计算公式如下:
该算法主要包含4步:
(1)求每一个训练批次数据t的均值,即e[t];
(2)求每一个训练批次数据t的方差,即var[t];
(3)使用求得的均值和方差对该批次的训练数据做归一化,获得0到1的区间分布,其中中是为了避免除数为0时所使用的微小正数;
(4)尺度变换和偏移:将t乘以φ调整数值大小,再加上上增加偏移后得到r,这里的φ是尺度因子,,是平移因子。由于归一化后的基本会被限制在正态分布下,使得网络的表达能力下降,为解决该问题,引入两个新的参数:φ,,。φ和和是在训练时网络自己学习得到。
批量标准化处理之后使用relu激活函数进行非线性变换,relu激活函数是现有函数,这里不赘述。
本实施例还在吸烟卷积神经网络smokingnet中引入残差网络,形成残差模块residualblock,如图、4所示,残差模块包括两层卷积层,假设残差模块的输入为u,经过两层卷积处理,每层卷积还要经过bn+relu处理,两层卷积记为f(·),则residualblock的输出为:
o(u)=u+f(u)
相邻残差模块之间还有1层卷积层以实现对特征图谱的大小减半,本实施例使用3*3卷积核进行步长为2*2的卷积操作,对图像的填充为1*1。假设输入特征图谱大小记为h*h,卷积核大小记为k*k,步长记为s*s,填充记为p*p,则输出特征图谱的大小为:
步骤s4、设置吸烟卷积神经网络的网络训练参数并进行训练,得到网络模型后对测试样本集进行平均准确度计算,实现对模型结果进行验证。
通过吸烟卷积神经网络可以从图片中提取特征并根据特征获取检测目标的位置,根据如下公式计算损失函数:
其中,(xi,yi,wi,hi)是对数据集标注的参考标准groundtruth在图片中的位置以及大小,
比如,输入图片大小统一为416*416,将分配好的训练样本输烟卷积神经网络网络中进行批次训练,一个批次包含64张图片,在一个批次中分8次送入网络中进行训练,每次送8张,然后每完成一个批次的训练就更新一次权重参数,本发明实施例中每一次学习的过程中,将学习后的参数按照0.0005比例进行降低。在进行动量法更新权重时,momentum设置为0.9,初始学习率设置为0.001,总训练次数设置为100000,迭代到80000时,学习率衰减十倍,迭代到90000时,学习率再衰减十倍。
将训练后得到网络模型后对测试样本集数据进行平均准确度map的计算,来对模型结果进行验证,具体计算步骤如下:
1、对于网络模型对图片中目标的位置预测结果,结合测试样本集中的标注框计算iou,设置阈值thred=0.6,iou>thred为tp(真正例),iou<thred为fp(假正例),对于未检测到的标注框记为fp(假负例);再根据如下公式计算准确率recall和召回率precision:
其中numgt是groundtruth的总数量。
2、绘制每个类别的precision-recall曲线,曲线下面积就是该类别的ap值,再根据如下公式计算map:
步骤s5、按要求生成并保存可用模型,使用保存好的可用模型即可应用到吸烟行为检测现实场景中。
训练完成后,可用以下几种方式保存模型:
a)完整地保存整个模型
使用model.saveapi完整地保存整个模型,将keras模型和权重保存在一个hdf5文件中,该文件将包含:模型的结构、模型的参数、优化器参数。
b)分别保存模型的结构和权重
只保存模型的结构:使用to_jsonapi或者to_ymlapi将模型结构保存到json文件或者yml文件。
只保留模型的权重:只保留模型的权重可以通过save_weightsapi实现,也可以通过检查点checkpoint的设置实现。
c)保存模型图
可以通过model.summaryapi打印模型的概述信息,通过模型的概述信息可以知道模型的基本结构。
选择map值最大的模型进行应用,具体地,将摄像头中视频流的图片输入网络中进行目标定位和预测,当对有多张图片检测到吸烟行为目标时,可以判定此时摄像头关注范围内出现吸烟行为。
综上,本发明提出一套基于深度学习的实时检测方法,首先构建吸烟行为数据集采集和标注,然后根据吸烟行为数据集的特点,进行图片预处理,包括数据增广、数据集的统一标准化和归一化;其中数据增广包括使用随机翻转、颜色增强、smoe算法进行数据增广;接着针对检测对象的特征,设计了一个多卷积核的吸烟卷积神经网络smokingnet,能够多方面提取检测对象特征,并且该网络结合bn技术和residualblock,能够提升网络性能;然后对网络训练过程中的参数设置和训练;最后安装方案要求保存模型,使用保存好的模型即可应用到现实场景中。本发明能够有效地制作吸烟行为检测数据集,生成具有高精度高实时性的吸烟行为检测模型,具有广阔的应用前景。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!