一种基于混合型特征选择的新钻井潜力评价方法与流程
本发明属于地球物理勘探领域和人工智能领域,具体涉及一种基于混合型特征选择的新钻井潜力评价方法。
背景技术:
分析已开发油田历史的数据信息,对油田的新钻井潜力进行评价,可以指导未来几年的新井投产状况,显著提高老油田的采收率和扩大已探明资源的利用率。与油田新钻井潜力评价相关的历史数据特征繁多,且关系复杂,使用单一属性无法反映新钻井潜力变化规律,多属性之间存在冗余等状况无法直接使用。利用属性分析技术能够有效地分析多种属性之间的相互关系,提取与新钻井潜力评价相关度高的特征组合,进而利用多属性反映新钻井潜力变化规律。
传统新钻井潜力评价一般仅考虑累产油量等几种相关因素进行估量,难以充分考虑影响新钻井潜力评价的诸多因素,在地质状况复杂的区域下,评价的结果存在偏差。随着计算机技术的高速发展,引入特征选择的相关知识分析属性之间的相关性已经越来越普遍,通过对油田开发历史数据进行特征选择,去除与新钻井潜力评价不相关以及冗余的油田开发历史数据特征,保留相关度大的数据特征。在充分考虑影响新钻井潜力评价的诸多因素情况下,采用支持向量回归机方法挖掘油田开发历史数据深层信息,实现新钻井潜力评价。
技术实现要素:
为了克服传统新钻井潜力评价方法无法充分考虑影响因素,导致评价结果存在偏差的问题,本发明提出了一种基于混合型特征选择的新钻井潜力评价方法,通过过滤式选择算子分析油田开发历史数据每维特征对新钻井潜力评价相关性影响,指导遗传算法对油田历史数据中最优特征组合的选择,并加入精英选择机制,增加对相关度大的油田历史数据特征组合的搜索精度,结合支持向量回归机进行深层信息挖掘,实现新钻井潜力评价。
为实现上述目的,本发明技术方案主要包括如下步骤:
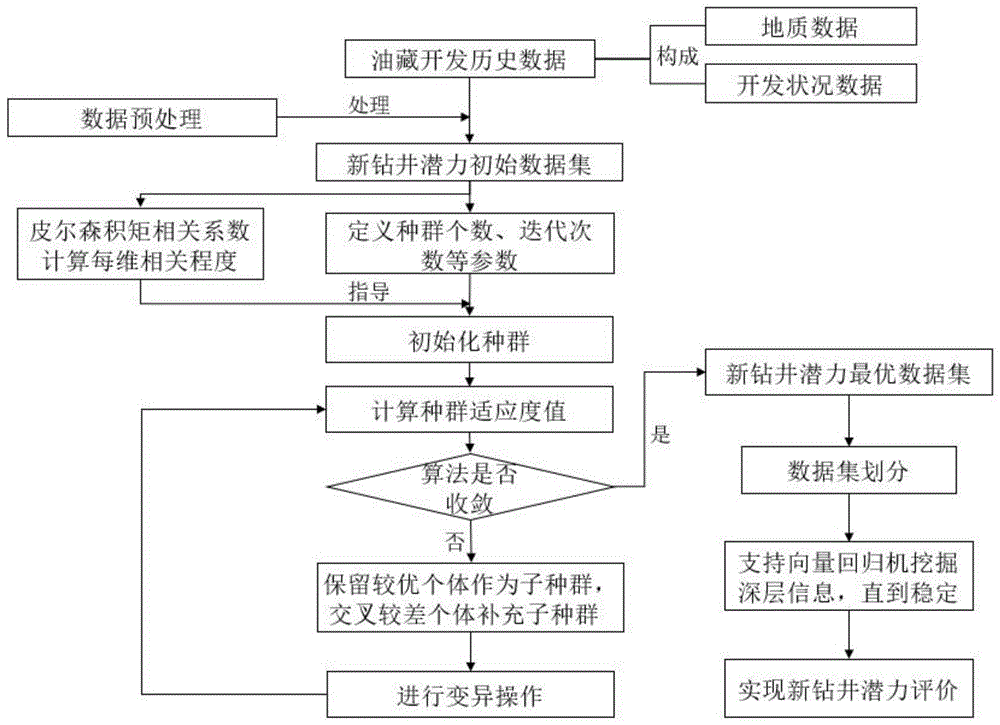
从地震数据库、油藏历史数据库等数据源中提取油藏开发历史数据以及区块新投产井数据。根据区块新投产井数据中历史区间内新投产井数,计算区块新钻井潜力评价值。合并油藏历史数据和区块新钻井潜力评价值,预处理后得到带有标记的新钻井潜力初始数据集。
a.采用混合型特征选择方法提取最优特征组合:
(1)利用皮尔森积矩相关系数计算新钻井潜力初始数据集中每维特征对新钻井潜力评价影响的相关程度,记为r值,r值介于-1到1之间,绝对值越大代表相关性越强,根据皮尔森积矩相关系数对每维属性赋予权重,权重大小与相关系数呈正比;
(2)新钻井潜力初始数据集中特征维数为n,设置遗传算法中种群个数为m,变异概率为p,最大迭代次数为t,采用长度为d的染色体x对特征组合进行编码,其中编码为0表示油藏历史数据中对应位置的特征被选中,编码为1表示油藏历史数据中对应位置的特征未被选中。采用轮盘赌方式对加权属性进行抽取,生成初始种群s。将个体x所代表的特征组合作为输入,以深度信念网络的评价结果的平均绝对误差的修正值mae(x)作为适应度函数f;
(3)计算种群中全部个体的适应度值fi,将种群中的个体按照其适应度值大小进行降序排序。选择种群中适应度值较大的一半个体构成子种群a,适应度值小的一半个体构成子种群b;
(4)采用单点交叉的方式,对选择出的种群a和种群b进行交叉操作构成种群c,将a和c中的个体混合到一起,生成子代种群s′;
(5)按照变异概率p随机选择种群中个体进行变异操作;
(6)重复步骤(3)-(5),直到满足最大迭代次数或者达到设置的阈值。选取适应度值最大的个体xmax,xmax对应的染色体编码值为油田历史数据最优特征组合,按照油田历史数据最优特征组合提取对应特征,得到新钻井潜力最优数据集。
b.采用支持向量回归机评价新钻井潜力
(1)将新钻井潜力最优数据集随机划分训练样本集、测试样本集与验证样本集,划分的比例为7:2:1。
(2)采用支持向量回归机方法挖掘训练样本集数据深层信息,直到效果稳定收敛,以平均绝对误差作为评价标准,在测试样本集上测试支持向量回归机的评价效果;
(3)保留验证样本集,重新划分训练样本集与测试样本集,重复(2)过程。对比多个支持向量回归机评价效果,保留平均绝对误差最小的支持向量回归机,将支持向量回归机处理待评价区块数据,实现新钻井潜力评价。
本发明的有益效果是:过滤式选择算子计算每维特征对新钻井潜力评价相关性影响,加快特征选择的执行速度,并指导油田历史数据最优特征组合的选择;在遗传算法中加入精英选择机制,每次迭代过程中保留一部分适应度值较大的个体,增加对相关度大的油田历史数据特征组合的搜索精度,增加新钻井潜力评价的准确度。
附图说明
图1是本发明的模型结构图
具体实施方式
下面结合图1对本发明作进一步详细的描述:
从地震数据库、油藏历史数据库等数据源中提取油藏开发历史数据以及区块新投产井数据,油藏开发历史数据包括油藏地质参数和开发状况数据。根据区块新投产井数据中历史区间内新投产井数,标记区块新钻井潜力评价值。合并油藏历史数据和区块新钻井潜力评价值,预处理后得到带有标记的新钻井潜力初始数据集。
a.采用混合型特征选择方法提取最优特征组合:
(1)特征相关性预分析
利用皮尔森积矩相关系数计算新钻井潜力初始数据集中特征对新钻井潜力评价影响的相关程度,记为r值,r值介于-1到1之间,绝对值越大代表相关性越强。根据皮尔森积矩相关系数的绝对值对每维属性赋予权重,权重大小与相关系数呈正比,r值计算公式:
其中,mi为特征值,
(2)种群初始化
油藏历史数据中特征维数为n,设置遗传算法中种群个数为m,变异概率为p,最大迭代次数为t,采用长度为d的染色体x对特征组合进行编码,其中编码为0表示油藏历史数据中对应位置的特征被选中,编码为1表示油藏历史数据中对应位置的特征未被选中。采用轮盘赌方式对加权属性进行抽取,初始化种群s={x1,x2,…,xm}。将个体x代表的特征组合作为输入,以深度信念网络的评价结果的平均绝对误差的修正值mae(x)作为适应度函数f;
(3)选择操作
计算种群中全部个体的适应度值fi,fi=mae(xi),f=1,2,...,m,将种群中的个体按照其适应度值大小进行降序排序{x′1,x′2,…,x′m},x′i表示排序数为i的个体。选择种群中适应度值较大的一半个体构成子种群a={x′1,x′2,…,x′m/2},适应度值小的一半个体构成子种群b={y′1,y′2,…,y′m/2};
(4)交叉操作
交叉操作以设置的交叉概率为基准,交换任意两个染色体的部分基因。本发明在迭代过程中保留当次迭代中较优个体作为下代种群,并选择较差个体的子种群与最优个体的子种群进行交叉操作,将交叉产生的新个体与较优个体的子种群重新构成新种群,从而在保留较优个体的同时,提高了算法全局搜索能力。
具体步骤如下:
采用单点交叉的方式,对选择出的种群a和种群b进行交叉操作构成种群c={z′1,z′2,…,z′m/2},将a和c中的个体混合到一起,生成子代种群s’={x′1,x′2,…x′m/2,z′1,z′2,…z′m/2};
(5)变异操作
变异操作是以设置的变异概率为基准,对某个染色体或者染色体上某段基因进行突变,本发明按照变异概率p使得个体发生变异,形成新个体;
(6)重复步骤(3)-(5),直到满足最大迭代次数或者达到设置的阈值,说明目前种群已趋于稳定不再进化,停止运算。选择适应度值最大的个体xmax,xmax对应的染色体编码值为油田历史数据的最优特征组合,按照油田历史数据最优特征组合提取对应特征,得到新钻井潜力最优数据集。
b.采用支持向量回归机评价新钻井潜力
(1)将新钻井潜力最优数据集以区块为单位随机划分训练样本集、测试样本集与验证样本集,划分的比例为7∶2∶1;
(2)采用支持向量回归机挖掘训练样本集数据深层信息,直到效果稳定收敛,以平均绝对误差作为评价标准,在测试样本集上测试支持向量回归机评价效果;
(3)保留验证样本集,重新划分训练样本集与测试样本集,重复(2)过程。对比多个支持向量回归机评价效果,保留平均绝对误差最小的支持向量回归机,将支持向量回归机处理验证样本集,实现区块的新钻井潜力评价。
以上所述,仅是本发明的较佳实施例,任何熟悉本专业的技术人员可能利用上述阐述的技术方案加以改型或变更为等同变化的等同实例。凡未脱离本发明技术方案内容,依据发明的技术方案对上述实施例进行的任何简单修改、变更或改型,均属于发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!