基于注意力机制的点击率预测方法与流程
本发明涉及互联网应用技术领域,特别涉及一种基于注意力机制的点击率预测方法。
背景技术:
随着互联网信息的爆炸性增长,计算机科学领域尤其是人工智能技术也取得了巨大的进步。作为计算机科学和应用科学的一个分支,它主要研究如何利用机器来模拟、延伸和扩展人类大脑的思维过程(比如记忆、学习、推理和决策)。目前人工智能技术己经成功应用于自动驾驶、医疗诊断、语言识别、图像识别、金融大数据等诸多领域。
尽管目前工业界对点击率预估有较深入的研究,但是这些模型也存在的一些问题,如数据量大、数据稀疏等,目前工业界还是偏于使用浅层的模型来解决,因为使用复杂模型难以训练、不易部署到生产环境中及解释性弱等缺点,使用浅层模型将更多的注意力专注于人工构造特征及一些特征间简单的运算等方式构造显性的组合特征来提高点击率预估模型的性能,并没有深度的挖掘数据间隐性的组合特征和特征内在的那些高度非线性关系等隐含信息,所以对于广告点击率预估问题还有很大的研究意义。现在应用比较广的算法通常是gbdt+lr模型,wide&deep模型。但是这些模型存在需要人工提取特征,无法提取高维度的特征组合的问题。而一些能自动提取的模型,如deepfm模型等都存在训练方式是隐式特征,容易导致维度过高的问题。目前虽然deep&cross模型可以解决这个问题,但是deep&cross模型是属于元素级别的交互,它并不能很好的表示特征交互向量。
技术实现要素:
本发明提供了一种基于注意力机制的点击率预测方法,其目的是为了解决传统模型需要人工提取特征,无法提取高维度的特征组合,容易导致维度过高的问题。
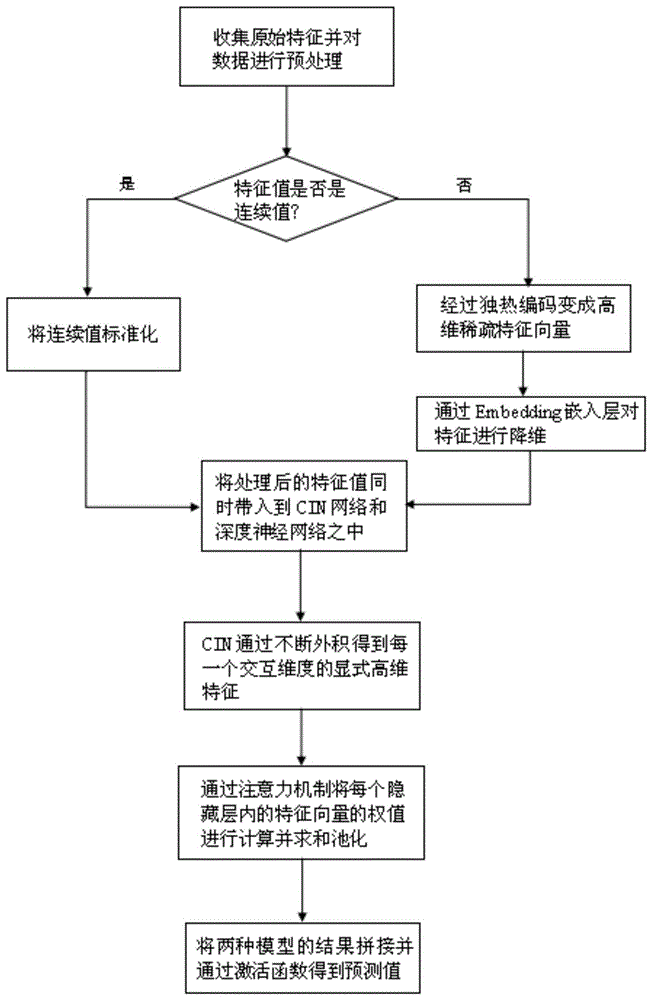
为了达到上述目的,本发明的实施例提供了一种基于注意力机制的点击率预测方法,包括:
步骤1,对用户的特征进行预处理,将同一类用户特征进行one-hot独热编码,得到一个高维度的稀疏特征向量;
步骤2,将高维度的稀疏特征向量通过嵌入向量对特征向量进行降维,将降维后的特征向量作为点击率模型的输入向量分别带入到压缩交互网络和深度神经网络之中;
步骤3,将输入的初始特征向量与每一个隐藏层的输入向量进行哈达玛积,将得到的结果作为下一个隐藏层输入值,每多一个隐藏层,特征之间的组合就上升一个维度;
步骤4,将每层得到的结果向量经过自注意力机制得到有用的组合特征,对组合特征进行求和池化;
步骤5,将池化后的结果与深度神经网络得到的结果简化拼接成新的特征向量并带入到输出层得到预测值。
其中,所述步骤1具体包括:
收集用户特征的数据集ⅹ={x1,x2,……xn}为总的训练样本数量,xi∈{x1,x2,……xn},xi表示第i个待处理的用户特征数据。
其中,所述步骤1还包括:
利用独热编码将用户特征转化成一个高维稀疏特征向量。
其中,所述步骤2具体包括:
通过一个嵌入层向量来转化成低维的组合特征,将稀疏的向量映射到相对稠密且向量元素都不为零的空间向量中。
其中,所述步骤2还包括:
通过标准化的方法将原始数据处理成均值为0,方差为1的数据,标准化之后的数据使用xnorm表示,具体计算公式如下:
其中,x表示连续值数据,μ表示原始数据的方差,σ表示原始数据的均值。
其中,所述步骤3具体包括:
根据嵌入层得到的特征向量,将特征向量拼接成一个m×d的矩阵,其中,m是特征向量的个数,d是特征向量的维度,xk表示压缩交互网络中第k层隐层的状态,
其中,1≤h≤hk,
其中,所述步骤4具体包括:
通过将每一层经过向量交互的结果通过自注意力机制将不同的交互向量赋予不同的权值,将结果通过求和池化得到高维交互结果。
其中,所述步骤5具体包括:
将嵌入层的向量带入到深度神经网络之中,得到经过多层交互之后的结果,将深度神经网络得到的结果与压缩交互网络得到的结果压缩拼接成一个新的矩阵并带入到单层感知机之中得到最终的结果,输出结果公式如下所示:
其中,σ是sigmoid函数,xf是原始特征,
其中,所述步骤5还包括:
通过损失函数与梯度下降不断更新模型的权值参数,损失函数的公式如下所示:
其中,
其中,λ表示正则项,θ表示参数集,包括线性部分,cin部分和dnn部分中的参数。
本发明的上述方案有如下的有益效果:
本发明的上述实施例所述的基于注意力机制的点击率预测方法,通过将embedding层之后的稠密向量经过类似于残差网络的交互,将多次交互得到的结果通过自注意力机制进行求和池化,通过将深度神经网络的结果与压缩交互网络的结果拼接成一个新的向量,将新的向量输出得到结果,预测的结果更加准确和可靠,综合考虑了用户的低维特征、显式高维特征和隐式高维特征,通过注意力机制筛选有用的特征组合,提高预测效率,不需要人工提取特征,可以提取高维度的特征组合,不容易导致维度过高。
附图说明
图1为本发明的流程图;
图2为本发明的模型结构图;
图3为本发明的每一层交互网络的示意图;
图4为本发明的自注意力机制求和池化示意图;
图5为本发明的实验结果图;
图6为本发明的不同的网络层数对实验结果的影响示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明针对现有的模型需要人工提取特征,无法提取高维度的特征组合,容易导致维度过高的问题,提供了一种基于注意力机制的点击率预测方法。
如图1至图6所示,本发明的实施例提供了一种基于注意力机制的点击率预测方法,包括:步骤1,对用户的特征进行预处理,将同一类用户特征进行one-hot独热编码,得到一个高维度的稀疏特征向量;步骤2,将高维度的稀疏特征向量通过嵌入向量对特征向量进行降维,将降维后的特征向量作为点击率模型的输入向量分别带入到压缩交互网络和深度神经网络之中;步骤3,将输入的初始特征向量与每一个隐藏层的输入向量进行哈达玛积,将得到的结果作为下一个隐藏层输入值,每多一个隐藏层,特征之间的组合就上升一个维度;步骤4,将每层得到的结果向量经过自注意力机制得到有用的组合特征,对组合特征进行求和池化;步骤5,将池化后的结果与深度神经网络得到的结果简化拼接成新的特征向量并带入到输出层得到预测值。
其中,所述步骤1具体包括:收集用户特征的数据集ⅹ={x1,x2,……xn}为总的训练样本数量,xi∈{x1,x2,……xn},xi表示第i个待处理的用户特征数据。
其中,所述步骤1还包括:利用独热编码将用户特征转化成一个高维稀疏特征向量。
本发明的上述实施例所述的基于注意力机制的点击率预测方法,独热编码的编码方式比较简单,按照n位状态寄存器来对n个状态进行编码,如用户的基本信息为user=[用户id=02,性别=男,兴趣爱好=摇滚],根据独热编码的定义转化成的向量就变成user=[0,1,0,…,0][1,0][0,1,0,…,0]这样的由0和1构成的向量。
其中,所述步骤2具体包括:通过一个嵌入层向量来转化成低维的组合特征,将稀疏的向量映射到相对稠密且向量元素都不为零的空间向量中。
其中,所述步骤2还包括:通过标准化的方法将原始数据处理成均值为0,方差为1的数据,标准化之后的数据使用xnorm表示,具体计算公式如下:
其中,x表示连续值数据,μ表示原始数据的方差,σ表示原始数据的均值。
本发明的上述实施例所述的基于注意力机制的点击率预测方法,针对one-hot编码存在特征维度过高的特点,通过一个嵌入层向量来转化成低维的组合特征,把稀疏的向量映射到相对稠密且向量元素都不为零的空间向量中,对于嵌入向量来说,初始的嵌入特征是随机数字生成的,通过梯度下降不断地迭代,最终得到准确的嵌入向量值,对于连续值来说,特征值需要经过归一化处理,具体来说就是通过标准化的方法将原始数据处理成均值为0,方差为1的数据,标准化的方法会改变原始数据的分布,对异常值不敏感,适合大数据场景。
其中,所述步骤3具体包括:根据嵌入层得到的特征向量,将特征向量拼接成一个m×d的矩阵,其中,m是特征向量的个数,d是特征向量的维度,xk表示压缩交互网络中第k层隐层的状态,
其中,1≤h≤hk,
本发明的上述实施例所述的基于注意力机制的点击率预测方法,两个向量间对应位元素的乘积操作,例如,
其中,所述步骤4具体包括:通过将每一层经过向量交互的结果通过自注意力机制将不同的交互向量赋予不同的权值,将结果通过求和池化得到高维交互结果。
本发明的上述实施例所述的基于注意力机制的点击率预测方法,因为向量交互存在时间复杂度过高的缺陷,通过将每一层经过向量交互的结果通过自注意力机制将不同的交互向量赋予不同的权值,可以节省大量的时间。
其中,所述步骤5具体包括:将嵌入层的向量带入到深度神经网络之中,得到经过多层交互之后的结果,将深度神经网络得到的结果与压缩交互网络得到的结果压缩拼接成一个新的矩阵并带入到单层感知机之中得到最终的结果,输出结果公式如下所示:
其中,σ是sigmoid函数,xf是原始特征,
其中,所述步骤5还包括:通过损失函数与梯度下降不断更新模型的权值参数,损失函数的公式如下所示:
其中,
其中,λ表示正则项,θ表示参数集,包括线性部分,cin部分和dnn部分中的参数。
本发明的上述实施例所述的基于注意力机制的点击率预测方法,模型训练及预测的实验部分采用了业界的公开数据集:大型的广告点击率预测criteo数据集和基于上下文的app推荐frappe数据集。criteo数据集总共包含大小11gb的连续7天的用户行为日志,大约有4100万条历史记录,每一条训练样本均包括39个不同字段的数据特征,其中,第一维11到第13维113为连续值匿名特征,c1到c26为离散值匿名特征,将这些经过脱敏处理的匿名特征主要包括用户特征、物品特征及环境特征,对于每个字段特征的具体含义是透明的。另外一个数据集是基于上文下的app推荐frappe数据集,每一条日志除了用户id、物品id之外包含8个上下文的类别特征,比如天气、城市、时间等,frappe数据集中包含10个字段的特征c1-c10,全部都属于类别特征,没有数值特征,frappe数据集规模相对小一些,一共有288609条训练样本。
将criteo数据集和frappe数据集随机取1/10的数据作为验证集,剩余数据作为训练集。所述基于注意力机制的点击率预测方法实验环境是基于tensorflow3+python3.6来实现,通过在验证集上执行网格搜索的方式为每个模型找到一组最优的超参数。优化方法为adam,学习率是0.001,批处理大小是4096,使用系数为0.0001的l2正则化,默认的隐藏节点个数:1.dnn输出层中为400;2.cin输出层在criteo数据集上为200,在frappe数据集上是100,对于deep&cross中的crossnet和cin模型,因为数据的不同,将通过改变隐藏层的深度进行实验,并将每个模型最好的实验结果进行比较。
如图5所示,所述的基于注意力机制的点击率预测方法(our’s)于其他模型实验结果的比较,从实验结果可以看出,lr模型是所有模型中表现最不好的一个,因为lr模型只能处理一些简单的低维度的特征组合,这说明对稀疏的数据通过深度学习的方法提取出其中的隐式特征是非常有必要的;其他的通过深度学习训练的模型如pnn、wide&deep、deepfm、deep&cross,比fm模型的效果要好,说明真实的数据特征一般都是非常复杂的,像fm模型只能处理二维特征的并不能很好地处理三维以上的特征,所以fm模型在高维特征交互处理效果不是很好;deepfm、deep&cross这两种混合模型的处理效果要比只考虑高维特征的pnn模型效果要好,这说明,有必要同时考虑低维交互特征和高维交互特征,wide&deep模型的效果不如pnn模型的原因是因为wide&deep模型的特征组合方式仍然是人工组合的;所述基于注意力机制的点击率预测方法预测结果要比wide&deep、deepfm、deep&cross这三种混合模型要好,这说明了将显式高维特征进一步细分的必要,将显式特征拆分成高维特征和低维特征,并结合隐式高维特征(dnn训练出来的特征)的训练起到了一定的成效。与计算机视觉的几十层的网络深度相比较,所述基于注意力机制的点击率预测方法的模型的网络设置不是特别深,往往只需3层左右就能达到很好的效果。从图6中可知道,当网络层数小于3时,模型的训练结果在上升,当网络层数大于3时,模型的训练结果出现下降,这说明模型的层数越复杂,训练的效果越不好,容易产生过拟合。
本发明的上述实施例所述的基于注意力机制的点击率预测方法,将同一类用户特征通过独热编码将特征映射成为高维稀疏向量,再通过嵌入层embedding将特征变成低维稠密向量,将特征向量分别带入到压缩交互网络和深度神经网络之中,压缩交互网络和深度神经网络通过将初始输入值与隐藏层的输入值进行矩阵对应位元素的乘积操作,得到下一层的输入值,并通过多个隐藏层的计算,得到每个隐藏层的输入向量,通过自注意力机制对每个隐藏层的输入向量进行权值计算,通过求和池化得到高维显式交互向量的结果,通过将深度神经网络中深度学习得到的结果与压缩交互网络的结果拼接之后通过激活函数输出结果,所述基于注意力机制的点击率预测方法在criteo和frappe公开数据集,综合考虑了用户的低维特征、显式高维特征和隐式高维特征,并通过注意力机制中的自注意力机制筛选有用的特征组合,提高预测效率,不需要人工提取特征,可以提取高维度的特征组合,不容易导致维度过高,提高了宽深度这一类模型对复杂组合特征提取的能力,所述基于注意力机制的点击率预测方法通过向量级别的相乘,而不是元素级别的相乘,并融合了注意力机制,使得预测效果更好。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!