一种基于模型融合的OCR识别方法与流程
本发明属于图像文字处理技术领域,具体涉及一种基于模型融合的ocr识别方法。
背景技术:
随着社会经济的快速发展,人们每天产生大量图片形式的数据,包括被扫描的身份证、自动拍摄的车牌照片、电子形式的发票,扫描形式的文件等等,将这些图片里面的字符信息自动转化为文本形式的过程,即称为光学字符识别(opticalcharacterrecognition,简称ocr)。在传统的ocr识别过程中,一般的流程是人工收集数据、人工录入数据、人工校验,但是整个流程下来,不仅耗费人工周期较长,而且容易出现人工数据录入错误。针对这种情况,急需一种高效且快速的ocr识别方法。
ocr已运用到各种领域,如常见的车牌识别系统,id卡识别系统,发票识别系统等。一个ocr系统按功能需求至少包括图像预处理、字符定位切割和字符识别。ocr应用于不同的领域,对模块性能的要求不相同。如车牌识别系统,需采用摄像头对车辆图像进行采集,周围环境如光照等容易对车牌的识别效果造成影响,因此,车牌系统对预处理模块的要求很高。而对于id卡识别系统、发票识别系统等,其输入的图像大都采用高拍仪、扫描仪等设备,扫描图像清晰、干扰小,所以对预处理模块的要求较低。而文献的版面内容比车牌更为复杂,需要考虑识别算法的快速性。因此针对不同的研究对象,ocr识别系统的设计都需要对其各个系统模块做算法的研究,寻找最契合的方案。
针对日益增加的ocr识别需求以及日益多样化和复杂化的图片数据。目前基于深度学习的ocr识别方法主要包含两个步骤:定位出要识别的字符区域,识别出该区域的字符内容。在传统的ocr识别方法中,通常采用图像处理技术来进行待识别区域的定位出逐个字符,但是当图片比较复杂时定位会出现很大偏差,所以导致后面的识别的准确率很低。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种基于模型融合的ocr识别方法。
根据本发明第一方面实施方式的一种基于模型融合的ocr识别方法,采用若干识别模型搭建深度学习神经网络模型,所述识别模型分别对字符定位数据进行训练,至模型收敛后得到预输出识别结果,将所述预输出识别结果融合优化后输出最终识别结果。
根据本发明的一些实施方式,包括以下步骤:
获得经过数据集预处理的识别模型和字符定位数据;
获得基于所述识别模型的深度学习神经网络模型;
获得预输出识别结果,所述预输出识别结果通过将所述字符定位数据输入所述深度学习神经网络模型进行训练后得到;
获得最终识别结果,所述最终识别结果由所述预输出识别结果经过融合优化后得到。
根据本发明的一些实施方式,所述数据集包括训练集、验证集和测试集。
根据本发明的一些实施方式,所述训练集、验证集和测试集的比例为4:1:1。
数据集预处理的识别模型,指用数据集对识别模型进行预处理。首先,将数据集按照4:1:1分为训练集、验证集和测试集,其次,对数据集进行预处理以增强模型的泛化能力。
其中,数据集可以选用但不局限于开源的icdar2017,其只含有英文字符,约16000张图片。还可以是超市发票图片,手机拍照上传的发票单据图片,收费站拍照汽车牌照图片等,即凡是含有文字的各种图片都属于ocr识别的数据。
4:1:1的比例根据实际经验设定,非固定。所属领域的技术人员可以根据实际情况设置任意比例。
预处理具体可以使用opencv开源的代码库,包含了对图片上下平移、旋转、调节亮度、对比度等操作。
根据本发明的一些实施方式,所述字符定位数据由深度学习技术得到,所述深度学习技术包括pixel-link神经网络技术。
根据本发明的一些实施方式,所述识别模型包括vgg+blstm+attention模型,densenet+gru+attention模型和vgg+blstm+ctc模型。
构建vgg+blstm+attention模型的方法为:
利用待识别定位图片构建基于vgg的卷积神经网络提取图片特征,接着通过全连接层输出r维的特征向量。
对vgg卷积神经网络提取的r维特征,输入给注意力机制网络层进行特征筛选,最终输入给双向长短时记忆神经网络进行识别输出。
构建densenet+gru+attention模型的方法为:
利用待识别定位图片构建基于densenet的卷积神经网络提取图片特征,接着通过全连接层输出w维的特征向量。
对densenet卷积神经网络提取的w维特征,输入给注意力机制网络层进行特征筛选,最终输入给门控循环单元神经网络进行识别输出。
构建vgg+blstm+ctc模型的方法为:
利用待识别定位图片构建基于vgg的卷积神经网络提取图片特征,接着通过全连接层输出n维的特征向量。
对vgg卷积神经网络提取的n维特征,输入给双向长短时记忆神经网络进行预测,最终输入给ctc算法得到识别结果。
根据本发明的一些实施方式,所述的融合优化方法包括投票计数法。
根据本发明的一些实施方式,所述投票计数法为:在若干个识别结果中,选择相同结果投票次数最多的结果作为最终识别结果。
根据本发明的一些实施方式,所述的融合优化方法还包括加权计算法。
根据本发明的一些实施方式,所述的加权计算法为:当存在若干个最大投票次数相同的识别结果时,选择权重最大的识别结果作为最终识别结果。
根据本发明实施例的一种基于模型融合的ocr识别方法,至少具有如下技术效果:
本发明实施例的ocr识别方法,解决了多模型融合的ocr识别问题。相比传统的ocr识别方法,采用深度学习的多模型融合的ocr识别技术,不仅定位精准,而且识别的准确率高,模型识别效果更稳定。
本发明实施例的ocr识别方法,在模型选择上,使用了densenet和vgg卷积神经网络来更好的提取特征,使用了基于注意力机制的blstm和gru模型,是对循环神经网络的扩展,能够更好的处理序列数据,解决待识别图片文本不定长度的难题。与单一的ocr识别模型相比,提高了模型的准确率和模型的识别稳定性。
本发明实施例的ocr识别方法,利用了多模型融合,充分发挥了各个模型的各自优点,实现了模型间的优势互补。
附图说明
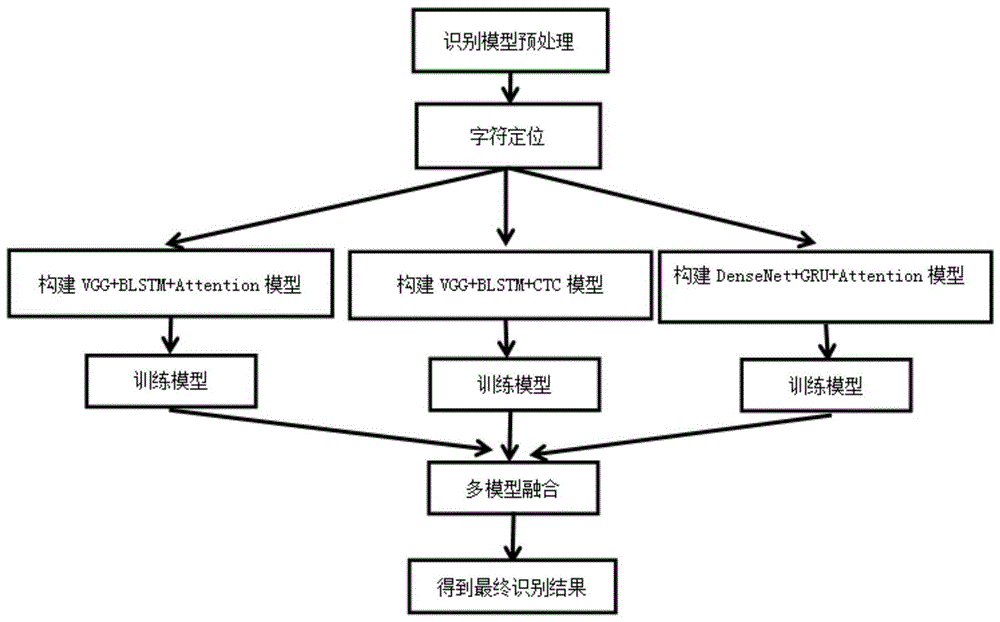
图1是基于模型融合的ocr识别方法的流程示意图。
具体实施方式
以下是本发明的具体实施例,并结合实施例对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
实施例1
本例提供了一种基于模型融合的ocr识别方法,该方法采用若干识别模型搭建深度学习神经网络模型,其中识别模型分别对字符定位数据进行训练,至模型收敛后得到预输出识别结果,将所述预输出识别结果融合优化后输出最终识别结果。
该方法流程如图1所示,具体包括以下步骤:
(1)获得待识别的图片数据,对图片数据进行预处理。
(1.1)对图片进行预处理:对图片进行倾斜矫正,灰度化,锐化,调节对比度,亮度,将图片等比例缩放到统一尺寸。
(1.2)对图片进行归一化处理。m=m/255。其中m为原始数据,m为归一化之后的结果,通过归一化之后图片像素取值范围[0,1],更有利于模型学习。
(1.3)把处理好的图片按照比例划分,划分为训练集:验证集:测试集=4:1:1。
(1.4)把训练集、验证集、测试集对应图片的真实值保存在对应的文本文件中。
(2)对待识别图片进行字符定位。
(3)构建vgg+blstm+attention的ocr识别模型。
(3.1)对步骤(2)定位好的图片作为vgg卷积网络的输入,在vgg卷积网络中采用了5个卷积团,每个卷积团中包含了一些3x3的卷积层,2x2最大的池化层,最后采用了3个全连接层。
(3.2)经过一系列的卷积团提取特征后,将其输入blstm神经网络中进行进一步编码,其编码结果再输入给attention层进行解码,attention层输出的结果再作为blstm层的输入。blstm层输出结果经过softmax激活函数得到输出结果。
(4)构建densenet+gru+attention的ocr识别模型。
(4.1)对步骤(2)定位好的图片作为densenet神经网络的输入,在densenet神经网络中采用了3个denseblocks,每个denseblock里面包含了一些1*1和3*3的卷积层。然后每个denseblock后面都接有一个转换层,每个转换层包含1*1的卷积核和2*2的平均池化层。
(4.2)经过一系列的卷积团提取特征后,将其输入gru神经网络中进行进一步编码,其编码结果再输入给attention层进行解码,attention层输出的结果再作为gru层的输入。gru层输出结果经过softmax激活函数得到输出结果。
(5)构建vgg+blstm+ctc的ocr识别模型。
(5.1)对步骤(2)定位好的图片作为vgg卷积网络的输入,在vgg卷积网络中采用了5个卷积团,每个卷积团中包含了一些3x3的卷积层,2x2最大的池化层,最后采用了3个全连接层。
(5.2)经过上面5个卷积团提取特征后,将其输入lstm神经网络中进行编码。lstm中在训练的时候采用了dropout随机失活来减少模型过拟合,其输出结果最终采用ctc损失函数,来评判模型的拟合能力。
(6)多模型融合识别。
(6.1)将步骤(2)中的图片随机增强产生30张待识别图片,分别给每个ocr识别10张图片进行识别。
(6.2)统计3个ocr识别模型总共产生的30个结果中,频率最高的结果即为多模型融合的最终识别结果。
(6.3)若步骤(6.2)中频率最高的识别候选结果同时出现多个,则预先分别给每个ocr识别模型设置一定的权重值。找出最高候选字符的总频率中3个模型各自的频率数,乘以各自的权重值,再累加3个ocr识别模型的计算值求和。最终选择计算总和最大的结果为多模型融合识别的最终识别结果。
实施例2
本例使用实施例1的基于模型融合的ocr识别方法,对一张待识别的图片进行了识别处理。
完整流程步骤如下:
(1)输入一张待识别的图片,并对其进行预处理,包括将倾斜歪曲的图片进行矫正,将模糊图片尽量去除噪音使其更清晰。
(2)采用pixel-link神经网络,将图片中含有字符的区域定位出来,截图并保存。
(3)将待识别的字符图片,进行随机的数据增强,由一张原始待识别的图片随机增强扩充为30张图片。具体增强扩充方式有:将其随机的上下平移,左右平移,随机的旋转一定角度,随机增加椒盐噪音,随机调节光度,亮度,对比度等。
(4)随机给3个已经训练好的模型各自分配10张图片进行识别,最终同一张原始图片会产生30个识别结果。
(5)采用多模型融合算法,首先统计30个结果中相同结果的频率最高的作为最终结果。但是,当频率最高的候选结果存在多个时候,则根据预先分别给每个ocr识别模型设置的权重值,找出最高候选字符的总频率中3个模型各自的频率数,乘以各自的权重值,再累加3个ocr识别模型的计算值求和。最终选择计算总和最大的结果为多模型融合识别的结果。
(6)输出该图片的最终识别结果。
表1实验结果对比
在实验过程中,事先准备好3种数据集,三种数据集分别只含有较短的字符长度的图片,中等字符长度的图片,较长字符长度的图片。然后,分别给每种识别模型,单独的输入3种数据集进行测试并统计其每种数据集的准确率。通过对比试验发现,多模型融合的ocr模型识别结果最稳定,不会出现较短的字符识别很好,较长字符识别效果很差的不平衡现象。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越本发明所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!