基于高斯混合概率假设密度的紧邻多目标跟踪方法与流程
本发明属于智能信息处理技术领域,具体涉及一种基于高斯混合概率假设密度的紧邻多目标跟踪方法。
背景技术:
近年来,基于有限集统计理论的概率假设密度(probabilityhypothesisdensity,phd)滤波器因无需复杂的数据关联过程,极大地降低了计算复杂度,引起了多目标跟踪领域学者的广泛关注。
phd滤波器是多目标贝叶斯滤波器的一种近似方法,它在每一时刻传递的并不是目标的完全后验密度,而是目标的概率假设密度(目标完全后验密度的一阶统计矩),目标状态及数目从该目标概率假设密度中获取。然而,phd滤波器迭代过程无法直接求得闭合解。线性高斯动态系统中,phd滤波器的闭合解可以采用高斯混合方式来实现,即利用多个高斯分量的加权和来近似目标概率假设密度,这种方法称为gm-phd滤波器。该滤波器的递推过程如下:
预测步:k-1时刻,假设目标概率假设密度
式中,
k时刻,目标预测概率假设密度
式中,
更新步:利用k时刻量测集zk更新目标预测概率假设密度
式中,pd表示检测概率,
式中,jk|k-1表示用k时刻高斯分量的预测数目,
式中,
目前,基于高斯混合(gaussianmixture,gm)近似方式的概率假设密度滤波方法已经在实际应用中得到验证。杂波跟踪环境下,gm-phd滤波器因具有较高迭代效率及状态提取方便等优势,被广泛用于线性高斯动态模型的目标跟踪系统。然而,基于phd滤波的多目标跟踪方法是假设跟踪场景中目标之间的距离较远,即目标间不存在相互干扰;但真实跟踪环境下,多个目标为了实现相互协同工作,这些目标间的距离通常可能非常小,即紧邻目标(交叉运动的目标和平行运动的目标)。当跟踪场景中的多个目标相互接近或保持近距离运动状态时,基于phd滤波的多目标跟踪方法便不能正确地区分出源于每个目标自身的真实量测,导致部分目标被错误更新和漏估计,因此,该类方法的目标状态及数目估计精度较低。此外,如果跟踪场景中的杂波均值较大且检测概率较低时,该类方法的滤波精度将进一步下降。
技术实现要素:
针对平行运动目标场景中基于phd滤波的多目标跟踪方法的目标状态及数目估计精度较低的问题,本发明提出了一种基于高斯混合概率假设密度的紧邻多目标跟踪方法,采用紧邻多目标高斯混合概率假设密度(mcst-gm-phd)解决了密集杂波、较低检测概率跟踪环境下的平行运动目标跟踪问题。
为解决以上技术问题,本发明所采用的技术方案如下:
一种基于高斯混合概率假设密度的紧邻多目标跟踪方法,包括如下步骤:
s1,增加高斯分量的标签和历史状态矩阵为辅助参数以构建用于表示目标的高斯分量的新标准描述集;
s2,初始化目标概率假设密度、目标标签集及目标历史状态矩阵集;
s3,根据新生目标的概率假设密度、标签集、历史状态矩阵集和存活目标的预测概率假设密度、预测标签集、预测历史状态矩阵集,计算目标预测概率假设密度、目标预测标签集、目标预测历史状态矩阵集;
s4,基于量测集计算目标后验概率假设密度、目标后验标签集和目标后验历史状态矩阵集,重分配目标后验概率假设密度中各高斯分量的权值;
s5,对目标的高斯分量集及其参数集进行变换,并对变换后的高斯分量集进行约简;
s6,估计目标的状态和数目;
s7,若跟踪单一时刻,则目标跟踪结束;若跟踪若干个时刻,则重复执行s3-s6直至迭代所有时刻。
在步骤s1中,所述表示目标的高斯分量的新标准描述集的表达式为:
o={w,m,p,l,χ};
式中,w表示高斯分量的权值,m表示高斯分量的均值,p表示高斯分量的协方差矩阵,l表示高斯分量的标签,χ表示高斯分量的历史状态矩阵;
k时刻的高斯分量的历史状态矩阵χk的表达式为:
χk=[mk-δ+1,...,mk-1,mk];
式中,δ表示传感器所设定的历史状态矩阵中的元素数目阈值。
在步骤s2中,所述目标概率假设密度
式中,
所述标签集
式中,
所述历史状态矩阵集λk的表达式为:
式中,
在步骤s3中,所述新生目标的概率假设密度γk(x)的表达式为:
式中,jγ,k表示新生高斯分量的数目,
所述新生目标的标签集
式中,
所述新生目标的历史状态矩阵集λγ,k的表达式为:
式中,
所述存活目标的预测概率假设密度
式中,
所述存活目标的预测标签集
式中,
所述存活目标的预测历史状态矩阵集λs,k|k-1的表达式为:
式中,
所述目标预测概率假设密度
式中,jk|k-1表示预测高斯分量的预测数目,
所述目标预测标签集
式中,
所述目标预测历史状态矩阵集λk|k-1的表达式为:
式中,
在步骤s4中,所述量测集zk的表达式为:
式中,mk表示k时刻量测集zk中量测的数目,
所述计算目标后验概率假设密度
s4.1;计算高斯分量
所述高斯分量
式中,
所述高斯分量
式中,
所述高斯分量
式中,i表示单位矩阵;
所述高斯分量
所述高斯分量
式中,
s4.2,计算高斯分量
所述非归一化权值矩阵ak的表达式为:
式中,
归一化权值矩阵bk的表达式为:
式中,
在步骤s4.2中,所述对各高斯分量的权值进行再分配,输出目标后验概率假设密度
s4.2.1,查找归一化权值矩阵bk中的最大权值的索引<i*,j*>,构建与该最大权值高斯分量具有相同标签的分量索引集ψ,计算分量索引集ψ中索引所对应的高斯分量的权值和ηw;
所述最大权值的索引<i*,j*>的表达式为:
式中,
所述分量索引集ψ的表达式为:
式中,
所述权值和ηw的表达式为:
s4.2.2,计算标志位
所述标志位
s4.2.3,将归一化权值矩阵bk中的权值
s4.2.4,更新高斯分量索引集
s4.2.5,基于优化权值矩阵ek中的权值,更新目标后验概率假设密度
所述目标后验概率假设密度
所述目标后验标签集
所述目标后验历史状态矩阵集λk的表达式为:
在步骤s4.2.2中,所述更新分量索引集中索引所对应的高斯分量的权值和ηw和标志位
s4.2.2a,从具有相同标签
所述高斯分量所对应的索引<ir,jc>的表达式为:
其中,
式中,比例系数ζ=[1,δ-1/δ,δ-2/δ,δ-3/δ,δ-4/δ],
s4.2.2b,更新非归一化权值矩阵ak和归一化权值矩阵bk中的各权值,对应的表达式分别为:
式中,比例因子
s4.2.2c,更新分量索引集ψ中索引所对应的高斯分量的权值和ηw和标志位
在步骤s5中,所述目标的高斯分量集的表达式为:
式中,jk|k-1表示预测高斯分量的预测数目,mk表示量测集zk中量测的数目;
所述参数集的表达式为:
式中,
所述变换后的高斯分量集的表达式为:
式中,高斯分量数目为jk=jk|k-1+jk|k-1×mk;
所述变换后的高斯分量集所对应的参数集表达式为:
所述对变换后的高斯分量集进行约简包括步骤如下:
s5.1,设定删减阈值t1,融合阈值u,最大高斯分量数目阈值jmax;
s5.2,设定计数变量j=0和高斯分量数目变量
式中,
s5.3,执行j=j+1,筛选具有最大权值的高斯分量
所述最大权值的高斯分量
s5.4,更新高斯分量索引集
所述更新高斯分量索引集
式中,过渡索引集
所述更新高斯分量数目变量
s5.5,对高斯分量数目变量
如果
在步骤s5.3中,所述建立新的高斯分量包括如下步骤:
s5.3.1,定义过渡索引集
式中,
s5.3.2,定义过渡索引集
式中,
s5.3.3,将过渡索引集l2中索引所对应的高斯分量
所述新的高斯分量
式中,
所述新的高斯分量
所述新的高斯分量
式中,
所述新的高斯分量
所述新的高斯分量
式中,
在步骤s6中,所述估计目标的状态和数目包括如下步骤:
s6.1,根据步骤s5中所获得的高斯分量参数集中的权值估计目标数目;
所述目标数目nk的表达式为:
式中,
s6.2,从高斯分量参数集中选择权值大于0.5的索引,之后将索引所对应的高斯分量作为真实目标,最后输出高斯分量的均值即作为当前时刻的目标状态估计。
本发明的有益效果:
本发明适用于航空和地面交通管制、移动机器人的道路规划和避障、无人机等系统的目标检测与跟踪,应用范围广;具有良好的跟踪性能和鲁棒性,可满足实际工程系统的设计需求,为密集杂波、较低检测概率跟踪环境下的紧邻多目标跟踪系统的设计提供了一种有效的方案。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
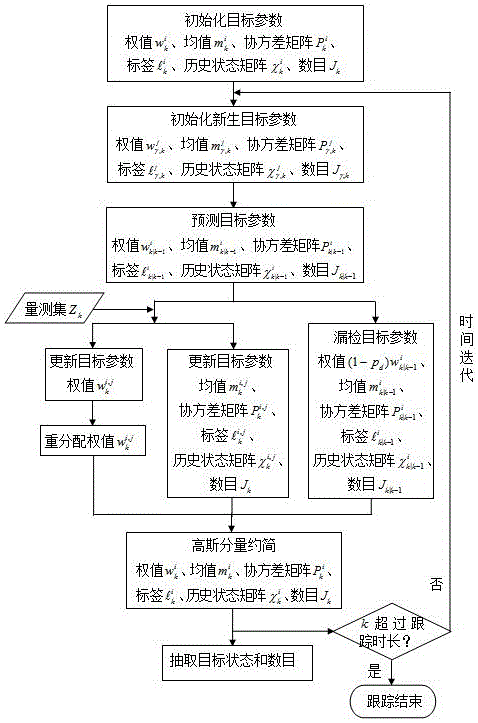
图1是本发明mcst-gm-phd的流程示意图。
图2是本发明试验采用的杂波环境下含有目标真实运动轨迹及量测的场景示意图;
图3是采用本发明mcst-gm-phd与gm-phd方法、p-gm-phd方法、cp-gm-phd方法以及ir-gm-phd方法的平均ospa距离的比较效果图。
图4是采用本发明mcst-gm-phd与gm-phd方法、p-gm-phd方法、cp-gm-phd方法以及ir-gm-phd方法的平均目标数目估计数的比较效果图。
图5是不同杂波均值环境下本发明mcst-gm-phd与gm-phd方法、p-gm-phd方法、cp-gm-phd方法以及ir-gm-phd方法的平均ospa距离的比较效果图。
图6是不同杂波均值环境下本发明mcst-gm-phd与gm-phd方法、p-gm-phd方法、cp-gm-phd方法以及ir-gm-phd方法的平均目标数目估计数的比较效果图。
图7是不同检测概率环境下本发明mcst-gm-phd与gm-phd方法、p-gm-phd方法、cp-gm-phd方法以及ir-gm-phd方法的平均ospa距离的比较效果图。
图8是不同检测概率环境下本发明mcst-gm-phd与gm-phd方法、p-gm-phd方法、cp-gm-phd方法以及ir-gm-phd方法的平均目标数目估计数的比较效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于高斯混合概率假设密度的紧邻多目标跟踪方法,如图1所示,包括如下步骤:
s1,增加高斯分量的标签和历史状态矩阵为辅助参数以构建用于表示目标的高斯分量的新标准描述集;
所述表示目标的高斯分量的新标准描述集o的表达式为:
o={w,m,p,l,χ};
式中,w表示高斯分量的权值,m表示高斯分量的均值,p表示高斯分量的协方差矩阵,l表示高斯分量的标签,χ表示高斯分量的历史状态矩阵;
标签用于识别高斯分量的身份以及属于不同目标的高斯分量;历史状态矩阵存储了高斯分量的若干个历史状态,通过计算目标的各高斯分量的历史状态矩阵与不同量测间的距离,实现当前时刻高斯分量与目标的相对最优匹配;在滤波器对目标进行初始化时,每个目标一般只采用一个高斯分量来表示,但是在滤波迭代过程中,每个目标通常由多个高斯分量来表示;
k时刻的高斯分量的历史状态矩阵χk的表达式为:
χk=[mk-δ+1,…,mk-1,mk];
式中,δ表示传感器所设定的历史状态矩阵中的元素数目阈值。
s2,初始化目标概率假设密度、标签集及历史状态矩阵集;
所述目标概率假设密度
式中,
所述目标标签集
式中,
所述目标历史状态矩阵集λk的表达式为:
式中,
初始化目标概率假设密度、目标标签集及目标历史状态矩阵集,为对将要跟踪的目标进行初始化。
s3,根据新生目标的概率假设密度、标签集、历史状态矩阵集和存活目标的预测概率假设密度、预测标签集、预测历史状态矩阵集,计算目标预测概率假设密度、目标预测标签集、目标预测历史状态矩阵集;
所述新生目标的概率假设密度γk(x)的表达式为:
式中,jγ,k表示新生高斯分量的数目,
所述新生目标的标签集
式中,
所述新生目标的历史状态矩阵集λγ,k的表达式为:
式中,
所述存活目标的预测概率假设密度
式中,
所述存活高斯分量
式中,ps表示存活概率,
所述存活高斯分量
式中,fk-1表示k-1时刻状态转移矩阵,
所述存活高斯分量
式中,qk-1表示k-1时刻过程噪声协方差矩阵,
所述存活高斯分量的预测数目js,k|k-1的表达式为:
js,k|k-1=jk-1;
式中,jk-1表示k-1时刻高斯分量的数目;
所述存活目标的预测标签集
式中,
所述存活目标的预测历史状态矩阵集λs,k|k-1的表达式为:
式中,
所述目标预测概率假设密度
式中,jk|k-1表示预测高斯分量的预测数目,
所述预测高斯分量的预测数目jk|k-1的表达式为:
jk|k-1=js,k|k-1+jγ,k;
所述预测高斯分量
式中,
所述预测高斯分量
式中,
所述预测高斯分量
式中,
所述目标预测标签集
式中,
所述预测标签
所述目标预测历史状态矩阵集λk|k-1的表达式为:
式中,
所述预测历史状态矩阵
步骤s3通过对前一时刻目标的概率假设密度、标签集和历史状态矩阵集进行一步预测,以得到当前时刻存活目标的预测概率假设密度、预测标签集和预测历史状态矩阵集,结合当前时刻新生目标的概率假设密度、标签集和历史状态矩阵集,以构建当前时刻所有目标的预测概率假设密度、预测标签集和预测历史状态矩阵集,为后续的目标更新做好准备工作。
s4,基于量测集计算目标后验概率假设密度
所述量测集zk的表达式为:
式中,mk表示k时刻量测集zk中量测的数目,
所述计算目标后验概率假设密度
s4.1:计算目标的高斯分量
所述高斯分量
式中,
所述高斯分量
式中,
所述高斯分量
式中,i表示单位矩阵;
所述高斯分量
所述高斯分量
式中,
s4.2,计算高斯分量
所述非归一化权值矩阵ak的表达式为:
式中,
归一化权值矩阵bk的表达式为:
式中,
然后,设定高斯分量索引集
所述对各高斯分量的权值再分配,并输出目标后验概率假设密度
s4.2.1,查找归一化权值矩阵bk中的最大权值的索引<i*,j*>,构建与该最大权值高斯分量具有相同标签的分量索引集ψ,计算分量索引集ψ中索引所对应的高斯分量的权值和ηw;
所述最大权值的索引<i*,j*>的表达式为:
式中,mk表示量测集zk中量测的数目;
所述分量索引集ψ的表达式为:
式中,
所述权值和ηw的表达式为:
s4.2.2,计算标志位
所述标志位
所述更新分量索引集中索引所对应的高斯分量的权值和ηw和标志位
s4.2.2a,从具有相同标签
所述高斯分量所对应的索引<ir,jc>的表达式为:
其中,
式中,比例系数ζ=[1,δ-1/δ,δ-2/δ,δ-3/δ,δ-4/δ],
s4.2.2b,更新非归一化权值矩阵ak和归一化权值矩阵bk中的各权值,对应的表达式分别为:
式中,比例因子
s4.2.2c,更新分量索引集ψ中索引所对应的高斯分量的权值和ηw和标志位
s4.2.3,将归一化权值矩阵bk中的权值
s4.2.4,更新高斯分量索引集
所述更新高斯分量索引集
s4.2.5,基于优化权值矩阵ek中的权值,更新目标后验概率假设密度
所述目标后验概率假设密度
所述目标后验标签集
所述目标后验历史状态矩阵集λk的表达式为:
步骤s4.2通过对高斯分量的权值进行再分配,得到了高精度的目标后验概率假设密度。
s5,对步骤s4中所获得的高斯分量集
所述高斯分量集
变换后的高斯分量
变换后的高斯分量
变换后的高斯分量
变换后的高斯分量
变换后的高斯分量
变换后的高斯分量
所述对变换后的高斯分量集进行约简包括步骤如下:
s5.1,设定删减阈值t1,融合阈值u,最大高斯分量数目阈值jmax。
s5.2,设定计数变量j=0和高斯分量数目变量
式中,
s5.3,执行j=j+1,筛选具有最大权值的高斯分量
所述最大权值的高斯分量
所述建立新的高斯分量包括如下步骤:
s5.3.1,定义第一过渡索引集l1;
所述第一过渡索引集l1的表达式为:
式中,
s5.3.2,定义第二过渡索引集l2;
所述第二过渡索引集l2的表达式为:
式中,
s5.3.3,将第二过渡索引集l2中索引所对应的高斯分量
所述新的高斯分量
式中,
所述新的高斯分量
所述新的高斯分量
式中,
所述新的高斯分量
所述新的高斯分量
式中,
s5.4,更新高斯分量索引集
所述更新高斯分量索引集
所述更新高斯分量数目变量
s5.5,对高斯分量数目变量
如果
所述约简后的高斯分量集
步骤s5通过对高斯分量进行约简,实现了对高斯分量的优化重组,降低了无效高斯分量的数目,能够有效地提高跟踪算法的计算效率。
s6,根据步骤s5中所获得的约简后的高斯分量集,估计目标的状态和数目,包括如下步骤:
s6.1,根据约简后的高斯分量参数集
所述目标数目nk的表达式为:
s6.2,从高斯分量参数集
步骤s6实现了从当前时刻高斯分量参数集中估计目标的状态和数目。
s7,若跟踪单一时刻,则目标跟踪结束;若跟踪若干个时刻,则重复执行s3-s6直至迭代所有时刻。
本发明的效果可通过以下仿真实验进一步说明:
①仿真条件及参数
图2是本发明试验采用的一个二维跟踪区域内目标真实轨迹及量测在100个时刻的仿真示意图,且杂波均值为5。k时刻的目标状态为
xk=fk-1xk-1+qk-1;
zk=hkxk+rk;
其中,
仿真场景中,过程噪声σw为一个均值为0、标准差为0.5m的高斯白噪声,量测噪声σv为一个均值为0、标准差为50m的高斯白噪声,检测概率pd=0.98,存活概率ps=0.99。设置删减阈值t1=10-5,融合阈值u=4,最大高斯分量数目阈值jmax=100,元素数目阈值δ=5。假设k=0时刻初始化的目标概率假设密度为:
其中,
②仿真结果与分析
仿真实验中,本发明mcst-gm-phd分别与gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法进行多目标跟踪性能对比。本发明中采用ospa距离和目标数目估计数为跟踪性能度量指标,其中ospa距离的两个参数分别为c=100和p=2。ospa距离越小,目标状态精度越高。每个实验结果均为200次蒙特卡罗仿真的均值。实验主要从以下三个方面开展:
实验1:杂波干扰下的多目标场景
图3是采用本发明mcst-gm-phd与gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法的平均ospa距离对比效果图。可以看出,本发明mcst-gm-phd的目标状态估计精度优于gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法。
图4是采用本发明mcst-gm-phd与gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法的平均目标数目估计数对比效果图。可以看出,本发明mcst-gm-phd的目标数目估计精度与ir-gm-phd方法相当,且均能够准确地估计出目标数目;本发明mcst-gm-phd的目标数目估计精度优于gm-phd、p-gm-phd和cp-gm-phd方法。
实验2:不同杂波均值下的多目标场景
图5是不同杂波均值环境下采用本发明mcst-gm-phd与gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法的平均ospa距离对比效果图。可以看出,在不同杂波均值环境下本发明mcst-gm-phd的目标状态估计精度优于gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法。
图6是不同杂波均值环境下采用本发明mcst-gm-phd与gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法的平均目标数目估计数对比效果图。可以看出,在不同杂波均值环境下本发明mcst-gm-phd的目标数目估计精度与ir-gm-phd方法相当,且优于gm-phd、p-gm-phd和cp-gm-phd方法。
实验3:不同检测概率下的多目标场景
图7是不同检测概率环境下采用本发明mcst-gm-phd与gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法的平均ospa距离对比效果图。可以看出,在不同检测概率环境下本发明mcst-gm-phd的目标状态估计精度优于gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法。
图8是不同检测概率环境下采用本发明mcst-gm-phd与gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法的平均目标数目估计数对比效果图。可以看出,在不同检测概率环境下本发明mcst-gm-phd的目标数目估计精度优于gm-phd、p-gm-phd、cp-gm-phd和ir-gm-phd方法。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!