一种融合光流算法与深度学习的模糊视频检测方法与流程
本发明涉及视频识别技术领域,尤其是一种融合光流算法与深度学习的模糊视频检测方法。
背景技术:
如何提高模糊视频的检测率一直是个难题,由于有视频散焦、部分遮挡、运动模糊的因素在里面,即便是高清视频,截取的帧也不如用相机拍出的照片清晰;而在视频监控中,由于有夜晚光照昏暗,以及拍摄距离过远等原因,所摄取的视频往往是较为模糊的。
目前模糊视频,包括监控的视频的检测工作主要是依靠专业人员来完成的,但在检测背景复杂的情况下,人员受知识水平等因素影响,凭借肉眼方式难以保证其准确度。同时,由于自然环境下监控视频受气候条件影响较大,如大雾、风雪、暴雨等,并掺杂光照、阴影等影响,使得传统的基于深度学习模糊视频检测方法效率低、鲁棒性较不理想。此外,目前检测方法大多数集中在视频帧的本身特征提取,忽略了视频的时序信息等相关条件因素的考虑,也致使模糊视频的自动识别只能存在于实验阶段。如何能够提高模糊视频检测的准确性已经成为急需解决的技术问题。
技术实现要素:
本发明的目的在于提供一种能够提高复杂应用情况下模糊视频检测与识别能力,提高模糊视频中目标的检测率的融合光流算法与深度学习的模糊视频检测方法。
为实现上述目的,本发明采用了以下技术方案:一种融合光流算法与深度学习的模糊视频检测方法,该方法包括下列顺序的步骤:
(1)进行训练视频样本的预处理:收集多个模糊视频及其相对应目标发生时的时间、地理位置信息作为训练数据,人工标记出模糊视频中的检测目标,并将所有标记视频截取帧,得到多类目标,每类目标有多个训练样本;
(2)基于深度学习算法,用步骤(1)中获得的帧进行训练获得模糊视频检测模型,构建模糊视频时序训练模型,并引入不同模糊视频拍摄时时间、地理位置作为特征数据,训练基于深度学习融合光流算法的水稻病害检测模型;并且通过深度学习算法获得视频帧的特征图;
(3)把待检测的帧的前十帧与后十帧的特征图按照取值从0到1、且符合正态分布的权重,用光流算法把这二十一张特征图都聚合到一张特征图上;
(4)按照正态分布算法,确定步骤(3)中的权重;
(5)基于深度学习的图像检测算法构建帧特征图检测模型,检测结合经光流算法计算产生的帧特征图,检测此特征图;
(6)结合目标在模糊视频中具体位置的标记,将待检测视频的空间、地理位置、时间信息输入训练后的帧特征图检测模型,进行模糊视频的识别与检测,定位并由计算机标记出目标在视频帧中具体位置。
在步骤(1)中,所述训练视频样本的预处理包括以下步骤:
(1a)收集多个因雨雪、大雾、夜晚而引起的模糊拍摄的视频,并将这些视频按照相对应目标发生时的时间、地理位置信息进行分类;
(1b)对视频用视频标记工具进行标记,所述视频标记工具为逐帧标记,标记内容是视频中的目标的类别;
(1c)把步骤(1a)中的依相对应目标发生时的时间、地理位置信息分类的视频,用算法截取帧,并将这些帧依照对应目标发生时的时间、地理位置分门别类存放,用于训练检测模型。
在步骤(2)中,所述基于深度学习算法,用获得的帧进行训练获得模糊视频检测模型,获得帧特征图,具体包括以下步骤:
(2a)获得帧特征图的训练网络采用resnet-50、resnet-101、googlenet,分别进行训练,用以多样化生成帧并在后续步骤中进行检测;
(2b)resnet-50的网络结构为:49个卷积层,1个平均池化层,其中卷积层分为16个块,每个块都有1个快捷连接,最后用softmax层来生成分类预测置信度;resnet-101的网络结构为:100个卷积层,1个平均池化层,其中卷积层分为33个块,每个块都有1个快捷连接,最后用softmax层来生成分类预测置信度;googlenet的网络结构:一共有22层,除了最后一层是softmax层,用于输出结果,其它层采用分支卷积后,再合并连接的方式,均值pooling层滤波器大小为5x5,步长为3;
(2c)当帧分别通过这三类网络时,在最后一层softmax层之前,输出帧的特征图。
所述步骤(3)具体包括以下步骤:
(3a)根据帧特征图提供目标物体实例的不同信息;
(3b)运用光流算法,将特定帧的特征图与它的前后各五帧的特征图,共十一张特征图融合起来,其公式如下:
其中,fi是特定帧的特征图,∑表示光流聚合,wi表示把相邻的这些特征图按不同的权重进行聚合,fj表示聚合后的特征图;
其中wi由下式确定:
而z是特定帧与相邻帧的距离,定义:z=|i-j|,μ是正态分布的均值,σ是正态分布的方差,取μ=0,σ=1;
所述光流算法采用计算机视觉库中的光流算法,具体是指:
设像素i(x,y,t),x,y表示坐标,t表示时间,移动了(dx,dy)的距离到下一帧,用了dt时间,假设此像素在微小的时间内是不变的,即:
i(x,y,t)=i(x+dx,y+dy,t+dt)
将上式泰勒展开,可得:
其中ε代表二阶无穷小项,比较上面两式,可得:
上式除dt,可得:
所述步骤(4)包括以下步骤:
(4a)将待检测帧相邻的十一帧编号;
(4b)按照权重计算公式
所述步骤(5)中的基于深度学习图像检测算法,构建帧特征图检测模型,检测帧特征图,包括以下步骤:
(5a)使用r-fcn网络作为检测帧特征图的网络,r-fcn网络包括rpn网络和r-fcn网络;
(5b)rpn网络使用9个锚框,每张图产生300个建议框;r-fcn网络中的位置敏感图是7×7像素;
(5c)用训练样本帧训练r-fcn网络,得到关于目标类别的帧检测模型;
(5d)将聚合后的特征图输入步骤(5c)中的帧检测模型,得到检测结果。
所述步骤(6)具体包括以下步骤:
(6a)将分门别类的训练样本帧分别训练得到各自类别的模糊视频经截取后的模糊帧的检测模型;
(6b)将各自类别的视频帧输入各自的检测模型,进行检测,得到含有空间、地理位置、时间信息各个类别的视频帧的检测结果;
(6c)检测结果在输出结果中有标注;
(6d)统计各个类别的训练样本帧的检测结果,检测结果包含目标发生时的时间、地理位置信息。
由上述技术方案可知,本发明的有益效果为:本发明与现有技术相比不仅考虑了视频帧本身的特征,还考虑了视频时序,以及空间、地理位置、天气等相关因素,用光流法对每一帧及其前后帧进行光流融合;本发明对不同地理位置、天气等因素分别建立模型,分别检测,提高了复杂应用情况下模糊视频检测与识别能力,提高了模糊视频中目标的检测率。
附图说明
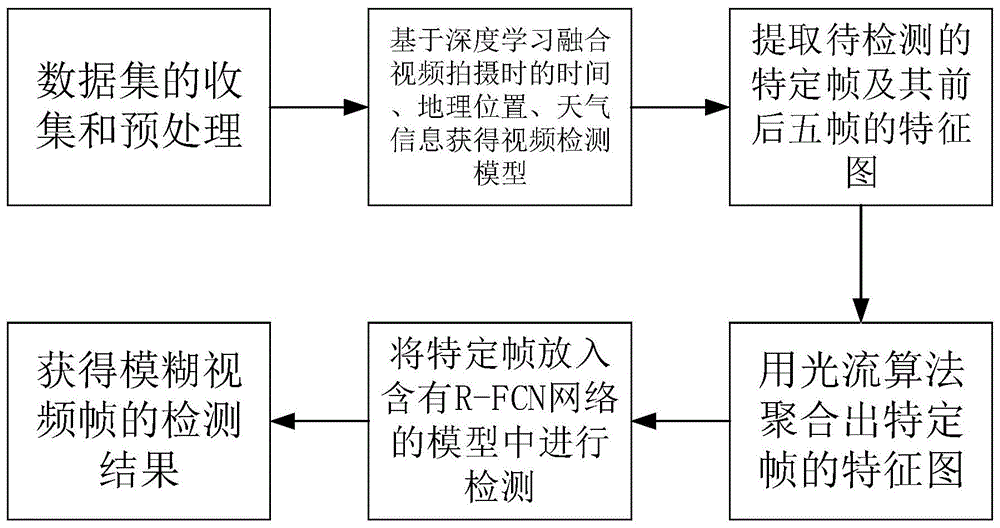
图1为本发明的方法流程图;
图2为本发明中光流法聚合视频帧的特征图的示意图。
具体实施方式
如图1所示,一种融合光流算法与深度学习的模糊视频检测方法,该方法包括下列顺序的步骤:
(1)进行训练视频样本的预处理:收集多个模糊视频及其相对应目标发生时的时间、地理位置信息作为训练数据,人工标记出模糊视频中的检测目标,并将所有标记视频截取帧,得到多类目标,每类目标有多个训练样本;
(2)基于深度学习算法,用步骤(1)中获得的帧进行训练获得模糊视频检测模型,构建模糊视频时序训练模型,并引入不同模糊视频拍摄时时间、地理位置作为特征数据,训练基于深度学习融合光流算法的水稻病害检测模型;并且通过深度学习算法获得视频帧的特征图;
(3)把待检测的帧的前十帧与后十帧的特征图按照取值从0到1、且符合正态分布的权重,用光流算法把这二十一张特征图都聚合到一张特征图上;
(4)按照正态分布算法,确定步骤(3)中的权重;
(5)基于深度学习的图像检测算法构建帧特征图检测模型,检测结合经光流算法计算产生的帧特征图,检测此特征图;
(6)结合目标在模糊视频中具体位置的标记,将待检测视频的空间、地理位置、时间信息输入训练后的帧特征图检测模型,进行模糊视频的识别与检测,定位并由计算机标记出目标在视频帧中具体位置。
在步骤(1)中,所述训练视频样本的预处理包括以下步骤:
(1a)收集多个因雨雪、大雾、夜晚而引起的模糊拍摄的视频,并将这些视频按照相对应目标发生时的时间、地理位置信息进行分类;
(1b)对视频用视频标记工具进行标记,所述视频标记工具为逐帧标记,标记内容是视频中的目标的类别;
(1c)把步骤(1a)中的依相对应目标发生时的时间、地理位置信息分类的视频,用算法截取帧,并将这些帧依照对应目标发生时的时间、地理位置分门别类存放,用于训练检测模型。步骤(1c)中的帧,应有若干类,在每一类中应有若干训练样本帧。
收集若干模糊视频及其相对应视频拍摄时的时间、地理位置、天气信息作为训练数据,人工标记出模糊视频中的目标,得到若干类视频,每类视频有若干个视频训练样本。这里,不仅获得了视频的样本,还获得了视频拍摄时的时间、地理位置、天气等信息,通过这些信息进一步增加了模糊视频识别的鲁棒性。
在步骤(2)中,所述基于深度学习算法,用获得的帧进行训练获得模糊视频检测模型,获得帧特征图,具体包括以下步骤:
(2a)获得帧特征图的训练网络采用resnet-50、resnet-101、googlenet,分别进行训练,用以多样化生成帧并在后续步骤中进行检测;
(2b)resnet-50的网络结构为:49个卷积层,1个平均池化层,其中卷积层分为16个块,每个块都有1个快捷连接,最后用softmax层来生成分类预测置信度;resnet-101的网络结构为:100个卷积层,1个平均池化层,其中卷积层分为33个块,每个块都有1个快捷连接,最后用softmax层来生成分类预测置信度;googlenet的网络结构:一共有22层,除了最后一层是softmax层,用于输出结果,其它层采用分支卷积后,再合并连接的方式,均值pooling层滤波器大小为5x5,步长为3;
(2c)当帧分别通过这三类网络时,在最后一层softmax层之前,输出帧的特征图。
所述步骤(3)具体包括以下步骤:
(3a)根据帧特征图提供目标物体实例的不同信息;
(3b)运用光流算法,将特定帧的特征图与它的前后各五帧的特征图,共十一张特征图融合起来,其公式如下:
其中,fi是特定帧的特征图,∑表示光流聚合,wi表示把相邻的这些特征图按不同的权重进行聚合,fj表示聚合后的特征图;
其中wi由下式确定:
而z是特定帧与相邻帧的距离,定义:z=|i-j|,μ是正态分布的均值,σ是正态分布的方差,应当依照不同应用范围进行调整,通常取μ=0,σ=1;
所述光流算法采用计算机视觉库中的光流算法,具体是指:
设像素i(x,y,t),x,y表示坐标,t表示时间,移动了(dx,dy)的距离到下一帧,用了dt时间,假设此像素在微小的时间内是不变的,即:
i(x,y,t)=i(x+dx,y+dy,t+dt)
将上式泰勒展开,可得:
其中ε代表二阶无穷小项,比较上面两式,可得:
上式除dt,可得:
上式表明,距离特定帧越近,权重取值越大,距离特定帧越远,权重取值越小。
所述步骤(4)包括以下步骤:
(4a)将待检测帧相邻的十一帧编号;
(4b)按照权重计算公式
所述步骤(5)中的基于深度学习图像检测算法,构建帧特征图检测模型,检测帧特征图,包括以下步骤:
(5a)使用r-fcn网络作为检测帧特征图的网络,r-fcn网络包括rpn网络和r-fcn网络;
(5b)rpn网络使用9个锚框,每张图产生300个建议框;r-fcn网络中的位置敏感图是7×7像素;
(5c)用训练样本帧训练r-fcn网络,得到关于目标类别的帧检测模型;
(5d)将聚合后的特征图输入步骤(5c)中的帧检测模型,得到检测结果。
所述步骤(6)具体包括以下步骤:
(6a)将分门别类的训练样本帧分别训练得到各自类别的模糊视频经截取后的模糊帧的检测模型;
(6b)将各自类别的视频帧输入各自的检测模型,进行检测,得到含有空间、地理位置、时间信息各个类别的视频帧的检测结果;
(6c)检测结果在输出结果中有标注,如目标在帧当中的位置、目标类别、目标置信度等;
(6d)统计各个类别的训练样本帧的检测结果,检测结果包含目标发生时的时间、地理位置信息。
综上所述,本发明与现有技术相比不仅考虑了视频帧本身的特征,还考虑了视频时序,以及空间、地理位置、天气等相关因素,用光流法对每一帧及其前后帧进行光流融合;本发明对不同地理位置、天气等因素分别建立模型,分别检测,提高了复杂应用情况下模糊视频检测与识别能力,提高了模糊视频中目标的检测率。
- 还没有人留言评论。精彩留言会获得点赞!