一种基于正交引导学习的多模态2D及3D人脸表情识别的制作方法
本发明涉及计算机视觉技术领域,具体涉及一种基于正交引导学习的多模态2d及3d人脸表情识别。
背景技术:
随着深度学习的快速发展,多模态2d及3d人脸表情识别(fer)在计算机视觉领域中受到广泛的关注。这些基于深度学习的方法都是先利用3d点云数据提取到多张3d属性图,将这几张属性图和2d人脸图作为输入,分别送入到cnn网络的各个特征提取支路中,最后,将每条支路提取到的特征进行融合来作为分类器的输入。但是,由于2d彩色图和3d属性图都是来自于同一个样本,导致每条支路学习到的特征可能会存在冗余,不利于直接进行特征融合,另外,对于每一张属性图都采用一个支路去提取特征,大大增加了模型的复杂度。
技术实现要素:
本发明的目的在于针对现有技术的缺陷和不足,提供一种基于正交引导学习的多模态2d及3d人脸表情识别,降低深度学习网络的复杂度以及抑制网络中不同分支提取的特征之间的冗余。
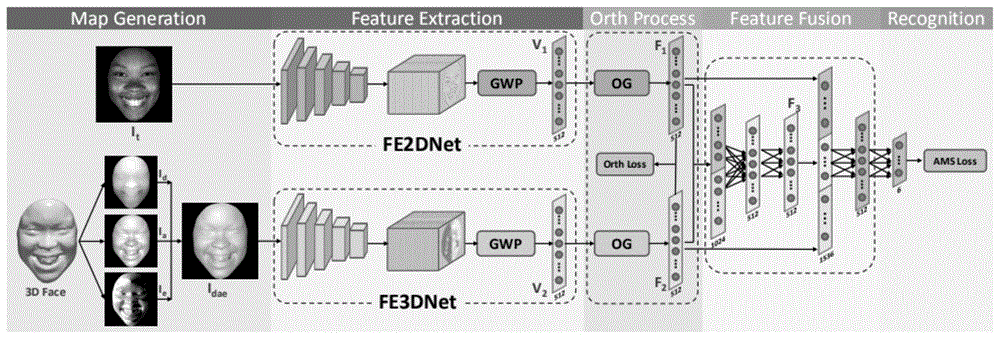
为实现上述目的,本发明采用以下技术方案是:它利用人脸点云数据生成三张属性图,分别为深度图、方位图、立面图,所述的深度图、方位图、立面图合成一个三通道的rgb图,所述的rgb图作为网络中某一条支路的输入,减少了模型的参数量。
所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,引入一个正交模块保证在特征融合时特征是正交的。
所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,特征提取部分使用两个不同结构的网络分支来分别提取2d人脸图和3d属性图的特征,分别定义为fe2dnet和fe3dnet,fe2dnet是vgg网络的变形,而fe3dnet则是resnet的衍生。
所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,采用全局加权池化(gwp)层来取代gap层,不同与通用物体,在人脸表情识别任务中,输入cnn网络的图像都是经过关键点对齐的,以至于在深层的特征图中,每个像素都代表着输入图像的某个特定区域,包含固定的语义信息。嘴巴,鼻子,眼睛等重要区域对表情的正确分类起着至关重要的作用,需要额外的关注这些区域的语义信息。直接使用gap,直接将所有像素求平均,那么这些关键区域的语义信息则很可能被忽略掉。
所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,每张特征图均设置有与之大小相同的权重图,权重图中的权值可由梯度下降更新,输出的特征向量由特征图和权重图点积计算得到,其计算如下公式所示:
所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,两条通道的输入图像都是来自于同一个人脸的2d灰度图和3d属性图,特征提取器提取到的特征向量v1和v2可能会存在冗余,进行特征融合之前,让v1和v2经过一个正交引导模块,使得输出的特征向量f1和f2正交,去除掉两个向量之间的冗余部分。正交引导模块是由一层全连接层和relu层构成。
所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,
正交引导模块分别以v1和v2作为输入,通过全连接层对其进行转换,并输出两个正交特征f1和f2,设计一个正交损失函数lorth来监督正交引导模块权重的更新,以确保f1和f2之间的正交性。lorth的公式定义如下:
本发明的工作原理:一种基于正交引导学习的多模态2d及3d人脸表情识别,利用人脸点云数据生成三张属性图,分别为深度图、方位图、立面图,所述的深度图、方位图、立面图合成一个三通道的rgb图,引入一个正交模块保证在特征融合时特征是正交的,在进行特征融合之前,我们先让v1和v2经过一个正交引导模块,使得输出的特征向量f1和f2正交,去除掉两个向量之间的冗余部分。
采用上述技术方案后,本发明有益效果为:以该发明一种基于正交引导学习的多模态2d及3d人脸表情识别,降低深度学习网络的复杂度以及抑制网络中不同分支提取的特征之间的冗余,产生了很好的经济效益和社会效益。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的网络结构及其流程示意图;
图2是本发明的fe2dnet和fe3dnet的网络结构示意图;
图3是本发明的gwp操作结构流程示意图;
图4是本发明的正交引导模块结构流程示意图。
具体实施方式
参看图1~图4所示,本具体实施方式采用的技术方案是:它利用人脸点云数据生成三张属性图,分别为深度图、方位图、立面图,所述的深度图、方位图、立面图合成一个三通道的rgb图,所述的rgb图作为网络中某一条支路的输入,减少了模型的参数量。
进一步的,所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,引入一个正交模块保证在特征融合时特征是正交的。
进一步的,所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,特征提取部分使用两个不同结构的网络分支来分别提取2d人脸图和3d属性图的特征,分别定义为fe2dnet和fe3dnet,fe2dnet是vgg网络的变形,而fe3dnet则是resnet的衍生。
进一步的,所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,采用全局加权池化(gwp)层来取代gap层,不同与通用物体,在人脸表情识别任务中,输入cnn网络的图像都是经过关键点对齐的,以至于在深层的特征图中,每个像素都代表着输入图像的某个特定区域,包含固定的语义信息。嘴巴,鼻子,眼睛等重要区域对表情的正确分类起着至关重要的作用,需要额外的关注这些区域的语义信息。直接使用gap,直接将所有像素求平均,那么这些关键区域的语义信息则很可能被忽略掉。
进一步的,所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,每张特征图均设置有与之大小相同的权重图,权重图中的权值可由梯度下降更新,输出的特征向量由特征图和权重图点积计算得到,其计算如下公式所示:
进一步的,所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,两条通道的输入图像都是来自于同一个人脸的2d灰度图和3d属性图,特征提取器提取到的特征向量v1和v2可能会存在冗余,因此在进行特征融合之前,让v1和v2经过一个正交引导模块,使得输出的特征向量f1和f2正交,去除掉两个向量之间的冗余部分。正交引导模块是由一层全连接层和relu层构成。
进一步的,所述的一种基于正交引导学习的多模态2d及3d人脸表情识别,正交引导模块分别以v1和v2作为输入,通过全连接层对其进行转换,并输出两个正交特征f1和f2,设计一个正交损失函数lorth来监督正交引导模块权重的更新,以确保f1和f2之间的正交性。lorth的公式定义如下:
本发明的工作原理:一种基于正交引导学习的多模态2d及3d人脸表情识别,利用人脸点云数据生成三张属性图,分别为深度图、方位图、立面图,所述的深度图、方位图、立面图合成一个三通道的rgb图,引入一个正交模块保证在特征融合时特征是正交的,在进行特征融合之前,我们先让v1和v2经过一个正交引导模块,使得输出的特征向量f1和f2正交,去除掉两个向量之间的冗余部分。
采用上述技术方案后,本发明有益效果为:以该发明一种基于正交引导学习的多模态2d及3d人脸表情识别,降低深度学习网络的复杂度以及抑制网络中不同分支提取的特征之间的冗余,产生了很好的经济效益和社会效益。
以上所述,仅用以说明本发明的技术方案而非限制,本领域普通技术人员对本发明的技术方案所做的其它修改或者等同替换,只要不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!