基于离散差分进化的多策略优化X结构最小树构建方法与流程
本发明属于集成电路计算机辅助设计
技术领域:
,具体涉及超大规模集成电路布线中x结构steiner最小树的构建。
背景技术:
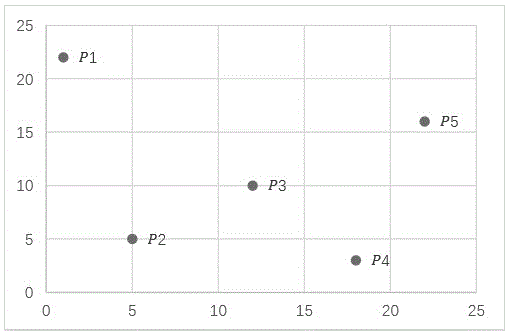
:smt(steinerminimumtree,smt)问题是在给定引脚集合的基础上,通过引入额外的点(steiner点)来寻找一棵连接这些引脚集合的具有最小代价的布线树。因此,smt的构建是超大规模集成电路(verylargescaleintegration,vlsi)布线中的重要环节之一。随着vlsi制造工艺的不断进步和发展,互连线效应逐渐成为影响芯片性能的重要因素。然而,目前大多数布线算法的研究都是基于曼哈顿结构展开的,这种基于曼哈顿结构的布线模型要求引脚之间的走线方式只能是水平方向和垂直方向,导致芯片中互连线的线长优化更加困难。而非曼哈顿结构由于具有更多的走线方向,能够更加充分利用布线资源,从而提高布线质量,改善芯片的性能。为了更好地开展非曼哈顿结构下的布线工作,非曼哈顿结构steiner最小树的构建是关键的一步。x结构是非曼哈顿结构的一种,除了水平和垂直方向,引脚之间的走线还可以使45°和135°方向。而现有的x结构steiner最小树(x-architecturesteinerminimumtree,xsmt)构建算法主要分为精确算法和启发式算法。随着问题规模地不断扩大,这些算法要么面临时间复杂度的剧增,要么极易陷入局部极值,很难得到一个高质量的解方案。因此,迫切需要一种高效可行的x结构steiner最小树构建方法以提高vlsi布线质量,最终优化芯片的性能。技术实现要素:有鉴于此,本发明的目的在于提供一种基于离散差分进化的多策略优化x结构最小树构建方法,能够得到更大的搜索空间,更小的布线树线长,优化布线树拓扑结构,减少布线资源的冗余。为实现上述目的,本发明采用如下技术方案:一种基于离散差分进化的多策略优化x结构最小树构建方法,包括以下步骤:步骤s1:读取待测试电路引脚信息,引脚按x轴坐标升序、y轴坐标升序的方式进行排序,设置迭代次数、阈值及交叉概率cr;步骤s2:对种群进行初始化,并且计算初始种群每个个体的适应值,初始化自适应参数f;步骤s3:判断算法迭代次数是否达到阈值;步骤s4:若未达到阈值,则从策略池随机选择一种变异策略,经过变异、交叉后得到儿子个体;若达到阈值,则根据传统的差分进化算法对种群进行变异、交叉操作;步骤s5:采用免疫克隆选择策略,经选择、克隆、变异、消亡四个步骤得到个体加入种群中;步骤s6:判断迭代是否满足终止条件,如果满足,则迭代终止输出最终种群,否则返回步骤s3继续下一次迭代更新;步骤s7:采用精炼策略,对最终种群中的每个个体搜索其共享程度最大的子结构,得到布线树最优方案。进一步的,所述适应值计算由如下公式所示:fitness(tx)=length(tx)其中其中,length(ei)表示在xsmt的边集合中边ei的长度。进一步的,所述步骤s2采用prim算法初始化种群中的个体,t为最小生成树集合,s为起始引脚点集合,v为引脚点集合,s为随机选取的起点。进一步的,所述策略池中的变异策略包括六种,每种策略用de/a/b来表示,其中de表示差分进化,a表示基向量的选择方式,b表示算子中差分向量的个数,由如下公式所示:(1)、de/rand/1:vi,g=xr1,g+f*(xr2,g-xr3,g)(2)、de/rand/2:vi,g=xr1,g+f*(xr2,g-xr3,g)+f*(xr4,g-xr5,g)(3)、de/best/1:vi,g=xbest,g+f*(xr1,g-xr2,g)(4)、de/best/2:vi,g=xbest,g+f*(xr1,g-xr2,g)+f*(xr3,g-xr4,g)(5)、de/current-to-best/1:vi,g=xi,g+f*(xbest,g-xi,g)(6)、de/rand-to-best/1:vi,g=xr0,g+f*(xbest,g-xr0,g)+f*(xr1,g-xr2,g)其中:r0≠r1≠r2≠r3≠r4≠r5≠i∈{1i2,…,np},xr,g表示第g次迭代种群中的随机个体,xbest,g表示第g次迭代时的全局最优解,缩放因子f∈[0,2]。进一步的,所述免疫克隆选择策略具体为:(1)选择:在差分进化算法一次变异、交叉、选择后,将当前种群中的所有个体按照适应值的大小进行排序,选择其中适应值排名前n的优秀的粒子组成临时种群,其中n的值:n=k×np其中k=0.2,np为种群大小;(2)克隆:对临时种群的粒子进行扩增,扩增数量依据如下式所示,生成临时克隆群体c={c1,c2,…,cni}k∈(0,1)其中ni为临时种群中第i个粒子的扩增数量,n为临时种群的粒子数,b为常数1,确保扩增数量大于等于1,k为0到1之间随机数,round()为取整;(3)变异:对于临时克隆种群的每个粒子逐个进行变异,变异策略采用更改布线树拓扑结构加连接方式变异,对于临时克隆种群中的每个个体随机选取e条边e∈[1,10],更改该边的连接方式,从四种连接方式,包括0选择、1选择、2选择、3选择中的一种,重新选择该边的的两端节点,此过程采用并查集的思想,保证变异后得到的是一棵合法树,得到一个变异种群m={m1,m2,…,mni},t的值由下式得到k∈(0,1)其中n为引脚数;(4)消亡:临时种群的个体pi经过克隆、变异后得到ni个个体的集合m={m1,m2,…,mni},在集合中选择适应值最优的个体mbest,若fitness(mbest)<fitness(pi),则将个体tbest加入当前迭代种群中,变异集合t中其余变异个体全部消亡,若fitness(tbest)≥fitness(pi),则变异集合t中的所有个体全部消亡。进一步的,所述精炼策略具体为:(1)对于最终种群,对种群中的每一个个体进行精炼,计算种群中的每一个体中每个点pi的度,在树的定义中,结点的度即为该点所连接边的数量,记为di;(2)对于一条边的走线方式有4种,若点pi的度为di,则该点可能存在子结构为种,枚举每一种子结构,以边的共享程度为衡量依据,记录其共享程度,对其进行排序,每次选取共享程度最大的子结构,结合并查集方法,不断获取子结构,从而构造出一棵合法树。本发明与现有技术相比具有以下有益效果:本发明使得在相同种群数与迭代次数中,能够得到更大的搜索空间,更小的布线树线长,优化布线树拓扑结构,减少布线资源的冗余。附图说明图1是本发明一实施例中xsmt引脚布线图;图2是本发明一实施例中x结构模型:图中(a)为0选择;(b)为1选择;(c)为2选择;(d)为3选择;图3是本发明一实施例中两种新型运算方法示意图,图中(a)为运算一;(b)为运算二;图4是本发明方法流程图。具体实施方式下面结合附图及实施例对本发明做进一步说明。在本实施例中,参考图1,xsmt问题模型具体为:与传统的曼哈顿结构布线不同,在xsmt问题中设计增加了两种走线方式,即在原来的水平走线与垂直走线的基础上加入了45°与135°两种走线方式。在xsmt问题中引入了steiner点的概念,steiner点存在于两个相互连接的引脚中,steiner点的固定决定了两个引脚间的走线方式。xsmt问题模型示例如下,在给定的一组引脚p={p1,p2,···,pn}中,pi代表第i个待连接的引脚,n表示引脚个数,引入笛卡尔坐标系,每个引脚点pi在坐标系中对应的坐标为(xi,yi),现给出5个引脚p={p1,p2,p3,p4,p5},每个引脚所对应的坐标由表1所示,对应的引脚分布图如图1所示。表1引脚坐标信息引脚p1p2p3p4p5坐标(1,22)(5,5)(12,10)(18,3)(22,16)关于xsmt问题的一些相关定义如下:定义1.pseudo-steiner点假设除引脚点外的连接点称为pseudo-steiner点,记作ps点。假设引脚a=(x1,y1),引脚b=(x2,y2)是连线ab的两个端点,且有x1<x2,有如下定义:定义2.0选择如图2中(a)所示,从a引垂直边至s点,再从s引x结构边至b。定义3.1选择如图2中(b)所示,从a引x结构边至s点,再从s引垂直边至b。定义4.2选择如图2中(c)所示,从a引垂直边至s,再从s引水平边至b。定义5.3选择如图2中(d)所示,从a引水平边至s,再从s引垂直边至b。请参照图4,本实施例中提供一种基于离散差分进化的多策略优化x结构最小树构建方法,包括以下步骤:步骤s1:读取待测试电路引脚信息,引脚按x轴坐标升序、y轴坐标升序的方式进行排序,设置迭代次数、阈值及交叉概率cr。步骤s2:采用prim算法对种群进行初始化,并且根据适应值公式计算初始种群每个个体的适应值,初始化自适应参数f。步骤s3:根据差分进化算法的流程进行迭代进化操作,在第一阶段的每一次的迭代中,采用ps+e混合策略,即变异操作改变最小树的拓扑结构以及边的走线方式,从策略池选择一种变异策略(根据公式16至公式20),经过变异、交叉后得到儿子个体;在第二阶段,采用ps策略只变换边的走线方式,将策略池修改为策略一,选择算子是基于贪心策略选择儿子个体与原个体中适应值最小的一个,保留到下一代。步骤s4:在每一次迭代结尾采用免疫克隆选择策略,经选择、克隆、变异、消亡四个步骤得到个体加入种群中。s5:检查迭代是否满足终止条件,如果满足,则迭代终止,否则返回s3继续下一次迭代更新。s6:在构建方法的最后采用精炼策略,对最终种群中的每个个体搜索其共享程度最大的子结构。在本实施例中,差分进化算法的基本思想为:随机产生一个初始种群,通过把种群中任意两个个体的向量差与第三个个体求和产生新个体,然后将产生的新个体与当前种群中相对应的个体进行比较,如果新产生的个体的适应值优于当前个体的适应值,通过采用贪婪策略,选择新产生的个体替换当前个体,否则仍保存旧个体。差分进化算法更新策略如下:种群的初始化:随机产生np个个体,每个个体的向量维度为d,如xi,0代表初始化第i个个体,xl是d维个体的下限,xh是d维个体的上限,对应初始化方式如下所示:xi,0=xl+randam(0,1)*(xh-xl)(1)变异算子:在第g次迭代过程中,通过选取第g代种群中三个个体xa,g、xb,g、xc,g,且三个个体不相同,根据变异公式生成新的变异个体vi,g,变异公式如下所示:vi,g=xa,g+f*(xb,g-xc,g)(2)其中a≠b≠c≠i,f为缩放因子在[0,2]之间选择。交叉算子:差分进化算法在第g代交叉过程中,采取如下交叉策略:其中j表示维度,cr为交叉概率,且cr∈[0,1]。选择算子:选择过程采用贪心策略,即选取适应值最优的个体,根据如下公式得到下一代个体:其中f(xi,g)表示第i个个体在g代的适应值。在本实施例中,采用边点对编码表示。因为边点对编码能够较好的保持住种群的最优子结构。在一个引脚分布图中,一个布线树网络中有n个引脚点,其生成树中对应有n-1条边,每条边中引入一个steiner点,故有n-1个steiner点和n-1个选择方式,对每个引脚进行编号,得到编号1,2,3,…,n-1,n,通过记录一条连线的两个端点来确定一条边,外加一位来记录该连线的选择方式,因此在实际编码中一个个体用长度为3×(n-1)数组即可表示,最后在加一位用来表示该个体的适应值大小,即最终编码长度为3×(n-1)+1,如图1的引脚分布图可以用以下字符串表示:13023045034346.284其中130表示引脚点1和3之间以0选择的方式连线,最后一个数字46.284表示该生成树的适应值大小,也是该生成树的非曼哈顿结构线长。在本实施例中,适应值函数具体为:xsmt的布线总长度由生成树的所有边的长度累加得到,公式如下所示:其中length(ei)表示在xsmt的边集合中边ei的长度。一棵xsmt的边集合中,所有边都属于如下四种方式中的一种:分别是水平线,垂直线,45°斜线与135°斜线。将45°斜线逆时针旋转45°可以得到一条垂直线,将135°斜线逆时针旋转45°可以得到一条水平线,这样就可以将四种边转换为两种边,再对所有的水平线与垂直线进行排列,此时xsmt的总长度便可由所有的水平线与垂直线相加得到。将斜边旋转为水平线和垂直线的原因是为了去除重叠的边,如果不将重叠的边去除,计算得到的总长度会比实际的总长度大。一棵x结构steiner树的优秀程度由该布线树的总长度决定,一棵布线树的总长度越小,该布线树的优秀程度越高,因此本文构建方法衡量一棵布线树的适应值大小就是该布线树总长度的大小,适应值计算由如下公式所示:fitness(tx)=length(tx)(6)在本实施例中,采用prim算法初始化种群中的个体,t为最小生成树集合,s为起始引脚点集合,v为引脚点集合,s为随机选取的起点。伪代码如算法1所示:在本实施例中,免疫克隆选择策略的具体步骤如下:(1)选择:在差分进化算法一次变异、交叉、选择后,将当前种群中的所有个体按照适应值的大小进行排序,选择其中适应值排名前n的优秀的粒子组成临时种群,其中n的值可根据公式(7)得到:n=k×np(7)其中k=0.2,np为种群大小。(2)克隆:对临时种群的粒子进行扩增,扩增数量依据如下扩增公式(8)所示,生成临时克隆群体c={c1,c2,…,cni}。其中ni为临时种群中第i个粒子的扩增数量,n为临时种群的粒子数,b为常数1,确保扩增数量大于等于1,k为0到1之间随机数,round()为取整。(3)变异:对于临时克隆种群的每个粒子逐个进行变异,变异策略采用更改布线树拓扑结构加连接方式变异,对于临时克隆种群中的每个个体随机选取e条边e∈[1,10],更改该边的连接方式,从四种连接方式(0选择、1选择、2选择、3选择)中的一种,重新选择该边的的两端节点,此过程采用并查集的思想,保证变异后得到的是一棵合法树,得到一个变异种群m={m1,m2,…,mni},t的值由公式(9)可得。其中n为引脚数量。(4)消亡:临时种群的个体pi经过克隆、变异后得到ni个个体的集合m={m1,m2,…,mni},在集合中选择适应值最优的个体mbest,若fitness(mbest)<fitness(pi),则将个体tbest加入当前迭代种群中,变异集合t中其余变异个体全部消亡,若fitness(tbest)≥fitness(pi),则变异集合t中的所有个体全部消亡。免疫克隆选择策略伪代码如算法2所示。在本实施例中,策略池具体包括的变异策略有六种,每种策略用“de/a/b”来表示,其中de表示差分进化,a表示基向量的选择方式,b表示算子中差分向量的个数,由如下公式所示:(1)、de/rand/1:vi,g=xr1,g+f*(xr2,g-xr3,g)(10)(2)、de/rand/2:vi,g=xr1,g+f*(xr2,g-xr3,g)+f*(xr4,g-xr5,g)(11)(3)、de/best/1:vi,g=xbest,g+f*(xr1,g-xr2,g)(12)(4)、de/best/2:vi,g=xbest,g+f*(xr1,g-xr2,g)+f*(xr3,g-xr4,g)(13)(5)、de/current-to-best/1:vi,g=xi,g+f*(xbest,g-xi,g)(14)(6)、de/rand-to-best/1:vi,g=xr0,g+f*(xbest,g-xr0,g)+f*(xr1,g-xr2,g)(15)其中:r0≠r1≠r2≠r3≠r4≠r5≠i∈{1,2,…,np},xr,g表示第g次迭代种群中的随机个体,xbest,g表示第g次迭代时的全局最优解,缩放因子f∈[0,2]。在阐述基于xsmt问题的多变异策略前,需要先要给出两种运算符号的定义。定义a为粒子x1的边集,b为粒子x2的边集,全集为a∪b,定义以下两种运算符:ab:表示为求a与b的对称差集,即为(a∪b)-(a∩b),如图3(a)所示。a⊕b:首先计算集合c=a-b,再将集合b中边加入集合c中,直至集合c的边集能够构成一棵合法的树为止,如图3(b)所示。给出以上定义后,接下来讨论基于xsmt问题提出三种新型变异策略构成的策略池:变异策略1:de/current-to-best(gbest+pbest)/1,该变异策略中,第一部分的基向量为当前个体,差分向量为当前个体与当前个体的局部最优个体运算产生,经公式(16)运算得到个体t,第二部分的基向量为个体t,差分向量为个体t与全局最优个体运算产生,经公式(17)运算得到目标变异个体vi,g。该变异策略能够保留当前个体与最优个体(包括全局最优个体与局部最优个体)的共同边,并且有50%的几率将最优个体中的边替换当前粒子的边,使得当前种群的个体与最优个体的相似程度提高。变异策略2:de/rand-to-best(gbest+pbest)/1,该变异策略中,第一部分的基向量为当前个体,差分向量由当前种群随机选取一个个体与局部最优个体运算产生,经公式(18)运算得到个体t,第二部分的基向量为个体t,差分向量为当前种群随机选取另一个个体与全局最优个体运算产生,经公式(19)运算得到目标变异个体vi,g,变异公式如下:其中r1≠r2≠i,从种群中随机选择的粒子的结构有较大的概率不同于当前个体与最优个体,使得变异的方向不仅局限于最优个体中的边集。变异策略3:de/current-to-rand/1,该变异策略中,基向量为当前个体,差分向量由当前粒子与种群中随机选取的粒子运算产生,经公式(20)运算得到变异个体vi,g,变异公式如下:种群中的粒子具有多样性,该变异策略的变异方向随机度大,在前期的搜索过程中提高粒子的多样性。在解决xsmt问题中,通常将整个迭代过程分为两个阶段,采用(ps+e)∶ps混合策略,在迭代的前期采用ps+e转换策略即改变最小树的拓扑结构和边的走线方式,后期只采用单纯的ps转换的策略。在多变异策略中,策略的选择在前后其采取不同方案,在前期混合使用三种策略,每种策略从策略池中等概率选取,在后期只使用变异策略1。多变异策略伪代码如算法3所示。在本实施例中,自适应参数f具体为:例如对于变异算子有fi∈[1,2],现定义运算符*:若fi<1,从边集合中随机淘汰n条边{e1,e2,…,en},其中且n的值由公式(22)计算得到:其中|xbest,g|为集合xbest,g的大小。若fi>1,从边集合中随机淘汰n条边{e1,e2,…,en},其中且n的值由公式(23)计算得到:若fi=1,则不对任何边集合进行改动,按原先的运算策略进行。自适应参数f的意义:当前个体xi,g的适应值fi足够接近xbest,g的适应值fbest时,其生成树的部分子结构已经为最优,此时减小fi的值以更大程度保留自身结构,反之应增大fi值以增大变异范围。自适应策略伪代码如算法4所示。在本实施例中,对于全部迭代结束后的最终的搜索结果,种群中的每个个体可能还存在着可以优化的空间。为了搜索每个个体的更优结果,加入了精炼策略,具体步骤如下所示:(1)对于迭代evalutions次后得到的最终种群,对种群中的每一个个体进行精炼,计算种群中的每一个体中每个点pi的度,在树的定义中,结点的度即为该点所连接边的数量,记为di;(2)对于一条边的走线方式有4种,若点pi的度为di,则该点可能存在子结构为种,枚举每一种子结构,以边的共享程度为衡量依据,记录其共享程度,对其进行排序,每次选取共享程度最大的子结构,结合并查集方法,不断获取子结构,从而构造出一棵合法树。精炼策略伪代码如算法5所示:在本实施例中,主要参数有:种群大小np、迭代次数evaluations、阈值threshold、自适应参数f、交叉概率cr。对比实验中,将参数均设为np=100,evaluations=500,threshold=0.4,对于自适应参数f在上文中已经给出详细介绍,交叉概率cr同样采用自适应策略,具体如下:其中crl=0.1,cru=0.6,fi,fmin,fmax,分别表示当前个体的适应值,种群中最小适应值个体,种群中最大适应值个体和种群中平均适应值个体。以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1