一种基于图像清晰度的车辆图像语义分割方法与流程
本发明属于计算机视觉技术领域,具体涉及基于深度学习的语义分割技术,针对车辆图像这一特定类别,结合图像清晰度获得更高精确度的语义分割结果。
背景技术:
图像语义分割技术作为计算机视觉领域经典和基础研究课题,不仅应用广泛,在场景解析、自动驾驶、人机交互、图像搜索引擎等领域具有重要意义,而且对于后续处理图像内容将产生直接影响,所以一直以来,图像语义分割技术都是计算机视觉领域最为活跃的一部分,许多研究人员先后对此做出巨大贡献。
图像语义分割是从像素水平,识别、理解并区分图像中的内容,对图像中的每一个像素点予以相应的类别,因此也可以将之视为密集预测问题,这是一项富有挑战性和意义的课题。
传统的语义分割主要有两大类,基于非监督的分割方法和基于概率图模型的分割方法。基于非监督的分割方法通常依靠提取图片的低级特征,检测一致的区域或区域的边界,从而获得分割的结果,但分割的结果没有语义的标注,因此不能算作严格意义上的语义分割。基于概率图的分割方法则是利用参数统计方法,基于几个简单的特征对图像进行过渡分割,然后使用马尔可夫随机场(mrf)方法,对每个像素点进行分类,选取概率高的作为分类类别。
随着计算机算力的提升,深度学习取得了突飞猛进的发展,研究人员逐步将深度学习引入到图像语义分割领域中,取得了卓越的成果。在这一过程中,long等人在2015年提出的全卷积神经网络fcn(fullyconvolutionalnetwork)无疑是当中的开山之作,该模型创新性地将深度卷积神经网络最后的全连接层替换为卷积层,实现对任意大小的输入图像进行语义分割,形成了端到端、像素点到像素点的网络框架,从此语义分割进入崭新的时代,越来越多基于fcn的分割网络被提出。badrinarayananv等人提出的segnet网络,在进行池化操作时存储最大池化索引,解码器使用在相应编码器的最大池化索引来执行非线性上采样,上采样的特征图是稀疏的,然后与可训练的滤波器卷积以生成密集的特征图,在减少计算量的同时提高了分割的准确率。chen等人则先后发表了deeplab系列论文,先后引入了膨胀卷积、空间金字塔池化等模块,在保留输入图像信息的同时结合多尺度的特征图,从而实现更好的分割效果。
本发明针对监控系统下的车辆图像,根据获得图像的清晰度,结合语义分割主干网络的训练过程,生成更加适合监控系统的车辆图像分割网络。
技术实现要素:
本发明针对现有技术的不足,提供一种基于图像清晰度的车辆图像语义分割方法。本发明针对监控系统获得车辆图像进行图像语义分割,由于监控系统下,车辆处于运动状态,获得的车辆图像可能会出现不同程度的模糊,从而给分割带来较大误差,导致后续识别、追踪等操作难以进行。针对可能会出现的因运动导致的车辆图像模糊,本发明设计了一个清晰度判别模块,并将结果导入总的损失函数中,实现更加精确的分割效果。
本发明解决其技术问题所采用的技术方案如下:
步骤1、设计清晰度判别模块:
本发明采用tenengrad函数来对输入的车辆图像进行清晰度判定,tenengrad函数采用sobel算子分别提取水平和垂直方向的梯度值,基于tenengrad函数的图像清晰度d(f)定义为:
d(f)=∑y∑x|g(x,y)|(1)
其中,g(x,y)的表达如下:
其中,gx(x,y)是像素点(x,y)处于sobel水平方向边缘检测算子gx的卷积,gy(x,y)是像素点(x,y)处于sobel垂直方向边缘检测算子gy的卷积,算子gx和gy分别为:
根据清晰度判别模块计算所得的d(f),设计清晰度损失函数ld如下:
ld=-logd(f)(5)
再将清晰度损失函数ld加入语义分割主干网络的损失函数中,共同作用于网络训练过程。
步骤2、语义分割主干网络训练
本发明采用deeplabv3+作为语义分割主干网络,将输入图像沿语义分割主干网络依次进行下采样、池化操作,得到高分辨率特征图;将得到的高分辨率特征图分别进行不同比例的膨胀卷积(分别为6,12,18,24),再经过空间金字塔池化模块,以concatenate操作将所得的不同比例膨胀卷积下的特征图拼接在一起,从而融合多尺度的上下文信息,最后经过卷积操作得到最终的预测结果;对预测结果进行上采样,从而得到与原输入图像大小一致的高精度像素级语义分割结果图。
步骤3、输出语义分割结果
网络训练完成后,得到针对监控系统下获得的车辆图像的语义分割网络,对于给定输入测试图像,经过该语义分割网络,在清晰度判别模块和语义分割主干网络的共同作用下,能够得到输入图像的高精度像素级语义分割结果图。从而为后续的相关操作提供可能。
本发明的有益效果:
本发明提出了一种基于图像清晰度的车辆图像语义分割方法,针对监控系统下的车辆图像可能会存在的模糊问题,从而导致语义分割精度不高,设计了一种清晰度判别模块,对于清晰度做出判定,根据判别结果,本发明设计了相应的损失函数ld,并将其加入到语义分割主干网络的损失函数中,从而使网络具有判别车辆图像清晰度的能力,增加了网络对车辆图像语义分割的针对性,提高语义分割主干网络的分割精度。
附图说明
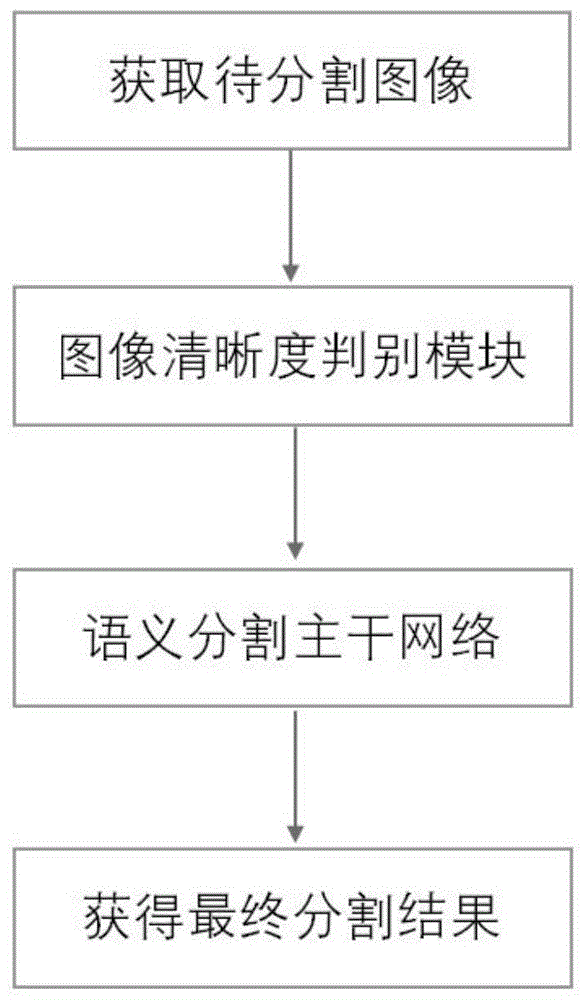
图1为本发明的总体流程。
具体实施方式
下面结合附图和实例对本发明做进一步详细说明,但是本发明不局限于该实例。
veri是一个城市监控系统下大规模车辆图像的基准数据集,是由20台摄像机在1km2的城市区域内24小时拍摄而来,包含776辆车的超过50000张图像,车辆图像是在真实世界的无约束监控系统下捕获的,因此具有很高的现实意义,对车辆图像进行人工标注,类别共59种包括背景在内,本实例基于上述发明方法,如图1所示,其步骤如下:
步骤1:数据集处理
从veri数据集中选取2000张作为训练图像集,选取1000张图像作为测试图像集,并对训练图像数据集进行数据增强操作,使训练图像的数量增加到10000张。
步骤2:初始化语义分割主干网络
导入deeeplabv3+网络对应层的参数,对语义分割主干网络进行初始化,加速训练过程中网络收敛所需时间。
步骤3:训练添加有清晰度判别模块的语义分割主干网络;
将输入图像和对应的groundtruth导入到网络中,首先经过清晰度判别模块,对每一张输入图像依次进行如下操作:
d(f)=∑y∑x|g(x,y)|(1)
其中,(x,y)对应输入图像的每一个像素点,而g(x,y)的计算方式为:
其中,gx(x,y)是像素点(x,y)处于sobel水平方向边缘检测算子gx的卷积,gy(x,y)是像素点(x,y)处于sobel垂直方向边缘检测算子gy的卷积,算子gx和gy分别为:
将清晰度判别模块计算所得的d(f)作为清晰度损失函数导入到总损失函数中:
ld=-logd(f)(5)
将输入车辆图像和groundtruth导入语义分割主干网络,采用随机梯度下降算法优化导入清晰度损失函数后的总损失函数,运用反向传播算法更新语义分割主干网络的参数,直到总损失函数的值不再下降,结束训练。
为了加速语义分割主干网络的收敛,引入参数学习的的学习率,学习率按照如下公式进行变化:
公式(6)中,t为迭代次数,l0为初始学习率,值为0.007,power为动量,值为0.9。
步骤4:对测试图像集进行语义分割
在对测试图像集进行语义分割的过程中,不需要清晰度判别模块,可以将步骤3中所得网络中的清晰度判别模块去掉,简化网络模型用于部署,将测试图像集依次导入简化后的网络中,即可得到高进度的语义分割结果。通过清晰度判别模块,网络对于清晰度做出判定,根据判别结果,本发明设计了相应的损失函数ld,并将其加入到语义分割主干网络的损失函数中,从而使网络具有判别车辆图像清晰度的能力,增加了网络对车辆图像语义分割的针对性,提高语义分割主干网络的分割精度。
上述实例旨在进一步阐述本发明的实施过程,其描述较为具体和详实,但不意味着本发明只有这一种用途,在不脱离本发明构思的前提下,还可以做出若干改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!