一种用于数论变换乘法的基16运算电路的制作方法
本发明涉及一种运算电路,特别是涉及一种用于数论变换乘法的基16运算电路。
背景技术:
大整数乘法除了传统的长乘法,还有
一个1048576点的数论变换可以被分解成5级基16运算单元和旋转因子乘法的运算。其中旋转因子的计算可以事先计算好并存于rom中,需要使用时直接读取即可。基16运算的计算量占数论变换的90%以上,它的优化对数论变换的效率至关重要。
大整数乘法器fpga设计与实现,谢星等,电子与信息学报,2019年。该论文描述了一种基于
技术实现要素:
针对上述现有技术的缺陷,本发明提供了一种用于数论变换乘法的基16运算电路,解决基16运算电路功耗及资源开销大的问题。
本发明技术方案如下:一种用于数论变换乘法的基16运算电路,包括:
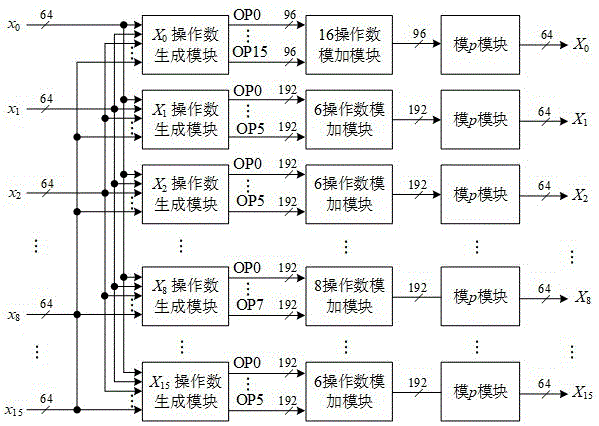
操作数生成模块,设有16个,16个操作数生成模块编号为xk,k=0,1,2,...,15,每个所述操作数生成模块包括分割电路、合并电路和填充零电路,所述分割电路对16个输入数据的每一个进行高位填零后以12比特为一个字分割为6个字,分割后的输入数据为xn,m,0≤n<16,0≤m<6,所述合并电路将所述分割为16×6个字的输入数据形成操作数输出,16个所述输出操作数生成模块的所述分割电路中1个输出为16个96比特操作数、12个输出为6个192比特操作数以及3个输出为8个192比特操作数输出,所述填充零电路将所述合并电路输出操作数时的空位填入“0”;
操作数模加模块,对每个所述操作数生成模块的输出的操作数进行模加;
以及,
模p模块,实现将每个所述操作数模加模块输出的数据对质数p取模后输出,所述质数p=264-232+1。
进一步地,所述输出为16个96比特操作数的操作数生成模块编号为x0,每个96比特操作数的后6个字为输入的数据,前2个字被分配为零。
进一步地,所述输出为6个192比特操作数的操作数生成模块编号为xk,k为奇数,每个操作数opm由32个不同的输入数据xn,m,0≤n<16,使用相同的字索引m,0≤m<6合并而成,xn,m的最低位在opm中的位置,是由12×(m+nk)(mod192)计算所得。
进一步地,所述输出为8个192比特操作数的操作数生成模块编号为x4、x8和x12,8个操作数分为4组,每组2个操作数,op0和op1是一组,op2和op3是一组,以此类推,每组内的操作数op2j和op2j+1由24个不同的输入数据xn,m,4j≤n≤4j+3,0≤m<6合并而成,xn,m的最低位在op2j和op2j+1中的位置,是由12×(m+nk)(mod192)计算所得,xn,m优先置于op2j中,如op2j中该位置已经被占用,则置于op2j+1中对应的位置。
进一步地,所述输出为6个192比特操作数的操作数生成模块编号为除x0、x4、x8和x16外的xk,k为偶数,6个操作数分为2组,op0至op2是一组,op3至op5是一组,每组内的操作数op3j至op3j+2由48个不同的输入数据xn,m,8j≤n≤8j+7,0≤m<6合并而成,xn,m的最低位在op3j至op3j+2中的位置,是由12×(m+nk)(mod192)计算所得,xn,m以2个字为周期合并操作数,优先置于op3j至op3j+2中索引号较小的op中。
本发明所提供的技术方案的优点在于:
利用操作数移位后的“零填充”的空位,合并数论变换乘法中基16运算的操作数,将操作数从现有技术的256个合并到112个,大幅减小了计算开销,提高了基16运算的计算效率。
附图说明
图1为本发明用于数论变换乘法的基16运算电路的总体结构示意图。
图2为操作数生成模块中分割电路对输入数据填充零分割方法示意图。
图3为操作数生成模块中分割电路示意图。
图4为x0操作数生成模块的合并电路得到的输出数据示意图。
图5为x0操作数生成模块的合并电路示意图。
图6为x1操作数生成模块的合并电路合并后的操作数。
图7为x1操作数生成模块中0号操作数op0的合并电路。
图8为x3操作数生成模块的合并电路合并后的操作数。
图9为x4操作数生成模块的合并电路合并后的操作数。
图10为x2操作数生成模块的合并电路合并后的操作数。
图11为16操作数模加模块的电路示意图。
图12为6操作数模加模块的电路示意图。
图13为8操作数模加模块的电路示意图。
具体实施方式
下面结合实施例对本发明作进一步说明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等同形式的修改均落于本申请所附权利要求所限定的范围内。
基16运算的公式如下
其中,0≤k<16,p是质数,w16是第16个单位根。
在质数p为solinas质数,p=264-232+1。该质数支持高效的取模操作:2192modp=1,296modp=-1,264modp=232-1。利用该质数计算得到的单位根w16=212是2的幂次方的特性,可以将以上的乘加运算,方便地转换为移位和模加运算,降低数论变换的计算复杂性。由此,基16运算可以写成
将每个xn以12比特为一个基本单位,分成6个字,称为xn,m,0≤m<6。xn可以表示为
其中m表示第m个字,xn的数据宽度是64比特,xn,m的数据宽度是12比特,xn,5的有效数据位是4比特。将输入数据分割后,基16运算可以写成以下公式,利用“0填充”可以合并移位后的操作数,减少模加的运算操作数。
请结合图1所示,本实施例涉及的一种用于数论变换乘法的基16运算电路,包括x0至x15共16个操作数生成模块、操作数模加模块和模p模块,其中操作数模加模块根据输入操作数的数量不同分为16操作数模加模块,6操作数模加模块,8操作数模加模块。电路结构上输入的16个64位比特数据作为每一个操作数生成模块的输入,每个操作数生成模块后连接操作数模加模块,每个操作数模加模块后连接模p模块。
操作数生成模块包括分割电路、合并电路和填充零电路,依次对输入的16个64位比特数据进行分割、合并、填充零处理,形成操作数。请结合图2及图3所示,分割电路将每个64比特输入数据xn的最高8比特填充0,形成72比特数据,然后分割成6个字,每个字包含12比特,第6个字因为最高8比特填充0,所以有效数据位是4比特。数据分割能够很容易的用现有硬件实现,几乎没有硬件开销。
以xk,k=0,1,2,...,15对操作数生成模块编号,每个操作数生成模块中的合并电路不同,但可以按照类型分成4组,每组内的电路相似。
组一:x0,共1个;组二:x1、x3、x5等k为奇数的,共8个;组三:x4、x8和x12,共3个;组四:除组一和组三外的k为偶数的,有x2、x6、x10、x14,共4个。
以下分组解释每组的数据合并操作:
组一,即x0操作数生成模块的合并电路。
操作数实际上是对齐的输入数据。换句话说,每个操作数都是从分割电路输出数据的6个连续字中派生得出的。合并电路输出为16个96比特的操作数,每个新的96比特操作数由8个字组成,后6个字为输入的数据,前2个字被分配为零。如图4所示,j号操作数opj有96比特,是将xn置于低72位,高24位填充零得到的,合并电路如图5所示。
组二,x1、x3、x5等奇数操作数生成模块的合并电路。
对于k为奇数的xk操作数生成模块的合并电路,输入是16个64比特输入数据,输出是6个192比特操作数。每个操作数opm由16个不同的数据xn,m,0≤n<16,使用相同的字索引m,0≤m<6合并而成。xn,m的最低位在opm中的位置,是由12×(m+nk)(mod192)计算所得。以下以x1和x3为例说明输出的操作数构成:
x1操作数生成模块的合并电路合并后的操作数,如图6所示。合并后共有6个操作数,每个操作数由16个不同的数据xn,m,0≤n<16,使用相同的字索引m,0≤m<6合并而成。x0,0的最低位在op0中的位置为12×(0+0×1)(mod192)=0,x1,0的最低位在op0中的位置为12×(0+1×1)(mod192)=12,而x0,1的最低位在op1中的位置为12×(1+0×1)(mod192)=12,x15,1的最低位在op1中的位置为12×(1+15×1)(mod192)=0。x1操作数生成模块中0号操作数op0的合并电路如图7所示。
x3操作数生成模块的合并电路合并后的操作数,如图8所示。x0,0的最低位在op0中的位置为12×(0+0×3)(mod192)=0,x1,0的最低位在op0中的位置为12×(0+1×3)(mod192)=36,而x0,1的最低位在op1中的位置为12×(1+0×3)(mod192)=12,x15,1的最低位在op1中的位置为12×(1+15×3)(mod192)=168。
其余的操作数生成模块的合并电路输出的操作数依次类推。
组三,x4、x8和x12操作数生成模块的合并电路。
输入是16个64比特输入数据,输出是8个192比特操作数。8个操作数分为4组,每组2个操作数,op0和op1是一组,op2和op3是一组,以此类推。每组内的操作数op2j和op2j+1由24个不同的数据xn,m,4j≤n≤4j+3,0≤m<6合并而成。xn,m的最低位在op2j和op2j+1中的位置,是由12×(m+nk)(mod192)计算所得。xn,m优先置于op2j中,如op2j中该位置已经被占用,则置于op2j+1中对应的位置。其余的空位全部填“0”。以x4操作数生成模块的合并电路输出数据为例,如图9所示,有4组操作数,每组包括2个合并后的操作数。每个新的192位操作数由16个字组成,它们来自4个不同的输入数据。
组四,除组一和组三外的偶数操作数生成模块
对于k为除0、4、8或12以外的偶数,即k为2、6、10、14的xk操作数生成模块的合并电路,输入是16个64比特输入数据,输出是6个192比特操作数。6个操作数分为2组,每组3个操作数,op0至op2是一组,op3至op5是一组。每组内的操作数op3j至op3j+2由48个不同的数据xn,m,8j≤n≤8j+7,0≤m<6合并而成。xn,m的最低位在op3j至op3j+2中的位置,是由12×(m+nk)(mod192)计算所得。xn,m以2个字为周期合并操作数,优先置于op3j至op3j+2中索引号较小的op中。其余的空位全部填“0”。以x2操作数生成模块的合并电路输出数据为例,如图9所示,有2组操作数,每组包括3个合并后的操作数。第一组包含了op0至op2;第二组包括op3至op5。每个新的192位操作数由16个字组成,它们来自8个不同的输入数据,每个输入数据提供2个连续的字。
根据上述不同组的操作数生成模块得到操作数数量不同,操作数模加模块包括16操作数模加模块,6操作数模加模块,8操作数模加模块。
16操作数模加模块如图11所示,其中csa表示保留进位加法器,cpa表示行波进位加法器,“<<1”表示将保留进位加法器的进位端(carry端)向左移位1比特。16个操作数中保留4i,i=1,2,3,4位置的操作数,其余的操作数每三个输入第一层csa;第一层csa的进位端向左移位1比特与其和数端及4i,i=1,2,3,4位置的操作数输入第二层csa;将每两个第二层csa的和数端及其中一个第二层csa的进位端向左移位1比特输入第三层csa;第三层csa的进位端向左移位1比特、第三层csa的和数端及每两个第二层csa中另一个第二层csa的进位端向左移位1比特输入第四层csa;第四层csa共两个csa,将第二个csa的进位端向左移位1比特、第二个csa的和数端及第一个csa的和数端输入第五层csa(共1个);第五层的csa进位端向左移位1比特、和数端以及第四层第一个csa的进位端向左移位1比特输入第六层csa;第六层的csa进位端向左移位1及和数端输入cpa,结果再输入模加模块。模加模块实现将输入的193比特宽度数据,实现低192位数据与第193位数据相加操作,输出结果与输入数据对质数p同余。
6操作数模加模块如图12所示,其中csa表示保留进位加法器,cpa表示行波进位加法器,“rol1-bit”表示将保留进位加法器的进位端(carry端)向左循环移位1比特。6个操作数每三个输入第一层csa(共两个),将第一个csa的和数端、第二个csa的进位端向左循环移位1比特、第二个csa的和数端输入第二层csa;第二层csa的进位端向左循环移位1比特、第二层csa的和数端及第一层第一个csa的进位端向左循环移位1输入第三层csa;第三层的csa进位端向左循环移位1比特及其和数端输入cpa,结果再输入模加模块。模加模块实现将输入的193比特宽度数据,实现低192位数据与第193位数据相加操作,输出结果与输入数据对质数p同余。
8操作数模加模块如图13所示,其中csa表示保留进位加法器,cpa表示行波进位加法器,“rol1-bit”表示将保留进位加法器的进位端(carry端)向左循环移位1比特。8个操作数中保留第4、8位置的操作数,其余的操作数每三个输入第一层csa;第一层csa的进位端向左循环移位1比特与其和数端及4i,i=1,2位置的操作数输入第二层csa;将第二层第一个csa的和数端、第二个csa的进位端向左循环移位1比特、第二个csa的和数端输入第三层csa;第三层csa的进位端向左循环移位1比特、第三层csa的和数端及第二层第一个csa的进位端向左循环移位1输入第四层csa;第四层的csa进位端向左循环移位1比特及其和数端输入cpa,结果再输入模加模块。模加模块实现将输入的193比特宽度数据,实现低192位数据与第193位数据相加操作,输出结果与输入数据对质数p同余。
模p模块实现对输入的数据对质数p取模。
- 还没有人留言评论。精彩留言会获得点赞!