京剧人物识别方法、设备、存储介质及装置与流程
本发明涉及京剧人物识别的技术领域,尤其涉及京剧人物识别方法、设备、存储介质及装置。
背景技术:
目前,对人物的识别主要采用的都是传统机器学习算法聚焦于脸部,进行实现人脸识别,而对于整体轮廓而言的采用基于深度学习的细粒度图像分类大多也只是面向于鸟类、车类以及花类等对象,针对这些细粒度图像对象由于类间长相相似以及类内由于姿态以及背景不同等因素进行识别。
但是,通过这些细粒度图像的识别过程中,仅仅通过传统的深度学习进行人物识别在采集的样本数量较少的情况下,容易造成识别的准确率不高的问题。
技术实现要素:
本发明的主要目的在于提供京剧人物识别方法、设备、存储介质及装置,旨在解决如何提高京剧人物识别的准确性。
为实现上述目的,本发明提供一种京剧人物识别方法,所述京剧人物识别方法包括以下步骤:
获取当前京剧人物图像信息;
将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息;
根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息;
将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息。
优选地,所述获取当前京剧人物图像信息之前,所述方法还包括:
获取原始京剧人物图像信息;
将所述原始京剧人物图像信息由三原色图像信息转换为灰度图像信息;
获取降采样规则信息,根据所述降采样规则信息对所述灰度图像信息进行降采样,生成预设尺寸的缩略图像信息;
获取所述缩略图像信息边界区域中的噪点像素信息;
根据所述噪点像素信息对所述缩略图像信息进行裁剪,得到当前京剧人物图像信息。
优选地,所述获取所述缩略图像信息边界区域中的噪点像素信息,包括:
获取所述缩略图像信息边界区域中参考像素信息对应的预设方向算子;
将所述预设方向算子与所述缩略图像信息的预设卷积值进行比较,得到预设方向算子与所述缩略图像信息的预设卷积值的差值信息;
将所述差值信息与门槛值进行比较,根据比较结果确定所述缩略图像信息边界区域中的噪点像素信息。
优选地,所述根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息,包括:
根据所述分类信息确定特征区域信息中的像素点集合信息;
根据所述像素点集合信息得到每个像素点的视觉重要权重值;
对所述视觉重要权重值进行归一化,得到每个像素点的相对视觉重要权重值,并根据所述相对视觉重要权重值得到上下文特征向量信息;
根据所述上下文特征向量信息通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息。
优选地,所述根据所述像素点集合信息得到每个像素点的视觉重要权重值,包括:
获取线性仿射变换函数以及系数矩阵;
根据所述像素点集合信息、线性仿射变换函数以及系数矩阵得到每个像素点的视觉重要权重值。
优选地,所述对所述视觉重要权重值进行归一化,得到每个像素点的相对视觉重要权重值,并根据所述相对视觉重要权重值得到上下文特征向量信息,包括:
对所述视觉重要权重值进行归一化,得到每个像素点的相对视觉重要权重值;
对所述相对视觉重要权重值进行线性加权,得到上下文特征向量信息。
优选地,所述将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息之后,所述方法还包括:
获取搜索指令,根据所述搜索指令获取所述目标分类信息对应的标签信息;
根据所述标签信息查找所述目标分类信息对应的京剧人物介绍信息,并将所述京剧人物介绍信息进行展示。
此外,为实现上述目的,本发明还提出一种京剧人物识别设备,所述京剧人物识别设备包括:存储器、处理器及存储在所述存储器上并在所述处理器上运行京剧人物识别程序,所述京剧人物识别程序被所述处理器执行时实现如上文所述的京剧人物识别方法的步骤。
此外,为实现上述目的,本发明还提出一种存储介质,所述存储介质上存储有京剧人物识别程序,所述京剧人物识别程序被处理器执行时实现如上文所述的京剧人物识别方法的步骤。
此外,为实现上述目的,本发明还提出一种京剧人物识别装置,所述京剧人物识别装置包括:
获取模块,用于获取当前京剧人物图像信息;
识别模块,用于将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息;
放大模块,用于根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息;
所述识别模块,还用于将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息。
本发明提供的技术方案,通过获取当前京剧人物图像信息;将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息;根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息;将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息,从而通过京剧人物分类网络结合注意力机制网络实现对京剧人物的识别,达到提高京剧人物识别准确性的目的。
附图说明
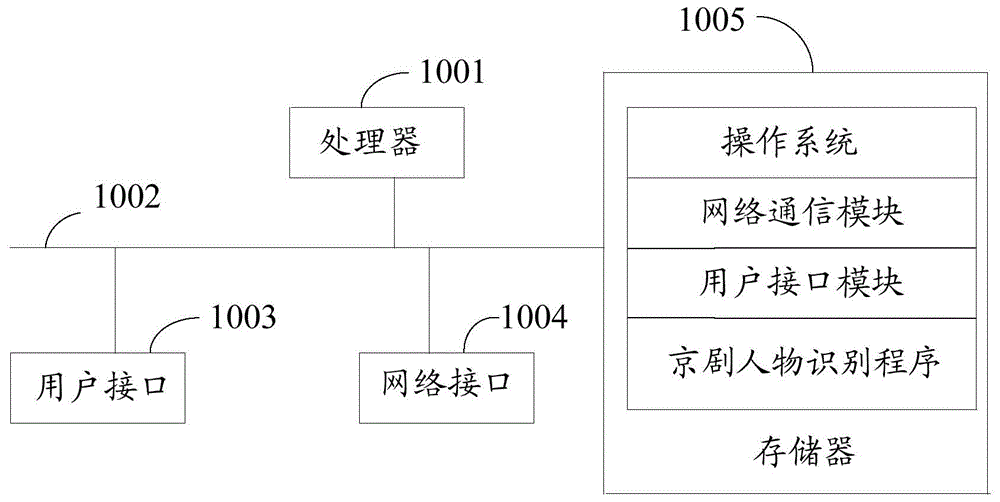
图1是本发明实施例方案涉及的硬件运行环境的京剧人物识别设备结构示意图;
图2为本发明京剧人物识别方法第一实施例的流程示意图;
图3为本发明京剧人物识别方法一实施例的京剧人物区域识别示意图;
图4为本发明京剧人物识别方法一实施例的京剧人物展示示意图;
图5为本发明京剧人物识别方法第二实施例的流程示意图;
图6为本发明京剧人物识别方法第三实施例的流程示意图;
图7为本发明京剧人物识别装置第一实施例的结构框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明实施例方案涉及的硬件运行环境的京剧人物识别设备结构示意图。
如图1所示,该京剧人物识别设备可以包括:处理器1001,例如中央处理器(centralprocessingunit,cpu),通信总线1002、用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display),可选用户接口1003还可以包括标准的有线接口以及无线接口,而用户接口1003的有线接口在本发明中可为通用串行总线(universalserialbus,usb)接口。网络接口1004可选的可以包括标准的有线接口以及无线接口(如wi-fi接口)。存储器1005可以是高速随机存取存储器(randomaccessmemory,ram);也可以是稳定的存储器,比如,非易失存储器(non-volatilememory),具体可为,磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的结构并不构成对京剧人物识别设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及京剧人物识别程序。
在图1所示的京剧人物识别设备中,网络接口1004主要用于连接后台服务器,与所述后台服务器进行数据通信;用户接口1003主要用于连接外设;所述京剧人物识别设备通过处理器1001调用存储器1005中存储的京剧人物识别程序,并执行本发明实施例提供的京剧人物识别方法。
基于上述硬件结构,提出本发明京剧人物识别方法的实施例。
参照图2,图2为本发明京剧人物识别方法第一实施例的流程示意图。
在第一实施例中,所述京剧人物识别方法包括以下步骤:
步骤s10:获取当前京剧人物图像信息。
需要说明的是,本实施例的执行主体为京剧人物识别设备,还可为其他可实现相同或相似功能的设备,本实施例对此不作限制,在本实施例中,以京剧人物识别设备为例进行说明。
在具体实现中,在用户收看电视中播放的京剧视频时,可通过识别指令,根据所述识别指令截取当前播放视频中的京剧人物的图像信息,将截取到京剧人物的图像信息作为当前京剧人物图像信息,以便进行当前京剧人物的识别,其中,所述识别指令可为通过遥控器操作的识别指令,还可为通过电视界面上的菜单进行的识别指令,还可为其他形式的识别指令,本实施例对此不作限制,在本实施例中,以电视机上的操作界面进行识别操作为例进行说明。
在本实施例中,可基于电视播放的京剧视频某一帧图片的静态识别,将视频文件的某一帧的图片截取作为京剧人物分类网络的输入,然后通过训练好的京剧人物分类网络进行分类,得到识别结果。
步骤s20:将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息。
可以理解的是,所述京剧人物分类网络可为基于深度学习训练得到的京剧人物分类网络,还可基于其他网络训练得到的,本实施例对此不作限制,在本实施例中,以基于卷积神经网络为例进行说明,京剧人物的行当,即类别,包括生旦净丑等四大类别,生角包括老生(中年男性)和小生(青年男性),旦角包括青衣(中年女性)、花旦(青年女性)以及老旦(老年女性),净角包括花脸,即性格特征明显的特殊群体,例张飞或者包拯,丑角的特征为丑,即特征明显的特殊群体,插科打诨的人,其中,所述分类信息包括行当的类别,即分类信息包括老生或者花旦等行当信息。
在本实施例中,老生的脸谱妆较浅、均有髯口,即胡子;小生脸谱妆相较于老生而言更浓,不戴髯口,所以可以对其相应特征明显的区域进行标记,从而实现京剧人物的分类信息。
在具体实现中,获取京剧人物分类网络,将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息,为了获取京剧人物分类网络,首先需要充实各个行当(类别)的图片数据量,采集一定图片后,进行行当归类并对部分图片的特征区域进行辅助框标记,以“老生”和“花脸”为例,识别京剧人物是老生还是花脸,可以通过脸部妆容图以及髯口的不同来区分,“老生”的脸妆比较淡,和普通人造型无异,“老生”的胡子是三片,即三髯,“老生”的造型一般比较规矩,通常穿戴颜色较淡的衣物,且没有较大幅度的肢体变化,“花脸”的脸妆特色鲜明,较夸张,呈现有五颜六色的脸谱,“花脸”的胡子是一片,即满髯;“花脸”的造型一般比较夸张,通常伴有佩剑、令旗、将袍等物品,通过对京剧人物的脸部、胡子以及整体进行标注,如图3所示京剧人物区域识别示意图,其中,虚线框标注的为京剧人物的脸部、胡子以及整体信息,然后记录下相应框的坐标,基于卷积神经网络对特征区域进行学习训练,得到京剧人物分类网络。
步骤s30:根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息。
在本实施例中,还设有注意力机制网络,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息,继续如图3所示的特征区域,将特征区域中的特征信息进行放大处理,通过采用基于视觉注意力机制网络以及基于目标块标记的半监督学习训练网络,具体表现为视觉系统在看东西的时候,先通过快速扫描全局图像获得需要关注的目标区域,而后抑制其他无用信息以获取感兴趣的目标,同时,再对特征区域通过特征框标记加以辅助提升训练效果。
在具体实现中,首先通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息,注意力机制网络通过京剧人物分类网络的最后一层卷积层作为输入,计算出特征区域的决定性因素信息,即中心点等坐标信息,然后通过图像分割操作实现特征区域放大。
在本实施例中,通过放大剪切出来的图像重新作为京剧人物分类网络的数据输入进分类网络,从而提高了脸部以及胡子等重要特征在图像中的占比率,使识别效果有显著的提高。
步骤s40:将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息。
在本实施例中,所述京剧人物识别网络包含三个级别子网络,每个级别子网络的网络结构都是一样的,只是网络参数不一样,每个级别子网络又包含两种类型的网络:京剧人物分类网络和注意力机制网络,京剧人物分类网络对标记框的数据集进行特征提取并分类,然后注意力机制网络基于提取到的特征进行训练得到注意集中区域信息,再将注意集中区域裁剪出来并放大,作为第二个级别网络的输入,重复进行三次就得到了三个级别网络的输出结果,最后将三个级别网络的结果进行融合得到输出,这样反复进行的学习调参,可以使模型对不同类别脸部的纹理、身体信息特征,例如胡子,服饰上的特殊饰物,例如头冠、御带以及水袖等等特征信息进行识别,最终达到对不同类别的京剧人物的识别效果。
进一步地,所述步骤s40之后,所述方法还包括:
获取搜索指令,根据所述搜索指令获取所述目标分类信息对应的标签信息。根据所述标签信息查找所述目标分类信息对应的京剧人物介绍信息,并将所述京剧人物介绍信息进行展示。
需要说明的是,所述搜索指令可为基于电视界面进行搜索操作,还可通过其他方式进行操作,本实施例对此不作限制,在本实施例中,以基于电视界面进行搜索操作为例进行说明。
如图4所示的京剧人物展示示意图,当在观看京剧视频时,选择某一即时场景,点击电视左下角的一个搜索按钮,后台就会调用中间件接口,对图片中出现的京剧人物进行分析,图片经过京剧人物识别网络得到各类别信息的识别率,选取识别率最大的行当类别,展示其事先标记好的标签信息。随后就能通过弹出信息框的形式向用户展示这些基本信息,即京剧人物介绍信息,用户也就能更深一步的了解这一京剧人物所属行当的基本信息。
本实施例通过上述方案,通过获取当前京剧人物图像信息;将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息;根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息;将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息,从而通过京剧人物分类网络结合注意力机制网络实现对京剧人物的识别,达到提高京剧人物识别准确性的目的。
参照图5,图5为本发明京剧人物识别方法第二实施例的流程示意图,基于上述图2所示的第一实施例,提出本发明京剧人物识别方法的第二实施例。
第二实施例中,所述步骤s10之前,所述方法还包括:
步骤s101,获取原始京剧人物图像信息。
需要说明的是,所述当前京剧人物图像信息为已经经过处理后的图像信息,为了保证的识别的准确性,需要预先对原始京剧人物图像信息进行处理,保证当前京剧人物图像信息的有效性。
步骤s102,将所述原始京剧人物图像信息由三原色图像信息转换为灰度图像信息。
步骤s103,获取降采样规则信息,根据所述降采样规则信息对所述灰度图像信息进行降采样,生成预设尺寸的缩略图像信息。
在本实施例中,所述降采样规则信息可为降采样倍数,根据所述降采样倍数对所述灰度图像信息进行降采样,生成预设尺寸的缩略图像信息,例如210*260尺寸的图像信息,经过降采样之后得到110*84的缩略图。
步骤s104,获取所述缩略图像信息边界区域中的噪点像素信息。
在具体实现中,通过获取所述缩略图像信息边界区域中参考像素信息对应的预设方向算子;将所述预设方向算子与所述缩略图像信息的预设卷积值进行比较,得到预设方向算子与所述缩略图像信息的预设卷积值的差值信息;将所述差值信息与门槛值进行比较,根据比较结果确定所述缩略图像信息边界区域中的噪点像素信息。
可以理解的是,所述预设方向算子可为四方向算子,例如水平、垂直、斜左上以及斜左下四个方向,还其他参数的方向算子,本实施例对此不作限制,在本实施例中,以四方向算子为例进行说明,在进行噪声识别时,当4个方向算子与源图像像素的卷积的最小值val大于或等于门槛tol时,则当前像素点被认为是一个噪声像素,采用中值滤波进行去噪,否则认为它是信号像素而保持不变。
步骤s105,根据所述噪点像素信息对所述缩略图像信息进行裁剪,得到当前京剧人物图像信息。
本实施例通过上述方案,通过对原始京剧人物图像信息进预处理,将原始京剧人物图像信息转换为有效的当前京剧人物图像信息,从而保证京剧人物识别的准确性。
参照图6,图6为本发明京剧人物识别方法第三实施例的流程示意图,基于上述图2所示的第一实施例,提出本发明京剧人物识别方法的第三实施例。
第三实施例中,所述步骤s30,包括:
步骤s301,根据所述分类信息确定特征区域信息中的像素点集合信息。
在本实施例中,所述特征区域信息可为在预设分类信息与区域信息对应关系中查找到的区域信息,例如通过京剧人物分类网络初步识别当前京剧人物为老生时,则对脸部妆容以及髯口等区域通过注意力机制网络进行方法处理。
步骤s302,根据所述像素点集合信息得到每个像素点的视觉重要权重值。
在具体实现中,通过获取线性仿射变换函数以及系数矩阵;根据所述像素点集合信息、线性仿射变换函数以及系数矩阵得到每个像素点的视觉重要权重值,即根据所述像素点集合信息、线性仿射变换函数以及系数矩阵采用以下公式(一)得到每个像素点的视觉重要权重值:
其中,
步骤s303,对所述视觉重要权重值进行归一化,得到每个像素点的相对视觉重要权重值,并根据所述相对视觉重要权重值得到上下文特征向量信息。
在具体实现中,对所述视觉重要权重值进行归一化,得到每个像素点的相对视觉重要权重值;对所述相对视觉重要权重值进行线性加权,得到上下文特征向量信息,即通过以下公式(二)得到每个像素点的相对视觉重要权重值:
其中,
通过以下公式(三)对所述相对视觉重要权重值进行线性加权,得到上下文特征向量信息:
其中,ct表示上下文特征向量信息。
步骤s304,根据所述上下文特征向量信息通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息。
本实施例通过上述方案,通过根据所述上下文特征向量信息通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息,从而通过上下文特征向量感知多个时间步上的关键信息。
此外,本发明实施例还提出一种存储介质,所述存储介质上存储有京剧人物识别程序,所述京剧人物识别程序被处理器执行时实现如上文所述的终端入网方法的步骤。
由于本存储介质采用了上述所有实施例的全部技术方案,因此至少具有上述实施例的技术方案所带来的所有有益效果,在此不再一一赘述。
此外,参照图7,本发明实施例还提出一种京剧人物识别装置,所述京剧人物识别装置包括:
获取模块10,用于获取当前京剧人物图像信息。
在具体实现中,在用户收看电视中播放的京剧视频时,可通过识别指令,根据所述识别指令截取当前播放视频中的京剧人物的图像信息,将截取到京剧人物的图像信息作为当前京剧人物图像信息,以便进行当前京剧人物的识别,其中,所述识别指令可为通过遥控器操作的识别指令,还可为通过电视界面上的菜单进行的识别指令,还可为其他形式的识别指令,本实施例对此不作限制,在本实施例中,以电视机上的操作界面进行识别操作为例进行说明。
在本实施例中,可基于电视播放的京剧视频某一帧图片的静态识别,将视频文件的某一帧的图片截取作为京剧人物分类网络的输入,然后通过训练好的京剧人物分类网络进行分类,得到识别结果。
识别模块20,用于将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息。
可以理解的是,所述京剧人物分类网络可为基于深度学习训练得到的京剧人物分类网络,还可基于其他网络训练得到的,本实施例对此不作限制,在本实施例中,以基于卷积神经网络为例进行说明,京剧人物的行当,即类别,包括生旦净丑等四大类别,生角包括老生(中年男性)和小生(青年男性),旦角包括青衣(中年女性)、花旦(青年女性)以及老旦(老年女性),净角包括花脸,即性格特征明显的特殊群体,例张飞或者包拯,丑角的特征为丑,即特征明显的特殊群体,插科打诨的人,其中,所述分类信息包括行当的类别,即分类信息包括老生或者花旦等行当信息。
在本实施例中,老生的脸谱妆较浅、均有髯口,即胡子;小生脸谱妆相较于老生而言更浓,不戴髯口,所以可以对其相应特征明显的区域进行标记,从而实现京剧人物的分类信息。
在具体实现中,获取京剧人物分类网络,将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息,为了获取京剧人物分类网络,首先需要充实各个行当(类别)的图片数据量,采集一定图片后,进行行当归类并对部分图片的特征区域进行辅助框标记,以“老生”和“花脸”为例,识别京剧人物是老生还是花脸,可以通过脸部妆容图以及髯口的不同来区分,“老生”的脸妆比较淡,和普通人造型无异,“老生”的胡子是三片,即三髯,“老生”的造型一般比较规矩,通常穿戴颜色较淡的衣物,且没有较大幅度的肢体变化,“花脸”的脸妆特色鲜明,较夸张,呈现有五颜六色的脸谱,“花脸”的胡子是一片,即满髯;“花脸”的造型一般比较夸张,通常伴有佩剑、令旗、将袍等物品,通过对京剧人物的脸部、胡子以及整体进行标注,如图3所示京剧人物区域识别示意图,其中,虚线框标注的为京剧人物的脸部、胡子以及整体信息,然后记录下相应框的坐标,基于卷积神经网络对特征区域进行学习训练,得到京剧人物分类网络。
放大模块30,用于根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息。
在本实施例中,还设有注意力机制网络,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息,继续如图3所示的特征区域,将特征区域中的特征信息进行放大处理,通过采用基于视觉注意力机制网络以及基于目标块标记的半监督学习训练网络,具体表现为视觉系统在看东西的时候,先通过快速扫描全局图像获得需要关注的目标区域,而后抑制其他无用信息以获取感兴趣的目标,同时,再对特征区域通过特征框标记加以辅助提升训练效果。
在具体实现中,首先通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息,注意力机制网络通过京剧人物分类网络的最后一层卷积层作为输入,计算出特征区域的决定性因素信息,即中心点等坐标信息,然后通过图像分割操作实现特征区域放大。
在本实施例中,通过放大剪切出来的图像重新作为京剧人物分类网络的数据输入进分类网络,从而提高了脸部以及胡子等重要特征在图像中的占比率,使识别效果有显著的提高。
所述识别模块20,还用于将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息。
在本实施例中,所述京剧人物识别网络包含三个级别子网络,每个级别子网络的网络结构都是一样的,只是网络参数不一样,每个级别子网络又包含两种类型的网络:京剧人物分类网络和注意力机制网络,京剧人物分类网络对标记框的数据集进行特征提取并分类,然后注意力机制网络基于提取到的特征进行训练得到注意集中区域信息,再将注意集中区域裁剪出来并放大,作为第二个级别网络的输入,重复进行三次就得到了三个级别网络的输出结果,最后将三个级别网络的结果进行融合得到输出,这样反复进行的学习调参,可以使模型对不同类别脸部的纹理、身体信息特征,例如胡子,服饰上的特殊饰物,例如头冠、御带以及水袖等等特征信息进行识别,最终达到对不同类别的京剧人物的识别效果。
进一步地,所述步骤s40之后,所述方法还包括:
获取搜索指令,根据所述搜索指令获取所述目标分类信息对应的标签信息。根据所述标签信息查找所述目标分类信息对应的京剧人物介绍信息,并将所述京剧人物介绍信息进行展示。
需要说明的是,所述搜索指令可为基于电视界面进行搜索操作,还可通过其他方式进行操作,本实施例对此不作限制,在本实施例中,以基于电视界面进行搜索操作为例进行说明。
如图4所示的京剧人物展示示意图,当在观看京剧视频时,选择某一即时场景,点击电视左下角的一个搜索按钮,后台就会调用中间件接口,对图片中出现的京剧人物进行分析,图片经过京剧人物识别网络得到各类别信息的识别率,选取识别率最大的行当类别,展示其事先标记好的标签信息。随后就能通过弹出信息框的形式向用户展示这些基本信息,即京剧人物介绍信息,用户也就能更深一步的了解这一京剧人物所属行当的基本信息。
本实施例通过上述方案,通过获取当前京剧人物图像信息;将所述当前京剧人物图像信息通过京剧人物分类网络进行识别,得到所述当前京剧人物图像信息的分类信息;根据所述分类信息确定特征区域信息,通过注意力机制网络对所述特征区域信息进行区域放大,得到放大后的特征信息;将所述放大后的特征信息重新通过所述京剧人物分类网络进行识别,得到目标分类信息,从而通过京剧人物分类网络结合注意力机制网络实现对京剧人物的识别,达到提高京剧人物识别准确性的目的。
本发明所述京剧人物识别装置采用了上述所有实施例的全部技术方案,因此至少具有上述实施例的技术方案所带来的所有有益效果,在此不再一一赘述。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!