一种大数据实时更新方法、系统、设备和存储介质与流程
本发明实施例涉及计算机技术,尤其涉及一种大数据实时更新方法、系统、设备和存储介质。
背景技术:
常见的营销系统通常由于性能、成本等多方面的限制,对营销系统的查询大部分是基于离线数据进行查询,现有离线查询方案的缺点是:数据由离线任务生成,数据实时性较差,对于实时性要求高的业务无法满足。故障恢复慢,离线etl(extract-transform-load,数据仓库技术)任务失败恢复流程较长,且速度依赖集群当前资源,对线上业务影响较大。
示例性的,对客户群体的查询中,用户的标签数据使用离线etl任务从hbase(一个分布式的、面向列的开源数据库)等存储系统中进行同步和处理,最终落地到hive(数据仓库工具)中提供给营销系统进行查询和使用,整个任务的执行间隔通常以天为单位,但是间隔时间太长,不能实时更新数据,无法满足用户的查询需求。
但支持实时更新和查询的营销系统又很难支持大量数据的并发写入和存储,大批量实时写入性能不足,对于大量数据的写入处理不及时很容易造成数据堆积,影响数据实时性,并且某些数据对于sql(structuredquerylanguage,结构化查询语言)的兼容性不佳,不利于业务层的查询和使用。此外,大多数现有方案的数据存储基于hdfs(hadoopdistributedfilesystem,分布式文件系统)实现,但hdfs并不支持数据的修改,且性能会受到gc(gridcommunication,网格通信)的影响。
技术实现要素:
本发明实施例提供一种大数据实时更新方法、系统、设备和存储介质,以实现准确的实时更新大量数据。
为达此目的,本发明实施例提供了一种大数据实时更新方法,该方法包括:
获取预设集群中新增的第一增量数据和源数据库中的源数据;
根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据;
将所述更新数据写入更新数据库中。
进一步的,所述获取预设集群中新增的第一增量数据包括:
获取预设主集群中新增的第一增量数据;
启动所述预设主集群的区域服务器,并将所述区域服务器设定为伪装集群;
将所述伪装集群注册至所述预设主集群中以使所述伪装集群作为所述预设主集群的从集群,所述伪装集群用于接收所述预设主集群写入的数据;
将所述预设主集群中的第一增量数据写入至所述伪装集群中。
进一步的,所述将所述预设主集群中的第一增量数据写入至所述伪装集群中之后包括:
将所述伪装集群中的第一增量数据写入至开源流处理平台中,所述开源流处理平台用于为所述第一增量数据提供数据缓冲和数据容错。
进一步的,所述根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据包括:
将所述开源流处理平台中的第一增量数据和源数据库中的源数据写入至预设处理框架中,所述预设处理框架用于根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据。
进一步的,所述将所述更新数据写入更新数据库中之后包括:
将第一查询引擎部署在所述更新数据库中;
接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的更新数据。
进一步的,所述接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的更新数据包括:
对所述更新数据库中的更新数据进行分区优化以得到分区更新数据;
接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的分区更新数据。
进一步的,所述接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的更新数据包括:
获取用户的查询权限;
根据所述查询权限接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的分区更新数据。
一方面,本发明实施例还提供了一种大数据实时更新系统,该系统包括:
数据获取模块,用于获取预设集群中新增的第一增量数据和源数据库中的源数据;
数据更新模块,用于根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据;
数据写入模块,用于将所述更新数据写入更新数据库中。
另一方面,本发明实施例还提供了一种大数据实时更新设备,该设备包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本发明任一实施例提供的方法。
又一方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本发明任一实施例提供的方法。
本发明实施例通过获取预设集群中新增的第一增量数据和源数据库中的源数据;根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据;将所述更新数据写入更新数据库中,解决了现有技术难以准确的支持大量数据的并发写入和存储的问题,实现了准确的实时更新大量数据的效果。
附图说明
图1是本发明实施例一提供的一种大数据实时更新方法的流程示意图;
图2是本发明实施例二提供的一种大数据实时更新方法的流程示意图;
图3是本发明实施例三提供的一种大数据实时更新方法的流程示意图;
图4是本发明实施例四提供的一种大数据实时更新系统的结构示意图;
图5为本发明实施例五提供的一种大数据实时更新设备的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
在更加详细地讨论示例性实施例之前应当提到的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各步骤描述成顺序的处理,但是其中的许多步骤可以被并行地、并发地或者同时实施。此外,各步骤的顺序可以被重新安排。当其操作完成时处理可以被终止,但是还可以具有未包括在附图中的附加步骤。处理可以对应于方法、函数、规程、子例程、子程序等等。
此外,术语“第一”、“第二”等可在本文中用于描述各种方向、动作、步骤或元件等,但这些方向、动作、步骤或元件不受这些术语限制。这些术语仅用于将第一个方向、动作、步骤或元件与另一个方向、动作、步骤或元件区分。举例来说,在不脱离本申请的范围的情况下,可以将第一模块称为第二模块,且类似地,可将第二模块称为第一模块。第一模块和第二模块两者都是模块,但其不是同一模块。术语“第一”、“第二”等不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个所述特征。在本发明实施例的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
实施例一
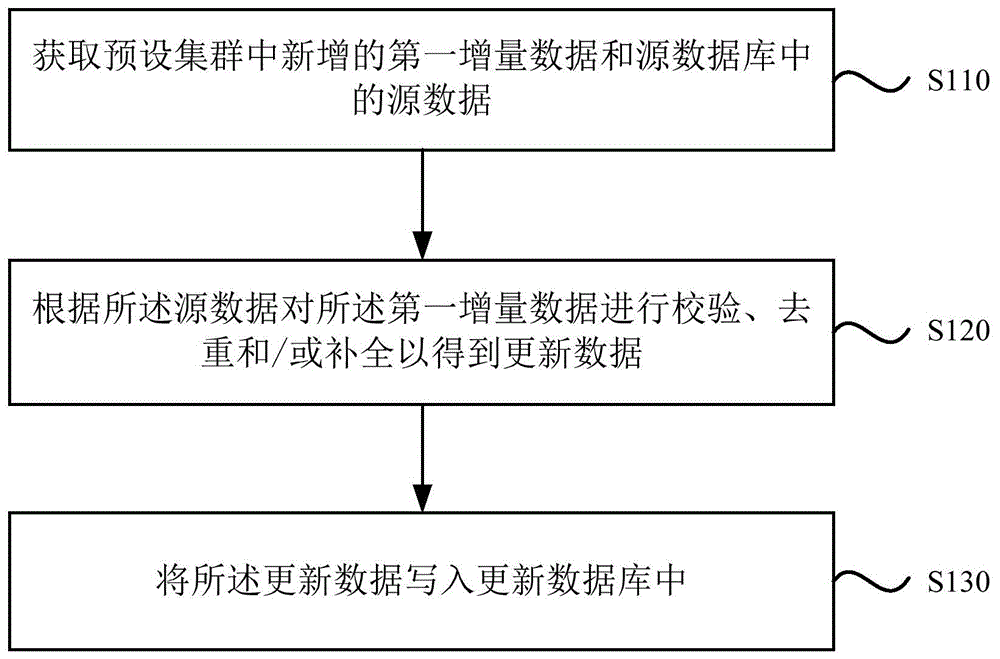
如图1所示,本发明实施例一提供了一种大数据实时更新方法,该方法包括:
s110、获取预设集群中新增的第一增量数据和源数据库中的源数据。
本实施例中,可以是实时更新任一营销系统中的大量数据,首先需要从营销系统中实时获取数据,其中,预设集群可以为营销系统中任一业务线对应的集群,从该预设集群中获取新增的第一增量数据,即获取该业务线中的新增数据,同时还要获取源数据库中的源数据,源数据库即营销系统中包括全部数据内容的数据库,源数据即源数据库中的全部数据。
s120、根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据。
s130、将所述更新数据写入更新数据库中。
本实施例中,在实时得到预设集群中新增的第一增量数据后,因该第一增量数据是实时获取的,还可能存在错误重复、或缺失的增量数据,作为优选的,还需要根据源数据对第一增量数据进行校验、去重和/或补全,得到校验、去重和/或补全后的更新数据,保证新增的更新数据是正确可靠的,最后将新增的更新数据写入更新数据库中,用户就可以对该更新数据库进行实时查询更新数据,即营销系统中新增的数据,并通过olap(onlineanalyticalprocessing,在线分析处理)对这些更新数据进行分析。
本发明实施例通过获取预设集群中新增的第一增量数据和源数据库中的源数据;根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据;将所述更新数据写入更新数据库中,解决了现有技术难以准确的支持大量数据的并发写入和存储的问题,实现了准确的实时更新大量数据的效果。
实施例二
如图2所示,本发明实施例二提供了一种大数据实时更新方法,本发明实施例二是在本发明实施例一的基础上进一步的说明解释,该方法包括:
s210、获取预设主集群中新增的第一增量数据和源数据库中的源数据。
本实施例中,预设主集群可以为基于hbase的数据库,基于lsm树(一种可以快速写入的存储引擎)列式存储的hbase数据库能够支持大并发量的数据写入,源数据库可以为mysql数据库(一种开放源代码的关系型数据库)。
s220、启动所述预设主集群的区域服务器,并将所述区域服务器设定为伪装集群。
s230、将所述伪装集群注册至所述预设主集群中以使所述伪装集群作为所述预设主集群的从集群,所述伪装集群用于接收所述预设主集群写入的数据。
本实施例中,在获取到hbase数据库中新增的第一增量数据后,进一步的,启动一批hbase数据库的区域服务器(hbaseregionserver),该批区域服务器和hbase数据库一般的区域服务器相同,不同之处在于该批区域服务器不对外提供服务,即对外不存储数据,只将该批区域服务器至注册至hbase数据库中,即将该批区域服务器作为预设主集群的从集群,这样该批区域服务器就可以接收预设主集群写入的数据,同时更适于后续的olap的分析。
s240、将所述预设主集群中的第一增量数据写入至所述伪装集群中。
本实施例中,伪装集群可以接收预设主集群写入的数据后,通过hbase数据库自身的replication(复制)机制,就可以将预设主集群中的第一增量数据写入至伪装集群中。
s250、将所述伪装集群中的第一增量数据写入至开源流处理平台中,所述开源流处理平台用于为所述第一增量数据提供数据缓冲和数据容错。
本实施例中,开源流处理平台可以为kafka(一种高吞吐量的分布式发布订阅消息系统)平台,kafka平台可以为数据提供缓冲和容错,因此还需要将伪装集群中的第一增量数据写入至该kafka平台中。
s260、将所述开源流处理平台中的第一增量数据和源数据库中的源数据写入至预设处理框架中,所述预设处理框架用于根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据。
本实施例中,预设处理框架可以为sparkstreaming(spark核心应用程序接口的一个扩展)框架,sparkstreaming框架可实现高吞吐量的,具备容错机制的实时流数据处理。因此将伪装集群中的第一增量数据写入至该sparkstreaming框架中,sparkstreaming框架通过实时的流计算对第一增量数据进行校验、去重和/或补全以及其他业务的处理,最终得到更新数据。
s270、将所述更新数据写入更新数据库中。
本实施例中,将经过sparkstreaming框架处理后得到的更新数据批量写入更新数据库中存储,更新数据库可以为kudu数据库,kudu数据库与hbase数据库相同,是一种基于lsm树的列式存储的数据库,支持大并发量的数据写入和存储。
一实施例中,在更新数据的同时可以将来自mysql数据库的全部数据,即源数据写入至sparkstreaming框架中,sparkstreaming框架将这些源数据写入至hdfs数据库中存储,并通过查询服务查询hdfs数据库中的数据,加快用户对营销系统中全部数据查询的速度。
实施例三
如图3所示,本发明实施例三提供了一种大数据实时更新方法,本发明实施例三是在本发明实施例二的基础上进一步的说明解释,在本发明实施例二的步骤s270之后,该方法还包括:
s310、将第一查询引擎部署在所述更新数据库中。
本实施例中,在将营销系统中新增的更新数据更新至更新数据库中,实现了更新数据的快速写入后,为了保证用户也可以实现快速查询,将第一查询引擎部署在更新数据库中,实现查询引擎的数据本地化,减少了网络的输入输出操作,提升查询速度。第一查询引擎可以为impala(一种可以查询存储在hdfs和hbase中的pb级大数据)查询引擎。
s320、对所述更新数据库中的更新数据进行分区优化以得到分区更新数据。
本实施例中,为了进一步提升查询速度,对更新数据库中的更新数据进行分区优化以得到分区更新数据,具体的,对更新数据进行一个预处理,进行排序后按预设区域进行数据分离,然后通过impala查询引擎自身的runtimefilter(运行时过滤)技术实现查询时的分区动态裁剪,减少文件和数据的扫描,进一步降低网络的输入输出操作。
s330、获取用户的查询权限。
s340、根据所述查询权限接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的分区更新数据。
本实施例中,为了保证营销系统的安全性,需要对用户的查询权限进行一个判断,根据查询权限接收用户的第一指令,第一指令用于通过第一查询引擎查询更新数据库中的分区更新数据。进一步的,在用户查询完分区更新数据后,还可以将该用户的查询记录下来,存储在kudu数据库中。综上方法可以实现数据支持大批量数据并发写入,具体为每秒百万行数据写入;秒级的数据即席查询,具体为支持亿级数据的秒级查询;在保证数据准确性的情况下数据的更新和查询实时性由天提升为小时。
实施例四
如图4所示,本发明实施例四提供了一种大数据实时更新系统100,本发明实施例四所提供的大数据实时更新系统100可执行本发明任意实施例所提供的大数据实时更新方法,具备执行方法相应的功能模块和有益效果。该大数据实时更新系统100包括数据获取模块200、数据更新模块300和数据写入模块400。
具体的,数据获取模块200用于获取预设集群中新增的第一增量数据和源数据库中的源数据;数据更新模块300用于根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据;数据写入模块400用于将所述更新数据写入更新数据库中。
本实施例中,数据获取模块200具体用于获取预设主集群中新增的第一增量数据;启动所述预设主集群的区域服务器,并将所述区域服务器设定为伪装集群;将所述伪装集群注册至所述预设主集群中以使所述伪装集群作为所述预设主集群的从集群,所述伪装集群用于接收所述预设主集群写入的数据;将所述预设主集群中的第一增量数据写入至所述伪装集群中。数据获取模块200具体还用于将所述伪装集群中的第一增量数据写入至开源流处理平台中,所述开源流处理平台用于为所述第一增量数据提供数据缓冲和数据容错。数据更新模块300具体用于将所述开源流处理平台中的第一增量数据和源数据库中的源数据写入至预设处理框架中,所述预设处理框架用于根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据。
本实施例中,该大数据实时更新系统100还包括数据查询模块500,数据查询模块500用于将第一查询引擎部署在所述更新数据库中;接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的更新数据。数据查询模块500具体用于对所述更新数据库中的更新数据进行分区优化以得到分区更新数据;接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的分区更新数据。数据查询模块500具体还用于获取用户的查询权限;根据所述查询权限接收用户的第一指令,所述第一指令用于通过所述第一查询引擎查询所述更新数据库中的分区更新数据。
实施例五
图5为本发明实施例五提供的一种大数据实时更新计算机设备12的结构示意图。图5示出了适于用来实现本发明实施方式的示例性计算机设备12的框图。图5显示的计算机设备12仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
如图5所示,计算机设备12以通用计算设备的形式表现。计算机设备12的组件可以包括但不限于:一个或者多个处理器或者处理单元16,系统存储器28,连接不同系统组件(包括系统存储器28和处理单元16)的总线18。
总线18表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(isa)总线,微通道体系结构(mac)总线,增强型isa总线、视频电子标准协会(vesa)局域总线以及外围组件互连(pci)总线。
计算机设备12典型地包括多种计算机系统可读介质。这些介质可以是任何能够被计算机设备12访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
系统存储器28可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(ram)30和/或高速缓存存储器32。计算机设备12可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统34可以用于读写不可移动的、非易失性磁介质(图5未显示,通常称为“硬盘驱动器”)。尽管图5中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如cd-rom,dvd-rom或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线18相连。存储器28可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
具有一组(至少一个)程序模块42的程序/实用工具40,可以存储在例如存储器28中,这样的程序模块42包括——但不限于——操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块42通常执行本发明所描述的实施例中的功能和/或方法。
计算机设备12也可以与一个或多个外部设备14(例如键盘、指向设备、显示器24等)通信,还可与一个或者多个使得用户能与该计算机设备12交互的设备通信,和/或与使得该计算机设备12能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口22进行。并且,计算机设备12还可以通过网络适配器20与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器20通过总线18与计算机设备12的其它模块通信。应当明白,尽管图中未示出,可以结合计算机设备12使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储系统等。
处理单元16通过运行存储在系统存储器28中的程序,从而执行各种功能应用以及数据处理,例如实现本发明实施例所提供的方法:
获取预设集群中新增的第一增量数据和源数据库中的源数据;
根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据;
将所述更新数据写入更新数据库中。
实施例六
本发明实施例六还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本申请所有发明实施例提供的方法:
获取预设集群中新增的第一增量数据和源数据库中的源数据;
根据所述源数据对所述第一增量数据进行校验、去重和/或补全以得到更新数据;
将所述更新数据写入更新数据库中。
本发明实施例的计算机存储介质,可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括——但不限于无线、电线、光缆、rf等等,或者上述的任意合适的组合。
可以以一种或多种程序设计语言或其组合来编写用于执行本发明操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c++,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括局域网(lan)或广域网(wan)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!