针对按位乘法器-累加器(MAC)的流水线架构的制作方法
相关申请的交叉引用
本申请要求享有于2019年5月20日提交的美国临时专利申请62/850,033的优先权,该申请通过引用并入本文。
本发明总体上涉及乘法-累加器。
背景技术:
乘法器-累加器(mac)是本领域已知的,并且用于处理对大量乘法求和的常见运算。这种运算在图像处理中常见的点积乘法和矩阵乘法中以及在用于神经网络的卷积中都很常见。
在数学上,乘法-累加运算是:
∑iaiki公式1
其中ai和ki是8位、16位或32位字。
在代码中,mac运算是:
qi=qi+(ai*ki)公式2
其中qi变量累加值aiki。
因为mac运算非常常见,mac典型地作为分开的单元在中央处理单元(cpu)或数字信号处理器(dsp)中以硬件实现。mac典型地具有用组合逻辑实现的乘法器、加法器和累加器寄存器。乘法器的输出馈入加法器,并且加法器的输出馈入累加器寄存器。累加器寄存器的输出反馈到加法器的一个输入,从而在先前的结果与新的乘法结果之间生成累加运算。在每个时钟周期,乘法器的输出被加到寄存器中。
mac的乘法器部分典型地用组合逻辑实现,而加法器部分典型地被实现为存储结果的累加器寄存器。
技术实现要素:
因此,根据本发明的优选实施例,提供了一种用于累加多个n个相乘的m位值的方法。该方法包括将被乘数a和b流水线化到乘法-累加器,使得在每个周期一组新的被乘数被接收;在每个周期,将当前被乘数a的位与当前被乘数b的位按位相乘,并且在位乘法器之间求和和进位;并且在每个周期,将按位相乘的输出按位累加,从而在流水线化过程期间累加被乘数。
根据本发明的优选实施例,还提供了一种用于累加多个n个相乘的m位值的方法。该方法包括针对各自具有m位的每一对被乘数a和b执行以下步骤。在各自具有m个乘法单元的m行中,单独地将被乘数a的每一位与被乘数b的每一位相乘,并且单独地对来自乘法单元的前一行的结果求和。在m行的乘法单元之后的m行的求和单元中,单独地对来自求和单元或乘法单元的前一行的结果求和。行朝向形成为列的累加器对输出求和。在累加器的累加器单元中,单独地累加来自每行的位输出的结果的每一位,并且沿结果的位从结果的lsb(最低有效位)到msb(最高有效位)传递进位值。
此外,根据本发明的优选实施例,乘法单元、求和单元以及累加器单元是位线处理器。
此外,根据本发明的优选实施例,该方法还包括在每个运算周期向乘法单元的上面一行提供一对新的被乘数a和b。
更进一步,根据本发明的优选实施例,单独地求和至少包括:生成乘法单元和求和单元中的至少一个的总和值和进位值,并且在每个周期将进位值向下传递一行以及将总和值向右且向下传递一行。
另外地,根据本发明的优选实施例,该方法包括:在每个周期将被乘数a的位向下传递一行,并且在每个周期将被乘数b的位向右且向下传递一行。
此外,根据本发明的优选实施例,m是2的幂。
更进一步,根据本发明的优选实施例,该方法包括:在提供停止后,每个周期单独地存储结果的一位,该存储在lsb处开始并且朝向msb移动。
此外,根据本发明的优选实施例,当n为1时,累加器的输出是被乘数a和b的乘法。
根据本发明的优选实施例,还提供了一种用于累加多个n个相乘的m位值的单元。该单元包括接收单元、按位乘法器和按位累加器。接收单元接收被乘数a和b的流水线,使得在每个周期一组新的被乘数被接收。按位乘法器将当前被乘数a的位与当前被乘数b的位按位相乘,并且在按位乘法器之间求和和进位。按位累加器将按位乘法器的输出累加,从而在流水线化过程期间累加被乘数。
此外,根据本发明的优选实施例,按位乘法器包括各自具有m个乘法单元的m行,以及在m行的乘法单元之后的m行的求和单元,其中每行包括m个求和单元。每个乘法单元单独地将被乘数a的每一位与被乘数b的每一位相乘,并且单独地对来自乘法单元的前一行的结果求和。每个求和单元单独地对来自求和单元或乘法单元的前一行的结果求和,其中行朝向按位累加器对输出求和。
此外,根据本发明的优选实施例,按位累加器包括形成为列的累加器的累加器单元。每个累加器单元单独地将来自其相关联的行的位输出的结果的位累加,并且沿结果的位从结果的lsb(最低有效位)到msb(最高有效位)传递进位值。
更进一步,根据本发明的优选实施例,乘法单元、求和单元以及累加器单元是位线处理器。
此外,根据本发明的优选实施例,乘法单元的上面一行在每个运算周期接收一对新的被乘数a和b。
此外,根据本发明的优选实施例,求和单元与下面一行中的求和单元通信,以在每个周期将进位值向下传递一行,并且将总和值向右且向下传递一行。
更进一步,根据本发明的优选实施例,乘法单元与下面一行中的乘法单元通信,以在每个周期将被乘数a的位向下传递一行。
此外,根据本发明的优选实施例,该单元还包括位传递单元,其用于将被乘数b的每一位传递到乘法单元中的其相关联的行。
此外,根据本发明的优选实施例,当n为1时,按位累加器的输出是被乘数a和b的乘法。
附图说明
在说明书的结束部分中特别地指出并且明确要求保护被视为本发明的主题。然而,关于组织和操作方法,以及其对象、特征和优点,可以通过在结合附图阅读时参考以下具体实施方式而最好地理解本发明,在附图中:
图1是根据本发明的优选实施例构造和可操作的流水线化乘法器-累加器的示意图示;
图2a、图2b和图2c分别是在图1的乘法器-累加器中有用的乘法处理器、求和处理器和累加处理器的示意图示;
图3a、图3b、图3c、图3d、图3e、图3f、图3g、图3h和图3i是示出数据如何在9个周期内移动通过按位乘法器-累加器100的示意图示,这些图有助于理解图1的流水线化乘法器-累加器;以及
图4是三个相邻的乘法位线处理器110m的示意图示。
应当理解,为了图示的简单和清楚起见,图中所示元件不一定按比例绘制。例如,为了清楚起见,元件中的一些元件的尺寸可能相对于其他元件被放大。此外,在认为适当的情况下,可以在附图中重复附图标记以指示对应的或类似的元件。
具体实施方式
在下面的具体实施方式中,阐述了许多具体细节,以提供对本发明的透彻理解。然而,本领域技术人员将理解,可以在没有这些具体细节的情况下实践本发明。在其他实例中,未详细描述公知的方法、过程和组件,以避免混淆本发明。
申请人已经意识到在乘法运算期间可以累加结果。与仅一旦一对值已经被相乘才进行累加相比,这明显更快并且更高效。此外,由于乘法器和累加器是单个单元的一部分,而不是两个分开的单元,因此它减少了芯片占用空间。
申请人已经进一步意识到,当乘法器和累加器是单个单元的一部分时,该单元在处理进位值时应该单独地累加每个位。此外,一旦每一位被单独地处理,运算就可以流水线化。申请人已经意识到,当仅向该流水线化乘法器-累加器单元提供1个乘法运算时,该流水线化乘法器-累加器单元也可以仅执行乘法。那么累加就是单个结果。
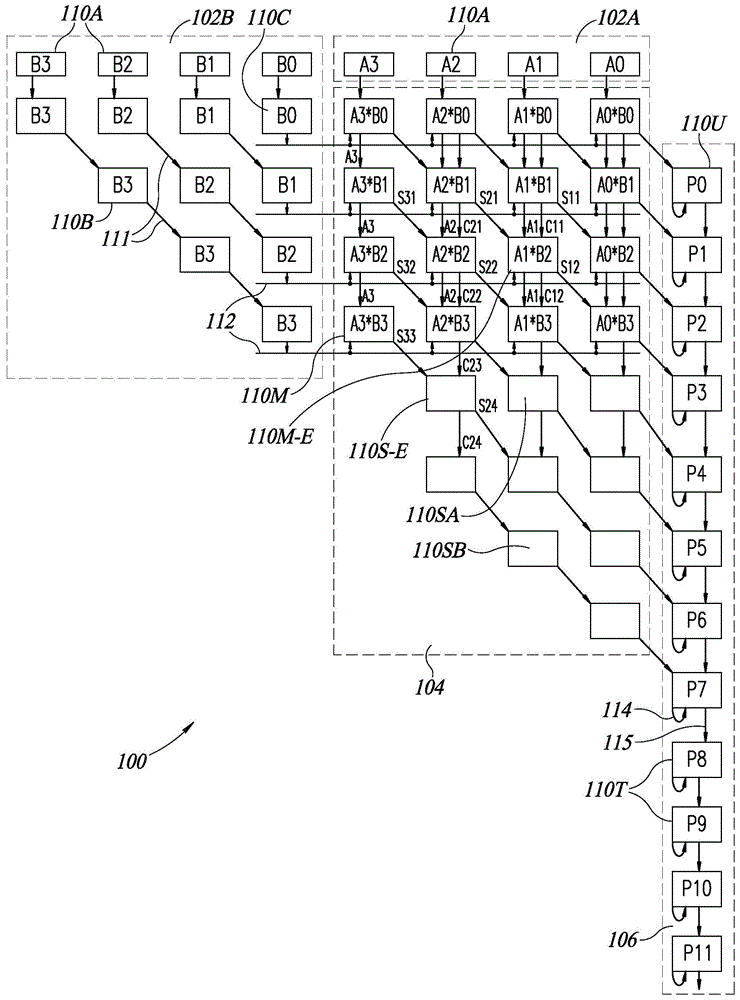
现在参考图1,图1示出了根据本发明的优选实施例构造和可操作的按位乘法器-累加器100。按位乘法器-累加器100可以在存储器内关联处理器中实现,例如,在由本申请的申请人当前拥有并且通过引用并入本文的美国专利8,238,173、9,418,719和9,558,812中讨论的那些。存储器内处理器处理存储器阵列中的数据,存储器阵列具有以行和列的矩阵形式的多个存储器单元,并且这些列被组织到处理器中。当多行一起被激活时,在处理器中会发生布尔计算运算,其中在处理器的列解码器中读取结果。
按位乘法器-累加器100包括分别用于每个被乘数a和b的单独的输入单元102a和102b、按位乘法器单元104和按位累加器单元106,其中每个单元102、104和106可以由多个处理器110构成,该多个处理器110可以在每个运算周期期间对一个位或一对位(一个位来自被乘数a和被乘数b中的每一个)进行运算。处理器110可以是任何合适的处理器,并且可以如本文示例中所描述的那样被实现为位线处理器110,在下文中更详细地描述。
在按位乘法器-累加器100中,处理器110可以形成为行和列,其中输入单元102a可以由乘法器104上方的处理器110的单个行形成,累加器106可以位于按位乘法器104的右侧,并且输入单元102b可以位于按位乘法器104的上面部分的左侧。
按位乘法器-累加器100可以对被乘数a和被乘数b进行运算,被乘数a和被乘数b可以根据需要具有4、8、16、32、64或更多位。在图1的示例中,按位乘法器-累加器仅对4位被乘数a和b进行运算。
输入单元102a可以包括一行m个接收处理器110a,其中m是被乘数a中位的数目,并且其中在图1中m是4。在每个运算周期,每个处理器110a可以接收当前被乘数a的一个位,其中被乘数a的最低有效位a0可以位于行的最右侧,并且最高有效位a3可以位于行的最左侧。在下一个运算周期,处理器110a可以将来自前一个周期的存储在其中的值传递到乘法器104的处理器110m的第一行,并且可以接收来自下一个被乘数a的位。因此,对于输入单元102a,所有位可以在每个周期向下(即,垂直地)移动一行。如可以看出的,对于m个周期,被乘数a的位被向下传递到下一行。因此,图1中的乘法器104的前四行从左到右示出了它们中的位a3–a0。
输入单元102a可以在每个周期向下一行提供被乘数a的位;然而,根据本发明的优选实施例,如下文更详细地描述的,乘法器-累加器100中的大多数处理器110可以在每个周期向下且向右(朝向累加器106)传递其数据。
输入单元102b可以包括三种类型的处理器110;1)一行接收处理器110a,其典型地与输入单元102a的处理器110a在同一行中对齐,2)数据传递处理器110b,其可以在每个周期(如斜箭头111所示)向下且向右传递来自前一个周期的存储在其中的值,以及3)信令处理器110c,其可以将存储在其中的值提供给向乘法器104中的一行处理器110提供输入的信令线112。
应当理解,信令处理器110c可以将被乘数b的相关联的位提供给按位乘法器104的前m行中的每一行。此外,数据传递处理器110b可以形成为三角形,以便向乘法器104的前m行中的每一行提供不同的位值。因此,输入单元102b可以将被乘数b的最低有效位b0提供给乘法器104的第一行,将被乘数b的下一有效位提供给乘法器104的第二行等。图1示出了四行,每一行沿着其信令线112接收被乘数b的不同位。图1还示出了四列,每列接收被乘数a的不同位,其中最低有效位在右侧,下一有效位在其左侧,等等。
按位乘法器单元104可以包括乘法处理器110m的mxm矩阵和求和处理器110s的m行。乘法器104的第一行中的每个乘法处理器110m可以接收一位被乘数a和一位被乘数b作为输入,可以将它们一起相乘,并且可以生成它们的两位结果(回想一下二进制中的1+1=10)。这两位被称为“总和”位和“进位”位,其中总和是结果的最右侧位,并且进位是结果的最左侧位(例如,对于1+1=10,总和位是0,并且进位位是1)。
其余的乘法处理器110m可以接收总和位(从在其上方且在其左侧的处理器)、进位位和来自被乘数a的位(从其上方的处理器),以及从其信令线112接收来自被乘数b的位。这些处理器110m可以在其被乘数位(这些处理器110m可以将总和值和进位值加到其上)之间执行乘法运算,生成新的总和位和进位位作为输出。在图1中,乘法处理器110m被它们所相乘的被乘数位标记。
例如,乘法处理器110m-e可以从执行其正上方的a1*b1的乘法的乘法处理器接收位a1的值,并且可以从其相关联的信令线112接收位b2的值。乘法处理器110m-e可以执行a1*b2的乘法,并且可以将来自在上方且在左侧的行中的a2*b1的乘法的总和s21以及来自其正上方的a1*b1的乘法的进位c11与其相加。乘法处理器110m-e可以将其求和结果s12提供给乘法处理器以执行运算a0*b3(例如,总和位s12向下且向右移动)并且将其进位结果c12和a1的值提供给乘法处理器以执行运算a1*b3(例如,进位位c12和a位向下移动)。
如图1中可以看出的,乘法处理器110m可以将它们的进位位cij(其中i是它们的a位的索引并且j是它们的b位的索引)和它们的被乘数位ai垂直向下提供给下一行的乘法处理器110m,并且可以将它们的总和位sij向下且向右提供(即,提供给下一行右边一列的乘法处理器110m)。注意,在本申请中,i索引是指列,而j索引是指行(列中每个ai位保持不变,而行中每个bj位保持不变)。
应当理解,对msb(最高有效位)位(图1的示例中的a3)运算的乘法处理器110m仅接收被乘数(图1的示例中的a3和bj),并且作为结果仅生成总和位。单元110m的其余部分可以接收总和位和进位位。将进一步理解的是,对lsb(最低有效位)位(图1的示例中的a0)运算的乘法处理器110m可以将其总和位传递给按位累加器单元106。
乘法器104的第二部分中的每个求和处理器110s可以是仅对它们的输入执行加法运算的加法处理器110sa,或者是可以在每个周期将来自前一个周期的存储在其中的进位值向下且向右传递的数据传递处理器110sb。没有类型的求和处理器110s接收任何被乘数位作为输入。
每个求和处理器110sa可以将总和位(来自在其上方且在其左侧的处理器)和进位位(来自其上方的处理器)一起相加,并且可以将结果的总和位提供给在其下方且在其右侧的处理器,并且将进位位提供给其下方的处理器。因为没有新的输入被乘数,所以每行有更少的求和处理器110s。图1示出了在前两行中有3个求和处理器,在第三行中有2个求和处理器,以及在第四且最后一行中有1个求和处理器。针对具有更多位的被乘数,可以做出类似的布置。
例如,求和处理器110s-e可以从执行在上方且在左侧的行中的a3*b3的乘法的乘法处理器接收总和位s33,并且可以从在其正上方执行a2*b3的乘法的乘法处理器接收进位位c23。求和处理器110s-e可以将总和位s33和进位位c23相加,并且可以将其求和结果s24向下且向其右侧提供给求和处理器,并且将其进位位c24提供给其正下方的求和处理器。
应该理解,每个乘法处理器110m执行按位乘法。不是将两个多位输入数字a和b一起相乘然后将它们一起相加,而是每个乘法处理器110m不仅将其相关联的被乘数位一起相乘,而且还将从相邻的乘法处理器接收到的总和信息和进位信息与其结果相加。然后,乘法处理器将其总和信息和进位信息提供给其相邻的乘法处理器。因此,乘法器104是“按位”乘法器。
将进一步理解的是,乘法器104的每一行可以将该行的输出朝向按位累加器106求和。
按位累加器单元106可以包括一行累加处理器110u和尾端处理器110t,从而生成其相应的结果位pk。申请人已经意识到,累加的结果的每一位都是从lsb到msb累加的,并且lsb始终是lsb位乘法的累加值。因此,lsb总和位可以从将a0*b0相乘的乘法处理器110m提供给按位累加器单元106中的第一累加处理器110u。注意,第一累加处理器110u在处理器110的第二行中开始。
此外,申请人已经意识到,由于在按位乘法器104中执行的求和运算和进位运算,每个累加处理器110u可以从其相邻的乘法处理器110m或求和处理器110s接收总和位,以将该总和位加到其先前累加的值中。
因此,累加器单元106的每个处理器110u和110t可以生成总和位和进位位,可以将其总和位返回到自身(如返回箭头114所指示的,并且作为下一个周期的输入),并且可以将其进位位提供给行中的下一个处理器(如箭头115所指示的)。如上文提到的,累加处理器110u也可以从相邻的乘法处理器110m和求和处理器110s接收总和位。然而,尾端处理器110t只能对其反馈的总和位以及对来自行中其前任处理器110s或110t的进位位进行运算。
注意,可能有m行乘法处理器110m和m行求和处理器110s,使得可能有2m个累加处理器110u。可能有q个尾端处理器110t,其中q至少为log2(n)并且n是要相乘和累加的值的数目。
应该理解,乘法器-累加器100中的运算可以并行进行,其中每列可以与其他列同时运算。因此,将精度从4位增加到8位不会显著地影响乘法器-累加器100的定时,尽管这确实增加了其大小。
此外,应理解,乘法器-累加器100可能只能针对整数运算进行运算,因为它不处理指数。
现在简要参考图2a、图2b和图2c,这些图分别示出了处理器110m、110s和110u。乘法处理器110m包括异或运算器120和全加法器122m。
异或运算器120可以接收被乘数位ai和bj,并且可以产生它们的乘法ai*bj。异或运算器120可以是任何合适的异或运算器。例如,异或运算器120可以在位线上实现,并且可以将其输出提供给全加法器122的输入中的标记为in的一个输入。
全加法器122m可以将从先前计算接收到的输入总和位sin和输入进位位cin加到当前输入值(即,异或输出)。全加法器122m可以分别生成新的总和位sout和进位位cout,并且可以传递接收到的ai的值。
全加法器122m可以是任何合适的全加法器。例如,全加法器122m可以类似于在作为us2018/0157621公开的美国专利申请15/708,181中所描述的全加法器,该申请转让给本申请的本申请人,并且通过引用并入本文。us2018/0157621讨论了如何在存储器阵列内实现多个并行的全加法器122,使得所有加法运算并行发生。添加异或120添加了最小数量的运算,并且也可以并行执行。因此,位线处理器110的每一行可以彼此并行地运算,将ai乘以bj,然后将结果加到提供给它们的总和位和进位位。
如图2b中所示,求和处理器110sa可以类似于乘法位线处理器110m,但不具有异或运算器120。相反,求和处理器110sa仅包括全加法器122s,并且可以将从先前的计算接收到的输入总和位sin和输入进位位cin相加。全加法器122s可以分别生成新的总和位sout和进位位cout。
如图2c中所示,累加处理器110u可以类似于求和位线处理器110sa,但具有sout的反馈环路。全加法器122u可以将从先前的计算接收到的输入总和位sin和输入进位位cin加到来自先前的计算的输出总和位sout。全加法器122u可以分别生成新的总和位sout和进位位cout。
剩余的讨论将呈现以处理器110作为位线处理器的示例性实施方式;然而,应当理解,本发明也可以用非位线处理器来实现。
申请人已经意识到,按位乘法器-累加器100的结构可以实现流水线化运算,这是非常高效的运算。一旦第一行运算完成(即,在第一周期中将ai乘以b0),则ai向下移动一行,并且bj向下且向右移动,这将b1–b3带到第二行。
在下一个周期引入一组新的ai和bj,并且将其提供给第一行,因此,第二行可以对来自第一周期的数据进行运算,同时第一行可以对来自第二周期的数据进行运算。在每个周期中,旧数据下移一行,并且新数据移到现在腾空的前一行。
在第二周期中,lsb位被提供给第一累加位线处理器110u以开始累加结果位p0。如上文提到的,每个累加位线处理器110u可以输出其进位位,但是其总和被返回给它,以加到下一个周期中生成的值。这是累加运算——在原位求和并且进位到下一个更高有效位。
现在参考图3a–3i,其示出了数据如何在9个周期内移动通过按位乘法器-累加器100,以用于3个乘法的简单相加,其中每个被乘数是4位。由于所有值都有多个版本,图3a–3f根据值所属的周期标记每个值。因此,a01来自第一周期,a02来自第二周期,等等。
在图3a中所示的准备周期中,将第一组被乘数位ai1和bi1分别接收到输入单元102a和102b的接收位线处理器110a中。在准备周期之后的第一周期中,b01可以被传递到其信令位线处理器110c,该信令位线处理器110c进而可以将b01的值提供给其信令线112,以用于乘法位线处理器110m的第一行。
乘法位线处理器110m的第一行可以将其ai1与b01相乘(例如,ai1*b01),并且可以将其进位位(标记为ci0)和其ai向下传递到下一行,以及将其总和位(标记为si0)向下且在下一行中向右侧传递。应当理解,只有来自最右侧的乘法位线处理器110m的总和s001可以传递到其相关联的累加位线处理器110u(这里标记为p0),以在下一个周期中开始针对p0的计算。
在图3b中所示的第二周期中,可以在第二行的信令位线处理器110c中接收b01,信令位线处理器110c进而可以将其值提供给第二行的信令线112。同时,可以将分别接收到输入单元102a和102b的接收位线处理器110a的第二组被乘数ai2和bj2传递给乘法器-累加器100的位线处理器的第一行。因此,b02可以被传递给其信令位线处理器110c,以将其b02的值提供给乘法位线处理器110m的第一行。因此,乘法位线处理器110m的第一行可以将ai2与b02相乘,同时乘法位线处理器110m的第二行可以将ai1与b01相乘(ai1*b11),并且可以将结果加到从上面一行传递给它们的总和以及进位。例如,可以将a11*b11加到s201和c101以生成s111和c111。在第二周期结束时,如上文所讨论的,来自乘法位线处理器110m的两行的ai的总和、进位和值可以向下传递一行。
在第二周期中,累加开始于累加位线处理器p0接受从周期1传递给它的值(即,p01=s001)。累加位线处理器p0可以将p01的值反馈给自身,并且可以将其进位输出cp01传递给下一个累加位线处理器110u,这里标记为p1,其可以计算p1。此外,在该周期结束时,第一行和第二行的最右侧的乘法位线处理器110m可以分别将总和位s002和s011传递给累加位线处理器p0和p1。
图3c示出了第三周期中的运算。乘法运算与第二周期的乘法运算非常相似。在该周期中,按位乘法器104的第三行可以对来自第一周期的数据进行运算,第二行可以对来自第二周期的数据进行运算,并且第一行可以对来自第三周期的数据进行运算。
在这个周期中,累加位线处理器p0将从第二周期传递给它的s002的值与前一个值p01相加,以生成累加位p02。累加位线处理器p0可以反馈p02的值,并且可以将其进位位cp02传递给累加位线处理器p1。同时,累加位线处理器p1可以将从第二行的最右侧的乘法位线处理器110m(其处理第一周期的数据)传递给它的总和位s011与在前一周期中从累加位线处理器p0接收到的进位位cp01相加。
应当理解,每个累加位线处理器(例如,p0和p1)首先从周期1接收数据,然后从周期2接收数据,等等。因此,在周期3中,第三行中的p1处理周期1数据,同时第二行中的p0在其在上一个周期中接收到的周期1数据的基础上累加周期2数据。
图3d示出了第四周期。由于这个示例仅示出了三个乘法的累加,因此在该第四周期中,没有更多的输入。典型地,按位乘法-累加器100可以累加数千个值,但是在某个时间点,累加结束。
在图3d中,累加位线处理器p0累加第三周期的lsb数据并完成。存储在其中的值是三个相乘的值的lsb(即,p03),并且因此,累加位线处理器p0可以将存储在其中的值移动到外部寄存器(未示出)。
尽管为了便于理解在图3a–3i中未示出,但是按位乘法-累加器100可以在下一个周期中的下一个mac运算上开始,并且可以带来要由乘法位线处理器110m的现在为空的第一行进行运算的一组新的被乘数a和b。
累加位线处理器p1和p2可以如上文所讨论的进行运算,将接收到的lsb总和位与先前存储在其中的值相加,其中累加位线处理器p1可以对来自周期2的数据(来自最右侧的乘法位线处理器的总和以及来自累加位线处理器p0的进位)进行运算,并且累加位线处理器p2可以对来自周期1的数据进行运算。
在图3e中所示的第五周期中,乘法器104的第一行(图中未示出)和第二行(图3e的顶部示出)为空,并且累加位线处理器p0不再累加。来自第一周期的数据现在在求和位线处理器110s的第一行中。如上文提到的,由于对msb(最高有效位)运算的乘法位线处理器110m仅生成总和位,因此在乘法器104的第二部分的第一行中只有三个求和位线处理器110sa。该行的求和位线处理器110sa仅将从前一行接收到的总和和进位相加,并且将它们的结果总和和进位提供给下一行。该行的lsb位so41被提供给累加位线处理器p4。累加位线处理器p2和p3可以如上文所讨论地运算,并且累加位线处理器p1累加第三周期的lsb数据并完成。
在图3f中所示的第六周期中,乘法器104的前三行为空(因此,图3f中未示出前两行),并且累加位线处理器p0和p1不再累加。来自第一周期的数据现在在求和位线处理器110s的第二行中。在该第二行中,有三个位线处理器110s,其中最左侧的处理器是数据传递处理器110sb,并且其余的处理器是求和位线处理器110sa。
数据传递处理器110sb可以接收进位c24,该进位c24可以从来自a3*b3的乘法的总和s33以及来自其邻居的进位c23生成。c24将继续传递,直到它传递到p7——单独的乘法中的任一个的msb。
该行的两个求和位线处理器110sa将从前一行的三个求和位线处理器110sa接收到的总和和进位相加,并且将它们的结果总和和进位提供给下一行。该行的lsb位so51被提供给累加位线处理器p5。累加位线处理器p3和p4可以如上文所讨论地运算,并且累加位线处理器p2累加第三周期的数据并完成。
在图3g中所示的第七周期中,乘法器已完成运算。来自第一周期的数据现在在求和位线处理器110s的第三行中,该行具有两个位线处理器110s,这两个位线处理器都是数据传递处理器110sb。
数据传递处理器110sb可以接收针对周期1的数据的进位c24和总和s15(在前一行中生成)。进位c24可以传递到下一行,而总和s15可以传递到p6。
累加位线处理器p4和p5可以如上文所讨论地运算,并且累加位线处理器p3累加第三周期的数据并完成。
乘法处理在图3h中所示的第八周期中完成。乘法器104的第八行包括单个数据传递处理器110sb,其接收进位c24的数据并且将其传递给累加位线处理器p7。累加位线处理器p5和p6可以如上文所讨论地运算,并且累加位线处理器p4累加第三周期的数据并完成。
在接下来的三个周期中(其中的第一周期在图3i中示出),累加位线处理器p5、p6和p7分别累加第三周期、第二周期和第三周期以及第一周期至第三周期的数据,以完成其计算。
如果存在要被累加的三个以上的乘法,则累加位线处理器110u(即,处理器p0–p7)的输出可以传递到尾端处理器110t(图1)以继续累加位。
应当理解,按位乘法器-累加器100针对mac单元具有非常高效的结构。当用位线处理器实现时,它可能特别高效,这是由于各种位线处理器110具有非常相似的结构,并且所有这些位线处理器110都可以在存储器阵列中实现,如下文中更详细地讨论的。此外,按位乘法器-累加器100在乘法运算期间通过对每一位而不是对被乘数a和b的全部位值进行运算来执行累加运算的一部分。
此外,如上文提到的,当乘法运算已经完成时,累加运算的一部分已经完成,使得乘法器-累加器100可以在完成上一个乘法-累加运算的同时开始下一个乘法-累加运算。
此外,如上文提到的,当仅向按位乘法器-累加器100提供一对被乘数时,按位乘法器-累加器100也可以用作乘法器。
现在参考图4,图4示出了三个相邻的乘法位线处理器110m,其中乘法位线处理器110m-i-j在乘法器-累加器100的第j行和第i列中,并且对被乘数a的第i位和被乘数b的第j位运算,乘法位线处理器110m-i-(j+1)也在第i列中,但在第(j+1)行中,并且乘法位线处理器110m-(i-1)-(j+1)在第(i-1)列和第(j+1)行中。
每个位线处理器110m可以由单个列中的至少7个存储器单元202形成,所有存储器单元202都附接到单个位线200。位线200和存储器单元202可以形成其中实现乘法器-累加器100的存储器阵列的一部分。如图4中所示,每个单元保存不同的值,其中,在图4的实施例中,第一单元存储被乘数位ai,第二单元存储被乘数位bj,第三单元存储来自前一行的进位位ci(j-1)i,并且第四单元存储来自前一行以及下一列的总和位s(i+1)(j-1)。这些是位线处理器110m的输入,大多数从前一个周期接收,但是在下面描述的运算发生之前,可以在当前周期中接收被乘数位bj。
位线处理器110m中的其他单元可以存储对四个输入的运算的中间和最终结果。
乘法位线处理器110m的运算可以在四个主要步骤中发生。在第一步骤中,乘法位线处理器110m-i-j可以对存储ai和bj的单元执行异或运算,并且可以将结果存储在aixorbj单元中,该aixorbj单元在图4中作为第五单元示出。在美国专利8,238,173中讨论了异或运算,并且可能涉及同时激活存储ai和bj的两行,从而在位线202中接收布尔函数结果。
在第二步骤中,乘法位线处理器110m-i-j可以实现如上文所讨论的全加法器122m,以将以下位一起相加:ci-(j-1)、s(i+1)(j-1)和(aixorbj),以生成进位位ci-j和总和位si-j。
在第三步骤中,乘法位线处理器110m-i-j可以将位ai和c-i-j读取和写入到乘法位线处理器110m-i-(j+1);并且在第四步骤中,乘法位线处理器110m-i-j可以将si-j读取和写入到乘法位线处理器110m-(i-1)-(j+1)。可替代地,全加法器122m可以直接写入进位位ci-j和总和位si-j。
应当理解,按位乘法器-累加器100可以一起激活每个位线处理器110,使得每个周期是完全并行的运算。如在图4的底部一行中可以看出的,相邻的位线处理器110m将相同类型的位值存储在相同的行中。因此,在图4中,可以同时激活存储所有ai和bj的行,并且可以同时将异或结果写入所有位线处理器110的(aixorbj)单元中。针对全加法器运算也是如此。
可以经由上文提到的美国专利9,418,719中描述的复用器来实现从一个位线处理器到下一个位线处理器的并行复制。
因此,一个周期的所有运算可以一起执行,从而进一步提高按位乘法器-累加器100的流水线化效率。
尽管本发明的某些特征已经在本文中进行了说明和描述,但是本领域普通技术人员现在将想到许多修改、替换、改变和等同物。因此,应当理解,所附权利要求旨在涵盖落入本发明真正精神范围内的所有此类修改和改变。
- 还没有人留言评论。精彩留言会获得点赞!