一种博弈策略优化方法、系统及存储介质与流程
本发明涉及人工智能技术领域,尤其涉及基于多智能体强化学习和虚拟自我对局的博弈策略优化方法、系统及存储介质。
背景技术:
现实场景中的诸多决策问题都可以建模成非完备信息博弈中的策略求解问题,但目前的机器博弈算法需要对问题的状态空间进行抽象,在高维动作空间中表现不佳,且通常仅适用于二人博弈,而实际问题中的博弈大多数是多人博弈。
神经网络虚拟自我对局(neuralfictitiousself-play,nfsp)是一种在机器博弈领域引发诸多关注的博弈策略求解方法,通过自我博弈来进行学习,分别利用深度强化学习和监督学习来实现机器博弈中最佳响应策略的计算和平均策略的更新。自博弈通过采样的方式来构造智能体的强化学习记忆,使其相当于近似对手采取平均策略的马尔可夫决策过程(markovdecisionprocess,mdp)经验数据。因此通过强化学习算法对mdp(马尔可夫决策过程)进行求解可以求解近似最优反应策略,同样地,智能体的监督学习记忆可用来近似智能体自身的平均策略经验数据,然后通过有监督分类算法求解策略。nfsp(神经网络虚拟自我对局)智能体将其博弈的经验数据存储在一个有限的重放缓冲区中,进行蓄水池抽样来避免抽样误差。同时nfsp(神经网络虚拟自我对局)还可以使智能体使用预期动力学有效地跟踪其对手的策略变化。
但是在多智能体博弈中的策略学习本质上比单智能体博弈更复杂,多智能体博弈中往往具有非平稳性,智能体不光要与对手进行交互,而且会受到其他智能体策略的影响。nfsp(神经网络虚拟自我对局)中的预期动态可以感知二人博弈中的策略变化,但在多人博弈中作用有限。在nfsp(神经网络虚拟自我对局)中每次生成的样本对应固定的对手策略,如果无法感知其他智能体带来的策略影响,那么学习到的最优反应策略和平均策略都是不准确的,将会导致mdp(马尔可夫决策过程)的马尔可夫性失效。此外在多智能体博弈中还存在维度灾难、信用分配、全局探索等诸多问题。
技术实现要素:
本发明提供了一种博弈策略优化方法,该博弈策略优化方法基于多智能体强化学习和虚拟自我对局进行实现,包括如下步骤:
建立基于最大熵的策略递度算法步骤:在最大熵强化学习中,除了要最大化累计期望收益这个基本目标,还要最大化策略熵:
其中的
多智能体最优反应策略求解步骤:采用中心化训练分散式执行的方式来求解最优策略,通过基线奖励评估合作博弈中的智能体收益。
作为本发明的进一步改进,在所述建立基于最大熵的策略递度算法步骤中,温度系数a的损失函数如下:
上述公式的意义就是保持策略熵大于
本发明还提供了一种博弈策略优化系统,该博弈策略优化系统基于多智能体强化学习和虚拟自我对局进行实现,包括:
建立基于最大熵的策略递度算法模块:在最大熵强化学习中,除了要最大化累计期望收益这个基本目标,还要最大化策略熵:
其中的
多智能体最优反应策略求解模块:采用中心化训练分散式执行的方式来求解最优策略,通过基线奖励评估合作博弈中的智能体收益。
作为本发明的进一步改进,在所述建立基于最大熵的策略递度算法模块中,温度系数a的损失函数如下:
上述公式的意义就是保持策略熵大于
本发明还提供了一种博弈策略优化装置,该博弈策略优化装置基于多智能体强化学习和虚拟自我对局进行实现,包括:存储器、处理器以及存储在所述存储器上的计算机程序,所述计算机程序配置为由所述处理器调用时实现本发明所述的博弈策略优化方法的步骤。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的博弈策略优化方法的步骤。
本发明的有益效果是:本发明采用中心化训练和分散式执行的方式,提高动作估值网络的准确性,同时引入了全局基线奖励来更准确地衡量智能体的动作收益,以此来解决人博弈中的信用分配问题。同时引入了最大熵方法来进行策略评估,平衡了策略优化过程中的探索与利用。
附图说明
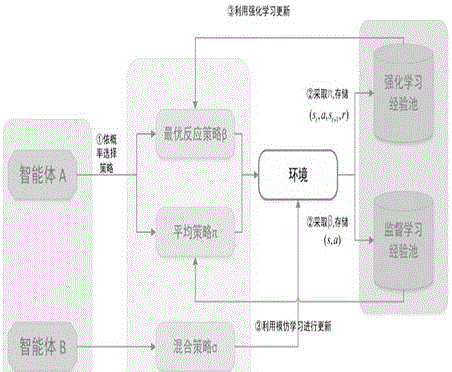
图1是背景技术的nfsp(神经网络虚拟自我对局)算法框架图;
图2是本发明的基于最大熵的策略梯度算法示意图;
图3是本发明的基于基线奖励的多智能体强化学习示意图;
图4是多智能体nfsp(神经网络虚拟自我对局)网络结构示意图。
具体实施方式
针对虚拟自我对局算法(nfsp)无法有效扩展到多人复杂博弈中的问题,本发明公开了一种博弈策略优化方法,该博弈策略优化方法基于多智能体强化学习和虚拟自我对局进行实现,采用中心化训练和分散式执行的方式,提高动作估值网络的准确性,同时引入了全局基线奖励来更准确地衡量智能体的动作收益,以此来解决人博弈中的信用分配问题。同时引入了最大熵方法来进行策略评估,平衡了策略优化过程中的探索与利用。
假设与定义:
强化学习的定义是学习如何从某个状态映射到某个行为,来最大化某个数值的奖励信号。强化学习的过程可以看成是智能体与环境的不断交互,交互的过程可以理解为试错,试错便是强化学习的重要特征,智能体通过学习不断调整策略来最大化累计期望奖励。在每一次交互过程中,环境会返回智能体一个反馈,反馈可以看成是一种带标签样本,由于环境反馈的奖励通常是延迟稀疏的所以反馈数据具有延时性,延迟奖励是强化学习的另一个重要特征。强化学习问题通常是通过马尔可夫决策过程来进行建模,因为强化学习的假设就是满足马尔可夫性(markovproperty),即是下个状态的概率分布只与当前状态有关而与之前的历史状态无关。马尔可夫决策过程可以用一个五元组<s;a;r;p;γ;>来表示,其中s表示状态空间,a表示有限动作集合,p即是状态转移概率,γ表示折扣因子,因为未来状态具有不确定性因此收益值会随着时间衰减,因此累计收益可以表示为:
其中
在标准的强化学习问题中,算法学习目标就是要求解一个策略能够最大化累计期望收益:
2.基于最大熵的策略梯度算法:
在最大熵强化学习中,除了要最大化累计期望收益这个基本目标,还要尽可能地最大化策略熵(policyentropy):
其中
采用的基于最大熵的策略梯度算法实质也是一种actor-critic算法,采用参数化的神经网络拟合估值网络
该方法借鉴了dqn的经验回放思想,利用智能体交互的数据构建了一个回放缓冲池。其中
其中在计算策略网络的损失时,引入了一个重新参数化的技巧
在策略学习的不同阶段,往往需要不同程度的探索与利用,因此这个温度系数对最终策略的影响显而易见。如果采用固定的温度系数,那么策略是无法应对博弈场景发生奖励变化的。那么采用一个可学习的温度系数是至关重要的,具体实现可以构造一个带约束的优化问题,相当于在最大化智能体期望收益的同时保持策略熵大于一个设定的阈值。那么温度系数的损失函数如下:
其中
基于基线奖励的多智能体最优反应策略求解:
上述基于最大熵的强化学习算法可以用来求解nfsp(神经网络虚拟自我对局)中的最优反应策略,但是在多智能体博弈中往往具有非平稳性,智能体不光要与对手进行交互,而且会受到其他智能体策略的影响。nfsp(神经网络虚拟自我对局)中的预期动态可以感知二人博弈中的策略变化,但在多人博弈中作用有限。针对多智能体博弈中非平稳性问题,采用中心化训练分散式执行的方式来求解最优策略。具体是在训练阶段允许利用其他智能体的可见信息,在智能体根据策略执行动作时则仅根据自身可见信息做出判断。
在该方法中,对于智能体i的估值网络critic的损失函数如下:
其中
对于智能体i的策略网络actor的梯度公式如下:
其中
除了通过解决多智能体博弈系统中的非平稳问题来优化nfsp(神经网络虚拟自我对局)中的策略优化,本发明还将针对信用分配问题引入一些解决办法,主要思想是引入一个基线奖励来更好地评估合作博弈中的智能体收益。
由图3可以看出为了在多智能体中更好地共享信息,在前面中心化训练分散式执行的基础上做了一些改动,把评估网络critic合并为一个,即利用一个集中的critic来评估所有智能体的行为,而不是原来的智能体单独训练自己的估值网络,这个改动不光可以增强智能体的协作能力同时还能中心化地计算基线奖励。通过这样一个中心化的
第一项表示选取动作
本发明还公开了一种基于多智能体强化学习和虚拟自我对局的博弈策略优化系统,包括:
建立基于最大熵的策略递度算法模块:在最大熵强化学习中,除了要最大化累计期望收益这个基本目标,还要最大化策略熵:
其中
多智能体最优反应策略求解模块:采用中心化训练分散式执行的方式来求解最优策略,通过基线奖励评估合作博弈中的智能体收益。
在所述建立基于最大熵的策略递度算法模块中,温度系数a的损失函数如下:
其中
在所述多智能体最优反应策略求解模块中,采用中心化训练分散式执行的方式来求解最优策略的具体技术方案是:在训练阶段允许利用其他智能体的可见信息,在智能体根据策略执行动作时则仅根据自身可见信息做出判断,对于智能体i的估值网络critic的损失函数如下:
其中
对于智能体i的策略网络actor的梯度公式如下:
其中
在所述多智能体最优反应策略求解模块中,通过基线奖励评估合作博弈中的智能体收益的具体技术方案是:利用一个集中的评估网络critic评估所有智能体的行为,通过中心化的
第一项表示选取动作
本发明还公开了一种博弈策略优化装置,该博弈策略优化装置基于多智能体强化学习和虚拟自我对局进行实现,包括:存储器、处理器以及存储在所述存储器上的计算机程序,所述计算机程序配置为由所述处理器调用时实现本发明所述的博弈策略优化方法的步骤。
本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的博弈策略优化方法的步骤。
本发明的有益效果将通过如下实验进行说明:
1.实验设置:
为了验证本发明的有效性,将本发明应用到neurips-2018(人工智能顶会2018)官方赛事多人pommerman游戏环境中,实现智能体博弈策略的优化。pommerman是neurips会议(人工智能顶会)上开设的多智能体竞赛,将多智能体协作、非完全信息博弈以及持续学习等关键问题浓缩到炸弹人竞赛中。赛事官方提供了基于图规则的专家智能体simpleagent,该智能体具有一定的博弈水平,适合用来作为基线进行对比试验。
具体实现是将pommerman环境中原始的状态表示矩阵编码为一个11*11*19的状态表征张量,作为网络的输入。状态表征矩阵中包括了地图信息、智能体炸弹威力、敌方智能体信息等,此外还加入了可以表征智能体存活时长的矩阵。最优反应策略求解部分是基于中心化训练分散式执行框架的,通过智能体共享的全局信息和动作训练了一个中心化的估值网络critic,并在损失函数中添加了策略熵来平衡探索和利用,更新方式是最小化均方差,critic的作用是对actor输出的网络进行评估。而actor网络是利用优势函数进行单独更新,优势函数是通过critic网络估值和一个基线奖励计算得到,基线奖励是在其他智能体采取默认动作的情况下自身策略的期望,actor网络用来拟合智能体的最优反应策略。平均策略则是采用行为克隆进行更新。平均策略的状态输入与最优反应策略一致,且共用一个卷积模块进行特征映射,输出都是一个6维的概率分布,表示智能体策略,其网络结构如图4所示。
现有方法对比:
(1)hitsz_scut:获得neruaips-2018pommerman第九名的智能体,其主要方法是在本发明多智能体虚拟自我对局的基础上引入了更多手工设计的规则。
(2)maddpg:中心化训练和分散化执行,允许使用一些额外的信息(全局信息)进行学习,只要在执行的时候仅使用局部信息。
(3)coma:引入基线奖励,解决多智能体信用分配问题。
实验结果:
本发明做了nfsp相关算法的训练结果实验,表示智能体与simpleagent对战的胜率曲线变化。可以看出基于最大熵的nfsp(神经网络虚拟自我对局)算法相较于其余两种方法收敛更慢,这是由于最大熵考虑的是探索与利用的平衡,不会过度利用当前的最优策略,在策略探索上花费的学习成本更多,收敛目标是一个泛化性更强的策略。而基于基线奖励的nfsp(神经网络虚拟自我对局)方法相比于其余两种方法有一定优势,这是因为实验中采取的是pommerman的团队模式,因此同一支队伍的智能体会共享一个全局奖励,而通过引入基线奖励则是可以更好地评估智能体动作对全局奖励的实际贡献,相当于优化了多智能体博弈中的信用分配。
本发明做了基于最大熵和基线奖励的多智能体nfsp(神经网络虚拟自我对局)智能体与其他算法的对比结果实验,纵轴表示奖励,游戏中只有获胜才可以得到+1奖励,平局和失败都只能获得-1奖励。在该实验中可以看出基于最大熵和基线奖励的多智能体nfsp(神经网络虚拟自我对局)收敛较快。coma引入的基线奖励相较于maddpg更适用于这种合作的博弈场景,而maddpg虽有共享信息的训练过程但未能处理好这种合作场景中的共享奖励问题,图中显著优于maddpg。而hitsz_scut由于利用先验知识手工设计规则会在实际场景中应用受限。除了nfsp(神经网络虚拟自我对局)的其余三种算法均是以simpleagent作为对手进行训练,而nfsp(神经网络虚拟自我对局)则是通过自博弈的方式进行策略优化,同时还引入了最大熵,虽然其他方法在对局simpleagent的对局更有优势,但最大熵和基线奖励的多智能体nfsp(神经网络虚拟自我对局)泛化性会更好。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!