一种基于轻量化网络的目标检测方法与流程
本申请涉及计算机技术领域,尤其涉及无人驾驶、辅助驾驶等计算机视觉领域中有效的目标检测方法,特别是涉及一种基于轻量化神经网络的目标检测方法。
背景技术:
物体检测是指利用计算机技术检测与识别出图像或视频中感兴趣目标(如车辆、行人、障碍物等)的类别与位置信息,是计算机视觉领域中重要研究领域之一。随着深度学习技术的不断完善与发展,基于深度学习的物体检测技术已经在诸多现实领域中具有广泛的应用场景,例如:无人驾驶、辅助驾驶、人脸识别、无人安防、人机交互、行为识别等相关领域中。
卷积神经网络(convolutionalneuralnetworks,简称cnn,有时也称为convnet)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforwardneuralnetworks),是深度学习(deeplearning)的代表算法之一。作为深度学习技术中的重要研究方向之一,深度卷积神经网络在物体检测任务上已经取得了显著成果,能够在图像数据中实现对感兴趣目标的实时检测与识别。
目前现有的技术就是改变卷积神经网络的参数,目前通用的几种方法是放大卷积神经网络的深度、宽度以及分辨率,在现有技术的放大卷积网络的方法,常用手段就是单独放大这三个维度中的一个,尽管任意放大两个或者三个维度也是可能的,但是任意缩放需要繁琐的人工调参,同时可能产生的是一个次优的精度和效率,使得最后输出图像的精度和识别效率并没有达到理想的值,例如导致目标识别率降低;与此同时,由于识别网络框架的限制,反而会造成目标检测的识别效率降低的问题。例如,现有技术的技术采取了模型缩放的方法提高目标检测的精度:如缩放cnn神经网络以适应不同的资源约束;再或者resnet[4]通过调整网络深度(层)来缩小(例如resnet-18)或增大(例如resnet-200);再或者wideresnet[5]、mobilenets[6]通过网络宽度(频道)来缩放cnn来提高识别图像的识别率。
下面就对三个维度单独缩放进行解释现有技术中存在的技术的缺陷:
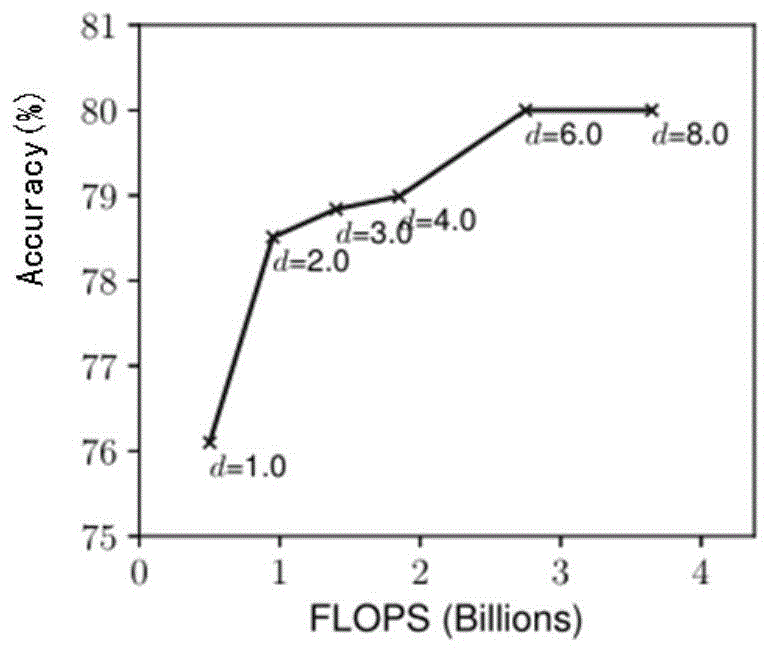
(1)加深深度(d):加深神经网络深度是许多convnets最常用的方法。最根本的原因是:更深层的convnet可以获取输入图像中更多的的特征信息,并在新的输入图像中更好地进行分类概括。请参见图1,然而,随着深度的提升,其网络对应的梯度消失,且更深层的网络也更难训练。尽管目前技术通过采用较深网络来缓解了其训练困难的问题:例如,resnet-1000(resnet网络第1000层)和resnet-101相比,具有更深的深度,但是检测精度相似。图1显示了不同深度系数d缩放网络基础模型的经验研究,进一步表明了较深的网络的精度的增长速度递减。
(2)增加宽度(w):缩放网络宽度通常适用用于小型模型,更宽广的的网络往往能够获得更多其输入图像的特征信息等特性,并且宽度更大的网络更容易训练。然而,较宽但较浅的网络往往难以捕获更高层次的特征。图2的结果表明,当网络变得更宽且w更大时,其检测精度达到一定时,无法提升至最优,导致其可调优精度有限。
(3)增加分辨率(r):使用更高分辨率的输入图像,convnets可以捕捉潜在的输入图像的更多像素的特征信息。从早期convnets的224x224开始,现代convnets倾向于使用299×299或331×331以获得更好的精度。图3显示了缩放网络分辨率的结果,总体上是提高了目标检测的精度,但是对于较高分辨率的输入图像,其检测精度到达一定程度时仍然未持续增加。
综上所述,可以得出结论:放大网络宽度、深度或分辨率的任何维度都可以提高精度,但对于更大的网络架构模型,其输出的图像目标物识别率反而会有所降低。
因此,如果轻量化网络架构模型并使得输出的图像目标物识别率达到最高,是本领域研究的重点。
技术实现要素:
本申请提供一种目标检测方法,通过平衡卷积神经网络中的网络深度、网络宽度和网络分辨率,并提出了一种新的网络的缩放的方法,使得本案的目标提取方法输出的图片分辨率高且效率高。
本发明的技术思路是,一种基于轻量化网络的目标检测方法,包括如下步骤:
step101,获取待检测图像,并根据卷积神经网络得到目标处理值,所述目标处理值包括所述待检测图像的分辨率r、所述卷积神经网络的深度w以及宽度d;
step102,根据所述目标处理值,进行复合优化处理,得到所述卷积神经网络的最大精确度(acc)和浮点运算速率(flops);
step103,将最大精确度(acc)和浮点运算速率(flops)进行优化处理,得到目标优化值taget,所述目标优化值用于衡量所述卷积神经网络中的检测效率;
taget=acc(m)×[flops(m)/t]w'(6)
其中,acc(m)和flops(m)表示该卷积神经网络的最大精确度和浮点运算速率,m表示卷积神经网络层数,其中t和w’是空间参数;
step104,利用优化后的卷积神经网络实现待检测图像的目标检测。
进一步的,step102的具体实现包括,
step1021,学习训练集得到浮点运算速率(flops),浮点运算速率flops与d2,w2,r2这些参数成比例,即flops=k1d2=k2w2=k3r2,其中k1、k2、k3为固定常数,根据目标处理值和浮点运算速率,计算参数α、β、γ和φ;
step1022,根据参数α、β、γ和φ,d、w和r重新赋值得到d′、w′和γ′;
深度:d′=αφ
宽度:w′=βφ(4)
分辨率:γ′=γφ
s.t.:α·β2·γ2≈2
α≥1,β≥1,γ≥1
其中,α、β、γ是常量,φ是一个固定系数,用于控制该卷积神经网络中的空闲空间,而α、β、γ用于将这些空闲空间分配给卷积神经网络的宽度、深度以及分辨率;
step1023,根据所述d′、w′和γ′,得到所述卷积神经网络的最大精确度acc,
约束条件
(s.t.)memory(n)≤target_memory
flops(n)≤target_flops
其中,
进一步的,系数φ=1。
进一步的,w=-0.07。
本发明所提供的技术方案的有益效果为:提出了一种新的网络的缩放的方法,使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率,减少了网络缩放的参数,有效平衡了卷积神经网络中的网络深度、网络宽度和网络分辨率,使得本案的目标检测方法输出的图片分辨率高且效率高。
附图说明
下面结合附图,通过对本申请的具体实施方式详细描述,将使本申请的技术方案及其它有益效果显而易见。
图1为加深深度(d)对准确率的影响示意图;
图2为加深宽度(w)对准确率的影响示意图;
图3为增加分辨率(r)对准确率的影响示意图;
图4为同时增加深度和分辨率对准确率的影响示意图;
图5为增加宽度、深度、分辨率以及组合增加的神经网络结构示意图;
图6为本发明实施的神经基础网络示意图;
图7为本技术交底书的流程图;
图8为本技术应用效果示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
基于上述现有技术的缺点及本申请提案所要解决的问题,本技术交底书提出了一个简单高效的复合缩放方法,不像传统实践中任意缩放这个神经网络架构中任一维度的参数及因子,我们的方法使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率。
在阐述本技术交底书提供的模型缩放方法之前,我将对模型缩放方法进行阐述:
yi=fi(xi)(1)
在卷积神经网络,convnetlayeri可以被定义为一个函数:
在该公式(1)中,fi是运算符,yi是输出张量,xi是输入张量,其中任一张量的映射可以表现为<hi,wi,ci>,其中hi和wi是空间维度,ci表示通道维度。一个神经网络converts可以由各个组成层convnetlayeri表示:
n=fk⊙...⊙f2⊙f1(x1)=⊙j=1...kfj(x1)(2)
例如,convnet层通常被划分为多个阶段,每个阶段中的所有层共享相同的体系结构:
例如,在resnet中,每个阶段中的所有层都具有相同的卷积类型,除了第一层执行下采样。因此,我们可以将convnet定义为:
图5(a)展示了一个典型的卷积神经网络(convnet),且其空间维度逐渐缩小,通道维度在各个层上逐渐展开,其卷积神经网络从初始输入映射<224,224,3>扩展到最终输出映射<7,7,512>。与通常的convnet设计不同的是,convnet设计主要集中在寻找最佳的层网络架构fi,该模型缩放扩展网络长度(li)、宽度(ci)和/或分辨率(hi,wi),不改变该基础网络预定义的运算组成函数fi。
具体的,本技术交底书所提供的目标检测方法可参见图7:
如图7所示,step101:获取待检测图像,并根据卷积神经网络得到目标处理值,所述目标处理值包括宽度w,深度d和分辨率r,其中w表示卷积神经网络的宽度,即卷积核大小,其决定了该卷积神经网络感受野大小;d表示神经网络的深度;r表示待检测图像的分辨率大小。
在现有技术中,在卷积神经网络convnetlayeri可以被定义为一个函数:
yi=fi(xi)(3)
在该公式(1)中,fi表示卷积神经网络各层的组成函数,yi是输出张量,xi是输入张量,其中任一输入张量的映射可以表现为xi=<hi,wi,ci>,其中hi和wi是空间维度,ci表示通道维度。
convnet层通常被划分为多个阶段,每个阶段中的所有层共享相同的体系结构:例如,在resnet中,每个阶段中的所有层都具有相同的卷积类型,除了第一层执行下采样。因此,我们可以将convnet定义为:
需要说明的是,目标处理值中,宽度
step102:根据所述目标处理值,进行复合优化处理,得到最大精确度acc和浮点运算速率flops。
具体的,请参见下图8,所述复合优化处理的步骤可以分为如下三个步骤:
step1021:学习训练集得到浮点运算速率flops,根据目标处理值和浮点运算速率,计算得参数α,β,γ和φ;
所述浮点运算速率flops是所述神经网络在训练数据集中主动学习得到的数据,表示在未输入待检测图像时,所述神经网络检测到目标物所需要的浮点运算速率;
需要说明的事,所述浮点运算速率flops和d2,w2,r2这些参数成比例,即flops=k1d2=k2w2=k3r2,其中k1、k2、k3为固定常数。
需要说明的是,加倍网络深度、加倍网络宽度会让其运算速率增加4倍。由于卷积运算通常主导了卷积网的计算成本,用上述公式对卷积神经网络进行缩放,故引入一组参数(α2·β2·γ2),该参数中α、β和γ与d2,w2,r2成正相关,因此,本技术交底书可以通过控制(α2·β2·γ2)以增加卷积神经网络的浮点运算速率(flops)。
优选的,在本技术交底中,采用(α2·β2·γ2)≈2,使得本技术交底提出的目标检测方法提高了2φ倍,其中φ为固定参数。
step1022:根据参数α、β、γ和φ,重新赋值得到d′、w′和γ′。
在本文中,我们提出一个新的复合扩展方法,它通过使用一个复合系数φ来对网络架构的宽度、深度和分辨率来进行优化:
深度:d′=αφ
宽度:w′=βφ(4)
分辨率:γ′=γφ
s.t.:α·β2·γ2≈2
α≥1,β≥1,γ≥1
其中,α、β、γ是常量,且位于某个实数范围内。φ是一个固定系数,用于控制该网络模型中的空闲空间,而α、β、γ用于将这些空闲空间分配给网络的宽度、深度以及分辨率。
需要说明的是,由于α,β,γ和均为常数,为了更好的平衡和,以此达到一个更优的检测效果,该α,β,γ和取值可采用以下两步骤进行取值:
step10221:修正复合系数φ=1,若该网路模型有比基础网络多2倍空间的空闲网络,α,β,γ在公式(3)和公式(4)中做一个搜索取值。
step10222:根据已搜索取值的修正常量α,β,γ,并在α,β,γ常量的范围内对复合系数φ进行搜索取值。
step1023:根据所述d′、w′和γ′,得到所述卷积神经网络的最大精确度acc;
目前对卷积神经网络调优可采用两种方法:第一,通过修正该模型中的fi,该网络模型缩放解决了网络架构大小受限制的问题,它仍然具有很大的网络架构空间去在li,ci,hi,wi各个层进行调优;第二,为了进一步缩小网络架构的空间,通过限制所有层必须以恒定比例均匀缩放。进一步的,还可以将两种方法进行结合,以使得该模型的最大化精确度为预先设置的最大阈值,并且可以通用于下述任意一种模型:
约束条件
(s.t.)memory(n)≤target_memory
flops(n)≤target_flops
其中,
表1本技术交底提供的神经网络的组成参数表
step103,将所述最大精确度acc和所浮点设运算速率(flops)优化处理,得到目标优化值。
本技术交底中的神经网络利用多目标神经网络架构来提高该神经网络的准确性(acc)和浮点运算速率(flops)。具体来说,我们使用相同的搜索向量,并使用目标优化值,其优化值的公式(6)作为是优化目标。
taget=acc(m)×[flops(m)/t]w(6)
需要说明的是,acc(m)和flops(m)表示该网络模型的准确性和浮点运算速率,m表示卷积网络层数,t是用于目标运行速率。
优选地,本技术交底中w=-0.07,其中t和w都是空间参数,用于平衡该网络模型的准确性和运行速率。
step104,在mobilenet网络上,固定φ=1,然后按上述方法找到满足公式(4)的最优α、β、γ,最后的实验结果如图8所示,可以看到本优化网络在取得和其他分类网络差不多的准确率时,参数量和计算量都很减少很多。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!