一种视频生成方法、装置、电子设备及存储介质与流程
1.本公开涉及计算机技术领域,尤其涉及一种视频生成方法、装置、电子设备及存储介质。
背景技术:
2.相关技术中,在基于一个二维人脸图像生成有表情变化的人脸视频时,常通过手动调整二维人脸图像或者由设计人员使用动画制作工具制作多帧人脸表情图像,进而基于多帧人脸表情图像生成一个有表情变化的人脸视频,一方面由于过程复杂且消耗较大的人力,无法规模性生成有表情变化的人脸视频,另一方面由于生成的人脸视频依赖于设计人员的技术,不能保证生成的人脸视频的质量。
技术实现要素:
3.本公开实施例提供一种视频生成方法、装置、电子设备及存储介质,用于简化根据二维人脸图像生成动态的人脸视频的过程。
4.本公开第一方面,提供一种视频生成方法,包括:
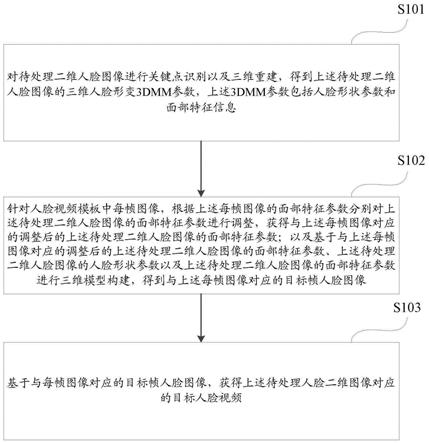
5.对待处理二维人脸图像进行关键点识别以及三维重建,得到所述待处理二维人脸图像的三维人脸形变3dmm参数,所述3dmm参数包括人脸形状参数和面部特征参数;
6.针对人脸视频模板中每帧图像,根据所述每帧图像的面部特征参数分别对所述待处理二维人脸图像的面部特征参数进行调整,获得与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数;以及基于与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数、所述待处理二维人脸图像的人脸形状参数以及所述待处理二维人脸图像的面部特征参数进行三维模型构建,得到与所述每帧图像对应的目标帧人脸图像;
7.基于与所述每帧图像对应的目标帧人脸图像,获得所述待处理人脸二维图像对应的目标人脸视频。
8.在一种可能的实现方式中,所述面部特征参数包括人脸的表情参数和姿态角信息,所述根据所述每帧图像的面部特征参数分别对所述待处理二维人脸的面部特征参数进行调整,获得与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数的步骤,包括:
9.基于每帧图像的姿态角信息调整所述待处理二维人脸图像的姿态角信息,得到与所述每帧图像对应的调整后的所述待处理二维人脸图像的姿态角信息;
10.分别将所述每帧图像的表情参数、与所述每帧图像对应的调整后的所述待处理二维人脸图像的姿态角信息,确定为与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数。
11.在一种可能的实现方式中,所述姿态角信息包括俯仰角、偏航角和翻滚角中的至少一个姿态角参数,所述基于每帧图像的姿态角信息调整所述待处理二维人脸图像的姿态
角信息,得到所述每帧图像对应的调整后的所述待处理二维人脸图像的姿态角信息的步骤,包括:
12.针对所述至少一个姿态角参数中每个姿态角参数,确定人脸视频模板中所有帧图像的所述每个姿态角参数的平均姿态角参数;
13.确定所述每帧图像的所述每个姿态角参数对应的偏差角,所述偏差角为所述每个姿态角参数与对应的平均姿态角参数的偏差值;
14.基于所述待处理二维人脸图像中所述每个姿态角参数和所述每帧图像中所述每个姿态角参数对应的偏差角,确定所述每帧图像对应的调整后的每个姿态角信息。
15.在一种可能的实现方式中,所述基于与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数、所述待处理二维人脸图像的人脸形状参数以及所述待处理二维人脸图像的面部特征参数进行三维模型构建,得到与所述每帧图像对应的目标帧人脸图像的步骤,包括:
16.针对所述每帧图像,根据所述待处理二维图像的面部特征参数和所述待处理二维图像的人脸形状参数进行三维模型构建,得到调整前的三维网格模型;
17.根据所述每帧图像对应的调整后的面部特征参数和所述待处理二维人脸图像的人脸形状参数进行三维模型构建,得到调整后的三维网格模型;
18.分别将所述调整前的三维网格模型和所述调整后的三维网格模型投影至同一平面,获得调整前的二维网格模型和调整后的二维网格模型;
19.将所述调整后的二维网格模型中各像素的像素值替换为所述调整前的二维网格模型中对应像素的像素值,得到所述每帧图像对应的目标帧人脸图像。
20.在一种可能的实现方式中,所述将所述调整后的二维网格模型中各像素的像素值替换为所述调整前的二维网格模型中对应像素的像素值,得到所述每帧图像对应的目标帧人脸图像的步骤之后,还包括:
21.对所述每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;
22.基于所述每帧图像对应的二维网格模型中的口腔区域调整所述每帧图像对应的目标帧人脸图像中的口腔边缘点,并将调整后的口腔边缘点确定的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
23.在一种可能的实现方式中,所述将所述调整后的二维网格模型中各像素的像素值替换为所述调整前的二维网格模型中对应像素的像素值,得到所述每帧图像对应的目标帧人脸图像的步骤之后,还包括:
24.若检测出所述每帧图像中存在口腔区域未闭合的图像,则对口腔区域未闭合的每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;
25.基于所述口腔区域未闭合的每帧图像对应的二维网格模型中的口腔区域调整所述口腔区域未闭合的每帧图像对应的目标帧人脸图像中的口腔边缘点,并将调整后的口腔边缘点确定的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
26.在一种可能的实现方式中,所述根据所述每帧图像的面部特征参数分别对所述待处理二维人脸图像的面部特征参数进行调整,获得与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数的步骤之前,还包括:
27.对所述每帧图像进行关键点识别;
28.根据关键点识别结果对所述每帧图像进行三维重建,得到所述每帧图像的3dmm参数中的面部特征参数。
29.本公开第二方面,提供一种视频生成装置,包括:
30.参数获取单元,被配置为执行对待处理二维人脸图像进行关键点识别以及三维重建,得到所述待处理二维人脸图像的三维人脸形变3dmm参数,所述3dmm参数包括人脸形状参数和面部特征参数;
31.目标帧人脸图像获取单元,被配置为执行针对人脸视频模板中每帧图像,根据所述每帧图像的面部特征参数分别对所述待处理二维人脸图像的面部特征参数进行调整,获得与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数;以及基于与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数、所述待处理二维人脸图像的人脸形状参数以及所述待处理二维人脸图像的面部特征参数进行三维模型构建,得到与所述每帧图像对应的目标帧人脸图像;
32.视频生成单元,被配置为执行基于与所述每帧图像对应的目标帧人脸图像,获得所述待处理人脸二维图像对应的目标人脸视频。
33.在一种可能的实现方式中,所述面部特征信息包括人脸的表情参数和姿态角参数,所述目标帧人脸图像获取单元具体被配置为执行:
34.基于每帧图像的姿态角信息调整所述待处理二维人脸图像的姿态角信息,得到与所述每帧图像对应的调整后的所述待处理二维人脸图像的姿态角信息;
35.分别将所述每帧图像的表情参数、与所述每帧图像对应的调整后的所述待处理二维人脸图像的姿态角信息,确定为与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数。
36.在一种可能的实现方式中,所述姿态角信息包括俯仰角、偏航角和翻滚角中的至少一个姿态角参数,所述目标帧人脸图像获取单元具体被配置为执行:
37.针对所述至少一个姿态角参数中每个姿态角参数,确定人脸视频模板中所有帧图像的所述每个姿态角参数的平均姿态角参数;
38.确定所述每帧图像的所述每个姿态角参数对应的偏差角,所述偏差角为所述每个姿态角参数与对应的平均姿态角参数的偏差值;
39.基于所述待处理二维人脸图像中所述每个姿态角参数和所述每帧图像中所述每个姿态角参数对应的偏差角,确定所述每帧图像对应的调整后的每个姿态角信息。
40.在一种可能的实现方式中,所述目标帧人脸图像获取单元具体被配置为执行:
41.针对所述每帧图像,根据所述待处理二维图像的面部特征参数和所述待处理二维图像的人脸形状参数进行三维模型构建,得到调整前的三维网格模型;
42.根据所述每帧图像对应的调整后的面部特征参数和所述待处理二维人脸图像的人脸形状参数进行三维模型构建,得到调整后的三维网格模型;
43.分别将所述调整前的三维网格模型和所述调整后的三维网格模型投影至同一平面,获得调整前的二维网格模型和调整后的二维网格模型;
44.将所述调整后的二维网格模型中各像素的像素值替换为所述调整前的二维网格模型中对应像素的像素值,得到所述每帧图像对应的目标帧人脸图像。
45.在一种可能的实现方式中,所述目标帧人脸图像获取单元还被配置为执行:
46.将所述调整后的二维网格模型中各像素的像素值替换为所述调整前的二维网格模型中对应像素的像素值,得到所述每帧图像对应的目标帧人脸图像的步骤之后,对所述每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;
47.基于所述每帧图像对应的二维网格模型中的口腔区域调整所述每帧图像对应的目标帧人脸图像中的口腔边缘点,并将调整后的口腔边缘点确定的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
48.在一种可能的实现方式中,所述目标帧人脸图像获取单元具体被配置为执行:
49.将所述调整后的二维网格模型中各像素的像素值替换为所述调整前的二维网格模型中对应像素的像素值,得到所述每帧图像对应的目标帧人脸图像的步骤之后,若检测出所述每帧图像中存在口腔区域未闭合的图像,则对口腔区域未闭合的每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;
50.基于所述口腔区域未闭合的每帧图像对应的二维网格模型中的口腔区域调整所述口腔区域未闭合的每帧图像对应的目标帧人脸图像中的口腔边缘点,并将调整后的口腔边缘点确定的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
51.在一种可能的实现方式中,所述目标帧人脸图像获取单元还被配置为执行:
52.根据所述每帧图像的面部特征参数分别对所述待处理二维人脸图像的面部特征参数进行调整,获得与所述每帧图像对应的调整后的所述待处理二维人脸图像的面部特征参数的步骤之前,对所述每帧图像进行关键点识别;
53.根据关键点识别结果对所述每帧图像进行三维重建,得到所述每帧图像的3dmm参数中的面部特征参数。
54.本公开第三方面,提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其中,所述处理器被配置为执行如下本公开第一方面及可能的实现方式中任意一项所述的过程。
55.本公开第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,当所述计算机指令在计算机上运行时,使得计算机执行如第一方面及一种可能的实施方式中任一所述的方法。
56.本公开的方案至少带来以下的有益效果:
57.本公开中能直接基于人脸视频模板中每帧图像的面部特征参数调整待处理二维人脸图像的面部特征参数,进而基于与人脸视频模板中每帧图像对应的调整后的待处理二维人脸图像的面部特征参数、待处理二维人脸图像的人脸形状参数以及待处理二维人脸图像的面部特征参数进行三维模型构建,得到与人脸视频模板中每帧图像对应的目标帧人脸图像,针对待处理二维人脸图像生成与人脸视频模板的面部特征信息一致的目标人脸视频,简化了根据待处理二维人脸图像生成动态的目标人脸视频的过程,且提升了生成目标人脸视频的效率。
附图说明
58.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理,并不构成对本公开的不当限定。
59.图1为本公开示例性实施例提供的一种视频生成方法的流程示意图;
60.图2为本公开示例性实施例提供的一种二维网格模型的示意图;
61.图3为本公开示例性实施例提供的一种获取人脸视频模板中每帧图像的面部特征参数的流程示意图;
62.图4为本公开示例性实施例提供的一种姿态角信息的示意图;
63.图5为本公开示例性实施例提供的一个目标帧人脸图像的调整后的口腔区域的示意图;
64.图6为本公开示例性实施例提供的一种获取人脸视频模板中任意帧图像对应的目标帧人脸图像的过程示意图;
65.图7为本公开示例性实施例提供的一种待处理二维人脸图像的示意图;
66.图8为本公开示例性实施例提供的人脸视频模板中一帧图像的示意图;
67.图9为本公开示例性实施例提供的一种目标帧人脸图像的示意图;
68.图10为本公开示例性实施例提供的一种视频生成装置的结构示意图;
69.图11为本公开示例性实施例提供的一种电子设备的结构示意图。
具体实施方式
70.为了使本领域普通人员更好地理解本公开的技术方案,下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述。
71.需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。
72.为了便于本领域技术人员更好地理解本公开的技术方案,下面对本公开涉及的技术名词进行说明。
73.巴塞尔人脸模型2009版本(base face model 2009,bfm2009):一种用于姿态和光照不变的人脸识别的三维网格模型(3d face model)。
74.三维人脸形变模型(3d morphable models,3dmm):是一个三维人脸形变模型,这个模型由一系列参数定义,这些参数分为:形状、反照、投影、身份等,通过给定一组这样的参数,生成一个三维模型,当然也可以生成二维图片;也可以使用二维图片,去预测这样一组3dmm参数,从而预测该二维图片对应的三维模型。
75.下面对本公开的设计思想进行说明。
76.相关技术中,在一些场景中需要给用户上传的二维人脸图像添加动态的表情以形成动态表情包,但在基于一个二维人脸图像生成有表情变化的人脸视频时,常由设计人员通过手动调整二维人脸图像或者使用动画制作工具制作多帧人脸表情图像,进而生成一个有表情变化的人脸视频,其过程复杂且消耗较大的人力,无法规模性生成,且生成的人脸视频的质量依赖于设计人员的技术。
77.随着技术的发展,出现使用表情驱动人物的方式,基于二维人脸图像生成人脸视频,该过程中通过三维重建技术创建一个虚拟人物,之后用表情驱动渲染该虚拟人物,但这种方案渲染出的人脸是独立于原来的二维人脸图像的一个虚拟形象,由于较重的渲染而使人脸缺乏真实感,且渲染出的人脸脱离了原始的二维人脸图像的背景,丢失了原始的二维
人脸图像的质感和纹理。
78.鉴于此,本公开设计一种视频生成方法、装置、电子设备及存储介质,用以简化根据二维人脸图像生成动态的人脸视频的过程,本公开的方法包括:基于3dmm模型获得待处理二维人脸图像的3dmm参数,该3dmm参数包括人脸形状参数和面部特征参数;并基于人脸模板视频中每帧图像的面部特征参数分别对待处理二维人脸图像的3dmm参数进行调整,获得与每帧图像对应的调整后的待处理二维人脸图像的面部特征参数,进而基于与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数、上述待处理二维人脸图像的人脸形状参数以及上述待处理二维人脸图像的面部特征参数进行三维模型构建,获得与每帧图像对应的目标帧人脸图像;并基于与每帧图像对应的目标帧人脸图像,生成待处理人脸二维图像对应的目标人脸视频。
79.其中目标帧人脸图像和人脸模板视频中对应帧图像的面部特征参数趋于一致,进而使得获得的目标帧人脸图像中的面部特征信息与人脸模板视频中对应帧图像的面部特征信息趋于一致。
80.以下结合附图对本公开的方案进行详细说明。
81.如图1所示,本公开提供一种视频生成方法,具体包括如下步骤:
82.步骤s101,对待处理二维人脸图像进行关键点识别以及三维重建,得到上述待处理二维人脸图像的三维人脸形变3dmm参数,上述3dmm参数包括人脸形状参数和面部特征信息。
83.具体地,上述关键点识别可以但不局限于使用较成熟的神经网络模型推理得到待处理二维人脸图像中人脸的第一设定数量的二维关键点,其中神经网络模型可以但不局限于包括卷积神经网络(convolutional neural networks,cnn)、循环神经网络(recurrentneuralnetworks,rnn)以及深度神经网络(deep neural networks,dnn)等;为了保证最终生成的目标人脸视频中人脸的真实度,可以但不局限于将上述第一设定数量设置为101。
84.在对待处理二维人脸图像进行关键点识别后,可以对识别出的二维关键点进行三维重建,具体地,可以但不局限于通过使用bfm2009的3dmm或bfm2017的3dmm或普通的3dmm方法进行三维重建,得到待处理二维人脸图像的3dmm参数。
85.步骤s102,针对人脸视频模板中每帧图像,根据上述每帧图像的面部特征参数分别对上述待处理二维人脸图像的面部特征参数进行调整,获得与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数;以及基于与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数、上述待处理二维人脸图像的人脸形状参数以及上述待处理二维人脸图像的面部特征参数进行三维模型构建,得到与上述每帧图像对应的目标帧人脸图像。
86.应当说明的是,对待处理二维人脸图像的面部特征参数进行调整的目的是尽量让调整后的待处理二维人脸图像的面部特征参数表征的面部特征,趋于和每帧图像的面部特征参数表征的面部特征趋向于一致,即每帧图像对应的调整后的面部特征参数表征的面部特征信息,与每帧图像的面部特征参数表征的面部特征信息趋向于一致。
87.作为一种实施例,上述面部特征信息包括人脸的表情参数和姿态角信息,可以通过如下方式,根据上述每帧图像的面部特征参数分别对上述待处理二维人脸的面部特征参
数进行调整,获得上述每帧图像对应的调整后的待处理二维人脸图像的面部特征参数:
88.基于每帧图像的姿态角信息调整上述待处理二维人脸图像的姿态角信息,得到与上述每帧图像对应的调整后的上述待处理二维人脸图像的姿态角信息;
89.分别将上述每帧图像的表情参数、与上述每帧图像对应的调整后的上述待处理二维人脸图像的姿态角信息,确定为与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参。
90.此处,将每帧图像的面部特征参数中的表情参数,作为每帧图像对应的调整后的待处理二维人脸图像的面部特征参数的一部分,即每帧图像对应修改后的待处理二维人脸图像的面部特征参数中保留了人脸视频模板中每帧图像中人脸的表情特征;基于每帧图像对应的姿态角信息调整待处理二维人脸图像对应的姿态角信息,得到与每帧图像对应的调整后的待处理二维人脸图像的姿态角信息;并将与每帧图像对应的调整后的姿态角信息,作为与每帧图像对应的调整后的待处理二维人脸图像的面部特征参数的一部分。即与每帧图像对应的调整后的面部特征参数中保留了待处理二维人脸图像中人脸根据每帧图像中人脸的姿态特征调整后的姿态特征。
91.作为一种实施例,可以通过如下方式,得到与上述每帧图像对应的目标帧人脸图像:
92.针对上述每帧图像,根据上述待处理二维图像的面部特征参数和上述待处理二维人脸图像的人脸形状参数进行三维模型构建,得到调整前的三维网格模型3dmesh_ori;
93.根据与每帧图像对应的调整后的面部特征参数和待处理二维人脸图像的人脸形状参数进行三维模型构建,得到调整后的三维网格模型3dmesh_new;
94.分别将上述调整前的三维网格模型3dmesh_ori和上述调整后的三维网格模型3dmesh_new投影至同一平面,获得调整前的二维网格模型2dmesh_ori和调整后的二维网格模型2dmesh_new;
95.将上述调整后的二维网格模型2dmesh_new中各像素的像素值替换为上述调整前的二维网格模型2dmesh_ori中对应像素的像素值,得到上述每帧图像对应的目标帧人脸图像。
96.其中二维网格模型可以看作三维网格模型在二维平面上的一个投影,请参见图2,本公开实施例还提供一种二维网格模型的示意图,该二维网格模型中包括一群离散的点和这些点围城的一个个小的三角形,其中每个小的三角形可以认为是一个像素,每个小的三角形里面的颜色可以认为是该像素的像素值。
97.调整后的二维网格模型2dmesh_new和调整前的二维网格模型2dmesh_ori都是待处理二维图形中的人脸对应的二维网格模型,只是2dmesh_new中的部分有关表情的像素相对于2dmesh_ori是改变了的,如若图2为2dmesh_ori,则2dmesh_new可能是图2中口腔区域201的像素发生了一些改变的二维网格模型;因此2dmesh_new中的像素和2dmesh_ori中的像素是存在对应关系的,可以根据这个对应关系将2dmesh_new中各像素的像素值替换为2dmesh_ori中各像素的像素值。
98.步骤s103,基于与每帧图像对应的目标帧人脸图像,获得上述待处理人脸二维图像对应的目标人脸视频。
99.具体地,可以按照人脸视频模板中每帧图像的排列顺序,将与每帧图像对应的目
标帧人脸图像排列得到待处理人脸二维图像对应的目标人脸视频。
100.作为一种实施例,在上述步骤s102中作为一种实施例,根据上述每帧图像的面部特征参数分别对上述待处理二维人脸图像的面部特征参数进行调整,获得与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数的步骤之前,还包括:
101.对上述每帧图像进行关键点识别;
102.根据关键点识别结果对上述每帧图像进行三维重建,得到上述每帧图像的3dmm参数中的面部特征参数。
103.具体地,对待处理二维人脸图像进行关键点识别以及三维重建,得到上述待处理二维人脸图像的面部特征信息。
104.具体地,上述关键点识别可以但不局限于使用较成熟的神经网络模型推理得到每帧图像的第二设定数量的二维关键点,其中神经网络模型可以但不局限于包括cnn、rnn)以及dnn等;为了保证最终生成的目标人脸视频中人脸的真实度,可以但不局限于将上述第二设定数量设置为101。
105.在对每帧图像进行关键点识别后,可以对识别出的二维关键点进行三维重建,具体地,可以但不局限于通过使用bfm2009的3dmm或bfm2017的3dmm或普通的3dmm方法进行三维重建,得到每帧图像的3dmm参数中的面部特征参数。
106.如图3所示,提供一种获取人脸视频模板中每帧图像的面部特征参数的过程,具体包括:
107.步骤s301,输入人脸视频模板,并获取上述人脸视频模板的每帧图像。
108.步骤s302,对每帧图像进行关键点识别,获得每帧图像的关键点。
109.步骤s303,通过bfm2009的3dmm对每帧图的关键点进行三维重建。
110.步骤s304,根据对每帧图的关键点进行三维重建的结果,提取每帧图像的3dmm参数中的面部特征参数。
111.在步骤s304之后,可以将提取的每帧图像的面部特征参数存储为预处理模板,以便后期对待处理二维人脸图像生成目标人脸视频时使用。
112.作为一种实施例,上述姿态角信息包括俯仰角yaw、偏航角pitch以及翻滚角roll中的至少一个姿态角参数,请参见图4,给出一种俯仰角yaw、偏航角pitch以及翻滚角roll的示意图,其中以图中人物头部的中心点为原点,原点向内图像内部为x轴、原点向图示上方为y轴,原点向图示右方为z轴建立一个三维坐标系,其中俯仰角yaw的方向为绕y轴旋转的方向,偏航角pitch的方向为绕x轴旋转的方向,翻滚角roll为绕z轴旋转的方向。
113.在上述步骤s102中可以通过如下方式,基于每帧图像的姿态角信息调整上述待处理二维人脸图像的姿态角信息,得到上述每帧图像对应的调整后的上述待处理二维人脸图像的姿态角信息:
114.针对上述至少一个姿态角参数中每个姿态角参数,确定人脸视频模板中所有帧图像的上述每个姿态角参数的平均姿态角参数;
115.确定上述每帧图像的上述每个姿态角参数对应的偏差角,上述偏差角为上述每个姿态角参数与对应的平均姿态角参数的偏差值;
116.基于上述待处理二维人脸图像中上述每个姿态角参数和上述每帧图像中上述每个姿态角参数对应的偏差角,确定上述每帧图像对应的调整后的每个姿态角信息。
117.进一步,可以通过如下公式1,基于每帧图像的面部特征参数中的俯仰角yaw调整上述待处理二维人脸图像的面部特征参数中的俯仰角yaw,得到与每帧图像对应的调整后的待处理二维人脸图像的俯仰角yaw:
118.公式1:src1.yaw=src.yaw+(dst.yaw-dst.meanyaw)
×
k1;
119.公式1中,src1.yaw为与每帧图像对应的调整后的待处理二维人脸图像的俯仰角,dst.yaw为上述每帧图像的面部特征参数中的俯仰角,dst.meanyaw为人脸视频模板中所有帧图像的面部特征参数中的俯仰角的平均值,k1为俯仰角的调整参数。
120.此处为了避免对待处理二维人脸图像的俯仰角的调整过大导致待处理二维人脸图像明显变形,以及避免对待处理二维人脸图像的俯仰角的调整过小导致待处理二维人脸图像无变化,可以但不局限于将上述k1设置为0.2或0.3。
121.进而可以通过如下公式2,基于每帧图像的面部特征参数中的偏航角pitch调整上述待处理二维人脸图像的面部特征参数中的偏航角pitch,得到上述每帧图像对应的调整后的待处理二维人脸图像的偏航角pitch:
122.公式2:src1.pitch=src.pitch+(dst.pitch-dst.meanpitch)
×
k2;
123.公式2中,src1.pitch为与每帧图像对应的调整后的待处理二维人脸图像的偏航角,dst.pitch为上述每帧图像的面部特征参数中的偏航角,dst.meanpitch为人脸视频模板中所有帧图像的面部特征参数中的偏航角的平均值,k2为偏航角的调整参数。
124.此处为了避免对待处理二维人脸图像的偏航角的调整过大导致待处理二维人脸图像明显变形,以及避免对待处理二维人脸图像的偏航角的调整过小导致待处理二维人脸图像无变化,可以但不局限于将上述k2设置为0.2或0.3。
125.进而可以通过如下公式3,基于每帧图像的面部特征参数中的翻滚角roll调整上述待处理二维人脸图像的面部特征数中的翻滚角roll,得到与每帧图像对应的调整后的待处理二维人脸图像的翻滚角roll:
126.公式3:src1.roll=src.roll+(dst.roll-dst.meanroll)
×
k3;
127.公式3中,src1.roll为与每帧图像对应的调整后的待处理二维人脸图像的翻滚角,dst.roll为上述每帧图像的面部特征参数中的翻滚角,dst.meanroll为人脸视频模板中所有帧图像的面部特征参数中的翻滚角的平均值,k3为翻滚角的调整参数。
128.此处为了避免对待处理二维人脸图像的翻滚角的调整过大导致待处理二维人脸图像明显变形,以及避免对待处理二维人脸图像的翻滚角的调整过小导致待处理二维人脸图像无变化,可以但不局限于将上述k3设置为0.1或0.2。
129.应当说明的是,对翻滚角的调整会导致人脸的扭动,翻滚角的调整参数k3过大时会导致人脸和背景扭曲过大,翻滚角的调整参数k3较小时导致无扭曲而使得人脸显得僵硬,因此翻滚角的调整参数可以但不局限于略小于俯仰角的调整参数或偏航角的调整参数。
130.作为一种实施例,在上述步骤s102中,若人脸视频模板中每帧图像中人脸的口腔区域是张开的,即人脸视频模板中的人脸是张嘴微笑的,而待处理二维人脸图像中人脸是闭嘴的话;或人脸视频模板中的人脸是闭嘴的,而待处理二维人脸图像中人脸是张嘴的话,则获取到的目标帧人脸图像中人脸的表情可能是异常的,因此将上述调整后的二维网格模型中各像素的像素值替换为上述调整前的二维网格模型中对应像素的像素值,得到上述每
帧图像对应的目标帧人脸图像的步骤之后,还可以对上述每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;基于上述每帧图像对应的二维网格模型中的口腔区域调整上述每帧图像对应的目标帧人脸图像的口腔边缘点,并将调整后的口腔边缘点围城的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
131.即针对人脸视频模板的一帧图像,若该帧图像中人脸是张嘴的,则该帧图像对应的二维网格模型中口腔区域的范围比较大,进而可以基于该帧图像对应的二维网格模型调整对应的目标帧人脸图像的口腔边缘点,使得调整后的口腔边缘点围城的口腔区域与该帧图像对应的二维网格模型中口腔区域的范围一致,进而基于预设口腔网格模板填充调整后的口腔边缘点围城的口腔区域的像素;若该帧图像中人脸是闭嘴的,则该帧图像对应的二维网格模型中口腔区域的范围比较小,基于该帧图像对应的二维网格模型调整对应的目标帧人脸图像的口腔边缘点,其中由于该镇图像中人脸是闭嘴的,调整后的口腔边缘点围城的口腔区域的范围较小,此时即便基于预设口腔网格模板填充调整后的口腔边缘点围城的口腔区域的像素,对调整后的口腔边缘点围城的口腔区域也较小。
132.考虑到进一步准确地调整目标帧人脸图像的口腔区域,本公开实施例中还可以,将上述调整后的二维网格模型中各像素的像素值替换为上述调整前的二维网格模型中对应像素的像素值,得到上述每帧图像对应的目标帧人脸图像的步骤之后,检测人脸视频模板中每帧图像的口腔区域是否闭合,若检测出上述每帧图像中存在口腔区域未闭合的图像,则对口腔区域未闭合的每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;
133.基于上述口腔区域未闭合的每帧图像对应的二维网格模型中的口腔区域调整上述口腔区域未闭合的每帧图像对应的目标帧人脸图像中的口腔边缘点,并将调整后的口腔边缘点确定的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
134.其中,针对检测出的口气区域闭合的图像,则不用按照上述方法调整与其对应的目标人脸图像的口腔边缘点。
135.为了更准确地调整目标帧人脸图像的口腔区域,本公开实施例中可以通过关键点识别检测出16个口腔边缘点,进而调整这16个口腔边缘点的位置;因为口腔闭合时牙齿因为遮挡而变暗,因此需要将调整后的口腔边缘点围城的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值之后,为了使得调整后的口腔区域与目标帧人脸图像的其他部分更好的融合,可以在调整后的口腔区域的边界使用alphablend来融合口腔边界,如图5所示,为一个目标帧人脸图像的调整后的口腔区域的示意图。
136.如图6所示,以下提供一种获取人脸视频模板中任意帧图像对应的目标帧人脸图像的过程,具体包括如下步骤:
137.步骤s601,对待处理二维人脸图像进行关键点识别以及三维重建,得到待处理二维人脸图像的人脸形状参数和面部特征参数,该面部特征参数包括表情参数和姿态角信息;
138.步骤s602,获取该任意帧图像的面部特征参数,该面部特征参数包括表情参数和姿态角信息;
139.步骤s603,基于该任意帧图像的姿态角信息调整待处理二维图像的姿态角信息,得到与该任意帧图像对应的调整后的待处理二维人脸图像姿态角信息;
140.步骤s604,将该任意帧图像的表情参数、与该任意帧图像对应的调整后的待处理二维人脸图像的姿态角信息,确定为与该任意帧图像对应的调整后的面部特征参数。
141.步骤s605,根据待处理二维图像的面部特征参数和待处理二维图像的人脸形状参数进行三维模型构建,得到调整前的三维网格模型3dmesh_ori。
142.步骤s606,根据该任意帧图像对应的调整后的待处理二维人脸图像的面部特征参数和待处理二维人脸图像的人脸形状参数进行三维模型构建,得到调整后的三维网格模型3dmesh_new。
143.步骤s607,分别将3dmesh_ori和3dmesh_new投影至同一平面,获得调整前的二维网格模型2dmesh_ori和调整后的二维网格模型2dmesh_new;并将2dmesh_new中各像素的像素值替换为2dmesh_ori中对应像素的像素值,得到该任意帧图像对应的目标帧人脸图像。
144.步骤s608,识别目标帧人脸图像的口腔边缘点;并基于该任意帧图像对应的二维网格模型中的口腔区域调整上述口腔边缘点,以及将调整后的口腔边缘点围城的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
145.请参见图7,给出一个待处理二维人脸图像的示意图,图8为人脸模板视频中某一帧图像,图9为根据上述人脸模板视频中某一帧图像的面部特征参数对待处理二维人脸图像的面部特征参数进行调整,并根据与上述某一帧图像对应的调整后的待处理二维人脸图像的面部特征参数、待处理二维人脸图像的面部特征参数以及待处理二维人脸图像的人脸形状参数获得的目标帧人脸图像的示意图。
146.本公开中基于人脸视频模板中每帧图像的姿态角信息调整待处理二维人脸图像的姿态角信息,并基于人脸视频模板中每帧图像对应的调整后的姿态角信息、人脸视频模板中每帧图像的表情参数以及待处理人脸二维图像中的人脸形状参数,获得将待处理二维人脸图像添加动态表情的目标人脸视频,一方面简化了基于待处理二维人脸图像生成动态视频的过程,另一方面为待处理二维人脸图像添加了动态表情的同时保证了得到的目标人脸视频中人脸的真实度,且保证了目标人脸视频中人脸的形状。
147.如图10所示,基于相同的发明构思,本公开实施例还提供一种视频生成装置1000,该装置包括:
148.参数获取单元1001,被配置为执行对待处理二维人脸图像进行关键点识别以及三维重建,得到上述待处理二维人脸图像的三维人脸形变3dmm参数,上述3dmm参数包括人脸形状参数和面部特征参数;
149.目标帧人脸图像获取单元1002,被配置为执行针对人脸视频模板中每帧图像,根据上述每帧图像的面部特征参数分别对上述待处理二维人脸图像的面部特征参数进行调整,获得与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数;以及基于与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数、上述待处理二维人脸图像的人脸形状参数以及上述待处理二维人脸图像的面部特征参数进行三维模型构建,得到与上述每帧图像对应的目标帧人脸图像;
150.视频生成单元1003,被配置为执行基于与上述每帧图像对应的目标帧人脸图像,获得上述待处理人脸二维图像对应的目标人脸视频。
151.可选的,上述面部特征信息包括人脸的表情参数和姿态角参数,目标帧人脸图像获取单元1002具体被配置为执行:
152.基于每帧图像的姿态角信息调整上述待处理二维人脸图像的姿态角信息,得到与上述每帧图像对应的调整后的上述待处理二维人脸图像的姿态角信息;
153.分别将上述每帧图像的表情参数、与上述每帧图像对应的调整后的上述待处理二维人脸图像的姿态角信息,确定为与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数。
154.可选的,上述姿态角信息包括俯仰角、偏航角和翻滚角中的至少一个姿态角参数,目标帧人脸图像获取单元1002具体被配置为执行:
155.针对上述至少一个姿态角参数中每个姿态角参数,确定人脸视频模板中所有帧图像的上述每个姿态角参数的平均姿态角参数;
156.确定上述每帧图像的上述每个姿态角参数对应的偏差角,上述偏差角为上述每个姿态角参数与对应的平均姿态角参数的偏差值;
157.基于上述待处理二维人脸图像中上述每个姿态角参数和上述每帧图像中上述每个姿态角参数对应的偏差角,确定上述每帧图像对应的调整后的每个姿态角信息。
158.可选的,目标帧人脸图像获取单元1002具体被配置为执行:
159.针对上述每帧图像,根据上述待处理二维图像的面部特征参数和上述待处理二维图像的人脸形状参数进行三维模型构建,得到调整前的三维网格模型;
160.根据上述每帧图像对应的调整后的面部特征参数和上述待处理二维人脸图像的人脸形状参数进行三维模型构建,得到调整后的三维网格模型;
161.分别将上述调整前的三维网格模型和上述调整后的三维网格模型投影至同一平面,获得调整前的二维网格模型和调整后的二维网格模型;
162.将上述调整后的二维网格模型中各像素的像素值替换为上述调整前的二维网格模型中对应像素的像素值,得到上述每帧图像对应的目标帧人脸图像。
163.可选的,目标帧人脸图像获取单元1002还被配置为执行:
164.将上述调整后的二维网格模型中各像素的像素值替换为上述调整前的二维网格模型中对应像素的像素值,得到上述每帧图像对应的目标帧人脸图像的步骤之后,对上述每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;
165.基于上述每帧图像对应的二维网格模型中的口腔区域调整上述每帧图像对应的目标帧人脸图像中的口腔边缘点,并将调整后的口腔边缘点确定的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
166.可选的,目标帧人脸图像获取单元1002具体被配置为执行:
167.将上述调整后的二维网格模型中各像素的像素值替换为上述调整前的二维网格模型中对应像素的像素值,得到上述每帧图像对应的目标帧人脸图像的步骤之后,若检测出上述每帧图像中存在口腔区域未闭合的图像,则对口腔区域未闭合的每帧图像对应的目标帧人脸图像进行关键点识别获得口腔边缘点;
168.基于上述口腔区域未闭合的每帧图像对应的二维网格模型中的口腔区域调整上述口腔区域未闭合的每帧图像对应的目标帧人脸图像中的口腔边缘点,并将调整后的口腔边缘点确定的口腔区域各像素的像素值替换为预设口腔网格模板中对应像素的像素值。
169.可选的,目标帧人脸图像获取单元1002还被配置为执行:
170.根据上述每帧图像的面部特征参数分别对上述待处理二维人脸图像的面部特征
参数进行调整,获得与上述每帧图像对应的调整后的上述待处理二维人脸图像的面部特征参数的步骤之前,对上述每帧图像进行关键点识别;
171.根据关键点识别结果对上述每帧图像进行三维重建,得到上述每帧图像的3dmm参数中的面部特征参数。
172.如图11所示,本公开提供一种电子设备1100,包括处理器1101、用于存储上述处理器可执行指令的存储器1102;
173.其中,上述处理器1101被配置为执行上述任意一种视频生成方法。
174.在示例性实施例中,还提供了一种包括指令的存储介质,例如包括指令的存储器,上述指令可由上述电子设备的处理器执行以完成上述方法。可选地,存储介质可以是非临时性计算机可读存储介质,例如,上述非临时性计算机可读存储介质可以是rom、随机存取存储器(ram)、cd-rom、磁带、软盘和光数据存储设备等。
175.本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本公开旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
176.应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1