一种基于标签语义相似度的短视频推荐方法与流程
【技术领域】
本发明涉及推荐系统,基于自然语言处理技术,与基于内容的短视频推荐算法结合,完成更精确与个性化的推荐技术领域,具体涉及一种基于标签语义相似度的短视频推荐方法。
背景技术:
基于内容的推荐算法是目前应用十分广泛的一种推荐方法,其基本原理是根据用户的历史行为,获得用户的兴趣偏好,为用户推荐与其兴趣偏好相似的标的物。在计算与用户兴趣偏好相似的标的物这一步中,在不同场景中则有不同的量化标准。
而在短视频的推荐场景中,由于从视频内容本身计算视频之间的相似度,难度较大且费时费力,因此通常会退一步通过计算视频标签之间的相似度来度量视频之间的相似度,但由于视频标签离散且短的属性,使用传统的方法如将词语转换为词向量再利用欧几里得距离计算相似度,这样计算出来的标签之间的相似度通常准确性不高,也仅考虑了字面上的相似度,并没有考虑标签隐含的语义信息,这就使得不能更加准确的完成个性化和多样化的推荐。目前在基于内容的短视频推荐方法中,视频标签难以准确计算相似度以及没有考虑隐含的语义信息的问题。
技术实现要素:
本发明的目的在于针对现有技术的缺陷和不足,提供一种基于标签语义相似度的短视频推荐方法。
本发明所述的一种基于标签语义相似度的短视频推荐方法,采用如下步骤:
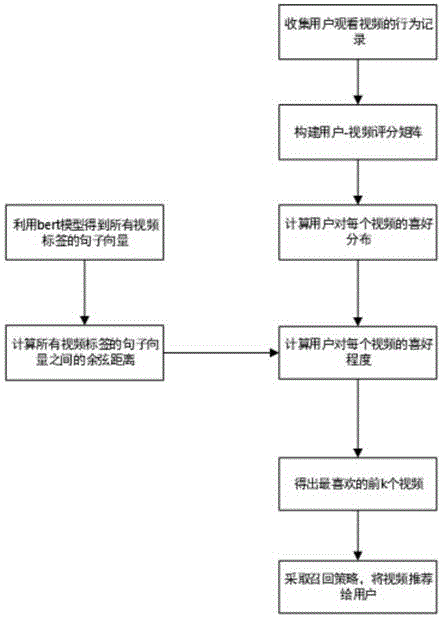
步骤一:收集用户观看视频的行为记录;
步骤二:基于步骤一中得到的交互行为记录,人为构建一系列评分规则,构建用户-视频评分矩阵u;
步骤三:对步骤二中的评分矩阵,计算用户对每个视频的喜好分布;
步骤四:根据步骤三中的用户对每个视频的喜好分布,需对每个用户对视频的喜好得分进行归一化,即将得分归一至0-1区间,作为喜好程度以便后面计算,在矩阵中即体现为列归一化;
步骤五:利用bert预训练模型,将每个视频的标签转化为句子向量,若一个视频标签由多个标签组成,则将所有标签的句子向量的平均值作为其句子向量;
步骤六:利用步骤五中的句子向量,计算所有标签向量的余弦距离得到相似矩阵v,再计算出步骤四中的用户对每个视频的喜好程度,形成喜好矩陈;
步骤七:在步骤六的基础上,根据用户对每个视频的喜好程度,计算用户得出最喜欢的前k个视频;
步骤八:根据步骤七中的最喜欢的前k个视频,再采用如回策略,将视应推荐给用户。
进一步地,步骤六中,计算所有标签向量的余弦距离得到相似矩阵v,余弦距离可以表达两个向量之间的相似程度,该值越大代表向量越相似;对于标签向量l1,l2,其余弦距离可表达如为:
进一步地,计算用户对每个视频的喜好程度,对步骤二中得到的评分矩阵u,评分矩阵u中的每一列代表一个用户的评分,步骤六中得到的相似矩阵v,喜好矩阵可按下式计算:
s=utv,得到的s的每一行即为用户对所有视频的喜好程度。
进一步地,基于矩阵s,得到每个用户最喜好的k个视频,采取召回策略,并将视频推给用户。
进一步地,对步骤七中得到的k个最相似视频,可存在视频过多或与实际用户特征不符合的视频,采取召回策略过滤及重排序视频,再将重先过滤排序后的视频推给用户。
本发明有益效果为:本发明所述的一种基于标签语义相似度的短视频推荐方法,它使用bert预训练模型将每个视频的标签表征为句子特征向量,再利用余弦距离计算向量之间的相似度从而得到视频标签的相似度,有利于相似视频的推荐,还可以实时且不受限制的加入新标签,不需要过多的人为干预,很适用于快速构建一个推荐系统。
【附图说明】
此处所说明的附图是用来提供对本发明的进一步理解,构成本申请的一部分,但并不构成对本发明的不当限定,在附图中:
图1是本发明结构示意图;
图2是本发明中的bert模型结构图。
【具体实施方式】
下面将结合附图以及具体实施例来详细说明本发明,其中的示意性实施例以及说明仅用来解释本发明,但并不作为对本发明的限定。
如图1-图2所示,本具体实施方式所述的一种基于标签语义相似度的短视频推荐方法,采用如下步骤:
步骤一:收集用户观看视频的行为记录;
通过记录用户对视频的观看时长,对视频是否点赞,是否评论等交互指标,基于此来衡量用户对观看视频的喜好程度。
步骤二:基于步骤一中得到的交互行为记录,人为构建一系列评分规则,构建用户-视频评分矩阵u;
基于步骤一中得到的交互行为记录,人为构建一系列评分规则,如看完该视频计2分,点赞视频计3分等,将多种交互行为的得分相加,就可以得到用户对视频的喜好得分,评分越高代表用户对该视频的喜好程度越高。
步骤三:对步骤二中的评分矩阵,计算用户对每个视频的喜好分布;
步骤四:根据步骤三中的用户对每个视频的喜好分布,需对每个用户对视频的喜好得分进行归一化,即将得分归一至0-1区间,作为喜好程度以便后面计算,在矩阵中即体现为列归一化;
步骤五:利用bert预训练模型,将每个视频的标签转化为句子向量,若一个视频标签由多个标签组成,则将所有标签的句子向量的平均值作为其句子向量;
步骤六:利用步骤五中的句子向量,计算所有标签向量的余弦距离得到相似矩阵v,再计算出步骤四中的用户对每个视频的喜好程度,形成喜好矩陈;
步骤七:在步骤六的基础上,根据用户对每个视频的喜好程度,计算用户得出最喜欢的前k个视频;
步骤八:根据步骤七中的最喜欢的前k个视频,再采用如回策略,将视应推荐给用户。
进一步地,步骤六中,计算所有标签向量的余弦距离得到相似矩阵v,余弦距离可以表达两个向量之间的相似程度,该值越大代表向量越相似;对于标签向量l1,l2,其余弦距离可表达如为:
进一步地,计算用户对每个视频的喜好程度,对步骤二中得到的评分矩阵u,评分矩阵u中的每一列代表一个用户的评分,步骤六中得到的相似矩阵v,喜好矩阵可按下式计算:
s=utv,得到的s的每一行即为用户对所有视频的喜好程度。
进一步地,基于矩阵s,得到每个用户最喜好的k个视频,采取召回策略,并将视频推给用户;
进一步地,对步骤七中得到的k个最相似视频,可存在视频过多或与实际用户特征不符合的视频,采取召回策略过滤及重排序视频,再将重先过滤排序后的视频推给用户。
本发明中,使用bert预训练模型将每个视频的标签表征为句子特征向量,若一个视频标签由多个标签组成,则将这多个标签的句子特征向量相加取平均作为最后的句子特征向量,再利用余弦距离计算向量之间的相似度从而得到视频标签的相似度。
例如在美食类视频的标签库中,与火锅视频相似的标签有焖锅、烧烤、串串等,可以看出这样计算出来的相似度,包含了标签隐含的信息,即相似标签的食物的口味及风格是相似的,存在着语境上的共性,这样不仅有利于相似视频的推荐,还可以实时且不受限制的加入新标签,不需要过多的人为干预,很适用于快速构建一个推荐系统。
以上所述仅是本发明的较佳实施方式,故凡依本发明专利申请范围所述的构造、特征及原理所做的等效变化或修饰,均包括于本发明专利申请范围内。
- 还没有人留言评论。精彩留言会获得点赞!