一种基于复杂网络的金融市场预测方法与流程
本发明涉及金融和计算机交叉研究技术领域,特别是涉及一种基于复杂网络的金融市场预测方法。
背景技术:
股市等金融市场是经济的晴雨表,金融市场将如何波动、公司表现如何,是经济管理部门、金融机构、企业和投资者都十分关心的问题,如何对金融市场表现进行有效预测在商业界和学术界都受到了广泛的关注。
现有的分析预测手段对上市公司之间的关联考虑得不够,在预测一个公司的金融指标的时候,只是孤立地考虑待预测公司的信息,没有考虑公司之间的相互影响。
技术实现要素:
本发明为了克服现有的分析预测手段对上市公司之间的关联考虑得不够,在预测一个公司的金融指标的时候,只是孤立地考虑待预测公司的信息,没有考虑公司之间的相互影响的缺点,本发明要解决的技术问题是提供一种基于复杂网络的金融市场预测方法,如何表示上市公司之间以及上市公司与版块、概念之间的关联,并利用这些信息来进行上市公司的金融指标预测。
为了解决上述技术问题,本发明提供了这样一种基于复杂网络的金融市场预测方法,该基于复杂网络的金融市场预测方法的具体步骤如下:
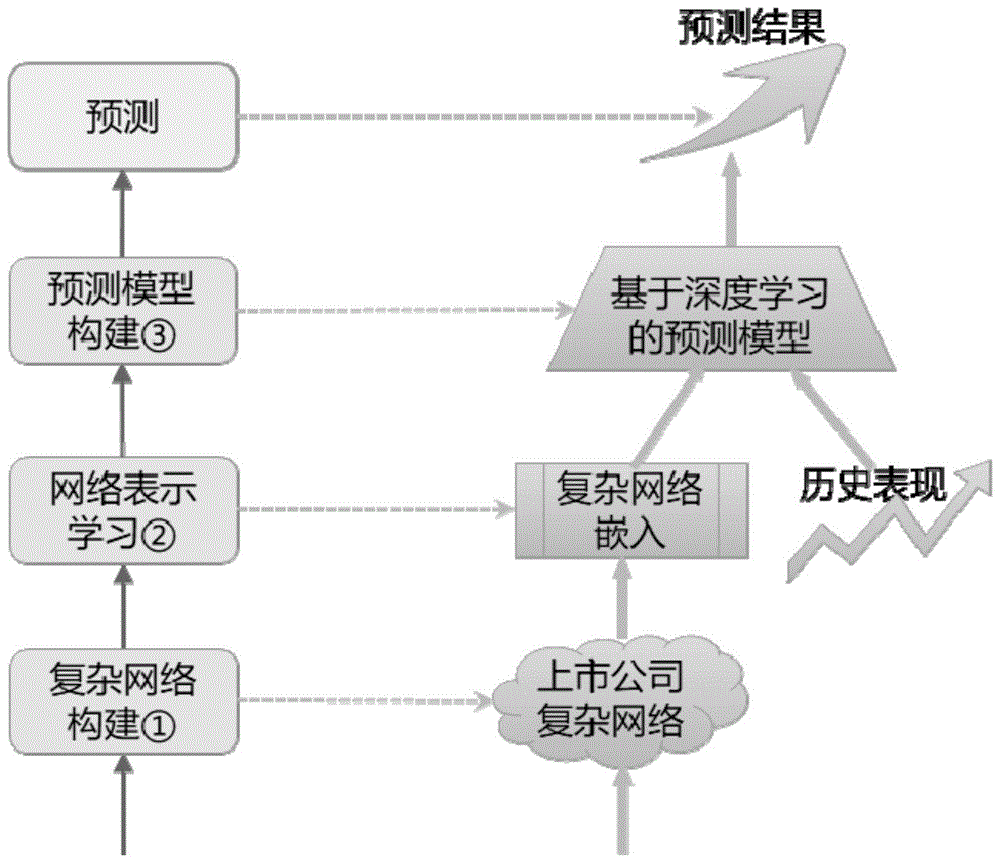
s1:构建上市公司复杂网络,所述上市公司复杂网络用于描述上市公司之间的关系;
s2:基于上市公司复杂网络进行分布式表示学习,得到节点的嵌入;
s3:构建深度学习模型,对上市公司的主要金融指标进行预测,其步骤如下:
1)、构建相关公司集合rel(o);
2)、计算所述相关公司集合rel(o)的嵌入,从上市公司复杂网络中提取rel(o)中的节点及其联系,得到一个子图grel(o),以图中每个节点的嵌入作为输入,运行图卷积神经网络算法,得到整个子图的嵌入,即rel(o)的嵌入;
3)、构建预测模型,所述模型的输入包括相关公司集合和相关公司的历史表现,采用lstm模型来根据所述相关公司的历史表现生成向量表示,把该向量作为模型的具体输入。
优选地,所述步骤s1中,所述上市公司复杂网络的构建包括上市公司实体抽取和上市公司关系抽取,所述上市公司实体抽取为从互联网上抓取国内上市公司的股票代码和股票名称信息,所述上市公司关系抽取根据上市公司的股价分为三类上市公司关系,分别为追随关系、背离关系和共现关系。
优选地,所述步骤s2包括:
将一个所述上市公司复杂网络表示为:g=(vs,vt,ess,est),其中vs是所有所述上市公司节点集合,vt是所有所述主题节点集合,ess是所述上市公司节点之间的边,est是所述主题节点与所述上市公司节点之间的边,所述嵌入的学习采用深度学习方法,总的损失函数定义为:
其中,
定义
其中p(u,v;θ)使用logistic函数计算:
类似地,定义
其中p(u,v;θ)使用logistic函数计算,
α用于控制结构损失和主题损失的比重。
优选地,步骤s3中步骤1)包括:
给定一个公司o和参数k,找出与公司o相关联的公司中关联度最强的k个公司,作为o的相关公司集合rel(o),以o为根,构造最小生成树,取该树靠近根部的k个节点构成rel(o)。
有益效果
本发明为金融市场预测提供了新的思路,有助于更深刻地理解金融市场波动的机理,不仅可以推动金融市场预测的研究,也可以促进复杂网络和深度学习等技术的发展,同时也可以用于对上市公司或者金融市场进行监测和预警,对于经济管理部门、金融机构、企业和投资者有重要的参考价值,在经济和金融预测等领域有重要的应用价值,可以显著提升上市公司金融指标预测的准确性,从而可以更准确地判断上市公司未来在金融市场上的表现,也可以更好地做出投资和管理决策。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中基于复杂网络的金融市场预测方法的研究思路流程示意图;
图2为本发明中基于复杂网络的金融市场预测方法的预测模型结构示意图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的说明。
实施例1
一种基于复杂网络的金融市场预测方法,如图1-2所示,该基于复杂网络的金融市场预测方法的具体步骤如下:
s1:构建上市公司复杂网络,所述上市公司复杂网络用于描述上市公司之间的关系;
所述上市公司复杂网络corpnet(corporationnetwork)是一个图结构,所述上市公司复杂网络存在上市公司节点和主题节点,每个所述上市公司节点表示一个上市公司,对应一只股票,每个所述主题节点表示表示一个主题,所述一个主题可以表示一个板块、行业或者概念,如银行板块、5g等;
所述上市公司复杂网络存在两种类型的边,一种是上市公司节点之间的边,另一种是主题节点与所述上市公司节点之间的边,所述上市公司节点之间的边表示两个所述上市公司之间的关系,所述主题节点与所述上市公司节点之间的边表示一个上市公司属于或者具有一个主题;
所述上市公司复杂网络的构建包括上市公司实体抽取和上市公司关系抽取;
所述上市公司实体抽取为从互联网上抓取国内上市公司的股票代码和股票名称以及上市公司的其他信息,所述上市公司实体抽取需要在一个实际的文本中识别出一个上市公司实体的出现,所述上市公司实体的描述存在两类问题:
(1):实体描述与实体名称不相符,却指向该实体。如“上半年中行发放贷款有较大幅度增长”这里“中行”指的是上市公司“中国银行”;
(2)实体描述与实体名称匹配,但是并非指向该实体。例如“中国移动通信产业经历了飞跃式发展”这里虽然提到了“中国移动”,但并非指任何一个上市公司;
针对上述问题,解决方法如下:
首先,搜集语料信息,构建上市公司以及股票名称同义词、近义词库;
其次,基于大规模语料库学习上市公司及股票名称的词嵌入,称为实体嵌入,使得该嵌入中包含丰富的实体上下文信息;
最后,在一个具体的文档中,根据词法形式和同义词、近义词库找出疑似匹配的实体,然后将训练得到的实体嵌入与疑似实体的上下文词嵌入进行比较,如果相似性大于阈值,则认为文档所指为当前实体;
所述上市公司关系抽取根据上市公司的股价分为三类上市公司关系,分别为追随关系、背离关系和共现关系,所述背离关系是指一只股票的表现发生变动时,另一只股票经常随着该股票发生同方向变化,所述背离关系是指一只股票的表现发生变换时,另一只股票的表现经常发生逆向变化,所述共现关系是指两个股票经常在一个上下文中同时提到;
其中,所述追随关系反映了两个上市公司之间存在共生共荣关系,如处于一个供应链上;所述背离关系反映了两个上市公司之间的竞争关系;而所述共现关系的内涵有可能是追随关系,也有可能是背离关系,还可能是其他关系,因此我们要求两个公司之间的追随或者背离与共现关系不能同时出现,以免重复表达,进一步地,对三类关系进行识别:
共现关系的识别:共现关系的识别比较简单,基于上市公司实体识别结果,在一个单位的上下文中,如果两个股票实体同时出现,则它们之间存在共现关系;
追随和背离关系的识别:将一个股票的市场表现抽象为一个变动序列,其中每个元素从{up,down,flat}中取值,分别表示上涨、下跌和平稳,其中平稳是指价格变动在一个预定义的范围内,给定两个股票序列,可以计算它们的相关性,如果高度正相关,则认为两个股票存在追随关系;如果高度负相关,则认为两个股票存在背离关系;为了减少计算量,拟采取“过滤—求精”框架,即先从每个序列抽取一些关键特征,根据这些特征将所有的序列分为若干个组,然后在组内进行比较。
s2:基于上市公司复杂网络进行分布式表示学习,得到节点的嵌入(embedding);
上市公司网络中包含了大量信息,它们在学习和预测中有重要作用,为了有效地利用上市公司网络中的信息,需要将其向量化。本项目基于表示学习技术,学习上市公司网络的嵌入(embeddings),使得嵌入表示中尽可能反映上市公司之间的各种关系;
将一个所述上市公司复杂网络表示为:g=(vs,vt,ess,est),其中vs是所有所述上市公司节点集合,vt是所有所述主题节点集合,ess是所述上市公司节点之间的边,est是所述主题节点与所述上市公司节点之间的边,所述嵌入的学习采用深度学习方法,总的损失函数定义为:
其中,
定义
其中p(u,v;θ)使用logistic函数计算:
类似地,定义
其中p(u,v;θ)使用logistic函数计算,
针对主题嵌入的产生,将每个主题节点用一个关键词集合表示,构造一个种子词集合,初始时包括主题词本身,然后考察一个主题下的每个节点的核心题材描述中的关键词,根据词嵌入找出与种子词相似的关键词,将这些关键词加入到种子词集合中,如此迭代,产生一个主题节点的关键词集合。然后产生一个主题的嵌入,考虑两种方式产生主题嵌入,一是用主题的关键词集合的词嵌入的平均作为主题的嵌入,二是利用lstm模型,以关键词集合的词嵌入为输入,模型的输出为主题的嵌入,整个网络的结构部分的损失函数和主题相关部分的损失函数为:
总的损失函数是结构和主题损失函数的结合,其中,α可以控制结构损失和主题损失的比重,默认取0.5,即在嵌入中包含相同比重的结构信息和主题信息;
训练过程中考虑使用sgd、adam等来优化。通过这种方式,不是分开来训练节点的结构嵌入和主题嵌入,而是联合训练,从而使得不同节点的嵌入有可比性,并预期可以取得更好的结果。
s3:构建深度学习模型,对上市公司的主要金融指标进行预测,其步骤如下:
1)、构建相关公司集合,由于一个公司的金融指标会受到其他公司的影响,因此在预测一个公司的金融指标的时候,首先找出对其影响最大的公司集合,给定一个公司o和参数k,找出与公司o相关联的公司中关联度最强的k个公司,作为o的相关公司集合rel(o),以o为根,构造最小生成树,取该树靠近根部的k个节点构成rel(o);
2)、计算所述相关公司集合rel(o)的嵌入,从上市公司复杂网络中提取rel(o)中的节点及其联系,得到一个子图grel(o),以图中每个节点的嵌入作为输入,运行图卷积神经网络算法,得到整个子图的嵌入,即rel(o)的嵌入;
3)、构建预测模型,所述模型的输入包括相关公司集合和相关公司的历史表现,所述相关公司的历史表现是指公司的股票、市值等金融指标的历史表现,取一个公司在某一时间段窗口内的金融指标作为该公司的历史表现,采用lstm模型来根据所述相关公司的历史表现生成一个向量表示,把该向量作为模型的具体输入,本方法不仅仅考虑待预测公司一个公司,而是考虑了与之关联最强的k个公司,将这k个公司的信息作为输入的一部分,因此,在预测的时候也以k个公司的预测结果作为模型的输出,也就是说,模型并不是预测一个公司的表现,而是一个集合的表现;
预测模型的总体结构如图2所示:模型的下半部分处理输入信息,将相关公司集合的嵌入和历史表现向量合并,然后通过一个自编码器产生一个融合了多方面信息的融合向量;模型的上半部分以该融合向量为输入,经过一个带注意力机制的多层卷积神经网络产生整个相关公司集合的预测结果,其中包括了待预测公司的预测结果。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!