一种融合图像和声音信息的视频标注方法与流程
本发明涉及一种融合图像和声音信息的视频标注方法,属于深度学习、数字图像处理技术领域。
背景技术:
视频标注(videocaption),即将视频内容自动地翻译成完整自然的句子,在检索视频信息、人机交互、辅助视觉障碍人士等方面有着重要的作用。以往对视频标注的研究大多采用深度学习的思想:利用训练集“训练”一个神经网络模型并用测试集检测模型的准确率。然而,传统的视频标注方法人为地割裂了视频的图像信息与音频信息的联系:仅仅使用了图像信息而忽略了音频信息,这很可能成为限制视频标注准确率的重要原因。
技术实现要素:
以解决现有视频标注忽略视频声音信息的问题,本发明提供一种基于s2vt(sequencetosequence:videototext)模型的融合图像和声音信息的视频标注方法,大大提高生成语句的自然程度。
技术方案:一种融合图像和声音信息的视频标注方法,包括以下步骤:
步骤1:采用msr-vtt数据集作为所需建立的神经网络模型的训练集和测试集,对所述训练集和测试集进行预处理,得到保存有视频信息的npy文件和用向量表征文字内容的文字标注库,所述视频信息包括图像信息与音频信息;采用通过预处理训练集得到的npy文件和文字标注库作为所需建立的神经网络模型的训练集,采用通过预处理测试集得到的npy文件作为测试神经网络模型准确率的测试集;
步骤2:以保存有视频信息的npy文件作为输入,以表征文字内容的向量为输出,搭建s2vt模型并初始化其内部参数;
步骤3:将文字标注库中的向量加载至神经网络模型中,利用反向传递修改神经网络模型的内部参数;
步骤4:循环执行步骤3,直至训练集中的所有视频都加载完毕,得到训练后的神经网络模型;
步骤5:采用测试集对训练后的神经网络模型进行准确率检测,得到可使用的神经网络模型;
步骤6:对需进行标注的视频进行预处理,得到保存有视频信息的npy文件,将该npy文件输入至可使用的神经网络模型中,得到一个向量,基于文字标注库,将该向量翻译为自然语言,得到视频标注内容。
进一步的,在步骤1中,所述的预处理包括以下子步骤:
s11:将训练集中的每个视频分离为图像部分和音频部分;
s12:对图像部分进行以下操作:
对图像部分每隔设定时间取一帧,形成帧集;
对帧集中的图像进行图像特征提取,得到保存有视频图像信息的npy文件;
s13:对音频部分进行以下操作:
对音频部分每隔设定时间进行取样,形成音频样本集;
对音频样本集中的音频进行特征提取,得到保存有视频音频信息的npy文件;
s14:将s12和s13得到的npy文件进行横向拼接,得到保存有视频信息的npy文件;
s15:将训练集中的文字标注部分进行以下操作:
将文字标注部分的每一条描述语句中的每个单词进行编号,形成初步描述语句库;
将初步描述语句库中使用频率低的单词及其对应的编号进行剔除,形成描述语句库;
将描述语句库中的所有描述语句转换为向量,得到文字标注库。
进一步的,所述神经网络模型采用s2vt模型。
进一步的,在s12中,采用ffmpeg软件对图像部分每隔设定时间取一帧,形成帧集。
进一步的,在s13中,采用ffmpeg软件对音频部分每隔设定时间进行取样,形成音频样本集。
进一步的,在s13中,采用mfcc方法对音频样本集中的音频进行特征提取。
有益效果:本发明在使用图像信息的同时,加入视频的音频部分,即将视频的图像和音频进行神经网络的训练,大大提升视频标准的准确率。
附图说明
图1为本发明的步骤2的图示;
图2为本发明的步骤3的图示;
图3为本发明的步骤4的图示;
图4为本发明的横向拼接的图示;
图5为实施例中用于进行视频标注的原视频。
具体实施方式
现结合附图和实施例进一步阐述本发明的技术方案。
本实施例的一种融合图像和声音信息的视频标注方法,包括以下步骤:
步骤1:获得msr-vtt(microsoftresearch-videototext)数据集,作为训练集和测试集;
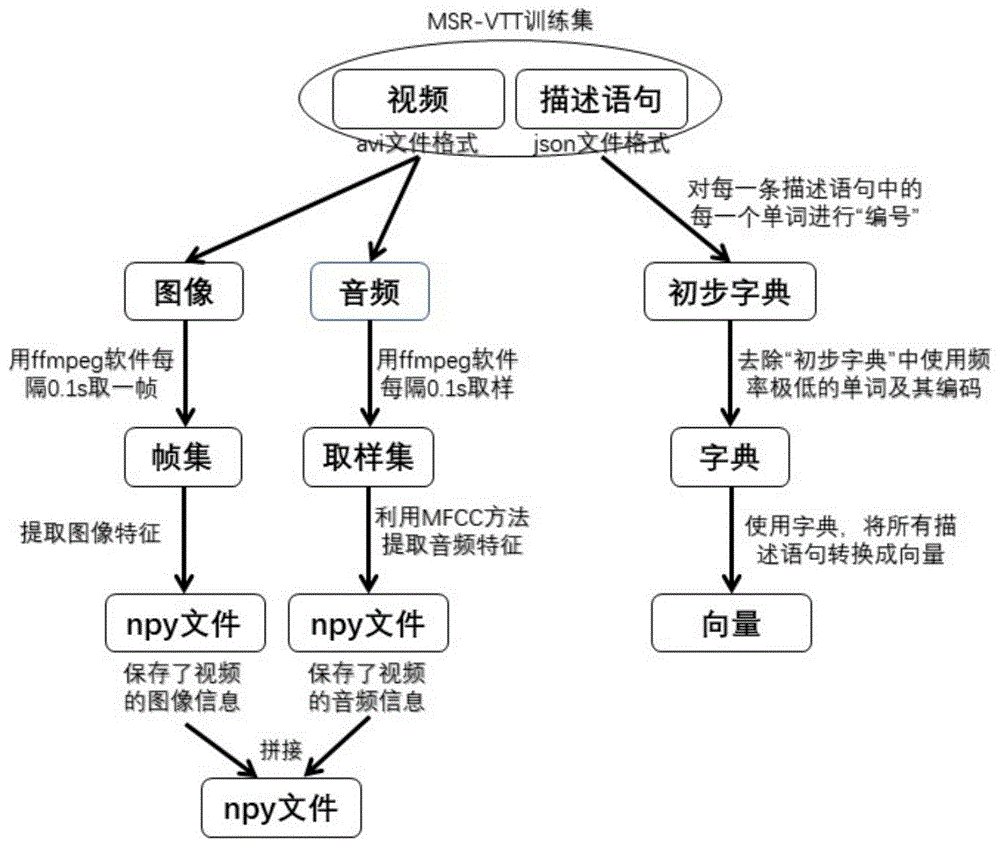
步骤2:对msr-vtt数据集进行预处理,可参见图1,在本实施例中,该预处理具体包括以下子步骤:
(2.1)将msr-vtt的训练集中的每一个视频都分离为图像部分和音频部分;
(2.2)对2.1中的每一个视频的图像部分进行以下操作:使用ffmpeg软件每隔0.1s取一帧,形成帧集,再通过卷积神经网络提取图像特征,得到保存一个视频的图像信息的npy文件;
(2.3)对2.1中的每一个视频的音频部分进行以下操作:使用ffmpeg软件每隔0.1s进行取样,再用mfcc(melfrequencycepstralcoefficients)方法提取音频特征,得到保存一个视频的音频信息的npy文件;
(2.4)将2.2与2.3的两个npy文件进行“横向拼接”,得到保存一个视频的信息(包括图像信息与音频信息)的npy文件,,具体可参见图4;
(2.5)对训练集中的文字标注部分进行以下操作:对每一条描述语句中的每一个单词进行“编号”,形成“初步字典”,之后去除“初步字典”中使用频率极低的单词及其编号,形成“字典”。再使用“字典”,将所有描述语句转换为向量。
步骤3:可参见图2,训练神经网络:
(3.1)搭建s2vt模型并初始化其内部参数;
(3.2)将2.4中的保存视频信息的npy文件作为模型的输入,将2.5中的向量作为模型的输出加载到s2vt模型中,利用反向传递修改s2vt模型内部的参数,直至训练集中的所有视频都加载完;
步骤4:可参见图3,测试:
(4.1)对msr-vtt数据集中的测试集(仅含视频,不含文字)进行与2.1、2.2、2.3、2.4部分相同的预处理步骤,得到保存测试集视频信息的npy文件;
(4.2)将4.1的npy文件加载到训练好的s2vt模型中,得到一个向量;
(4.3)“查询”“字典”,将向量“翻译”为自然语言;
步骤5:用多种评测方法(包括bleu、meteor、rouge_l、cider)评价测试效果;对比无声音训练结果,发现对输出语句流畅性和连贯性要求较高的bleu_4的准确率得到了提升,这表明本实施例加入声音训练是有效的。此外,在对单一视频进行测试时,加入声音所得的模型对于有声音的视频的输出有了大幅的改善。
采用训练好的s2vt模型对图5所示的视频进行视频标注,其得到的生成的描述语句为:
“image_id”:“video11212”;
“caption”:“agroupofpeopleareplayingbadminton”。
- 还没有人留言评论。精彩留言会获得点赞!