一种难样本重训练的深度神经网络声呐目标检测方法与流程
本发明属于目标检测领域中的声呐目标检测问题,具体涉及一种难样本重训练的深度神经网络声呐目标检测方法。
背景技术:
海洋一直是各国关注的重点。随着政治形势复杂化,合理开发海洋资源,保护领海安全显得尤为重要。在这样的背景下,如何提高声呐目标检测精度成为学术界的重要研究方向。
现有的声呐目标检测方法大致可以分为基于统计分析学的目标检测方法、基于传统机器学习的目标检测方法和基于深度神经网络的目标检测方法三大类。由于海洋物体繁多,环境复杂,导致基于统计分析学的目标检测方法存在诸多问题,精度瓶颈无法得到解决。仅仅使用传统方法是不够的,仍需在声呐目标检测领域探索新方法。
伴随人工智能在图像识别领域不断取得重大突破,越来越多的人工智能模型被用于声呐目标检测。基于传统机器学习的方法一般需要研究人员手动提取声呐图像特征,而手工方法存在诸如不能确保提取到目标的深层特征、识别精度对特征依赖性较大等不足,导致此类方法在复杂水体环境的声呐图像目标检测任务中效果表现欠佳。基于深度学习的目标检测方法通过对训练数据实现样本特征的自动学习,避免了手动提取特征的缺点,灵活性与检测精度均得到很大提升。
近年来,各类应用在声呐目标检测领域的深度学习网络取得了良好的效果。但与自然图像不同,因海底环境干扰较大,导致声呐图片具有典型的信噪比低、成像质量差等特点。本发明基于一种高效的深度神经网络模型fasterrcnn(使用区域建议网络产生建议窗口的区域卷积神经网络)并进行改进,即网络训练过程中通过计算输入样本的损失值并筛选出难检测样本并返回进行重新训练,使训练效果进一步提升,更适用于声呐目标检测领域。
技术实现要素:
本发明的目的在于提供一种难样本重训练深度神经网络的声呐目标检测方法。
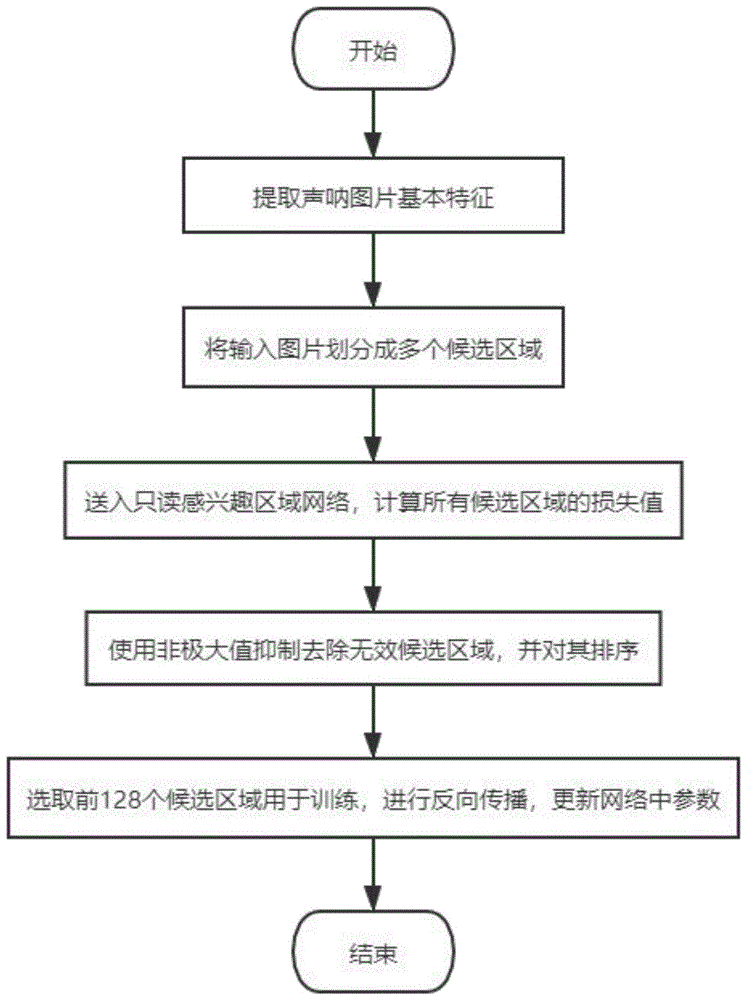
本发明的具体步骤如下:
步骤1、声呐数据的获取和处理。
1-1.获取三维声呐数据,生成声呐图像。
1-2.对声呐图像进行目标标记并制作声呐数据文件。
步骤2、利用标记后声呐数据训练深度神经网络。
2-1.将fasterrcnn网络中扩充出两个感兴趣区域网络,并使这两个感兴趣区域网络共享参数。其中一个感兴趣区域网络进行前向传播;另一感兴趣区域网络进行参数迭代,接收筛选出的难样本并回传参数,从而得到难样本重训练深度神经网络。
2-2.在难样本重训练深度神经网络上训练声呐数据。
将声呐图像和声呐数据文件输入难样本重训练深度神经网络。难样本重训练深度神经网络对声呐图像进行特征提取;使用难样本重训练深度神经网络内的区域建议网络在声呐图像上框选出多个候选区域,并分别计算各候选区域含有目标的预测概率pi以及预测边框偏移量ti。
将所有的候选区域分别送入进行前向传播的感兴趣区域网络计算损失值l({pi},{ti})如式(1)所示。
式(1)中,lcls(pi,pi*)、lreg(ti,ti*)分别表示第i个候选区域的分类损失和回归损失;ncls为分类损失对应的归一化系数;nreg为回归损失对应的归一化系数;λ为权重系数。
分类损失lcls(pi,pi*)的表达式如式(2)所示。
lcls(pi,pi*)=-log[pipi*+(1-pi*)(1-pi)]式(2)
式(2)中,pi表示区域建议网络对第i个候选区域是否含有目标的预测概率。pi*表示第i个候选区域的类标签。
回归损失lreg(ti,ti*)的表达式如式(3)所示。
式(3)中,ti为区域建议网络对第i个候选区域的预测边框偏移量;ti*为人工标记边框偏移量。
2-3.根据各个候选区域的损失值l({pi},{ti}),通过非极大值抑制法剔除多余的候选区域,初步筛选出m个优选候选区域,m>128;在m个优选候选区域按照损失值从大到小进行排序,取损失值较大的前128个优选候选区域作为难样本区域。
2-4.将所选取的难样本区域送入用于参数迭代的感兴趣区域网络进行迭代学习,完成难样本重训练深度神经网络的训练。
步骤3、将被测声呐图像输入难样本重训练深度神经网络,进行目标的识别和框选,得到目标的位置。
作为优选,步骤1-1与1-2之间执行以下操作:依据声呐数据协议将声呐目标嵌入三维声呐数据,合成了含有目标的声呐图像。
作为优选,步骤2-2中,若第i个候选区域与声呐数据文件内最接近的目标标记的重合度大于或等于0.7时标签为正,则第i个候选区域的类标签pi*为1;否则第i个候选区域的类标签pi*为0。
作为优选,步骤2-3中,非极大值抑制法的具体过程如下:
①.对各候选区域损失值按照从大到小排序;
②.从损失值最大候选区域开始,判断与其余候选区域的重叠度是否高于预设的阈值;若两个候选区域的重叠度高于阈值,则将这两个候选区域中损失值较小的那个候选区域抛弃。
③.重复步骤①和②,直至所有候选区域均被保留。
本发明具有的有益效果是,
1、本发明通过对检测精度影响较大的难样本的发掘与重训练,提高了训练数据的利用率。在不增加样本数量的同时提升了模型精度,这对于样本获取困难的声呐目标检测领域具有重大意义。
2、本发明解决了数据不平衡问题。若某类别数量较少时,往往该类别的损失较大,更容易被筛选为难样本。通过此方法无需对数据不平衡类别进行人为处理,降低了声呐数据处理的难度。
附图说明
图1为本发明的总流程示意图。
图2a与2d、2b与2e、2c与2f分别为三组现有fasterrcnn模型与本发明在难样本声呐图像上的目标检测结果对比图。
具体实施方式
下面结合附图对本发明的较佳实施案例进行详细阐述,以使得本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
本发明的实施方式包括如下步骤:
步骤1、声呐数据的获取和处理。
1-1.通过实际海上作业获取三维声呐数据,并使用matlab软件依据声呐数据协议解析,将其保存为图片。
1-2.因声呐样本有限,将步骤1-1中保存得到的图片中有大量无目标的背景图像。本发明利用此类图像依据声呐数据协议将声呐目标嵌入其中,合成了含有目标的声呐图像。
1-3.对步骤1-2处理之后的声呐图像按标准的目标检测数据集格式进行标记并制作相应的xml格式的声呐数据文件。声呐数据文件中含有声呐图像内各个目标的框选位置。
步骤2、利用标记后声呐数据训练深度神经网络。
2-1.本发明基于深度学习框架caffe(convolutionalarchitectureforfastfeatureembedding,一个主要应用于视频与图像处理的深度学习框架)的fasterrcnn网络进行改进。fasterrcnn网络基于vgg16(verydeepconvolutionalnetworksforlarge-scaleimagerecognition,用于大规模图像识别的深层卷积神经网络)
首先对caffe框架进行编译、调试。然后在fasterrcnn中加入难样本重训练的方法,其具体步骤为:将fasterrcnn网络中的一个感兴趣区域网络(即roi网络,regionofinterest)扩充为两个感兴趣区域网络,并使这两个感兴趣区域网络共享参数。其中一个感兴趣区域网络只进行前向传播(即图1中的只读感兴趣区域网络),用于计算样本的损失值并送入筛选难样本网络层;另一感兴趣区域网络进行参数迭代和梯度更新,用于接收筛选出的难样本并回传参数。fasterrcnn网络扩充后即为所需的难样本重训练深度神经网络。
2-2.在修改后的难样本重训练深度神经网络上训练声呐数据。
将步骤1-2所得的声呐图像和步骤1-3得到的声呐数据文件输入步骤2-1修改后的难样本重训练深度神经网络。难样本重训练深度神经网络对声呐图像进行特征提取;并使用难样本重训练深度神经网络内的区域建议网络在声呐图像上框选出多个存在相交的候选区域,并分别计算各候选区域是否含有目标的预测概率pi以及预测边框偏移量ti。
将所有的候选区域分别送入进行前向传播的感兴趣区域网络计算损失值l({pi},{ti}),目标函数如式(1)所示。
式(1)中,i为候选区域索引(即序号);lcls(pi,pi*)与lreg(ti,ti*)分别表示第i个候选区域的分类损失和回归损失;ncls为分类损失对应的归一化系数;nreg为回归损失对应的归一化系数;λ为权重系数,用于使归一化之后的分类损失和回归损失的权重趋近相同。
分类损失lcls(pi,pi*)用于区分候选区域是目标或背景,目标函数如式(2)所示。
lcls(pi,pi*)=-log[pipi*+(1-pi*)(1-pi)]式(2)
式(2)中,pi表示区域建议网络对第i个候选区域是否含有目标的预测概率。pi*表示第i个候选区域的类标签,若第i个候选区域与声呐数据文件内最接近的目标标记的重合度大于或等于0.7时标签为正,则第i个候选区域的类标签pi*为1;否则第i个候选区域的类标签pi*为0。
回归损失lreg(ti,ti*)用于微调候选区域的位置,目标函数如式(3)所示。
式(3)中,ti为区域建议网络对第i个候选区域的预测边框偏移量;ti*为人工标记边框偏移量,即声呐数据文件内记录的最靠近第i个候选区域的目标标记与第i个候选区域的中心距。
2-3.根据各个候选区域的损失值l({pi},{ti}),通过非极大值抑制法剔除多余的候选区域,初步筛选出m个优选候选区域,m>128;在m个优选候选区域按照损失值从大到小进行排序,取损失值较大的前128个优选候选区域作为难样本区域。精选出的128个难样本区域能够避免多个框选中同一目标,造成大量重叠的情况。
非极大值抑制法的具体过程如下:
①.对各候选区域损失值按照从大到小排序;
②.从损失值最大候选区域开始,判断与其余候选区域的重叠度是否高于预设的阈值;若两个候选区域的重叠度高于阈值,则将这两个候选区域中损失值较小的那个候选区域抛弃。
③.重复步骤①和②,直至所有候选区域均被保留。
2-4.将所选取的难样本区域送入用于参数迭代的感兴趣区域网络进行迭代学习,并调试超参数,完成难样本重训练深度神经网络的训练,达到最优识别效果,并得到特征权重值。。
步骤3、利用步骤2训练好的难样本重训练深度神经网络进行声呐目标检测。
3-1.用声呐设备对被测区域进行声呐数据采集,并将采集得到的数据根据步骤1-1中的方法进行预处理,得到被测声呐图像。
3-2.用步骤2中训练好的难样本重训练深度神经网络对步骤3-1得到的被测声呐图像进行目标的识别和框选,从而得到被测区域中目标的位置。
为验证本发明的技术效果,使用170张未被用于训练的声纳图像作为测试集,使用现有fasterrcnn模型与本发明分别进行检测,所得目标检测结果对比图如图2a-2f所示(图2a-2c为现有技术的检测结果,图2d-2f为本发明的检测结果):‘columnor’与‘linear’字样表示目标所属类别,下方数字代表检测结果的置信度。对比观察到本发明可将所有目标检出,而现有fasterrcnn模型存在一例误检,同时本发明给出的目标边框也较现有fasterrcnn模型更为准确。总精度对比结果如表1所示。通过对比改进前后的模型可发现,本发明对于线状目标检测有明显提高,总体上有0.04的平均精度提升,进而验证了本发明的可靠性。
表1:本发明与改进前fasterrcnn模型精度对比。
- 还没有人留言评论。精彩留言会获得点赞!