一种基于Spark引擎的智能分析系统的制作方法
本发明涉及数据分析服务领域,具体涉及基于spark的计算引擎实现的对金融数据的分析系统。
背景技术:
金融期货市场的快速发展和技术的迅速成熟,为监管工作提出了新的挑战,特别是2015年资本市场发生异常波动,表明在应对风险的跨境、跨市场传递以及程序化交易等信息技术应用方面,传统监管模式还不能完全适应,迫切要求监管工作者能够及时发现市场主体的潜在风险,加强对市场异动的监控,提升稽查执法的深度和广度,维护市场稳定,切实保护中小投资者合法权益。这些都需要监管工作向科技化、智能化的方向发展。为贯彻落实证监会提出加强“监管科技”建设的工作思路,推动监管科技应用落地是监查系统建设的重要任务。这也是监查系统的重要组成部分。
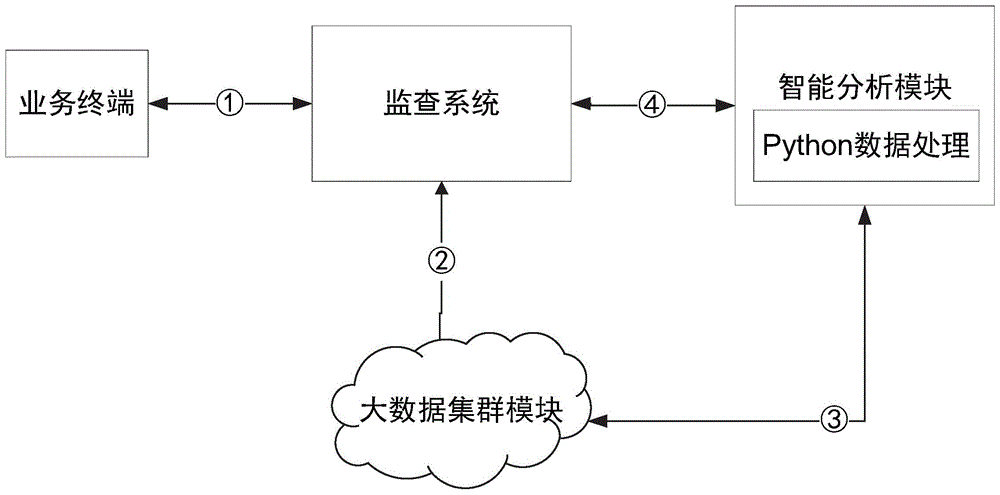
目前监查系统——长城系统中的智能分析服务,其总体架构如图1所示,在数据生成过程中,由监查系统后台定时任务触发调用智能分析restful服务(图1的路径④),从而触发智能算法运行,产生的结果数据最终存入大数据集群(通过图1中的路径③,以hdfs文件储存)。
在数据使用过程中,监查系统的业务查询后台直接以impala查询方式访问大数据集群上的数据(图1中的路径②),从而获得智能分析服务最终结果数据,完成业务终端查询。
图2示出了传统系统中的python数据处理模块中的计算路径,其中包含数据来源(数据输入)和数据流向(数据输出)路径。数据输入路径包含图2所示的①、②和③,分别为来自本地文件系统、大数据集群的分布式文件系统hdfs和传统数据库;数据输出路径包含图2所示的④和⑤,分别为大数据集群的分布式文件系统hdfs和传统数据库。python数据处理模块主要进行常规python数据处理和机器学习等更为复杂的处理。此python数据处理模块是单机处理的,因而在处理大数据量时会造成处理慢、处理时间极长甚至导致最终无法得出有效结果,具有性能问题和应用局限性。
总的来说,目前的智能分析系统存在以下问题:
i.基于python的智能分析算法是以单机运行的,而单机处理速度、数据量都是有限的。面对监查系统需要处理的大规模数据,已经远远超出了单机的负荷。若算法使用较短的时间参数或小数据量,则可能导致训练数据不够而使算法结果无法发挥作用或者效果大打折扣;若算法使用较长的时间参数或大数据量,则可能导致算法无法在有效时间内计算出结果。
ii.基于python的智能分析算法,不能在集群数据上直接运行,其需要从集群中将处理数据读到本地,在本地单机处理完成后再将结果传回集群,这种双向io也是个耗时因素,拖慢智能服务速度。
iii.智能分析系统(pythondjango框架)跟监查系统(公司内部的java框架)的调用链(图1中的路径④)存在不稳定因素,需要改造。
iv.智能分析系统是智能化处理数据的模块,新一代监查系统则是专门提供监查服务的业务系统,目前新一代监查系统还负责智能数据处理模块数据生成过程的调用触发,这部分功能属于任务调度,可以从新一代监查系统(业务系统)中剥离出来,使业务无关的支持功能与业务核心功能解耦合。
v.最后一点,python单机数据处理通常更适用于小数据量下的科学探索,并不适合工业化应用,因此,探索过程之后,应该寻求工业化解决方案。
技术实现要素:
以下给出一个或多个方面的简要概述以提供对这些方面的基本理解。此概述不是所有构想到的方面的详尽综览,并且既非旨在指认出所有方面的关键性或决定性要素亦非试图界定任何或所有方面的范围。其唯一的目的是要以简化形式给出一个或多个方面的一些概念以为稍后给出的更加详细的描述之序。
本发明的目的在于解决上述问题,提供了一种基于spark引擎的智能分析系统,解决了智能分析服务的性能问题,实现了将智能分析服务应用于长时间、大数据分析场景,支持海量数据分析和价值挖掘,可以拓宽科技监管的探索深度和广度,同时使得系统架构更为灵活和独立,且复杂度也得到了降低,还可以进一步拓宽科技监管的应用场景、提供与市场变化情况接近同步的监控管理。
本发明的技术方案为:本发明揭示了一种基于spark引擎的智能分析系统,系统包括智能分析模块中设置的数据处理模块和数据服务调用管理模块、大数据集群模块、服务查询模块,智能分析模块和大数据集群模块建立双向的数据传输,服务查询模块集成在监查系统中,监查系统接收大数据集群模块的输出,监查系统和智能分析模块建立双向的数据传输,其中:
数据处理模块,用于实现基于spark引擎的智能分析服务的数据逻辑;
数据服务调用管理模块,用于实现基于spark引擎的智能分析服务的定时触发,以生成预期数据供后续消费;
大数据集群模块,包括spark组件及其数据资源,用于对数据存储访问和数据查询分析的支持;
服务查询模块,实现基于spark引擎的智能分析服务结果的对外展示。
根据本发明的基于spark引擎的智能分析系统的一实施例,数据处理模块配置为针对特定业务选取适用算法,利用spark集成的sparkmlib和graphx库,并基于存储在大数据集群模块上的数据资源进行数据预处理、计算、训练和预测,输出结果文件并存储于大数据集群模块上,其中算法根据业务实际需求编写。
根据本发明的基于spark引擎的智能分析系统的一实施例,数据处理模块配置为离线部分和实时部分,其中离线部分与监查系统进行解耦合,实时部分为监查系统提供实时应用服务支持。
根据本发明的基于spark引擎的智能分析系统的一实施例,数据处理模块中的spark引擎配置为接收本地文件系统、大数据集群模块上的分布式文件系统hdfs、数据库和kafka流式数据源的四种输入,采用sparksql、sparkstreaming、sparkmlib和sparkgraphx组件对业务或算法进行处理,输出为大数据集群模块上的分布式文件系统hdfs、数据库、实时报告展示和kafka流式数据源这四种类型。
根据本发明的基于spark引擎的智能分析系统的一实施例,数据处理模块所提供的实时数据服务包括:数据处理模块分析kafka流式数据,将kafka流式数据的分析结果提供给监查系统,作为实时报告展示中的实时数据加以展示,或者再次进入kafka流式数据中,成为处理后的数据流以供后续使用。
根据本发明的基于spark引擎的智能分析系统的一实施例,数据服务调用管理模块进一步配置为将数据处理模块的逻辑代码根据业务需求进行实际调度触发,还使用shell脚本进行周期性服务调用、错误管理和报警,以及利用外部的任务调度平台进行管理。
根据本发明的基于spark引擎的智能分析系统的一实施例,大数据集群模块进一步配置为处理大数据集群中spark组件的安装,spark资源的控制、管理、扩展、监控,spark数据源与大数据集群已有数据资源的使用和存储权限管理。
根据本发明的基于spark引擎的智能分析系统的一实施例,服务查询模块进一步配置为在监查系统中集成智能分析服务的用户查询界面和接口,以供用户访问智能分析服务的结果数据,还根据业务需求提供统计分析功能。
本发明对比现有技术有如下的有益效果:本发明的系统利用spark这一分布式技术,将原先单机运行的算法改造成可分布式运行的算法,以高处理性能、可扩展性的集群计算方式解决python算法单机运行的性能瓶颈,实现了将智能分析服务应用于长时间、大数据分析场景,支持海量数据分析和价值挖掘,可以拓宽科技监管的探索深度和广度。另外,基于spark技术的系统可以与已有的hadoop集群无缝结合,能够便利地利用已有数据,也方便处理结果数据快速存回大数据集群上。而且,本发明的系统将智能服务生产离线数据与监查系统消费离线数据两种行为进一步解耦合,采用了更为适合大数据处理的更灵活的定时任务调度管理方式,避免了现有智能分析系统里java框架和django框架间不稳定的服务调用交互,使得系统架构更为灵活和独立,且复杂度也得到了降低。同时,本发明的系统还增加提供实时数据服务的功能,可以进一步拓宽科技监管的应用场景、提供与市场变化情况接近同步的监控管理等。
附图说明
在结合以下附图阅读本公开的实施例的详细描述之后,能够更好地理解本发明的上述特征和优点。在附图中,各组件不一定是按比例绘制,并且具有类似的相关特性或特征的组件可能具有相同或相近的附图标记。
图1示出了供监查系统使用的传统的基于python的智能分析系统的架构图。
图2示出了传统的基于python的数据处理模块中的数据计算路径的处理流程示意图。
图3示出了本发明的基于spark引擎的智能分析系统的一实施例的架构图。
图4示出了图3所示系统实施例中的数据处理模块的数据计算路径的处理流程示意图。
具体实施方式
以下结合附图和具体实施例对本发明作详细描述。注意,以下结合附图和具体实施例描述的诸方面仅是示例性的,而不应被理解为对本发明的保护范围进行任何限制。
spark是专门为大规模数据处理而设计的实时计算引擎,可以进行批处理或实时处理,现在已经是一个高速发展且使用广泛的生态系统。其中底层也支持hdfs和yarn,可以无缝接入已有的hadoop生态环境,并使用其中的数据;其应用库还支持了如sparksql、sparkstreaming、mlib、graphx等更为专业的领域算法和数据处理技术。
图3示出了本发明的基于spark引擎的智能分析系统的一实施例的原理架构。请参见图3,本实施例的系统包括智能分析模块中设置的数据处理模块、数据服务调用管理模块、大数据集群模块、服务查询模块。
智能分析模块和大数据集群模块建立双向的数据传输,服务查询模块设置在监查系统中,监查系统接收大数据集群模块的输出,监查系统和智能分析模块建立双向的数据传输。
数据处理模块用于实现智能分析服务的数据逻辑。数据处理模块内部具体的处理为:针对特定的业务选取适用的算法,并利用spark集成的现成sparkmlib和graphx库等,基于存储在大数据集群模块上各种数据资源(hdfs文件,与impala为同源数据),基于spark引擎的分布式运行的算法和集群计算方式进行数据预处理、计算、训练和预测,其中算法根据业务实际需求编写,可采用但不限于scala语言。数据处理模块的输入为算法参数和大数据集群上的基础数据和中间数据(组合因子等),输出为存储于大数据集群模块上的结果文件。本实施例中可分为智能服务生产离线数据部分和实时数据服务部分,其中数据处理模块的智能服务生产离线数据部分可替代原基于python智能分析系统的功能,该智能服务生产离线数据部分与监查系统消费离线数据两种行为进行解耦合,即,智能服务系统生产数据的过程和监查系统消费数据的过程的依赖关系在流程上得以解除,是相互独立的行为,而背景技术中提到的现有的智能服务系统的数据生产过程是需要监查系统进行触发的,这部分在本发明的系统中是不需要的。实时数据服务部分为本实施例的新增功能,为监查系统提供实时应用服务支持。
图4示出了数据处理模块的基于spark引擎的数据处理流程。图4中展示了spark引擎的4条数据输入路径,分别为本地文件系统(图4中的①)、大数据集群的分布式文件系统hdfs(图4中的②)、传统数据库(图4中的③)和kafka流式数据源(图4中的④)。同时也展示了spark引擎的4条数据输出路径,分别为大数据集群的分布式文件系统hdfs(图4中的⑤)、传统数据库(图4中的⑥)、实时报告展示dashboard(图4中的⑦)和kafka流式数据源(图4中的⑧)。核心的数据处理模块利用包括spark引擎中的sparksql、sparkstreaming、sparkmlib和sparkgraphx在内的技术支持业务处理或算法处理。
图4中的输入路径④、sparkstreaming技术、输出路径⑦和⑧可以提供基于spark的实时数据服务,即基于spark引擎的数据处理模块分析来自kafka的流数据,然后将其提供给监查系统,作为dashboard中的实时数据展示(输入路径④+输出路径⑦),或者再次进入kafka,成为处理后的数据流供后续使用(输入路径④+输出路径⑧)。
从离线的智能分析服务功能角度,图2中的路径①、②和③可替代图1传统系统中的①、②、③和④,少了路径④是因为图2的基于spark引擎的智能分析系统的调用管理模块与监查系统进行了解耦合,避免让服务使用方(即监查系统)充当定时任务调用管理的角色。从实时智能分析服务功能角度,图2中的路径①、②、③和④都是存在的,此处路径④是实时服务访问路径(监查系统可以作为spark智能分析系统实时数据的展示dashboard),并非定时任务调用管理路径。
对比图2和图4,可以看出本发明的基于spark引擎的智能分析系统核心的数据处理模块的功能更加强大,其分布式的数据处理技术解决了图2中单机限制带来的一系列问题,并且还可以提供实时数据处理路径,丰富了智能分析系统的服务范围。
数据服务调用管理模块用于实现智能分析服务的定时触发,生成预期数据供后续消费。数据服务调用管理模块内部具体的处理为:将数据处理模块的逻辑代码(如jar包)根据业务需求进行实时调度触发,可使用shell脚本进行周期性服务调用、错误管理和报警等,且方便进行失败重跑,也可利用任务调度平台进行管理。任务调度平台不是智能分析系统的一部分,它属于支持系统。其角色取决于不同公司内部的定义,经常是一个公司或者大部门内的基础架构系统,但也可以被认定为诸如数据平台中的核心组件(即使数据平台该部分复用公司已有的调度系统模块)。任务调度平台的主要作用是对定时任务和依赖任务的调度运行,并且时刻监督任务的运行状况,在必要时刻给予进度、异常警示、错误提醒或需人工介入处理的多渠道通知等。属于公司不可或缺的流程管理体系,对正常业务运维极其重要,对任何一个企业都算是必备的基础架构系统。
大数据集群模块为智能分析模块的支持平台,主要是构建在hadoop系统之上的spark组件和其上的数据资源。大数据集群模块内部具体处理涉及大数据集群中spark组件的安装,spark资源的控制、管理、扩展、监控,spark数据源与大数据集群已有数据资源的使用和存储权限管理等。大数据集群模块是智能分析系统和监查系统中的服务查询功能的交互枢纽,主要用于对数据存储访问和数据查询分析的支持。
服务查询模块集成在监查系统内,用于实现基于spark引擎的智能分析服务结果的对外展示。服务查询模块内部具体的处理为:在监查系统中集成智能分析服务的用户查询界面和接口,以供用户访问智能分析服务的结果数据,也可根据业务需求提供必要的统计分析功能,其数据输入为大数据集群模块上的数据文件。
尽管为使解释简单化将上述方法图示并描述为一系列动作,但是应理解并领会,这些方法不受动作的次序所限,因为根据一个或多个实施例,一些动作可按不同次序发生和/或与来自本文中图示和描述或本文中未图示和描述但本领域技术人员可以理解的其他动作并发地发生。
本领域技术人员将进一步领会,结合本文中所公开的实施例来描述的各种解说性逻辑板块、模块、电路、和算法步骤可实现为电子硬件、计算机软件、或这两者的组合。为清楚地解说硬件与软件的这一可互换性,各种解说性组件、框、模块、电路、和步骤在上面是以其功能性的形式作一般化描述的。此类功能性是被实现为硬件还是软件取决于具体应用和施加于整体系统的设计约束。技术人员对于每种特定应用可用不同的方式来实现所描述的功能性,但这样的实现决策不应被解读成导致脱离了本发明的范围。
结合本文所公开的实施例描述的各种解说性逻辑板块、模块、和电路可用通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其它可编程逻辑器件、分立的门或晶体管逻辑、分立的硬件组件、或其设计成执行本文所描述功能的任何组合来实现或执行。通用处理器可以是微处理器,但在替换方案中,该处理器可以是任何常规的处理器、控制器、微控制器、或状态机。处理器还可以被实现为计算设备的组合,例如dsp与微处理器的组合、多个微处理器、与dsp核心协作的一个或多个微处理器、或任何其他此类配置。
结合本文中公开的实施例描述的方法或算法的步骤可直接在硬件中、在由处理器执行的软件模块中、或在这两者的组合中体现。软件模块可驻留在ram存储器、闪存、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、可移动盘、cd-rom、或本领域中所知的任何其他形式的存储介质中。示例性存储介质耦合到处理器以使得该处理器能从/向该存储介质读取和写入信息。在替换方案中,存储介质可以被整合到处理器。处理器和存储介质可驻留在asic中。asic可驻留在用户终端中。在替换方案中,处理器和存储介质可作为分立组件驻留在用户终端中。
在一个或多个示例性实施例中,所描述的功能可在硬件、软件、固件或其任何组合中实现。如果在软件中实现为计算机程序产品,则各功能可以作为一条或更多条指令或代码存储在计算机可读介质上或藉其进行传送。计算机可读介质包括计算机存储介质和通信介质两者,其包括促成计算机程序从一地向另一地转移的任何介质。存储介质可以是能被计算机访问的任何可用介质。作为示例而非限定,这样的计算机可读介质可包括ram、rom、eeprom、cd-rom或其它光盘存储、磁盘存储或其它磁存储设备、或能被用来携带或存储指令或数据结构形式的合意程序代码且能被计算机访问的任何其它介质。任何连接也被正当地称为计算机可读介质。例如,如果软件是使用同轴电缆、光纤电缆、双绞线、数字订户线(dsl)、或诸如红外、无线电、以及微波之类的无线技术从web网站、服务器、或其它远程源传送而来,则该同轴电缆、光纤电缆、双绞线、dsl、或诸如红外、无线电、以及微波之类的无线技术就被包括在介质的定义之中。如本文中所使用的盘(disk)和碟(disc)包括压缩碟(cd)、激光碟、光碟、数字多用碟(dvd)、软盘和蓝光碟,其中盘(disk)往往以磁的方式再现数据,而碟(disc)用激光以光学方式再现数据。上述的组合也应被包括在计算机可读介质的范围内。
提供对本公开的先前描述是为使得本领域任何技术人员皆能够制作或使用本公开。对本公开的各种修改对本领域技术人员来说都将是显而易见的,且本文中所定义的普适原理可被应用到其他变体而不会脱离本公开的精神或范围。由此,本公开并非旨在被限定于本文中所描述的示例和设计,而是应被授予与本文中所公开的原理和新颖性特征相一致的最广范围。
- 还没有人留言评论。精彩留言会获得点赞!