将微操作分配到微操作高速缓存器的处理设备及其操作方法与流程
本文公开的主题涉及处理设备中的指令高速缓存器。更具体地,本文公开的主题涉及一种向处理设备中的微操作(μop)高速缓存器有效地分配微操作的系统和方法。
背景技术:
移动设备中的中央处理单元(cpu)基于移动设备电池寿命受到功耗以及与热限制有关的性能调节的约束。因此,在不损失性能的情况下减少功耗可以提供cpu微架构的理想进展。已经开发出跟踪高速缓存器(tracecache),提供了重复指令流不需要重复地通过整个指令和解码管线。而是,从高速缓存器结构中取回(fetch)重复指令的解码μop。跟踪高速缓存器提供在可变长度x86指令集架构(isa)解码器或微代码只读存储器(rom)读出之后压缩后解码指令的能力以及避免未对准高速缓存器行取回的能力。跟踪高速缓存器可以使用基于分支预测器的专用跟踪高速缓存器零气泡(zero-bubble)偏置,并且如果指令的分支应当采用不同的路径进行跟踪,则遵循制作相同指令的冗余副本的代码的字面“跟踪”。
还开发了μop高速缓存器。μop高速缓存器中的微操作与准确地址映射上的相应输入指令相匹配,由于缺少μop复制,导致使用比跟踪缓存器更少的存储的折中。然而,微操作编码通常使用比指令高速缓存器中的do指令更多的位,因此,μop高速缓存器通常可以使用比指令高速缓存器更多的存储。μop高速缓存器通过将取回瓶颈与派遣分离,允许具有可变长度解码和/或rom限制的cpu具有一些改进的性能。另外,如果在μop高速缓存器中存在基本块,则μop高速缓存器可以通过不经由指令/解码管线进行冗余排序来节省一些功率。尽管因为跟踪高速缓存器复制μop而μop高速缓存器没有,所以压缩量比跟踪高速缓存器要多,但是μop结构已经成功并在当今许多cpu中都处于活跃状态。
在高级risc机器(arm)isa中,a64中的实现不具有可变长度解码,或者通常将rom用于微代码例程。因此,通过μop高速缓存器对取回和发出操作进行解耦可能几乎没有性能优势。尽管如此,arm实现往往针对移动应用,因此降低功耗可能是可期望的,尤其是当移动设备性能指标的不断提高时。
仅关注功率而不充当中间管道高速缓存器以使解码指令与各种取回机制解耦的微操作高速缓存器可以允许基于不同设计约束进行优化。具体地,对于新的设计空间,可以允许选择驱动预测器、匹配指令的能力、写入什么和何时写入以及何时从高速缓存器中读取功率。
技术实现要素:
示例实施例提供一种将微操作(μop)分配到μop高速缓存器中的方法,所述方法可以包括:由微分支目标缓冲器(μbtb)将指令划分为第一基本块,指令由处理设备执行,并且第一基本块对应于由处理设备执行的指令的边缘;由μbtb将第一基本块分配给反向基本块队列(ibbq);响应于确定第一基本块适合μop高速缓存器,由μbtb将第一基本块分配给反向基本块队列(ibbq);以及由ibbq基于处理设备重复执行与第一基本块相对应的指令的边缘的次数,将第一基本块分配给μop高速缓存器。在一个实施例中,所述方法还可以包括递增μbtb中的计数器,包含由处理设备执行与第一基本块相对应的边缘的次数的计数。在另一实施例中,ibbq可以包括n条目缓冲器(n-entrybuffer),以跟踪分配给ibbq的基本块被重复的次数。
示例实施例提供一种处理设备,可以包括微操作(μop)高速缓存器、微分支目标缓冲区(μbtb)和反向基本块队列(ibbq)。μbtb可以将指令划分为第一基本块,其中,指令可以由处理设备执行,并且第一基本块对应于由处理设备执行的指令的边缘,其中,μbtb可以确定第一基本块适合μop高速缓存器。ibbq可以耦合到μbtb,并且ibbq可以基于确定第一基本块适合μop高速缓存器来接收第一基本块。ibbq可以基于处理设备重复执行与第一基本块相对应的指令的边缘的次数,将第一基本块分配给μop高速缓存器。在一个实施例中,μbtb还可以包括计数器,包含由处理设备执行与第一基本块相对应的边缘的次数的计数。
附图说明
在以下部分中,将参照图中所示的示例性实施例来描述本文公开的主题的各方面,在附图中:
图1描绘了根据本文公开的主题的微处理器的示例实施例的框图,该微处理器包括具有微分支目标缓冲器、μop高速缓存器和关联解耦队列的前端;
图2描绘了图1的微处理器的前端的示例实施例的框图;
图3描绘了根据本文公开的主题的图1和图2的微分支目标缓冲器的示例实施例的框图;以及
图4是根据本文公开的主题的反向基本块队列的分配和加权的基本算法的示例实施例的流程图。
具体实施方式
在下面的详细描述中,阐述了许多具体细节以便提供对本公开的透彻理解。然而,本领域技术人员将理解,可以在没有这些具体细节的情况下实践所公开的方面。在其他情况下,没有详细描述公知的方法、过程、组件和电路,以免使本文公开的主题不清楚。
在整个说明书中,对“一个实施例”或“实施例”的引用意味着结合该实施例描述的特定特征、结构或特性可以包括在本文公开的至少一个实施例中。因此,在整个说明书中各处出现的短语“在一个实施例中”或“在实施例中”或“根据一个实施例”(或具有相似含义的其他短语)可能不一定全都指同一实施例。此外,在一个或多个实施例中,可以以任何合适的方式组合特定的特征、结构或特性。对此,如本文所用,词语“示例性”是指“用作示例、实例或说明”。本文中被描述为“示例性”的任何实施例都不应被解释为有必要比其他实施例优选或有利。另外,在一个或多个实施例中,可以以任何合适的方式组合特定特征、结构或特性。此外,根据本文讨论的上下文,单数术语可以包括对应的复数形式,并且复数术语可以包括对应的单数形式。类似地,连字符术语(例如,“二-维”,“预-定”,“像素-特定”等)可以偶尔与对应的非连字符版本(例如,“二维”,“预定”,“像素特定”等)和大写条目(例如,“counterclock”、“rowselect”、“pixout”等)可以与相应的非大写版本(例如,“counterclock”、“rowselect”、“pixout”等)。这种偶然的互换使用不应被认为是相互矛盾的。
此外,取决于本文讨论的上下文,单数术语可以包括对应的复数形式,并且复数术语可以包括对应的单数形式。还应注意,本文示出和讨论的各种附图(包括组件图)仅用于说明目的,并且未按比例绘制。同样,各种波形和时序图仅出于说明目的。例如,为了清楚,一些元件的尺寸可能相对于其他元件被放大。此外,如果认为适当,则在附图之间重复附图标记以指示相应和/或类似的元件。
本文中使用的术语仅出于描述一些示例实施例的目的,并且不旨在限制所要求保护的主题。如本文所使用的,单数形式“一”、“一个”和“该”也意图包括复数形式,除非上下文另外明确指出。还将理解,当在本说明书中使用术语“包括”和/或“包含”时,其指定所述特征、整数、步骤、操作、元件和/或组件的存在,但并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或其组。如本文中所使用的,术语“第一”、“第二”等被用作它们之前的名词的标签,并且除非明确定义,否则不暗示任何类型的排序(例如,空间、时间、逻辑等)。此外,可以在两个或更多个附图上使用相同的附图标记来指代具有相同或相似功能的部件、组件、块、电路、单元或模块。然而,这种用法仅是为了说明简单和易于讨论;这并不意味着这些组件或单元的构造或架构细节在所有实施例中都是相同的,或者这种共同参考的部件/模块是实现本文所公开的一些示例实施例的唯一方式。
如本文中所使用的,术语“第一”、“第二”等被用作它们之前的名词的标签,并且除非明确定义,否则不暗示任何类型的排序(例如,空间、时间、逻辑等)。此外,可以在两个或更多个附图上使用相同的附图标记来指代具有相同或相似功能的部件、组件、块、电路、单元或模块。然而,这种用法仅是为了说明简单和易于讨论;这并不意味着这些组件或单元的构造或架构细节在所有实施例中都是相同的,或者这种共同参考的部件/模块是实现本文所公开的一些示例实施例的唯一方式。
除非另有定义,否则本文中使用的所有术语(包括技术术语和科学术语)具有与本主题所属领域的普通技术人员通常所理解的相同含义。还将理解,诸如在常用词典中定义的那些术语应被解释为具有与其在相关技术的上下文中的含义一致的含义,并且除非在本文中明确定义,否则将不会以理想化或过于正式的意义来解释。
如本文所使用,术语“模块”是指被配置为结合模块提供本文所描述的功能的软件、固件和/或硬件的任何组合。该软件可以体现为软件包、代码和/或指令集或指令,并且如本文所述的任何实现方式中所使用的术语“硬件”可以包括例如单个或任意组合的硬连线电路、可编程电路、状态机电路和/或存储由可编程电路执行的指令的固件。模块可以集体或单独地体现为形成较大系统的一部分的电路,例如但不限于集成电路(ic)、片上系统(soc)等。本文公开的各种组件和/或功能块可以体现为模块,该模块可以包括提供结合各种组件和/或功能块在此描述的功能的软件、固件和/或硬件。
微操作高速缓存器相对较小,并且出于效率的考虑,其高速缓存器行尺寸通常比关联指令高速缓存器的行尺寸小得多。由于指令的分支行为,典型的μop高速缓存器行经常不被有效解码指令完全占用,从而导致μop高速缓存器的低效使用。例如,如果cpu在尝试将解码指令容纳于典型的μop高速缓存器中时过于激进,则程序内核可能随后需要已经从μop高速缓存器中逐出(即移除)的先前解码指令,从而导致μop高速缓存器未命中,浪费功率,并且在一些实现方式中可能会由于取回访问指令高速缓存器而导致性能损失。
本文公开的主题提供一种μop高速缓存器系统,该μop高速缓存器系统利用(1)最有可能被取回和(2)共同适合μop高速缓存器的程序内核的基本块组(μop)有效地填充μop高速缓存器的行。如本文所使用的,术语“基本块”是指指令(μop)的“直线”段,其开始于采取分支(takenbranch)的目标或未采取分支(non-takenbranch)的下一个顺序指令,并终止于按程序顺序的下一个分支。可以通过添加权重来修改微分支目标缓冲器(μbtb),权重跟踪由μbtb图条目中的采取链路、未采取链路和顺序链路表示的程序边缘/基本块中的每一个的“热量”。反向基本块队列(ibbq)确定哪些热块应适合μop高速缓存器。跟踪每个基本块的热度,并确定或估计单独适合μop高速缓存器和共同适合μop高速缓存器的最热基本块组。
μbtb可以使用温度计权重来保持跟踪每个基本块的“热度”。每次提交指令的基本块时,μbtb中相应温度计权重被增加。如果任何特定权重饱和,则通过将权重值向右移动一位而将所有权重除以2,从而允许维持所有基本块的相对热量。反向基本块队列(ibbq)可以用于将基本块分类为“分区(bucket)”或组,以基于温度计权重的哪个最高有效位被置位来进行跟踪。ibbq可以对于所有分区化块估计μop的数量,从最热的块分区到最冷的块分区,直至达到μop高速缓存器的最大容量,然后将其分配到μop高速缓存器。然后,响应于由μbtb和ibbq发出的高速缓存器构建命令,可以将估计的μop组分配或插入到μop高速缓存器。在指令取回时间,在解码器解码对应指令之后,μbtb指示给定基本块要被写入到μbtb中。μop高速缓存器和解码器可以进行实际指令解码,并将μop写入μop高速缓存器中。
本文公开的主题提供关于哪些基本块应当被写入到μop高速缓存器的指示。通过直到被估计要分配给μop高速缓存器的最热内核的整个预测群已构建并且μbtb确定正在取回的μop来自μop高速缓存器中的μop群为止、不进入μop高速缓存器取回模式,可以提高cpu的性能,从而避免基于未构建或逐出的μop,由μop高速缓存器未命中引起的cpu重定向。在一些实施例中,适合μop高速缓存器的基本块的确定可能由于以下事实而变得复杂:基于将μop分配到μop高速缓存器中的顺序的改变,在第一次通过内核期间被确定适合μop高速缓存器并且被分配到μop高速缓存器的内核可能在第二次分配中不适合μop高速缓存器。
执行确定μop组的逻辑可以被称为μop高速缓存器构建“过滤器”,其可以包括μbtb和ibbq。ibbq可以被用于确定最有可能被取回并且单独地适合于μop高速缓存器的基本块。μbtb可以填充ibbq条目,并且将μbtb中的基本块标记为由ibbq跟踪。ibbq还可以确定共同(作为一组)适合μop高速缓存器的缓存器行的基本块组。基本块组可以基于可以占用μop高速缓存器行的μop的平均数。ibbq还可以跟踪已被估计为单独且共同适合整个μop高速缓存器的基本块组以及已放置(构建)在μop高速缓存器中的基本块的热度。
可以周期性评估μop高速缓存器的有效性,并可以调整可以适合μop高速缓存器行的指令的平均数,以便根据从μop高速缓存器接收的“适合”反馈,使μop高速缓存器构建过滤器更保守或更激进。如果确定可以适合μop高速缓存器行的指令的平均数过于激进,则可以通过减少可以适合μop高速缓存器行的指令的平均数来使用多少μop高速缓存器条目的更保守估计,以构建每个指令。如果确定估计过于保守,则可以通过增加可以适合μop高速缓存器行的指令的平均数,将可以适合μop高速缓存器行的指令的平均数调整为更激进。
本文所公开的主题还可以通过仅对实际上将适合μop高速缓存器的程序边缘以及已经被构建并且位于μop高速缓存器中的所有较热程序边缘发出μop高速缓存器构建命令来提供功率节省。如本文所使用的,术语“程序边缘”是指基本块。通过在确定要插入到μop高速缓存器中的最热内核的整个群已经建立之前,不进入μop高速缓存器取回模式,可以提高性能,这可以避免由未构建或逐出的μop导致的高速缓存器未命中引起的前端重定向。
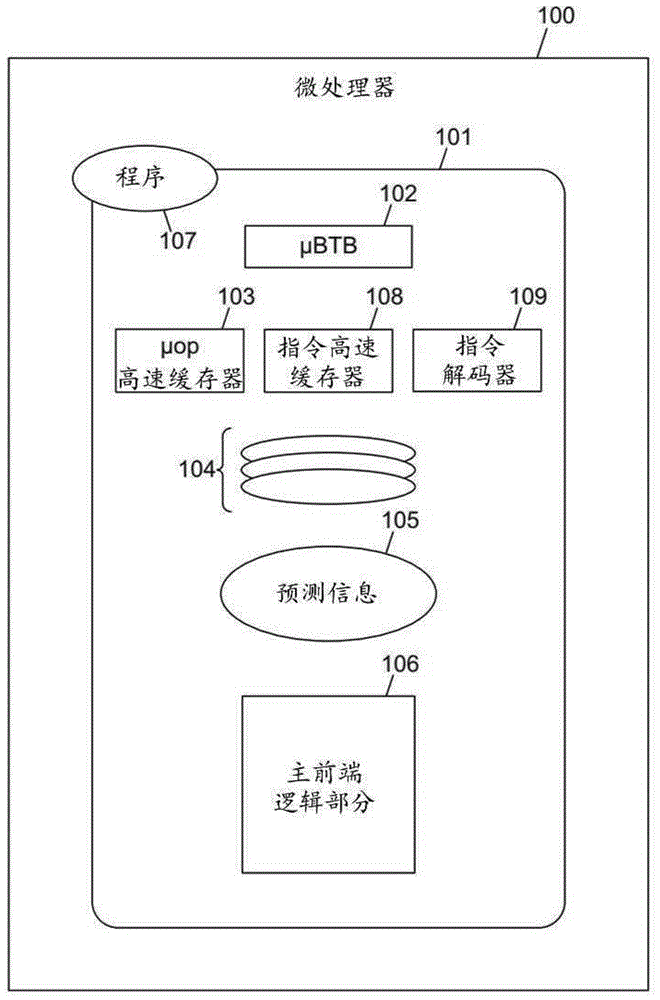
图1描绘了根据本文公开的主题的微处理器100的示例实施例的框图,微处理器100包括具有μbtb102、μop高速缓存器103和关联解耦队列104的前端101。前端101还可以包括指令高速缓存器108、指令解码器109、分支预测逻辑(未示出)、取回逻辑(未示出)等,如本文中进一步描述的。μbtb102、μop高速缓存器103和解耦队列104可以产生可以由微处理器100的主前端逻辑部分106接收的预测信息105。将理解,可以将解耦队列104视为μbtb102的一部分,或者可替换地,可以将其视为与μbtb102分离,但是与μbtb102相关联。解耦队列104可以将预测信息105提供给主前端逻辑部分106,并将μbtb102与微处理器100的其余部分解耦。微处理器100可以执行程序107。当μbtb102确信预测信息105时,μbtb102可以电力选通(powergate)主前端逻辑部分106的主预测结构,从而显著降低微处理器100的功耗。
图2描绘了图1的微处理器100的前端101的示例实施例的框图。图3描绘了根据本文公开的主题的图1和图2的μbtb102的示例实施例的框图。
前端101可以包括μbtb102、μop高速缓存器103和解耦队列104,其可以将预测信息105提供给主前端逻辑部分106。主前端逻辑部分106可以包括各种选择器或多路复用器(例如205)、加法器(例如,250、255、260)、比较器(例如,240、290和296)、返回地址栈275和/或其他未示出的组件。另外,主前端逻辑部分106可以包括与μbtb102分离的主btb215和虚拟btb270。
btb可以是包含关于程序107中的分支的地址、目标、类和/或特定预测状态信息的信息的结构。主btb215和虚拟btb270可以包括关于程序107中的分支的信息。μbtb102可以捕获程序107的热内部,并且如果由主btb215或虚拟btb270预测,则允许分支的零气泡采取预测,否则将引起多周期损失(气泡)。
主btb215可以在取回窗口中按程序顺序容纳一个或两个分支。例如,取回窗口可以是指令地址空间的32字节对准块。虚拟btb270可以容纳在给定取回窗口中给定的附加分支对。取回可以包括例如从高速缓存器层级或存储器中检索指令数据,预测当时已知存在的任何分支指令,以及将指令数据与指令位置对准以进行解码。虚拟btb270可以处理相对不太可能的情况,其中,在给定取回窗口中驻留多于两个分支。主条件预测器265可以耦合到主btb215,在μbtb110对其预测准确度没有足够的信心的情况下,可以基于诸如权重220的信息和来自主btb215的信息来预测分支。
主前端逻辑部分106还可以包括一个或多个内容可寻址存储器(cam)(例如,225和245)和/或一个或多个转换后备缓冲器(例如,stlb230和stlb285)。在一些实施例中,前端逻辑部分106可以包括itag部分292和/或utag部分235。主前端逻辑部分106还可以包括tlb页表条目(例如,btlbpte280)和/或未命中缓冲器294。主前端逻辑部分106可以被划分为分支预测管道级(例如,b1、b2、b3和b4)。在第一分支预测管道级(例如,b1)中,多路复用器205可以接收来自取回逻辑210、退出重定向202、执行重定向204、地址检查206和/或来自μbtb102的预测信息120的输入并选择。尽管本文中使用术语“多路复用器”,但是将理解,“多路复用器”可以指代任何合适种类的选择器。
图3描绘了根据本文公开的主题的μbtb102的示例实施例的框图。μbtb102可以包括μbtb图表(或缓冲器)302、ibbq303、μbtb内容可寻址存储器(cam)304以及每个条目可用时隙(uspe)寄存器305。构建在μop高速缓存器中的基本块103可以是μbtb102跟踪的基本块的子集。μbtb图表302、ibbq303和uspe寄存器305一起可以用作μop高速缓存器103(图2)的构建过滤器。可以将μbtb图表302称为图表,因为它捕获或反映在微处理器100上执行的程序(例如,程序107)的“图表”。μbtb图表302可以跟踪关于程序107的分支和它们的被确定为热的基本块(即,感兴趣内核的最内部)的信息。μbtbcam304可以用于将μbtb102与cpu100的取回管线同步,使得μbtb102可以向取回管线提供预测。
μbtb图表302可以存储有关μop目标分支310的信息,并且可以使用关于μbtb图表302跟踪的每个程序边缘的n位“温度计”权重值来跟踪它跟踪的基本块/分支的“热量”。目标分支不必由μbtb102跟踪。在一个实施例中,μbtb图表302可以跟踪多达128个基本块。在另一个实施例中,μbtb图表302可以跟踪多于128个基本块。温度计权重在本文中可以被称为link[t|n|seq]weight[7:0]311。可以与由μbtb102跟踪的每个程序边缘相关联的状态位可以指示程序边缘是否由ibbq303跟踪(link[t|n|seq].tracked)312、是否在μop高速缓存器中构建(link[t|n|seq].built)313,或者因为尝试构建所以被标记为“无μop高速缓存器构建”(link[t|n|seq].noμop)314。
ibbq303可以被认为是μbtb102的扩展。ibbq303可以是n条目寄存器结构306,其跟踪已经被估计为单独适合整个μop缓存器103的μbtb程序边缘的群或组。在一个实施例中,ibbq303可以包括八(8)个分区或条目。ibbq303的第n-1条目可能是“最热”条目,而第0条目可能是最冷条目。例如,较热条目(例如,具有相对较大热值的条目)在ibbq303中移动较高,而较冷条目朝向ibbq303的底部移动。每个ibbq条目跟踪程序边缘组而不是单个边缘。给定程序边缘的ibbq303的目标条目可以由设置在其热量中的最高有效位来确定。例如,如果权重具有值0xff,则它映射到ibbq条目[7],因为权重的位[7]被设置为1。例如,如果权重具有值0x52,则权重映射到ibbq条目[6]。如果权重具有值0x03,则它映射到ibbq303的ibbq条目[2]。
每个ibbq条目可以包含:有效位315;表示特定ibbq条目跟踪的所有程序边缘所需的μop的估计数量(estimateduops[8:0])316;在μop高速缓存器中尚未构建的由该ibbq条目跟踪的μbtb程序边缘的数量(numunbuiltedges[7:0])317;以及适合位318。如果由有效ibbq条目和较热有效ibbq条目跟踪的所有基本块被估计为适合μop高速缓存器103,则可以将适合位318设置为等于1。
ibbq条目的记录计划(por)数量可以为8,由8位程序边缘热权重来索引,该8位程序边缘热权重被添加到由μbtb102跟踪的每个边缘。μbtb102中的每个链接可以添加link[t|n|seq].tracked位312,以确定是否由ibbq303跟踪对应的程序边缘。对于每个链接,热权重可以在μbtb图表302中被表示为添加到每个图表条目的link[t|n|seq]weight[7:0]311。
usableslotsperentry[x:0](uspe)寄存器304可以是被μop高速缓存器103有效使用的每个μop高速缓存器条目的μop数量的统计估计。在一个实施例中,每个μop高速缓存器条目可以容纳六(6)个μop。也就是说,将μop高速缓存器行中的每个μop分配给μop条目中的六个时隙之一。取决于指令解码成多少个μop指令以及μop高速缓存器103能够将解码的μop放入μop高速缓存器条目的效率如何(这也可能是填充μop缓存器条目的顺序的函数),每个μop高速缓存器条目最多可容纳6条指令。因此,uspe寄存器305使用三(3)位以计数最多6。然而,替选实现方式可以指示大于6的值,以处理μbtb中的程序边缘在μop高速缓存器103中重叠的情况。为了估计可以适合μop高速缓存器103的μop的群,尽管一些指令可以解码成多于一个μop,但是假设每个指令恰好解码成一个μop。uspe寄存器305可以用作启发式以确定可以有效地适合μop高速缓存器103的基本块的填充。通过将已知沿着与μbtb链接相对应的程序边缘放置的指令的数量与μop高速缓存器中的条目数乘以在uspe寄存器305中包含的值进行比较,uspe寄存器305可以用于确定已知沿着与μbtb链接相对应的程序边缘放置的指令的数量本身理论上是否适合整个μop高速缓存器103。取决于如何有效地使用分配给μop高速缓存器的μop,可以周期性地将uspe寄存器305的值调整为更激进或更不激进。uspe寄存器305始终计数为6可能不切实际,因为各种μop高速缓存器碎片效应可能会导致每个条目的可用时隙平均数小于6。由于μbtb图表302中的程序边缘在指令地址空间中重叠,因此特定程序内核的uspe寄存器305甚至可能大于6。
图4是根据本文公开的主题的ibbq303的分配和加权的基本算法的示例实施例的流程图400。为了插入到ibbq303中,在401,新的基本块必须首先通过构建过滤器,然后在402输入到μbtb102。此时,在403,通过构建过滤器涉及跟踪插入μbtbcam304及其相应边缘的种子分支,以确定它们是否重复。根据定义,μbtb102无法检测到并且无法轻松适应的任何对象将不会在403处重复足够多,或不足以用于μop高速缓存器103中。在404,确定包含基本块所需的μop数量。在405,确定基本块的尺寸是否可以适合整个μop高速缓存器103。如果尺寸太大,则流程返回403。如果基本块的尺寸可以适合整个μop高速缓存器103,则流程继续到406,在406,用于基本块的图表将图表中的基本块指示为link[t|n|seq].tracked312。在407,设置μbtb102中的跟踪位并更新ibbq303。
在包括408-410的循环期间,当遍历或执行块时,μbtb102更新μbtb图表302中的各个基本块的“热量”。在408,确定是否遍历块。如果是,则流程继续到409。如果不是,则流程保持在408。在409,响应于基本块的遍历或命中可以将权重值递增1。可以使用八位“温度计”权重值。
在410,如果在409关于任何特定基本块的权重值递增,并且已经为该基本块设置的最高有效位前进一个位置(例如,权重从127递增到128),则在411,该基本块应该被移动到较高温度分区中。例如,如果基本块位于分区ibbq[6]中,则如果在图表中“跟踪”位312被置位则可以从分区ibbq[6]中去除分支信息,并且该分支信息可以被添加到分区ibbq[7]。
流程继续到412,在412,确定μbtb图表302中的任何权重值是否已经饱和在最大值(255)。如果是,则流程继续到413,在413,图表的所有权重值(包括饱和值)向右移动一个位置,从而将移位后的权重除以2。也就是说,ibbq303的全部内容向下移位一个位置。在另一实施例中,可以将图表中的所有权重值(包括饱和值)向右移动多于一个的位置。流程返回到408。
在407分配给ibbq303之后,ibbq条目可以用于通过对已被采取的分支目标的指令数量计数并包括下一个标记分支(对于采取分支)进行计数,或者对从下一个顺序指令开始直到下一个标记分支为止尚未采取的分支目标的指令数量计数,来估计边缘的μop的数量。在一个实施例中,ibbq303可能没有检测到μop高速缓存器的低效率,诸如碎片和碎块指令。每当ibbq303或uspe寄存器305被更新时,可以通过使用uspe寄存器305的值更新所有ibbq适合位318来处理碎片和碎块指令条件。这可以通过以下来完成:如果ibbq303基于每个分区的estuopcount值的总和预测或估计分区和所有较热有效分区可以适合μop高速缓存器103,则从最热有效分区[7]到最冷有效分区[0]遍历ibbq303,并设置每个分区的适合位318。这可以通过将estuopcount的总和与μop高速缓存器条目的数量乘以在uspe寄存器305中包含的值的乘积进行比较来完成。如果estuopcount的总和小于或等于μop高速缓存器条目的数量乘以在uspe寄存器305中包含的值的乘积,则确定该分区和所有较热有效分区适合μop高速缓存器103。将与该分区相对应的适合位置位,指示ibbq303已确定程序边缘或基本块的群以高度置信度适合μop高速缓存器103。
ibbq303可能不会向μop高速缓存器103发出构建请求,直到ibbq303的第7分区或第6分区足够“暖”以进行置信预测。当最热的ibbq分区([7])或第二最热的ibbq分区([6])足够暖以考虑单独μbtb图表边缘权重饱和有效时的ibbq移动时,这可能会发生。μbtb102还应当取回被标记为在ibbq303中跟踪的程序边缘,对应ibbq分区必须有效,并且ibbq分区合适位318必须等于1。
子例程返回可能是一种特殊情况,因为如果从程序的多个位置调用给定返回,则给定返回目标的μop的估计数量可能会更改。μbtb102可以使用μbtb提交返回地址栈(ras)来确定从调用的下一个顺序指令直到但不包括顺序路径上的下一个分支的程序计数器(pc)的μop的估计数量。
ibbq303可以继续跟踪基本块的相对热量,以确定这些块是否已经被分配在μop高速缓存器103中。如果内核也仍然存在于μbtb102中,则这是可能的。μbtb102仍然可以在取回时命中μop高速缓存器103,但是基本块的相对热量可能会丢失。ibbq303可以将基本块相对热量与每个块的μop的估计数量结合使用,以选择是否以新构建破坏现有分配。例如,具有大量μop计数的相对较热的基本块不应总是被认为比具有相对较少μop计数的较暖的基本块更可构建。如果ibbq303确定基本块既足够热又能够适合μop估计,则ibbq303将向解码器发送构建消息。
ibbq303还被用于确定何时已构建属于给定ibbq条目的所有边缘。numunbuiltedges[7:0]计数器字段317指示μbtb102正在跟踪尚未被分配到μop高速缓存器103的多少μbtb边缘。当未构建边缘被分配或移动到ibbq条目(从较冷条目到新的较热条目)时,ibbq条目的numunbuiltedges[7:0]计数器字段317可以递增1。当μbtb102确定在μop高速缓存器103中已经构建与边缘相对应的所有μop时,μbtb102在μbtb102中将边缘标记为built或已分配,并递减numunbuiltedges[7:0]计数器字段317。当给定ibbq条目的numunbuiltedges[7:0]317等于0时,已知已经构建与该ibbq条目相对应的所有边缘。使用此信息,可以检测已经构建处于相同ibbq热量或比当前预测的μbtb102分支更热的所有边缘,这指示此时进入μop高速缓存器取回模式可能是有效益的。也就是说,不太可能立即尝试从未构建边缘的取回。通过要求适合=1的所有ibbq条目也具有等于0的numunbuiltedges[7:0]317,可以使这种情况变得非常保守。稍微更保守的方法可以在能够对给定边缘进入μop高速缓存器取回模式之前,要求从下一最冷条目到最热条目的所有ibbq条目具有等于0的numunbuiltedges[7:0]317。可以通过将allbuilt位添加到ibbq条目来处理时序问题,该位指示关于给定条目的numunbuiltedges[7:0]计数器317何时倒计数到0。
当ibbq303已经确定内核足够小以适合μop高速缓存器103并且又足够热而可重复时,ibbq303可以开始向解码器发出构建消息,以当μop流过管道用于正常执行时捕获一些μop。通常,构建流程可以如下:前端101可以发出带有开始和结束指令指针的构建消息。构建消息可以附加到现有μop高速缓存器行,或使用空闲列表指向新行以开始分配。解码器可以开始捕获μop。当μop高速缓存器行填充时,解码器可以将响应构建行有效(或失败)消息发送到前端101,指示该行中的指令(非μop)端点以及指令尾部的μop是否溢出到另一行。
前端101可以通过在转换μop高速缓存器行标签中标记更新指令分配来更新μop高速缓存器103。如果需要新的空闲列表条目,则将新指针提供给解码器。如果需要,则前端101可以向解码器提供构建行消息的重新响应,用于识别任何顺序指针链更新。解码器可以继续捕获μop,并且前端101可以继续提供重新响应,直到解码器分配所有请求的指令或发生结束/取消/刷新/失败条件为止。
每个条目的可用μop高速缓存器时隙的数量uspeslotsperentry或uspe寄存器305中的uspe值可以用于预测给定程序边缘或基本块是否可以单独适合整个μop高速缓存器103。uspe寄存器305的值可以向下调整,以解决可能导致μop高速缓存器条目使用效率低下的碎片效应。另外,uspe寄存器305的值可以向上调整,以实现条目使用效率的提高,这可能是由于取回模式的变化(导致效率提高)以及在指令空间中重叠的μbtb图表302中的程序边缘,即,μbtb102跟踪的边缘在指令和μop高速缓存器中重叠。这可以通过使用filterbranchcommitcounter[11:0]寄存器来检测例如自上次重新评估uspe值以来何时提交4095个分支来完成。当filterbranchcommitcounter[11:0]寄存器溢出时,可以采用以下步骤:filterbranchcommitcounter寄存器被重置,并且是否μop高速缓存器103的所有条目有效(不是每个条目中的所有时隙,而是所有条目),即,是否μop高速缓存器103已满。如果从μop高速缓存器103完全击中的来自μop高速缓存器103的取回的次数少于例如在被取回使用之前从μop高速缓存器103逐出的μop高速缓存器条目数量的10倍,则如果uspe值尚未达到0则将uspe值递减1。如果在可以使用μop以提供给定取回的所有μop之前逐出太多的μop高速缓存器条目,则这使得uspe寄存器305值更加保守。
如果不是μop高速缓存器103的所有条目都有效的,即存在一个或多个空闲的并且能够被用于容纳更大的程序内核,并且如果从μop高速缓存器103完全击中的来自μop高速缓存器103的取回的次数大于或等于例如在被取回使用μop之前从μop高速缓存器103逐出的μop高速缓存器条目数量的10倍,则如果uspe值尚未饱和则可以将uspe值递增1。这通过扩展可以由μop高速缓存器103覆盖的程序图表的尺寸,使得uspe寄存器305中的值更激进。可以调整uspe寄存器305的大小,使得其可以计数到大于μop缓存器条目中的μop位置数量的值,以解决μop高速缓存器103中重叠的程序边缘。
为了保持ibbq和μbtb一致,每当发生以下事件中的任何时,可以重置ibbq条目,清除ubtb图表link[n|t|seq]tracked312,并且可以将所有μbtb图表link[t|n|seq]weight311(权重)清零:(1)指令高速缓存器行无效;(2)μbtb图表条目从一个条目移动到另一个条目;(3)新分支被添加到μbtb图表302;(4)μbtb图表条目连接到形成新基本块(或程序边缘)的另一个μbtb图表条目,除非写入是对于通过没有误预测其目标的返回写入的调用的μbtb图表seq的链接之外;(5)μbtb图表条目无效。
如本领域技术人员将认识到的,本文描述的创新概念可以在广泛的应用范围内进行修改和变化。因此,要求保护的主题的范围不应限于以上讨论的任何具体示例性教导,而是由所附权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!