一种自动化载波调度系统文件读取方法及装置与流程
本发明涉及数据读取领域,更具体涉及一种自动化载波调度系统文件读取方法及装置。
背景技术:
随着5g时代的到来,移动通信以前所未有的速度发展,各个移动运营商对用户资源的争夺愈加激烈,而网络覆盖、网络容量、网络质量从根本上体现了移动网络的服务水平成为了运营商获取竞争优势的关键因素,同时随着城市移动用户的飞速增加及高层建筑越来越多,话务魔都和覆盖要求也不断上升。几乎所有的城市乡村都存在载频资源的不均衡分布。相同基站不同扇区,不同基站覆盖区域的人群活动特点导致话务高峰出现在不同时间段,突发话务高峰,网络无法满足突发的话务高峰。通常采用的解决方法是通过增加载波数目或多重覆盖等方式来保证小区的网络容量,但是这会导致占用更多的载波资源。智能载波调度系统也即自动化载波调度系统是一种能够有效改善移动网络中蜂窝小区用户不平衡状况的小区资源调度体系。
自动化载波调度系统进行资源调度过程中文件的读取很关键,现有自动化载波调度系统文件读取方案采用dom方式读取基站硬件数据xml文件,辽宁师范大学学报(自然科学版)第26卷第4期公开了《基于dom读取xml文件的方法研究》,由于dom方式对xml文件是一次性全部读取,因此对内存的消耗非常的大。另外,如果xml文件比较大,容易影响读取性能且会造成内存泄漏。
技术实现要素:
本发明所要解决的技术问题在于现有技术自动化载波调度系统文件读取方法及装置存在内存消耗大且容易造成内存泄漏的问题。
本发明通过以下技术手段实现解决上述技术问题的:一种自动化载波调度系统文件读取方法,所述方法包括:
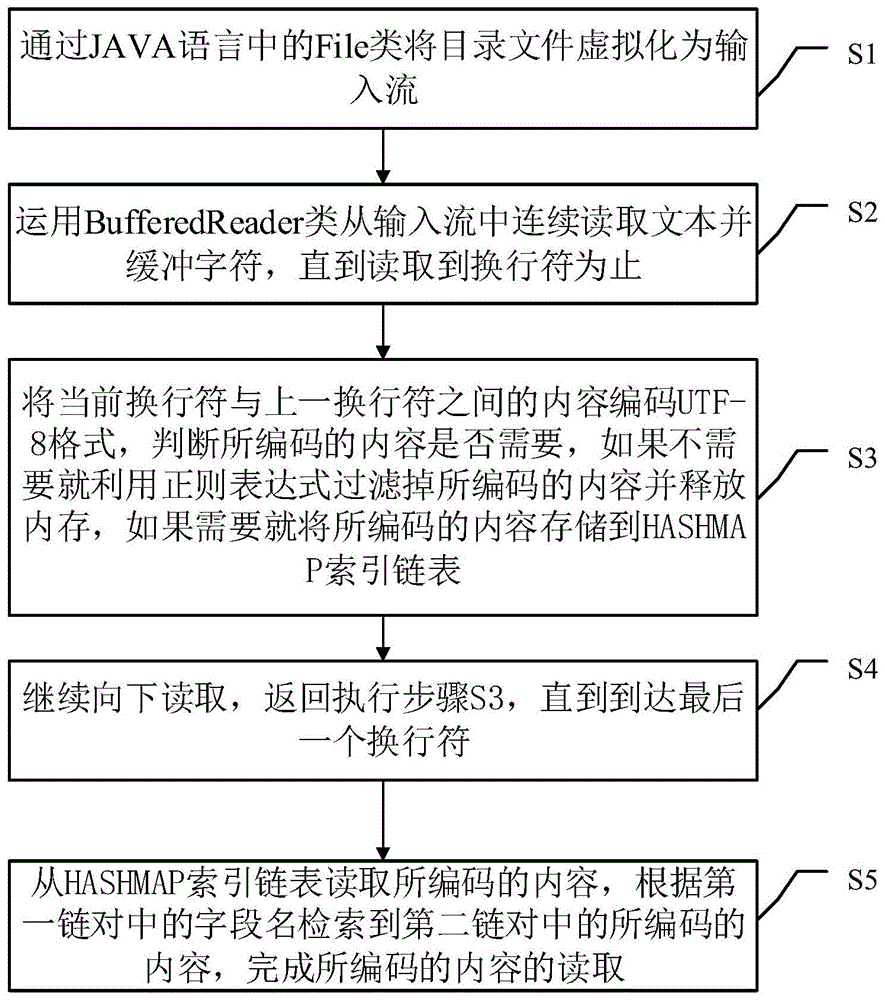
步骤一:通过java语言中的file类将目录文件虚拟化为输入流;
步骤二:运用bufferedreader类从输入流中连续读取文本并缓冲字符,直到读取到换行符为止;
步骤三:将当前换行符与上一换行符之间的内容编码为utf-8格式,判断所编码的内容是否需要,如果不需要就利用正则表达式过滤掉所编码的内容并释放内存,如果需要就将所编码的内容存储到hashmap索引链表;
步骤四:继续向下读取,返回执行步骤三,直到到达最后一个换行符。
本发明根据载波所需数据的必要性,把所需要的文件虚拟化为输入流,从输入流中连续读取文本并缓冲字符,直到读取到换行符为止,从而读取一行处理一行,降低了对内存的消耗,并通过hashmap建立索引的方式,有针对性的读取,不需要全部读取,减少内存损耗,只从大量的参数文件中读取所需的内容进行缓存,不需要的内容丢弃,由此防止全文读取造成的内存泄露。
优选的,所述步骤三中的正则表达式为:若需要获取所编码的内容中含有特定参数符号的节点参数,则对每个节点的首行判断所编码的内容是否有此特定参数符号,如果没有此特定参数符号,则过滤掉所编码的内容并释放内存。
优选的,所述步骤三包括:建立针对字段名和索引的第一链对,建立针对索引和所编码的内容的第二链对;
将字段名作为第一链对的key值,将索引作为第一链对的value值,将索引作为第二链对的key值,将所编码的内容作为第二链对的value值。
优选的,还包括步骤五:从hashmap索引链表读取所编码的内容,根据第一链对中的字段名检索到第二链对中的所编码的内容,完成所编码的内容的读取。
本发明还提供一种自动化载波调度系统文件读取装置,所述装置包括:
虚拟化模块,用于通过java语言中的file类将目录文件虚拟化为输入流;
第一读取模块,用于运用bufferedreader类从输入流中连续读取文本并缓冲字符,直到读取到换行符为止;
判断模块,用于将当前换行符与上一换行符之间的内容编码为utf-8格式,判断所编码的内容是否需要,如果不需要就利用正则表达式过滤掉所编码的内容并释放内存,如果需要就将所编码的内容存储到hashmap索引链表;
第二读取模块,用于继续向下读取,返回执行判断模块,直到到达最后一个换行符。
优选的,所述判断模块中的正则表达式为:若需要获取所编码的内容中含有特定参数符号的节点参数,则对每个节点的首行判断所编码的内容是否有此特定参数符号,如果没有此特定参数符号,则过滤掉所编码的内容并释放内存。
优选的,所述判断模块还用于:建立针对字段名和索引的第一链对,建立针对索引和所编码的内容的第二链对;
将字段名作为第一链对的key值,将索引作为第一链对的value值,将索引作为第二链对的key值,将所编码的内容作为第二链对的value值。
优选的,还包括第三读取模块:从hashmap索引链表读取所编码的内容,根据第一链对中的字段名检索到第二链对中的所编码的内容,完成所编码的内容的读取。
本发明的优点在于:本发明根据载波所需数据的必要性,把所需要的文件虚拟化为输入流,从输入流中连续读取文本并缓冲字符,直到读取到换行符为止,从而读取一行处理一行,降低了对内存的消耗,并通过hashmap建立索引的方式,有针对性的读取,不需要全部读取,减少内存损耗,只从大量的参数文件中读取所需的内容进行缓存,不需要的内容丢弃,由此防止全文读取造成的内存泄露。
附图说明
图1为本发明实施例所公开的一种自动化载波调度系统文件读取方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
如图1所示,一种自动化载波调度系统文件读取方法,所述方法包括:
步骤s1:通过java语言中的file类将目录文件虚拟化为输入流;java文件类以抽象的方式代表文件名和目录路径名。file类主要用于文件和目录的创建、文件的查找和文件的删除等。file对象代表磁盘中实际存在的文件和目录。
步骤s2:运用bufferedreader类从输入流中连续读取文本并缓冲字符,直到读取到换行符为止;bufferedreader类主要作用是从字符输入流中读取文本,缓冲各个字符,从而提供字符、数组和行的高效读取。可以指定缓冲区的大小,或者可使用默认值,大多数情况下,默认值就可以。
步骤s3:将当前换行符与上一换行符之间的内容编码为utf-8格式,判断所编码的内容是否需要,如果不需要就利用正则表达式过滤掉所编码的内容并释放内存,如果需要就将所编码的内容存储到hashmap索引链表;utf-8(8位元,universalcharacterset/unicodetransformationformat)是针对unicode的一种可变长度字符编码。它可以用来表示unicode标准中的任何字符,而且其编码中的第一个字节仍与ascii相容,使得原来处理ascii字符的软件无须或只进行少部份修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中优先采用的编码。
正则表达式,又称规则表达式。(英语:regularexpression,在代码中常简写为regex、regexp或re),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由unix中的工具软件(例如sed和grep)普及开的。本实施例中正则表达式为:若需要获取所编码的内容中含有特定参数符号的节点参数,则对每个节点的首行判断所编码的内容是否有此特定参数符号,如果没有此特定参数符号,则过滤掉所编码的内容并释放内存。实际应用中,根据所需的内容不同,正则表达式也不同。例如,需获取含有“dn=”的节点参数,则对每个节点的首行判断是否有此参数,无则丢弃并释放内存。
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,hashmap也不例外。hashmap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。hashmap基本原理是hashmap在底层将key-value当成一个整体进行处理,这个整体就是一个entry对象。hashmap底层采用一个entry[]数组来保存所有的key-value对,当需要存储一个entry对象时,会根据hash算法来决定其在数组中的存储位置,再根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该entry,其中hash算法、equals方法均属于现有技术。虽然hashmap也占有一定的内存,但是相比本该过滤掉的内容所占的内存较少,占有率不多,所以采用hashmap能够节省内存。
本实施例中,建立针对字段名和索引的第一链对,建立针对索引和所编码的内容的第二链对;
将字段名作为第一链对的key值,将索引作为第一链对的value值,将索引作为第二链对的key值,将所编码的内容作为第二链对的value值。建立第一链对、第二链对通过索引的方法匹配虽然索引也占用一定的存储空间,但是索引的方法属于数字匹配,占用的空间少,而直接采用字段名与所编码的内容匹配需要进行字符匹配,字符匹配占用的空间多并且缺少索引的情况下,字段名以及所编码的内容在hashmap索引链表中的位置难以确定,容易混乱,出现故障,而索引直接对应hashmap索引链表中的位置,能够直接将字段名、所编码的内容在hashmap索引链表中对应起来。
步骤s4:继续向下读取,返回执行步骤s3,直到到达最后一个换行符;
步骤s4之后还包括步骤s5:从hashmap索引链表读取所编码的内容,根据第一链对中的字段名检索到第二链对中的所编码的内容,完成所编码的内容的读取。这一步主要是步骤s4筛选整个文件中需要的内容,将不需要的内容过滤掉以后存储到hashmap索引链表,通过hashmap索引链表将所有需要的内容读取出来。实际应用中也可将步骤s5放在步骤s3后面,在完成一行数据的读取以后,若该行数据为需要的内容则存储到hashmap索引链表,通过hashmap索引链表将该行内容读取出来,继续读取下一行,直到到达最后一行。
通过以上技术方案,本发明提供的一种自动化载波调度系统文件读取方法,根据载波所需数据的必要性,把所需要的文件虚拟化为输入流,从输入流中连续读取文本并缓冲字符,直到读取到换行符为止,从而读取一行处理一行,降低了对内存的消耗,并通过hashmap建立索引的方式,灵活的读取需要的内容,降低了读取文件对内存的消耗,只从大量的参数文件中读取所需的内容进行缓存,不需要的内容丢弃,由此防止全文读取造成的内存泄露。
实施例2
与本发明实施例1相对应的,本发明实施例2本发明还提供一种自动化载波调度系统文件读取装置,所述装置包括:
虚拟化模块,用于通过java语言中的file类将目录文件虚拟化为输入流;
第一读取模块,用于运用bufferedreader类从输入流中连续读取文本并缓冲字符,直到读取到换行符为止;
判断模块,用于将当前换行符与上一换行符之间的内容编码为utf-8格式,判断所编码的内容是否需要,如果不需要就利用正则表达式过滤掉所编码的内容并释放内存,如果需要就将所编码的内容存储到hashmap索引链表;
第二读取模块,用于继续向下读取,返回执行判断模块,直到到达最后一个换行符。
具体的,所述判断模块中的正则表达式为:若需要获取所编码的内容中含有特定参数符号的节点参数,则对每个节点的首行判断所编码的内容是否有此特定参数符号,如果没有此特定参数符号,则过滤掉所编码的内容并释放内存。
具体的,所述判断模块还用于:建立针对字段名和索引的第一链对,建立针对索引和所编码的内容的第二链对;
将字段名作为第一链对的key值,将索引作为第一链对的value值,将索引作为第二链对的key值,将所编码的内容作为第二链对的value值。
具体的,还包括第三读取模块:从hashmap索引链表读取所编码的内容,根据第一链对中的字段名检索到第二链对中的所编码的内容,完成所编码的内容的读取。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!