一种基于孤立森林的消费信贷欺诈行为检测方法及其系统与流程
本发明涉及互联网金融消费信贷行业的风控技术领域,特别涉及一种基于孤立森林的消费信贷欺诈行为检测方法及其系统。
背景技术:
消费信贷行业是互联网金融的重要组成部分,近几年得到了飞速发展,伴随着行业的欣荣发展,欺诈黑色产业链也在不断地渗透到该领域,各种新颖的欺诈手段与方式层出不穷,对消费信贷行业的健康发展蒙上了一层阴影。据不完全统计,每年因欺诈导致的损失可达到500亿—1000亿,欺诈风险已成为消费信贷防范风险的重中之重。
结合统计学,防范欺诈行为主要方法为异常点检测,异常点检测是对异常数据的查找过程,异常数据由于分布稀疏且离密度高的群体较远特点,在检测通过找出明显偏离其他数据或不满足一般对象行为特征的数据,通过对检测出的异常数据进行分析,并挖掘出有意义的潜在信息,能够及时发现各种不正常行为,来降低风险发生概率。目前,异常点检测广泛地应用于诸多领域和场景,包括电信欺诈分析、网络攻击检测、金融贷款及信用卡欺诈检测和医疗疾病诊断等。
消费信贷用户申请欺诈行为属于异常申请,行业一般采用异常点检测的方法来识别申请欺诈行为。传统的异常点检测算法包括:基于线性模型的主成分分析(principalcomponentanalysis,pca)和一类支持向量机(oneclasssvm)算法、基于聚类的k均值聚类(k-means)和dbscan密度聚类算法、基于密度的k最近邻(k-nearestneighbor,knn)和基于相似性的局部异常因子(localoutlierfactor,lof)算法。
传统的异常检测算法主要有以下几个缺陷:
(1)大数据集高维度难处理:当前处理的数据集的数据量更大维度更高,传统异常检测算法未对原始数据集稀疏化处理,在异常数据检测过程中对于正常数据集中的部分多次进行异常检测过程,加大了计算的时间和空间复杂度,不易实现;
(2)模糊化处理鲁棒性低:现有技术在对处于边缘点和两个子空间相交的面上的异常点没有很好地处理,造成将正常数据加入到异常数据集中,很多数据会产生模糊化操作,缺乏具体严谨的异常检测标准,导致鲁棒性和准确性不高;
(3)未做标签化处理:目前消费信贷行业主要采取有监督学习算法对用户的贷款申请进行欺诈检测,但新申请客户一般是没有标签的,只能通过根据用户以往申请行为、埋点操作行为数据、第三方多头借贷、金融逾期数据进行人工标注来检测用户是否有欺诈风险,传统异常检测算法未对数据进行标签化处理,检测效果及效率都比较低,在面对新型欺诈行为识别也比较落后。
面对当今发展迅猛地消费信贷行业和日益变化的欺诈方式,在处理大数据集高维度、无标签的数据问题,亟需一种更加先进高效地异常检测方法用于挖掘出欺诈行为。
孤立森林(isolationforest,简称iforest)是一种基于集成学习的无监督快速异常检测算法,该算法利用一种名为孤立树(isolationtree,简称itree)的二叉搜索树结构来孤立样本,算法步骤为从训练集中进行采样构建itree树,对iforest中的每棵itree进行测试,记录路径长度及平均路径长度,然后根据计算公式得到待检测数据的异常分数,分数越高,异常概率越大。孤立森林算法有如下的优点:
(1)适合高维大数据集:孤立森林吸取了随机森林算法的并行化优点,随机采样一部分数据集生成孤立树,每棵itree构造过程并不受其他树的影响,孤立森林可以称得上是一个非常完美的分布式并行模型,可部署在大规模分布式系统上来加速运算,对内存要求很低,处理速度很快,具有线性时间复杂度和高精准度,能够有效处理高维海量数据,可以用于异常点实时检测,符合大数据处理要求;
(2)准确性和鲁棒性高:孤立森林递归随机分割数据集,直到所有的样本点都是孤立的,在这种随机分割的策略下,异常点通常具有较短的路径,相较于lof、k-means等其他异常点检测算法,孤立森林算法在高维数据上检测异常点有较好的实用性、计算效率、准确率和鲁棒性表现;
(3)无监督快速异常检测:孤立森林是一种无监督学习算法,通过寻找与其他数据最不匹配的实例来检测出来未标记数据的异常,不需要样本标签化处理,当异常数据量太少,只用正常样本构建孤立森林也是可行。
技术实现要素:
为了解决上述技术问题,本发明中披露了一种基于孤立森林的消费信贷欺诈行为检测方法及其系统,本发明的技术方案是这样实施的:
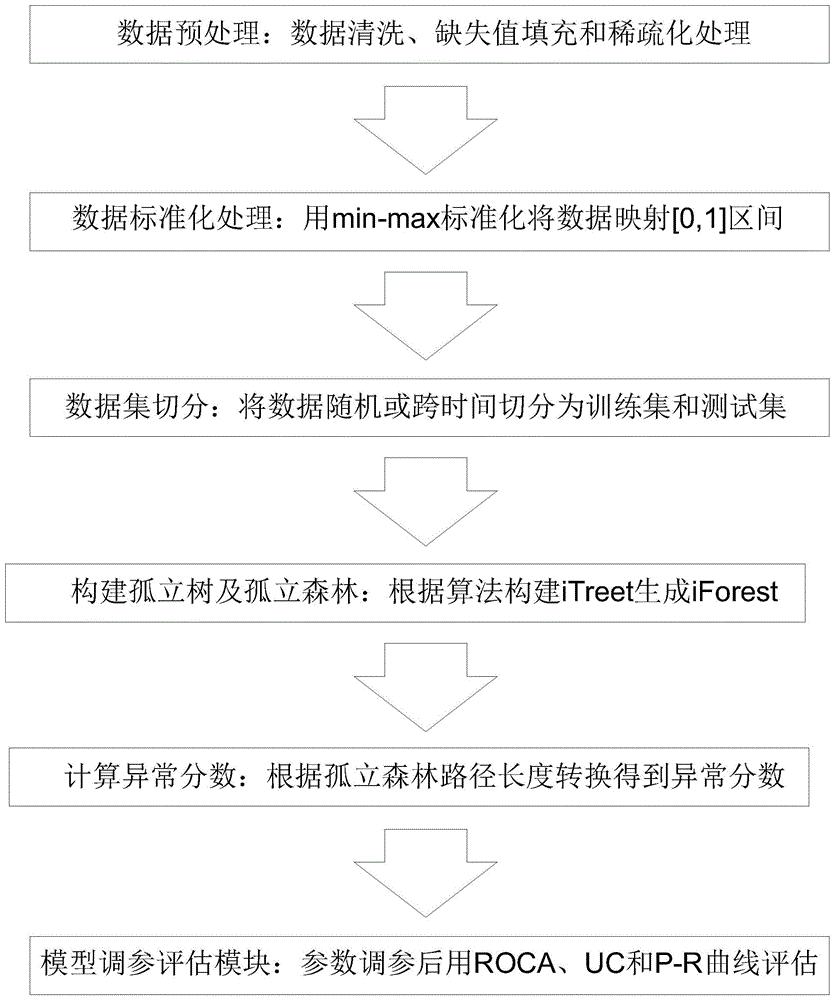
一种基于孤立森林的消费信贷欺诈行为检测方法,包括以下步骤:步骤1:数据预处理:对原始消费信贷申请数据进行预处理,包括数据清洗、缺失值填充和稀疏化处理;步骤2:数据标准化处理:使用min-max标准化将预处理后的每一列数据都映射到[0,1]区间,得到标准化数据集;步骤3:样本集划分:将所述标准化数据集按比例随机或根据样本申请日跨时间划分为训练集和测试集;步骤4:itree生成,包括:步骤4-1:从训练集中随机选择ψ个点样本点作为子样本,放入树的根节点;步骤4-2:随机指定一个维度,在当前节点数据中随机产生一个切割点p,所述切割点p产生于当前节点数据中指定维度最大值和最小值之间步骤4-3,从切割点p生成一个超平面,将当前节点数据空间划分为两个子空间,即当前节点的左孩子和右孩子,把指定维度里小于切割点p的数据放在当前节点的左孩子中,把指定维度里大于或等于切割点p的数据放在当前节点的右孩子中;步骤4-4:重复步骤4-2和步骤4-3,不断构造新的子节点,直到数据本身不可在分或者子节点已经达到限定的高度,生成itree,所述限定的高度指树的深度达到log2ψ;步骤5:构建孤立森林:重复步骤4构建t棵具有差异性的itree后构成iforest模型;步骤6:计算异常分数:将iforest模型应用于测试集上进行测试,令样本数n的任一数据x遍历每一棵itree,得出x在每棵itree的高度平均值,计算每条待测数据的异常分数s(x,n),异常分数s(x,n)计算公式为:
式中,h(x)为叶子节点到根节点的路径长度,c(n)为二叉搜索树的平均路径长度,h(k)为调和,h(k)=in(k)+ξ,ξ是欧拉常数,取值为0.5772156649;当s(x,n)越接近1,表示异常点的可能性越高,消费信贷申请欺诈行为的概率越高;当s(x,n)越接近0,表示正常点的概率越高;根据上述测试结果设定阈值τ,所述阈值τ介于0.5到1之间,若样本的异常分数s(x,n)大于τ则该样本为异常点,反之则该样本为正常点;步骤7:对iforest模型进行调参;步骤8:模型评估:运用测试集并采用roc、auc与p-r曲线对iforest模型效果评估。
进一步地,所述数据清洗包括:对数据进行描述性统计,将数据的类型划分为连续型和离散型,删除异常数据,保持数据集的完整性;所述缺失值填充包括:采用均值插补的方法填充缺失值,或者采用随机森林算法构造决策树对缺失值预测插补;所述稀疏化处理包括:对于较多变量的稀疏的数据采用k-means算法进行聚类,可减少计算的时间和空间复杂度。
进一步地,步骤7中所述调参的参数包括n_estimators、max_samples、max_features,所述n_estimators指配置itree的个数t,默认为100,所述max_samples指构建每棵itree的训练样本个数,默认为265;所述max_features指每棵itree的最大特征数,默认为全部特征,但对于高维数据,只选取部分特征。
一种基于孤立森林的消费信贷欺诈行为检测系统,包括:信息采集模块:用于获取申请人的信贷申请数据、申请用户app操作埋点的行为特征信息以及授权的第三方数据,所述操作埋点的行为特征信息包括:登录本平台的次数、点击次数、点击频率、输入总耗时及平均耗时等信息等,设备信息包括:手机号数据、gps位置、mac地址、ip地址数据、地理信息申请频次、ip的申请频次、设备电量占比、陀螺仪的平均加速度等,对提取的数据进行数字化处理;数据预处理模块:对获数据变量进行描述性统计,删除异常数据,用均值或者随机森林算法插补缺失值;数据标准化及数据切分模块:使用min-max标准化的方法对原始数据的线性变换,将处理后的标准化数据按比例随机或根据样本申请日期跨时间划分训练集和测试集;孤立树及孤立森林构建模块:从训练集中进行采样根据孤立树算法流程构建孤立树itree,重复构建具有差异性的t棵itreet组成孤立森林iforest;异常评分计算模块:计算每个待检测申请用户数据在孤立森林模型中的路径长度,得到申请用户的异常分数,取出异常评分接近1的用户标记为高风险异常申请用户,结合申请人过往的申请特征及第三方数据判定是否存在欺诈行为,其余异常分数区间在(0.5,1)的用户标注为中风险,在(0,0.5)的用户标注为低风险,结合申请人的贷后表现来调整重置风险级别的阈值,当异常评分达到高风险异常申请用户的预设阈值时,判定为异常申请;模型效果调参及评价模块:对n_estimators、max_samples及max_features参数调参优化模型效果,通过roc、auc和p-r曲线来评估孤森林模型的检测效果,并对进行预处理和标准化处理后的数据用其他异常检测算法结果对比。
实施本发明的技术方案可解决现有技术中传统的异常检测算法鲁棒性和准确性不高、检测效果及效率都比较低等的技术问题;本发明的技术方案,将孤立森林算法与互联网金融的消费信贷场景相结合,孤立森林根据自身的算法优越性能够更好解决高维大数据集异常点检测鲁棒性及准确率低的问题,提升了对欺诈行为的识别效果和效率,相对于传统的消费信贷欺诈行为检测方法,本发明在准确率、计算复杂度、通用性等指标上的表现也更加优秀,能够有效处理高维海量数据,有能力识别消费信贷中变种和从未见过的欺诈行为,更加适合当前大数据风控的需求。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一种实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明检测方法流程图;
图2为本发明检测系统图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于孤立森林的消费信贷欺诈行为检测方法,如图1所示,包括以下步骤:步骤1:数据预处理:对原始消费信贷申请数据进行预处理,包括数据清洗、缺失值填充和稀疏化处理;步骤2:数据标准化处理:使用min-max标准化将预处理后的每一列数据都映射到[0,1]区间,得到标准化数据集;步骤3:样本集划分:将所述标准化数据集按比例随机或根据样本申请日跨时间划分为训练集和测试集;步骤4:itree生成,包括:步骤4-1:从训练集中随机选择ψ个点样本点作为子采子样本,放入树的根节点;步骤4-2:随机指定一个维度,在当前节点数据中随机产生一个切割点p,所述切割点p产生于当前节点数据中指定维度最大值和最小值之间步骤4-3,从切割点p生成一个超平面,将当前节点数据空间划分为两个子空间,即当前节点的左孩子和右孩子,把指定维度里小于切割点p的数据放在当前节点的左孩子中,把指定维度里大于或等于切割点p的数据放在当前节点的右孩子中;步骤4-4:重复步骤4-2和步骤4-3,不断构造新的子节点,直到数据本身不可在分或者子节点已经达到限定的高度,生成itree,所述限定的高度指树的深度达到log2ψ;步骤5:构建孤立森林:重复步骤4构建t棵具有差异性的itree后构成iforest模型;步骤6:计算异常分数:将iforest模型应用于测试集上进行测试,令样本数n的任一数据x遍历每一棵itree,得出x在每棵itree的高度平均值,计算每条待测数据的异常分数s(x,n),异常分数s(x,n)计算公式为:
式中,h(x)为叶子节点到根节点的路径长度,c(n)为二叉搜索树的平均路径长度,h(k)为调和数,h(k)=in(k)+ξ,ξ是欧拉常数,取值为0.5772156649;当s(x,n)越接近1,表示异常点的可能性越高,消费信贷申请欺诈行为的概率越高;当s(x,n)越接近0,表示正常点的概率越高;根据上述测试结果设定阈值τ,所述阈值τ介于0.5到1之间,若样本的异常分数s(x,n)大于τ则该样本为异常点,反之则该样本为正常点;步骤7:对iforest模型进行调参;步骤8:模型评估:运用测试集并采用roc、auc与p-r曲线对iforest模型效果评估。
一种基于孤立森林的消费信贷欺诈行为检测系统,如图2所示,包括:信息采集模块:用于获取申请人的信贷申请数据、申请用户app操作埋点的行为特征信息以及授权的第三方数据,所述app操作埋点的行为特征信息包括:登录本平台的次数、点击次数、点击频率、输入总耗时及平均耗时等信息等,同时还可以获取用户的设备信息,包括手机号数据、gps位置、mac地址、ip地址数据、地理信息申请频次、ip的申请频次、设备电量占比、陀螺仪的平均加速度等,对提取的数据进行数字化处理;数据预处理模块:对获数据变量进行描述性统计,删除异常数据,用均值或者随机森林算法插补缺失值;数据标准化及数据切分模块:使用min-max标准化的方法对原始数据的线性变换,将处理后的标准化数据按比例随机或根据样本申请日期跨时间划分训练集和测试集;孤立树及孤立森林构建模块:从训练集中进行采样根据孤立树算法流程构建孤立树itree,重复构建具有差异性的t棵itreet组成孤立森林iforest;异常评分计算模块:计算每个待检测申请用户数据在孤立森林模型中的路径长度,得到申请用户的异常分数,取出异常评分接近1的用户标记为高风险异常申请用户,结合申请人过往的申请特征及第三方数据判定是否存在欺诈行为,其余异常分数区间在(0.5,1)的用户标注为中风险,在(0,0.5)的用户标注为低风险,结合申请人的表现来调整重置风险级别的阈值,当异常评分达到高风险异常申请用户的预设阈值时,判定为异常申请;模型效果调参及评价模块:对n_estimators、max_samples及max_features参数调参优化模型效果,通过roc、auc和p-r曲线来评估孤森林模型的检测效果,并对进行预处理和标准化处理后的数据用dbscan、lof、oneclasssvm等其他异常检测算法结果对比。
实施该实施例,将孤立森林算法与互联网金融的消费信贷场景相结合,孤立森林根据自身的算法优越性能够更好解决高维大数据集异常点检测鲁棒性及准确率低的问题,提升了对欺诈行为的识别效果和效率,相对于传统的消费信贷欺诈行为检测方法,本发明在准确率、计算复杂度、通用性等指标上的表现也更加优秀,能够有效处理高维海量数据,有能力识别消费信贷中变种和从未见过的欺诈行为,更加适合当前大数据风控的需求。
在一种优选的实施方式中,结合图1所示,所述数据清洗包括:对数据进行描述性统计,将数据的类型划分,删除异常数据,保持数据集的完整性;所述缺失值填充包括:采用均值插补的方法填充缺失值,或者采用随机森林算法构造决策树对缺失值预测插补;所述稀疏化化处理包括:对于较多变量的稀疏数据采用k-means算法进行聚类,可减少计算的时间和空间复杂度。
在该实施例中,所述异常数据包括离散型、格式内容错误行、无关数据列和数据集中的冗余等。
在一种优选的实施方式中,结合图1所示,步骤7中所述调参的参数包括n_estimators、max_samples、max_features,所述n_estimators指配置itree的个数t,默认为100,所述max_samples指构建每棵itree的训练样本个数,默认为265;所述max_features指每棵itree的最大特征数,默认为全部特征,但对于高维数据,只选取部分特征。
需要指出的是,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!