一种基于深度学习的路牌文本检测与识别算法的制作方法
本发明属于计算机视觉
技术领域:
,具体涉及一种基于深度学习的路牌文本检测与识别算法。
背景技术:
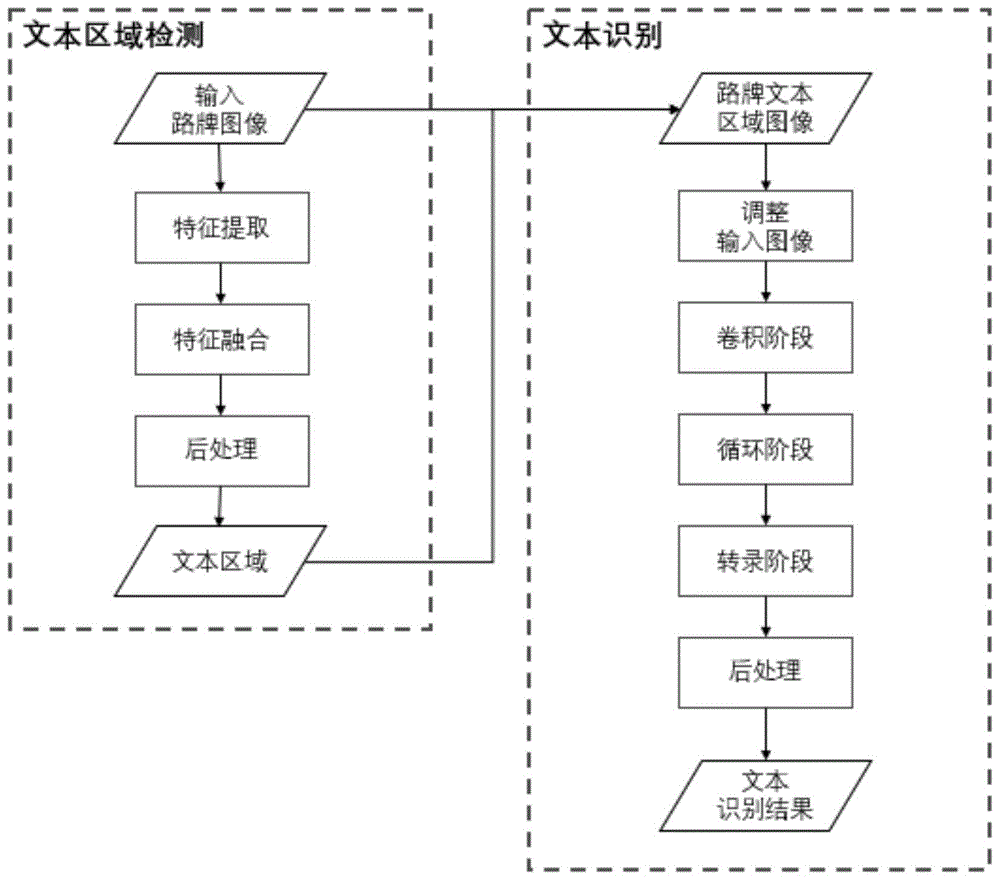
:路牌作为道路信息的载体和生活中常见的标识,对汽车驾驶员来说至关重要。现代化城市的飞速发展使得各种不同类型的道路数量大幅上升,各种带有文字信息的路牌也越来越多。随着科技进步,有着广阔前景的智能交通系统应运而生,路牌文本检测与识别是智能交通系统的重要一环。一个效果好的路牌文本检测与识别方法可以帮助汽车驾驶员提前关注路况信息,这样可以大大提高交通运输效率,降低交通事故的发生率。深度学习作为人工智能领域一个重要的分支和研究热点,最近越来越多地受到学者和研究人员们的青睐,深度学习技术在计算机视觉、自然语言处理、语音识别和跨模态等领域已经有了突破性的进展。自然场景中的文本检测与文本识别作为计算机视觉领域的重要子问题,近些年来得到了广泛地发展。目前大多数自然场景下的文本检测和文本识别方法都是基于深度学习技术的,但是针对路牌文本检测与识别的研究却不多,并且也缺乏公开数据集。有学者和研究人员提出了一些多阶段的方法,该类方法首先使用颜色空间转换和阈值法等算法提取路牌区域,然后经过二值化算法提取路牌中的文本区域。但是这些方法只能处理简单场景下的路牌图像,比如路牌颜色单一或者光照条件良好的情况,在面对复杂自然场景下的路牌图像时效果不佳。另外,多阶段的处理过程会使整个流程变得繁琐,并且每个阶段的结果高度依赖与前一阶段的处理结果,最终结果的稳定性也较差。技术实现要素:针对以上问题,本发明提出了一种基于深度学习的路牌文本检测与识别算法,该算法不对路牌区域进行提取而是直接对输入图像进行路牌文本检测,然后再对检测到的文本区域进行文本识别。该算法能够很好的处理自然场景下的路牌图像,提升了路牌文本检测与识别的性能。本发明的技术方案具体介绍如下。本发明提供一种基于深度学习的路牌文本检测与识别算法,其分为两个处理阶段:文本区域检测阶段和文本识别阶段;其中:文本区域检测阶段,首先将文本区域检测作为一个实例分割问题来解决,一个文本区域就是一个文本实例,利用改进的vgg16网络提取输入图像的图像特征,然后将提取的图像特征经过多个步骤的特征融合得到实例分割结果,最后对分割结果进行处理得到检测的文本区域;文本识别阶段,首先将文本区域检测阶段的结果作为输入,经过文本识别网络获取文本识别结果,然后再基于规则对文本识别的结果进行过滤,得到最终的文本识别结果;所述文本识别网络由三个子阶段组成,分别是卷积阶段、循环阶段和转录阶段,卷积阶段利用卷积神经网络cnn来提取输入图像的特征序列,循环阶段利用双向lstm网络根据特征序列预测文本概率分布,转录阶段对文本概率分布进行整合并翻译成文本识别结果。优选的,文本区域检测阶段中,特征融合包括上采样和融合两个过程,上采样过程采用双线性插值的方式,融合过程采用加和的方式;在特征融合之后输出实例分割结果,实例分割结果包括文本/非文本预测结果和连接关系预测结果。优选的,文本区域检测阶段中,对分割结果进行处理得到检测的文本区域的具体步骤如下:①如果一个像素在文本/非文本结果图上预测为正,而且在某个方向上和相邻像素的连接关系预测也为正,那就把它们连接起来;根据这个规则处理所有的像素,得到很多连通分量,每一个连通分量代表一个预测的文本实例。②利用opencv的minarearect函数处理每一个连通分量,得到该连通分量的最小边界框,该边界框为矩形框;③将任意边长长度小于15像素的矩形框和面积小于400像素平方的矩形框过滤掉。优选的,文本识别阶段中,输入文本识别网络前,将文本区域检测阶段获得的文本区域对应的图像转化为灰度图像,然后采用双线性插值法将图像等比缩放,优选的,文本识别阶段中,转录阶段对文本概率分布进行整合并翻译成文本识别结果的具体方法如下:①找到概率分布矩阵中每一列概率取最大值的所在行数,然后到文本序列中查找该行数对应的文本,文本序列即为所有可识别文本加上空白字符“-”构成的序列,由此就得到了循环阶段预测的文本;②将预测的文本中连续重复文本变为一个单独的文本;③将所有的“-”去除得到最终的预测文本。优选的,文本识别阶段中,对文本识别的结果进行过滤基于的规则如下:①识别结果字符长度不超过25个字符,其中一个汉字为两个字符,一个英文字母或者一个标点符号为一个字符;②识别结果不能只由数字或标点符号构成;③如果识别结果中50%以上的字符为英文字符,则不允许汉字出现,允许标点符号和数字出现;④如果识别结果中50%以上的字符为中文字符,则不允许出现多个英文字符,允许标点符号、数字和单一英文字符出现;⑤识别结果中不能出现车牌号格式。和现有技术相比,本发明的有益效果在于:本发明的算法简单,将多阶段任务简化为两阶段任务,能基于一张含有路牌区域的图像,直接检测出图像中路牌的文本区域并且识别出文本信息;该算法能够很好的处理自然场景下的路牌图像,在公开数据集上取得了较好的结果。附图说明图1是本发明的一种基于深度学习的路牌文本检测与识别算法的流程框图。图2是文本区域检测网络结构图。图3是文本识别网络结构图。具体实施方式下面结合附图和实施例对本发明的技术方案进行详细阐述。本发明提出的基于深度学习的路牌文本检测与识别算法,如图1所示,分为两个处理阶段:文本区域检测阶段和文本识别阶段。文本区域检测阶段将文本区域检测作为一个实例分割问题来解决,一个文本区域就是一个文本实例。该阶段首先利用改进的vgg16网络提取图像特征,然后将提取的图像特征经过多个步骤的特征融合得到实例分割结果,最后对分割结果进行处理得到检测的文本区域。文本识别阶段先经过文本识别网络获取文本识别结果,然后再基于规则对文本识别的结果进行过滤。其中文本识别网络由三个子阶段组成,分别是卷积阶段、循环阶段和转录阶段。卷积阶段利用卷积神经网络来提取输入图像的特征序列,循环阶段利用双向lstm网络根据特征序列预测文本概率分布,转录阶段对文本概率分布进行整合并翻译成文本识别结果。一、文本区域检测阶段,具体步骤为:(1)准备一张输入图像,将其输入到文本检测网络,通过该网络来获取文本/非分文本预测结果以及像素连接预测结果。整个文本检测网络分为两个过程:特征提取和特征融合。网络结构如图2所示。其中上面一部分属于特征提取阶段,特征提取阶段采用改进的vgg16网络,特征提取阶段的具体参数如表1所示。表1特征提取网络结构特征提取过程中,五个卷积阶段的卷积核大小都为3×3,在卷积阶段之后都会有一个步长为2的最大池化层,经过最大池化(maxpooling)后特征图的分辨率会缩小为原来的1/4,然后再进行下一阶段的卷积操作。在最后一个卷积阶段后的最大池化层步长设为1,特征图分辨率与上一阶段保持一致,然后再用7×7的卷积核进行卷积。特征融合主要分为上采样和融合两个过程,上采样过程采用双线性插值(bilinearinterpolation)的方式,融合过程采用加和(add)的方式。在特征融合之后使用2个1×1的卷积核输出文本/非文本预测结果和连接关系预测结果。文本/非文本区域预测结果为1个1280*1280的矩阵,表示原图上每一个像素点有一个预测结果。预测结果大于等于0.5的像素为文本区域,称这些像素为正像素,反之则为非文本区域,称为负像素。连接关系预测结果为8个1280*1280的矩阵,表示每个像素和相邻的八个像素点间均有一条连接,每个矩阵分别表示一个方向的连接关系,八个特征图的连接方向依次为:top-left,top,top-right,left,right,bottom-left,bottom,bottom-right。针对每一条连接,如果其相连的两个像素包含一个及以上的正像素,那么该连接称之为正连接,其值为1,反之则称之为负连接,其值为0。(2)对文本检测网络预测到的结果进行后处理,来获得路牌文本区域。具体可以分为三个步骤:①如果一个像素在文本/非文本结果图上预测为正,而且在某个方向上和相邻像素的连接关系预测也为正,那就把它们连接起来。根据这个规则处理所有的像素,得到很多连通分量,每一个连通分量代表一个预测的文本实例。②利用opencv的minarearect函数处理每一个连通分量,得到该连通分量的最小边界框,该边界框为矩形框。③将任意边长长度小于15像素的矩形框和面积小于400像素平方的矩形框过滤掉。路牌文本检测网络的损失函数由两个部分组成,一个是像素分类损失lpixel,另一个是连接关系分类损失llink。损失函数定义如公式(1)所示,其中λ值设置为2.0。像素分类损失如公式(2)所示,其中r值设置为3.0,s为所有文本实例的像素个数,lpixel_ce为像素交叉熵损失。lpixel_ce如公式(3)所示,其中i和j分别表示图像的行和列,wi,j表示该像素的权重,其值为1/该像素所属实例的面积,所有的负样本属于同一个实例,yi,j表示该像素的实际类别,如果该像素为正像素取值为1,为负像素取值为0,p(xi,j)表示该像素的预测概率值。连接关系损失如公式(4)所示,其中llink_pos为正连接损失,llink_neg为负连接损失,wlink_pos为正连接权重,wlink_neg为负连接权重,r值设置为3.0。公式(5)和公式(6)中,i和j分别表示图像的行和列,k表示像素的第k个邻居,wi,j为像素的权重,其值与公式(3)中的wi,j一致,y(i,j,k)为该像素与其第k个邻居的实际连接关系,p(xi,j,k)表示预测的连接关系。llink_poss如公式(7)所示,其中llink_ce为连接交叉熵损失,llink_ce如公式(9)所示。l=λlpixel+llink(1)lpixel_ce=-∑i∑jwi,j(yi,jlog(p(xi,j))+(1-yi,j)log(p(xi,j)))(3)wlink_pos(i,j,k)=wi,j*(y(i,j,k)==1)(5)wlink_neg(i,j,k)=wi,j*(y(i,j,k)==0)(6)llink_pos=wlink_pos(i,j,k)llink_ce(7)llink_neg=wlink_neg(i,j,k)llink_ce(8)llink_ce=-∑i∑j∑k(y(i,j,k)log(p(xi,j,k))+(1-y(i,j,k))log(p(xi,j,k)))(9)二、文本识别阶段,具体步骤为:(1)首先将文本区域对应的图像转化为灰度图像,然后采用双线性插值法将图像等比缩放,缩放后的图像高度为32像素。(2)将灰度图像输入到文本识别网络,通过该网络来获取文本的识别结果。该网络由三个阶段组成,分别为卷积阶段、循环阶段和转录阶段。网络结构如图3所示,该网络具体参数如表2所示。表2路牌文本识别网络参数表卷积阶段的主要任务是利用卷积神经网络(cnn)提取输入图像的特征得到特征图。将特征图中的每一列作为一个特征得到一个特征序列,然后把该特征序列作为循环阶段的输入。循环阶段采用两个双向的lstm(longshort-termmemory)结构,预测特征序列中每一个特征向量的文本概率分布,最终得到一个概率分布矩阵。转录阶段整合并翻译文本概率分布矩阵,得到最终的识别结果。具体做法为如下三个步骤:①找到概率分布矩阵中每一列概率取最大值的所在行数,然后到文本序列中查找该行数对应的文本,文本序列即为所有可识别文本加上空白字符“-”构成的序列,由此就得到了循环阶段预测的文本。②将预测的文本中连续重复文本变为一个单独的文本,如将“aaa-b”变为“a-b”。③将所有的“-”去除得到最终的预测文本。(3)最后去掉不满足以下五条规则的文本识别结果,得到最终的识别结果。具体规则如下:①识别结果字符长度不超过25个字符(其中一个汉字为两个字符,一个英文字母或者一个标点符号为一个字符)。如“上海浦东新区国家级野生动物园”,有14个汉字,28个字符,不满足该规则。②识别结果不能只由数字或标点符号构成。如“123.”,不满足该规则。③如果识别结果中50%以上的字符为英文字符,则不允许汉字出现,允许标点符号和数字出现。如“shanghai路”,不满足该规则。④如果识别结果中50%以上的字符为中文字符,则不允许出现多个英文字符,允许标点符号、数字和单一英文字符出现。如“祖冲之road”,共有10个字符,汉字占6个,出现了4个英文字符,不满足该规则。⑤识别结果中不能出现车牌号格式。如“沪a12345”,不满足该规则。文本识别网络的损失函数定义如公式(10)所示。其中x={(ii,li)}1n表示训练集,ii表示训练集中的图像,li表示第i个样本真实标签序列,y为第i个样本预测的概率分布矩阵,p(li|yi)如公式(11)所示。π是一个字符序列,b(π)表示对字符序列π执行如上转录阶段的三步操作,b(π)=l表示π经过转录阶段能够变成l。p(π|y)为预测出该字符序列的概率,其具体结果为每一个字符概率的乘积,如公式(12)所示,其中表示概率分布矩阵第i列中文本πi的概率。p(l|y)=∑π:b(π)=lp(π|y)(11)实施例1一、实验数据集构建了路牌文本检测数据集(简称tstd数据集)和路牌文本识别数据集(简称tstr数据集)用于实验。下面详细描述数据集的构建情况。(1)tstd数据集tstd数据集一共包含11000张图像,其中训练集10000张,测试集1000张。采用智能手机在行驶的汽车内拍摄了2000张原始图像,图像大小均为1280×1280。将2000张原始图像平均分为两部分,分别作为训练集和测试集。对训练集的1000张原始图像采用一系列图像变换方法得到扩充图像9000张。采用的路牌图像包含了不同的路牌背景颜色和文字颜色组合方式,具体组合方式如表3所示。同时为了考虑光照强度的影响,采用的路牌图像拍摄时间段包含了一天内所有的时间段。除此之外,还考虑了车辆牌照和路标等非路牌文本区域的干扰。表3路牌背景颜色和文字颜色种类及使用场景在进行数据增强在扩充数据集时,采用了如下五种数据增强的方法:·模糊:对图像进行两种不同程度的模糊操作,每张图像产生两张新图像·亮度调整:分别将图像亮度调高和调低,每张图像产生两张新图像·对比度调整:分别将图像对比度增强和降低,每张图像产生两张新图像·饱和度调整:分别将图像饱和度增强和降低,每张图像产生两张新图像·锐度增强:将图像锐度增强,每张图像产生一张新图像(2)tstr数据集tstr训练集一共包含100.5万张图像,其中训练集100万张,测试集5000张。生成训练集图时选取了3000个常用汉字、26个英文字母(包含大小写)、10个阿拉伯数字和常用标点符号。tstr训练集构建参数如表4所示。测试集图像通过对tstd测试集进行图像截取得到。表4tstr训练集构建参数二、模型训练使用tstd数据集训练路牌文本区域检测模型,训练时将所有训练集图像的尺寸统一调整为512×512,在前100次迭代中将学习率设置为0.001,100次迭代之后将学习率设置为0.01,batchsize设置为32,共进行10万次迭代。使用tstr数据集训练路牌文本识别模型,训练时将所有图像转变为灰度图,然后图像的高度调整为32,将学习率设置为0.0001,batchsize设置为32,共进行30万次迭代。三、实验结果对多阶段方法和本文的两阶段方法分别在tstd测试集上进行实验,其中多阶段方法的识别过程使用本文路牌文本识别方法,实验结果如表5所示。从表中可以看出,本文方法在tstd测试集上的表现明显要优于多阶段方法。表5本文方法和多阶段方法在tstd测试集上的实验结果方法准确率召回率f1-score平均识别准确率多阶段方法89.162.773.683.9本文方法92.394.893.595.8选取east[1]和seglink[2]两个主流的文本检测方法与本文提出的路牌文本区域检测方法在tstd数据集上进行了对比实验,实验结果如表6所示。可以看出,本文方法在tstd测试集上的性能要优于seglink和east两个文本检测方法,充分验证了本文基于实例分割的路牌文本检测方法的优势。表6本文方法和两个主流文本检测方法在tstd测试集上的实验结果方法精确率召回率f1-scoreseglink85.786.686.1east89.493.191.2本文方法92.394.893.5选取dsol[3]和rtw[4]两个主流的文本识别方法和本文提出的文本识别方法在tstr数据集上进行对比实验,实验结果如表7所示。可以看出,本文方法在tstr测试集上的效果要优于dsol和rtw两个文本识别方法。表7本文方法和两个主流文本识别方法在tstr数据集上的实验结果方法平均识别准确率dsol96.6rtw97.5本文方法98.2参考文献:[1]zhoux,yaoc,wenh,etal.east:anefficientandaccuratescenetextdetector[j].2017.[2]shib,baix,belongies.detectingorientedtextinnaturalimagesbylinkingsegments[j].2017.[3]jaderbergm,simonyank,vedaldia,etal.deepstructuredoutputlearningforunconstrainedtextrecognition[j].eprintarxiv,2014,24(6):603–611.[4]jaderbergm,simonyank,vedaldia,etal.readingtextinthewildwithconvolutionalneuralnetworks[j].internationaljournalofcomputervision,2016,116(1):1-20.当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1