一种氢负荷预测方法与流程
本发明涉及一种氢负荷预测方法。
背景技术:
近年来,随着化石能源日渐枯竭,世界各国都不约而同的将目光转向新能源。然而,随着越来越多的可再生能源电场建成,可再生能源装机容量不断攀升,部分地区可再生能源装机容量占到本地区总装机容量的一半以上,本地消纳能力有限、外送通道制约等问题导致弃风弃光量居高不下。采用可再生能源电解制氢是一种有前途的大规模制氢方法,由于间歇性可再生能源的波动性,电网并不能完全接纳这类发电机组发出的电能,相当一部分电能被直接浪费了。从经济角度来看,这部分电能是近乎免费的。电解制氢技术发展较为成熟,主要缺陷就在于电费支出导致的高昂制氢成本,如果利用间歇性可再生能源过剩的电能电解制氢,制氢成本将大大下降。
氢气的应用领域很广,广泛用于生产合成氨、甲醇以及石油炼制等工业领域。此外,在供热、交通运输领等域额对氢气的需求也十分巨大。我国氢气的需求量巨大。
技术实现要素:
本发明的目的在于克服现有技术的上述缺点,针对未来社会中氢能在工业、供热、交通等领域的需求,提出一种氢负荷预测的方法。
提出一种氢负荷预测方法。
本发明氢负荷预测方法步骤如下:
1、首先,从中国统计年鉴获得工业领域石油裂化、合成氨、制甲醇、煤制气和还原铁等产品以月份为单位的产量时间序列,通过查找文献得到各产品需氢量的经验参数,进而得到各产品的月需氢量时间序列,采用svm回归算法对工业领域对氢能的需求进行预测,建立数学预测模型;
2、其次,从中国统计年鉴获得供热领域以月份为单位的时间序列的城市天然气需求量,查找外文文献获得国外天然气掺氢比,采用改进的灰色预测方法,结合新陈代谢方法进行新旧数据替换,构建天然气中掺氢量的数学预测模型;
3、再次,从中国统计年鉴获得传统公共汽车和私家车的以月为时间序列的销售数量,采用改进的灰色预测方法构建传统公共汽车和私家车的数学预测模型;从中国统计年鉴获得氢能公共汽车和私家车当月的销售数量,采用类比方法获得氢能汽车的数学预测模型,考虑到政策鼓励与技术进步给该数额学模型乘以一个修正系数,通过文献查找氢能汽车的年行驶里程和百公里行驶里程耗油量,最终可以获得交通领域氢能需求的数学预测模型。
4、最后,将得到的三种氢负荷预测叠加,构建氢负荷的数学预测模型。
各步骤具体说明如下:
所述的步骤1建立的工业领域的氢负荷需求数学预测模型;
f:rn→r(2)
yi=f(xi)(i=1,···i)(3)
上式(1)中,q1为工业领域的氢负荷预测,he为核函数,b为阈值,b∈r,r为负荷预测值,ai为上支持矢量
上式(2)中,f为函数映射,rn即为影响负荷预测的因素,为负荷的趋势分量和周期分量;r为负荷预测值;
上式(3)中,i为训练样本个数。xi为第i个训练样本,yi为第i个输出值,i为训练样本序数;
上式(4)中,yt为t月负荷观测值;t为序列长度,n为观测数据序列年份个数,且有关系为t=12n;gt为t月负荷观测值的趋势分量;ht为t月负荷观测值的周期分量;et是均值为零的随机噪声,包括测量噪声或模型误差,对于含有趋势性和季节变化规律的负荷模型;
上式(5)中,表示以12为周期,以t为中心的2阶滑动平均数字滤波,经过数字滤波后,不再含有周期分量,j为月份序数,yt+j为t+j月负荷观测值,yt+j+1为t+j+1月负荷观测值;
s.t.((ω·xi)+b)-yi≤ε+ξi(7)
yi-((ω·xi)+b)≤ε+ξi(8)
ξi≥0,ε≥0(9)
上式(6)~(14)中,rn为影响负荷预测的因素,r为负荷预测值,ω为权重,ω∈rn:x为样本输入值,x∈rn:b为阈值,b∈r,c为用来平衡模型复杂性项||ω||2/2的权重参数,v为用来平衡模型训练误差项的权重参数,l为训练样本个数,ε为不敏感损失函数,ξ为上松弛因子,
为了最小化式(6),需要求出式(10)的鞍点,即变量ω,ε,b,ξ,
2、所述的步骤2建立的供热领域的氢负荷需求的数学预测模型:
q2=x(0)(k+1)(15)
x(0)(k+1)=x(1)(k+1)-x(1)(k)(16)
上式(15)~(17)中,q2为供热领域的氢气预测量,k为月份数,x(1)(k+1)为第k+1个累加数据,x(1)(k)为第k个累加数据,a为发展灰数,c为内生控制灰数,x(0)(k+1)即为预测量;
式(17)为建立的预测模型;
式(18)中,i为月份序数,x(0)(i)为第i月负荷观测值,其依次累加得到新的数据序列
上式(21)~(22)中,n为原始数据建模个数,ri为经验比值,x(1)(i)为第i个累加数据,x(1)(i+1)为第i+1个累加数据;
上式(23)~(24)中,a为参数列,a为发展灰数,c为内生控制灰数,采用最小二乘法进行参数估计,b为累加矩阵,bt为累加矩阵转置,yn为数据向量;
考虑信息优先原则,将得到的预测数据x(1)(k+1)依次替换公式(18)中的原始数据x(1)(1),但要保持公式(18)的数据维度,利用新的数据信息构建新的gm(1,1)模型,得出后一年的数据信息,反复重复此步骤直到预测结束,反复迭代过程中建立的模型为新陈代谢模型。
3、所述的步骤3建立的交通领域的氢负荷需求的数学预测模型为:
j为氢能汽车种类数量,j为氢能汽车种类序数;βj第j种汽车百公里耗氢量,单位为l/100km;δj为第j种氢能汽车年行驶里程,单位为km;ρ为修正系数;g为氢能汽车月销售量增长率;nj为第j种氢能汽车月销售量;n为传统汽车月销售数量;g为采用灰色预测法测算的传统汽车月销售量增长速率;
4、所述步骤4,将得到的四种氢负荷预测叠加,构建氢负荷预测的数学预测模型为:
q=q1+q2+q3(27)
上式中,q为总的氢负荷预测;q1为工业领域的氢负荷预测;q2为供热领域的氢负荷预测;q3为交通领域的氢负荷预测。
附图说明
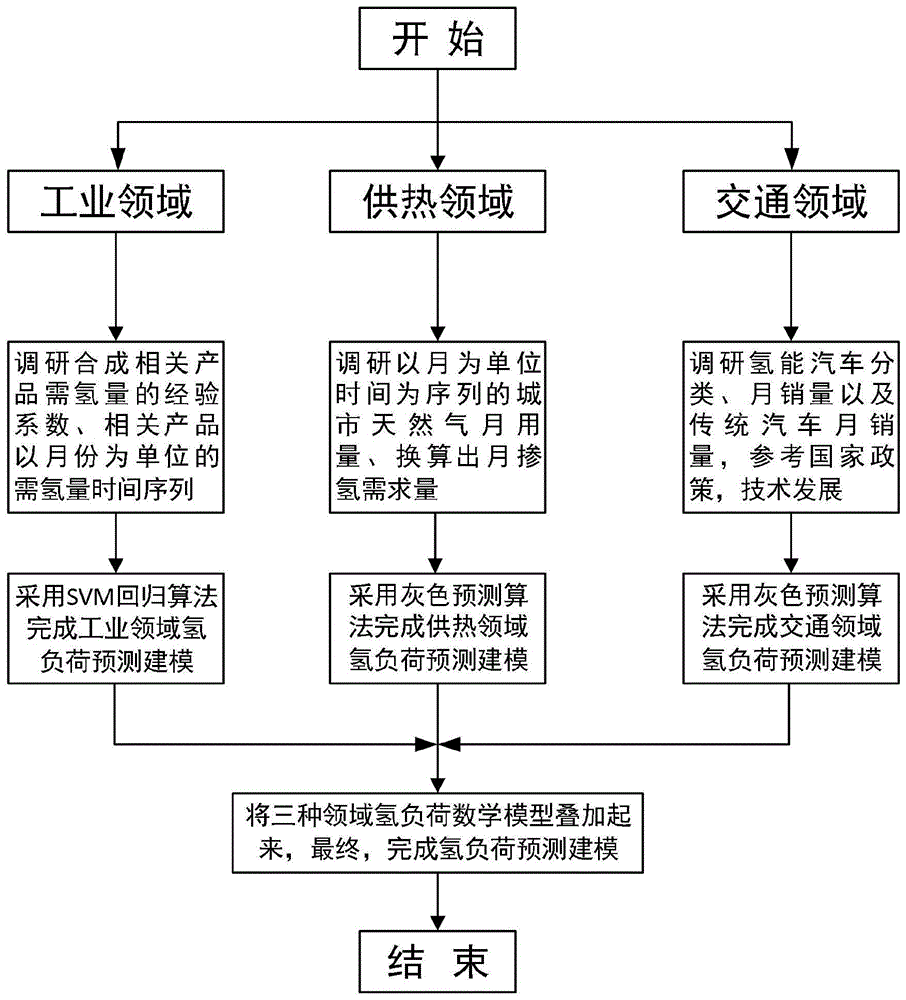
图1是本发明建模方法的流程图。
具体实施方式
以下结合附图及具体实施方式进一步说明本发明。
如图1所示,本发明建立基于蓄热式电锅炉的风电供暖调度优化模型方法的流程如下:
1、首先,从中国统计年鉴获得工业领域石油裂化、合成氨、制甲醇、煤制气和还原铁等产品以月份为单位的产量时间序列,通过查找文献得到各产品需氢量的经验参数,进而得到各产品的月需氢量时间序列,采用svm回归算法对工业领域对氢能的需求进行预测,建立数学预测模型;
2、其次,从中国统计年鉴获得供热领域以月份为单位的时间序列的城市天然气需求量,查找外文文献获得国外天然气掺氢比,采用改进的灰色预测方法,结合新陈代谢方法进行新旧数据替换,构建天然气中掺氢量的数学预测模型;
3、再次,从中国统计年鉴获得传统公共汽车和私家车的以月为时间序列的销售数量,采用改进的灰色预测方法构建传统公共汽车和私家车的数学预测模型;从中国统计年鉴获得氢能公共汽车和私家车当月的销售数量,采用类比方法获得氢能汽车的数学预测模型,考虑到政策鼓励与技术进步给该数额学模型乘上一个修正系数,通过文献查找氢能汽车的年行驶里程和百公里行驶里程耗油量,最终可以获得交通领域氢能需求的数学预测模型;
4、最后将得到的三种氢负荷预测叠加,构建氢负荷的数学预测模型。
- 还没有人留言评论。精彩留言会获得点赞!