一种中文分词和汉字多音字识别的方法及装置与流程
本申请涉及文字识别领域,尤其涉及一种中文分词和汉字多音字识别的方法及装置。
背景技术:
对于中文分词,早先的语言处理模型在输出词汇时,存在很多缺点:
(1)中文词汇的总数量数以百万计,所以在输出层确定输出词汇时,所需要的人工神经元数量巨大;
(2)对不同的领域,需要中文词汇不同,动态调整最后输出层的神经元会删除所有的该层训练参数;
(3)在输出时,可能的词汇很少,不需要到整个词库中搜索。
技术实现要素:
本申请提供了一种中文分词和汉字多音字识别的方法,包括:
预先设置词库,为备选词中的多音字和多音词预设发音,在词库中匹配出所有可能的词汇,组成备选词列表,将备选词列表中的所有备选词输入模型,经过模型的嵌入层后,组成备选词向量列表;
将单个汉字组成的待翻译中文句子输入模型,经过模型的编码器将输入序列压缩成指定长度的向量,编码向量在译码阶段的每个时刻,经过语言处理模型的注意机制输出上下文向量;
在备选词向量列表中匹配上下文向量,选中匹配的备选词,将选中的备选词及其预先设定的发音作为当前时刻的输出。
如上所述的中文分词和汉字多音字识别的方法,其中为备选词中的多音字和多音词预设发音,具体为:为多音字或多音词的多种读音设置对应的标识、为包含多音字的非多音词设置唯一发音标识。
如上所述的中文分词和汉字多音字识别的方法,其中将选中的备选词及其预先设定的发音作为当前时刻的输出,具体为:根据上下文向量确定每个备选词的词义,根据词义选择对应的正确发音,确定该发音对应的标识,将该标识附加在选中的备选词之后一齐作为当前时刻的输出。
如上所述的中文分词和汉字多音字识别的方法,其中将备选词列表中的所有备选词输入语言处理模型,经过语言处理模型的嵌入层后,组成备选词向量列表,具体包括如下子步骤:
将备选词列表中的所有备选词输入语言处理模型,提取所有备选词,计算备选词之间的词意相似度,根据词意相似度缩小备选词库的范围,得到备选词特征向量;
将高维稀疏的备选词特征向量转换为低维稠密的备选词特征向量,降低训练所需的数据量;
将得到的备选词特征向量作为特征值输入语言处理模型中进行训练,得到备选词向量列表。
如上所述的中文分词和汉字多音字识别的方法,其中采用下式经语言处理模型的注意机制输出上下文向量:
其中,lx表示输入句子的长度,aij代表在输出句子第i个单词时输入句子中第j个单词的注意力分配系数,hj是输入句子中第j个单词的语义编码。
本申请还提供一种中文分词和汉字多音字识别的装置,包括:
备选词向量列表生成模块,用于预先设置词库,为备选词中的多音字和多音词预设发音,在词库中匹配出所有可能的词汇,组成备选词列表,将备选词列表中的所有备选词输入模型,经过模型的嵌入层后,组成备选词向量列表;
待翻译中文句子上下文向量生成模块,用于将单个汉字组成的中文句子输入模型,经过模型的编码器将输入序列压缩成指定长度的向量,编码向量在译码器阶段的每个时刻,经过语言处理模型的注意机制输出上下文向量;
输出模块,用于在备选词向量列表中匹配上下文向量,选中匹配的备选词,将选中的备选词及其预先设定的发音作为当前时刻的输出。
如上所述的中文分词和汉字多音字识别的装置,其中备选词向量列表生成模块包括备选词发音设置子模块,具体用于为多音字或多音词的多种读音设置对应的标识、为包含多音字的非多音词设置唯一发音标识。
如上所述的中文分词和汉字多音字识别的装置,其中输出模块包括发音确定模块,具体用于根据上下文向量确定每个备选词的词义,根据词义选择对应的正确发音,确定该发音对应的标识,将该标识附加在选中的备选词之后一齐作为当前时刻的输出。
如上所述的中文分词和汉字多音字识别的装置,其中备选词向量列表生成模块,具体用于将备选词列表中的所有备选词输入语言处理模型,提取所有备选词,计算备选词之间的词意相似度,根据词意相似度缩小备选词库的范围,得到备选词特征向量;将高维稀疏的备选词特征向量转换为低维稠密的备选词特征向量,降低训练所需的数据量;将得到的备选词特征向量作为特征值输入语言处理模型中进行训练,得到备选词向量列表。
如上所述的中文分词和汉字多音字识别的装置,其中采用下式经语言处理模型的注意机制输出上下文向量:
其中,lx表示输入句子的长度,aij代表在输出句子第i个单词时输入句子中第j个单词的注意力分配系数,hj是输入句子中第j个单词的语义编码。
本申请实现的有益效果如下:
(1)将输入的单个汉字组成的句子转换为由多个词语组成的句子,预先为多音字或多音词设置预设读音,根据上下文语义确定对应的读音使得输出的读音更加符合中文习惯;
(2)对预先设置的中文词汇根据词义缩小范围,使得在输出层确定输出词汇时,减少所需要的人工神经元数量,提高输出效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1是本申请实施例一提供的一种中文分词和汉字多音字识别的方法流程图;
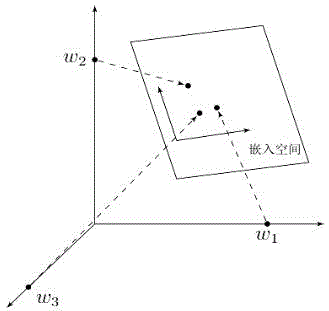
图2是将高维稀疏的巨大维度的备选词特征向量嵌入一个更小维度的空间示意图;
图3是语言处理模型示意图;
图4是本申请实施例二提供的一种中文分词和汉字多音字识别的装置图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
本申请实施例一提供一种中文分词和汉字多音字识别的方法,由于中文的分词可看作是语言处理问题,输入为单个汉字组成的中文句子,输出为由汉字词语组成的句子,即输入和输出组成的句子的单位由字变成词,应用基于注意力的语言处理模型进行更高准确率的中文分词,使用深度学习算法与匹配算法相结合的方式同时进行中文分词和汉字多音字识别,如图1所示,具体包括如下步骤:
步骤110、预先设置词库,为备选词中的多音字和多音词预设发音,然后在词库中匹配出所有可能的词汇,组成备选词列表,将备选词列表中的所有备选词输入语言处理模型,经过语言处理模型的嵌入层后,组成备选词向量列表;
本申请实施例中,在进入语言处理模型前,先将所有中文词汇汇总得到词库,然后在词库中匹配出所有符合中文习惯的词汇,作为备选词列表;
同时,考虑中文文字和词汇中存在许多多音字和多音词,如“长”的读音有“chang”和“zhang”,“朝阳”的读音有“chaoyang”和“zhaoyang”,因此预先为多音字和多音词设置对应的标识,例如将“长”的读音“chang”定义为“长1”、读音“zhang”定义为“长2”;“朝阳”的读音“chaoyang”定义为“朝阳1”、读音“zhaoyang”定义为“朝阳2”;
另外,需要说明的是,对于包含多音字的非多音词,在识别到该词时,由于该词中的多音发音已经确定,因此对于包含多音字的非多音词则不做上述操作,例如“长大”,虽包含多音字“长”但遇到词语“长大”时必须读“zhang”,因此对于此种词汇不需要为该词做多种标识。
其中,备选词列表中的备选词输入语言处理模型后,先进入嵌入层,将输入的备选词离散变量转变为连续向量,组成备选词向量列表,具体包括如下子步骤:
步骤111、将备选词列表中的所有备选词输入语言处理模型,提取所有备选词,计算备选词之间的词意相似度,根据词意相似度缩小备选词库的范围,得到备选词特征向量;
具体地,将备选词向量由整形改为浮点型,变为整个实数范围的表示,然后计算备选词之间的相似度,将相似度较高的多个备选词作为同类型向量,由此缩小备选词的范围;
本申请应用下式计算备选词之间的相似度:
其中,ra和rb分别为备选词a和备选词b的词义,ia,b为备选词集合,删除部分词义相似度较高的备选词以缩小备选词库范围,得到备选词特征向量。
步骤112、将高维稀疏的备选词特征向量转换为低维稠密的备选词特征向量,由此可以降低训练所需的数据量;
具体地,如图2所示,将高维稀疏的巨大维度的备选词特征向量嵌入一个更小维度的空间,得到低维稠密的备选词特征向量,由此降低备选词的数据量,提高训练的效率。
步骤113、将得到的备选词特征向量作为特征值输入语言处理模型中进行训练,得到备选词向量列表。
返回参见图1,步骤120、将单个汉字组成的中文句子输入语言处理模型,经过语言处理模型的编码器将输入序列压缩成指定长度的向量,编码向量在译码器阶段的每个时刻,经过语言处理模型的注意机制输出上下文向量;
图3为语言处理模型示意图,其中,语言处理模型包括嵌入层、编码器、解码器和匹配层;备选词列表进入嵌入层得到备选词向量列表,然后输入匹配层等待匹配;当需要将单个汉字组成的中文句子进行分词和多音识别时,将中文句子输入编码器转换为模型能够识别的机器语言,在进入解码器的每个时刻均经过语言处理模型的注意机制输出上下文向量,该上下文向量输入匹配层与匹配层中的备选词向量进行匹配;
具体地,采用下式经语言处理模型的注意机制输出上下文向量,具体如下:
其中,lx表示输入句子的长度,aij代表在输出句子第i个单词时输入句子中第j个单词的注意力分配系数,hj是输入句子中第j个单词的语义编码。
步骤130、在备选词向量列表中匹配上下文向量,选中匹配的备选词,将选中的备选词及其预先设定的发音作为当前时刻的输出;
本申请实施例中,备选词向量列表和待翻译句子转换的上下文向量进行匹配,选中的词作为当前时刻的输出,即本申请输入为单个汉字的中文句子,输出为由汉语词组组成的句子;
进一步地,在选中匹配的备选词之后,由于备选词中存在多音字或多音词发音,因此根据待翻译句子的上下文向量确定每个单词的词义,然后根据词义选择备选词对应的正确发音,确定该发音对应的标识,将该标识附加在选中的备选词之后一齐作为当前时刻的输出;
例如,输入的单个汉字的中文句子为“迎”“着”“朝”“阳”,在备选词向量列表中选中了备选词“迎着”和“朝阳”,然后根据“迎着”的语义确定“朝阳”的词义应该读“zhaoyang”,确定该发音对应的标识为“朝阳2”,因此该句子的输出为“迎着”“朝阳2”,输出的读音为“yingzhezhaoyang”;
又例如,输入的单个汉字的中文句子为“一”“起”“长”“大”,在备选词向量列表中选中了备选词“一起”和“长大”而“长大”为包含多音字的非多音词,因此在识别此类词语时,直接输出“一起”“长大”,输出的读音为“yiqizhangda”。
实施例二
本申请实施例二提供一种中文分词和汉字多音字识别的装置,如图4所示,包括:
备选词向量列表生成模块410,用于预先设置词库,为备选词中的多音字和多音词预设发音,在词库中匹配出所有可能的词汇,组成备选词列表,将备选词列表中的所有备选词输入模型,经过模型的嵌入层后,组成备选词向量列表;
待翻译中文句子上下文向量生成模块420,用于将单个汉字组成的中文句子输入语言处理模型,经过语言处理模型的编码器将输入序列压缩成指定长度的向量,编码向量在译码器阶段的每个时刻,经过语言处理模型的注意机制输出上下文向量;
输出模块430,用于在备选词向量列表中匹配上下文向量,选中匹配的备选词,将选中的备选词及其预先设定的发音作为当前时刻的输出。
本申请实施例中,备选词向量列表生成模块410包括备选词发音设置子模块,具体用于为多音字或多音词的多种读音设置对应的标识、为包含多音字的非多音词设置唯一发音标识。
本申请实施例中,输出模块430包括发音确定模块,具体用于根据上下文向量确定每个备选词的词义,根据词义选择对应的正确发音,确定该发音对应的标识,将该标识附加在选中的备选词之后一齐作为当前时刻的输出。
本申请实施例中,备选词向量列表生成模块410,具体用于将备选词列表中的所有备选词输入语言处理模型,提取所有备选词,计算备选词之间的词意相似度,根据词意相似度缩小备选词库的范围,得到备选词特征向量;将高维稀疏的备选词特征向量转换为低维稠密的备选词特征向量,降低训练所需的数据量;将得到的备选词特征向量作为特征值输入语言处理模型中进行训练,得到备选词向量列表。
本申请实施例中,待翻译中文句子上下文向量生成模块420具体用于采用下式经语言处理模型的注意机制输出上下文向量:
其中,lx表示输入句子的长度,aij代表在输出句子第i个单词时输入句子中第j个单词的注意力分配系数,hj是输入句子中第j个单词的语义编码。
以上所述实施例,仅为本申请的具体实施方式,用以说明本申请的技术方案,而非对其限制,本申请的保护范围并不局限于此,尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本申请实施例技术方案的精神和范围。都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!