牛股选择方法与装置、跨行业的股票数据筛选方法与装置与流程
本发明涉及证券研究方法技术领域,特别是涉及牛股选择方法与装置、跨行业的股票数据筛选方法与装置。
背景技术:
基于“量化因子”的证券研究方法是在全球金融行业中应用最广泛、历史最悠久的证券研究方法之一,它指的是针对一组证券的集合(例如“中国a股的所有股票”)构造一个能够反映个体差异的定量化指标(例如“指标=总市值+2*证券代码尾数”),并通过对该指标的计算、比较或聚合,实现一个既定目标(例如“选出一组下一交易日平均涨跌幅的期望值高于平均水平的股票”)的技术过程。
值得注意的是,由于指标的构造方式是任意的,因此通常只有当一种构造能够与既定目标产生合理的因果关联时,我们才认为这种构造(更确切地说,是构造中真正产生关联的部分,例如在前述的例子中,“总市值”这部分可能是产生关联的,而“2*证券代码尾数”这部分可能是毫无关联的,但有时这样的分离难以实现)是有意义和价值的,业界称这些有意义的构造为“量化因子”。如何创造有意义和价值的“量化因子”成为本领域值得研究的关键问题。
技术实现要素:
鉴于以上所述现有技术的缺点,本发明的目的在于提供牛股选择方法与装置、跨行业的股票数据筛选方法与装置,将自主研发的“基因矩阵”指标作为一种新型的“量化因子”,解决现有技术中定量化指标的构造缺乏合理性、有效性的技术问题。
为实现上述目的及其他相关目的,本发明提供一种牛股选择方法,包括:定义牛股集合;其中,所述牛股集合中包括从证券交易所披露的公开数据中选出的一行业的预设数量的符合预设条件的股票;建立所述牛股集合的基因矩阵;其中,所述基因矩阵由所述牛股集合中每只股票的用于刻画股票内在特征的多维基因向量所构成;建立除所述牛股集合所属行业之外的其它行业的股票的多维基因向量;分别计算各所述其它行业的股票的多维基因向量与所述基因矩阵之间的差异度,根据差异度的大小选择其它行业的预设数量的股票以得到相应行业的牛股集合。
于本发明一实施例中,根据所述公开数据得到符合预设条件的牛股集合的一种实现方式包括:选择一时间点,计算若干预设行业指数在过去一段时间内的变动幅度,并从中选择变动幅度最大的一个行业;计算所述变动幅度最大的一个行业的所有股票在过去一段时间内的价格变动幅度,并从中选择变动最大的所述预设数量的股票并形成所述牛股集合。
于本发明一实施例中,建立每只股票的多维基因向量的一种实现方式包括:定义所述多维基因向量的每个维度;针对每个维度选择多个量化因子,根据所述多个量化因子计算得到该维度的取值。
于本发明一实施例中,计算一股票的多维基因向量与所述基因矩阵之间的差异度的一种实现方式包括:计算该股票的多维基因向量与所述基因矩阵之间的距离。
为实现上述目的及其他相关目的,本发明提供一种跨行业的股票数据筛选方法,包括:获取证券交易所披露的公开数据,并从中选择第一行业的预设数量的符合预设条件的股票数据,作为第一股票数据集;分析所述股票数据集中每只股票数据的内在特征,据以建立每只股票数据的多维基因向量,并根据每只股票数据的多维基因向量构建所述第一股票数据集的基因矩阵;从所述证券交易所披露的公开数据中选择第二行业的股票数据,作为第二股票数据集,并为所述第二股票数据集中的每只股票数据建立多维基因向量;计算所述第二股票数据集中的每只股票数据的多维基因向量与所述基因矩阵之间的差异度,根据差异度的大小筛选出所述第二行业的预设数量的股票数据。
于本发明一实施例中,从所述证券交易所披露的公开数据中选出所述第一股票数据集的一种实现方式包括:选择一时间点,计算若干预设行业指数在过去一段时间内的变动幅度,并从中选择变动幅度最大的一个行业;计算所述变动幅度最大的一个行业的所有股票数据在过去一段时间内的价格变动幅度,并从中选择变动最大的所述预设数量的股票数据并形成所述第一股票数据集。
于本发明一实施例中,建立每只股票数据的多维基因向量的一种实现方式包括:定义所述多维基因向量的每个维度;针对每个维度选择多个量化因子,根据所述多个量化因子计算得到该维度的取值。
于本发明一实施例中,计算一股票数据的多维基因向量与所述基因矩阵之间的差异度的一种实现方式包括:计算该股票数据的多维基因向量与所述基因矩阵之间的距离。
为实现上述目的及其他相关目的,本发明提供一种牛股选择装置,包括:牛股定义模块,用于定义牛股集合;其中,所述牛股集合中包括从证券交易所披露的公开数据中选出的一行业的预设数量的符合预设条件的股票;基因建立模块,用于建立所述牛股集合的基因矩阵;其中,所述基因矩阵由所述牛股集合中每只股票的用于刻画股票内在特征的多维基因向量所构成;牛股选择模块,用于建立除所述牛股集合所属行业之外的其它行业的股票的多维基因向量;分别计算各所述其它行业的股票的多维基因向量与所述基因矩阵之间的差异度,根据差异度的大小选择其它行业的预设数量的股票以得到相应行业的牛股集合。
为实现上述目的及其他相关目的,本发明提供一种跨行业的股票数据筛选装置,包括:股票数据获取模块,用于获取证券交易所披露的公开数据;股票数据处理模块,用于从所述公开数据中选择第一行业的预设数量的符合预设条件的股票数据,作为第一股票数据集;分析所述股票数据集中每只股票数据的内在特征,据以建立每只股票数据的多维基因向量,并根据每只股票数据的多维基因向量构建所述第一股票数据集的基因矩阵;从所述证券交易所披露的公开数据中选择第二行业的股票数据,作为第二股票数据集,并为所述第二股票数据集中的每只股票数据建立多维基因向量;计算所述第二股票数据集中的每只股票数据的多维基因向量与所述基因矩阵之间的差异度,根据差异度的大小筛选出所述第二行业的预设数量的股票数据
如上所述,本发明通过“基因矩阵”可有效量化牛股特征,有助于筛选不同行业中与牛股(例如“正在高速上涨”、亦或其他特征)内在逻辑结构最相似的股票数据,既可以作为机构或个人实施投资的直接参考,也可以作为其他证券研究工作的间接参考,因此在多个方面具备有益价值。
附图说明
图1显示为本发明一实施例中的牛股选择方法的原理示意图。
图2显示为本发明一实施例中的牛股选择装置的原理示意图。
图3显示为本发明一实施例中的跨行业的股票数据筛选方法的原理示意图。
图4显示为本发明一实施例中的跨行业的股票数据筛选装置的原理示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
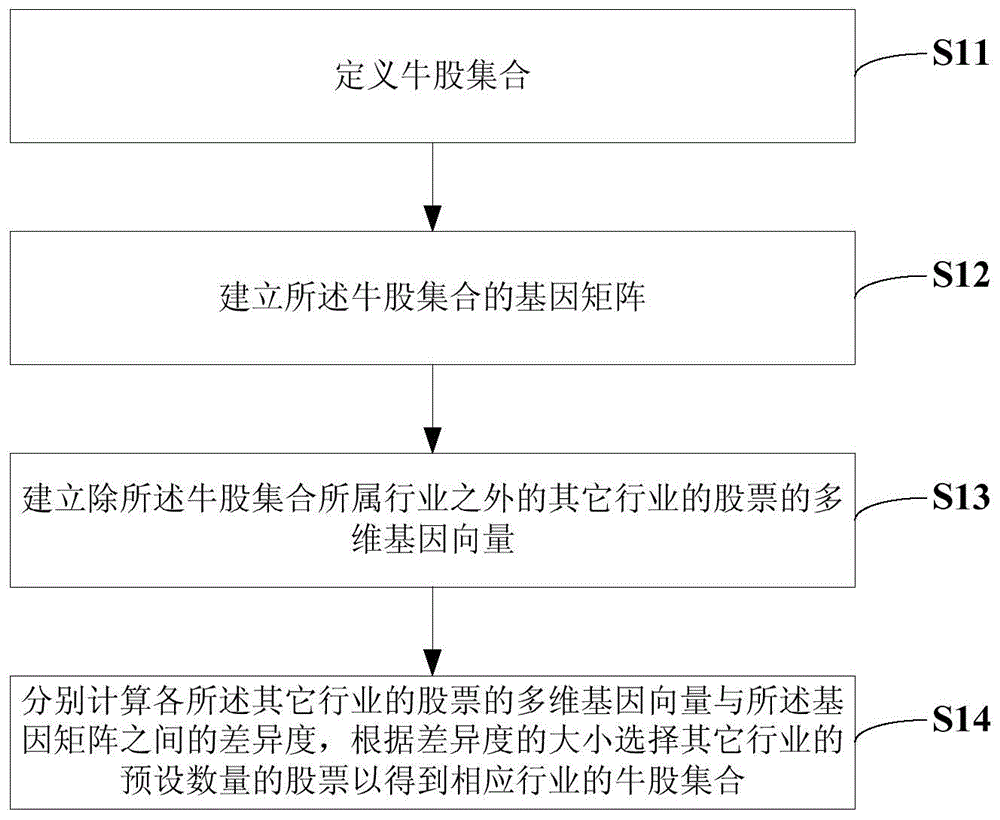
如图1所示,本实施例提供一种牛股选择方法,包括如下步骤:
s11:定义牛股集合;其中,所述牛股集合中包括从证券交易所披露的公开数据中选出的一行业的预设数量的符合预设条件的股票。
定义牛股指对任意一个国家或地区的证券交易所组织和管理的股票交易市场(以下简称“股票市场”),在任意一个时间点,能够根据交易所披露的公开数据,选出一组包含x只股票(x是事先指定的正整数)的集合、并将其定义为“牛股”的算法。该算法的实现,主要基于对股票市场所有关于股票价格、行业指数等数据的收集、计算、比较和筛选。
具体地,首先,选择一时间点,计算若干预设行业指数在过去一段时间内的变动幅度,并从中选择变动幅度最大的一个行业;然后,计算所述变动幅度最大的一个行业的所有股票在过去一段时间内的价格变动幅度,并从中选择变动最大的所述预设数量的股票并形成所述牛股集合。
以中国a股市场为例,在任意一个时间点,计算多个(如28个)申万行业指数(还可以是证监会行业指数等,本发明对此不做限制)在过去几分钟内的变动幅度,并从中选取变动幅度最大的一个行业;计算该行业所有股票在过去几分钟内的价格变动幅度,并从中选取变动幅度最大的10只股票形成牛股集合s=(s1,s2,…,s10)。
s12:建立所述牛股集合的基因矩阵;其中,所述基因矩阵由所述牛股集合中每只股票的用于刻画股票内在特征的多维基因向量所构成。
建立基因矩阵指对任意股票市场内的任意一组股票的集合,能够根据交易所披露的公开数据,计算出唯一确定形如g=(g1,g2,…,gn)的n维向量值(n是事先指定的正整数),用来最大限度地刻画这组股票内在特征的逻辑共性、并将其定义为“基因矩阵”的算法。该算法的实现,主要基于以实现发明的有益效果为目标,定义每只股票的n个基因维度并选出n组量化因子,通过对每组量化因子的计算和聚合,来获得每只股票在每个维度上的基因值。
以牛股集合s=(s1,s2,…,s10)为例,定义刻画基因的5个维度,分别是“盈利”、“成长”、“安全”、“趋势”和“反转”。为牛股集合s中的每只股票si计算5维基因gi=(gi1,gi2,gi3,gi4,gi5)的步骤如下:
1)计算市场中所有股票的毛利率;
2)计算股票si的毛利率得分=(1-毛利率在所有股票中的分位数)*10;
3)类似地,计算si的现金收入比得分,及其他与盈利相关的量化因子得分;
4)计算si的盈利维度基因值gi1=毛利率得分、现金收入比得分及其他所有纳入盈利维度的量化因子得分的加权平均值;
5)类似地,计算si的成长维度基因值gi2=利润增长率得分、eps成长性得分及其他所有纳入成长维度的量化因子得分的加权平均值;
6)计算si的安全维度基因值gi3=市净率得分、换手率得分及其他所有纳入安全维度的量化因子得分的加权平均值;
7)计算si的趋势维度基因值gi4=一致预期变化得分、平均动向指标得分及其他所有纳入趋势维度的量化因子得分的加权平均值;
8)计算si的反转维度基因值gi5=变动率指标得分、力度指标得分及其他所有纳入反转维度的量化因子得分的加权平均值;
9)综合以上结果,得到股票si的5维基因gi=(gi1,gi2,gi3,gi4,gi5)。
10)计算整个牛股集合s的基因矩阵g=(g1+g2+…+g10)/10
前述列举的10个量化因子和表层定义,具体含义如下:
1.毛利率=(营业收入–营业成本)/营业收入
2.现金收入比=自由现金流入净额/营业收入
3.利润增长率=(净利润ttm–上期净利润ttm)/|上期净利润ttm|
4.eps成长性=eps增长率*0.8+近8期eps标准差/近8期eps均值*0.2
5.市净率=总市值/所有者权益或股东权益合计
6.换手率=近5个交易日总成交额/流通市值
7.一致预期变化=(一致预期eps–5日前一致预期eps)/|5日前一致预期eps|
8.平均动向指标=ma[|上升动向–下降动向|/(上升动向+下降动向),24]
9.变动率指标=(收盘价–5日前收盘价)/5日前收盘价
10.力度指标=ema[成交量*(收盘价-前收盘价),13]
需要说明的是,以上示例中的各项参数和数值仅用于说明本示例的具体实现过程,并不是对本发明保护范围的限制。
s13:建立除所述牛股集合所属行业之外的其它行业的股票的多维基因向量。
具体建立原理可参见前述步骤1)~9),于此不重复赘述。
s14:分别计算各所述其它行业的股票的多维基因向量与所述基因矩阵之间的差异度,根据差异度的大小选择其它行业的预设数量的股票以得到相应行业的牛股集合。
基因选股指对任意市场内的任意一个形如g=(g1,g2,…,gn)的基因,能够根据交易所披露的公开数据,选出一组包含y只股票(y是事先指定的正整数)的集合,它们同指定的基因具有比其他股票更高的相似性和契合度。该算法的实现,主要基于将步骤s12中构造的基因矩阵应用于市场中的所有股票,并从中选出与指定基因“距离”最短(距离是一个事先定义的计算公式)的一定数量的股票。
以同行业的牛股集合s=(s1,s2,…,s10)和它的基因矩阵g=(g1,g2,g3,g4,g5)为例,计算市场中除该行业外所有股票的5维基因gi=(gi1,gi2,gi3,gi4,gi5),及它们与基因矩阵的距离:
di=(gi1-g1)2+(gi2-g2)2+(gi3-g3)2+(gi4-g4)2+(gi1-g5)2。
最后,从中选取该距离最小的10只股票t=(t1,t2,…,t10)。
实现上述各方法实施例的全部或部分步骤可以通过计算机程序相关的硬件来完成。基于这样的理解,本发明还提供一种计算机程序产品,包括一个或多个计算机指令。所述计算机指令可以存储在计算机可读存储介质中。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(如:软盘、硬盘、磁带)、光介质(如:dvd)、或者半导体介质(如:固态硬盘solidstatedisk(ssd))等。
参阅图2,本实施例提供一种牛股选择装置20,作为一款软件搭载与电子设备中,以在运行时执行前述方法实施例的牛股选择方法。由于本实施例的技术原理与前述方法实施例的技术原理相似,因而不再对同样的技术细节做重复性赘述。本实施例的牛股选择装置20包括如下模块:
牛股定义模块21,用于执行前述牛股选择方法的步骤s11;
基因建立模块22,用于执行前述牛股选择方法的步骤s12;
牛股选择模块23,用于执行前述牛股选择方法的步骤s13~14。
本领域技术人员应当理解,图2实施例中的各个模块的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个或多个物理实体上。且这些模块可以全部以软件通过处理元件调用的形式实现,也可以全部以硬件的形式实现,还可以部分模块通过处理元件调用软件的形式实现,部分模块通过硬件的形式实现。
如图3所示,本实施例提供一种跨行业的股票数据筛选方法,包括以下步骤:
s31:获取证券交易所披露的公开数据,并从中选择第一行业的预设数量的符合预设条件的股票数据,作为第一股票数据集;
具体地,首先,选择一交易时间点,计算若干预设行业指数在过去一段时间内的变动幅度,并从中选择变动幅度最大的一个行业;然后,计算所述变动幅度最大的一个行业的所有股票数据在过去一段时间内的价格变动幅度,并从中选择变动最大的所述预设数量的股票数据并形成所述第一股票数据集。
s32:分析所述股票数据集中每只股票数据的内在特征,据以建立每只股票数据的多维基因向量,并根据每只股票数据的多维基因向量构建所述第一股票数据集的基因矩阵;
具体的,先定义所述多维基因向量的每个维度;之后针对每个维度选择多个量化因子,根据所述多个量化因子计算得到该维度的取值。
s33:从所述证券交易所披露的公开数据中选择第二行业的股票数据,作为第二股票数据集,并为所述第二股票数据集中的每只股票数据建立多维基因向量;
s34:计算所述第二股票数据集中的每只股票数据的多维基因向量与所述基因矩阵之间的差异度,根据差异度的大小筛选出所述第二行业的预设数量的股票数据。
具体的,计算该股票数据的多维基因向量与所述基因矩阵之间的距离,将距离最小的几个股票数据作为筛选结果。
需要说明的是,由于本实施例的跨行业的股票数据筛选方法的实现原理与图1实施例的牛股选择方法的实现原理一致,故于此不对细节做重复性赘述。
实现上述各方法实施例的全部或部分步骤可以通过计算机程序相关的硬件来完成。基于这样的理解,本发明还提供一种计算机程序产品,包括一个或多个计算机指令。所述计算机指令可以存储在计算机可读存储介质中。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(如:软盘、硬盘、磁带)、光介质(如:dvd)、或者半导体介质(如:固态硬盘solidstatedisk(ssd))等。
参阅图4,本实施例提供一种跨行业的股票数据筛选装置40,作为一款软件搭载与电子设备中,以在运行时执行前述方法实施例的跨行业的股票数据筛选方法。由于本实施例的技术原理与前述方法实施例的技术原理相似,因而不再对同样的技术细节做重复性赘述。本实施例的跨行业的股票数据筛选装置40包括如下模块:
股票数据获取模块41,用于执行前述跨行业的股票数据筛选方法的步骤s31;
股票数据处理模块42,用于执行前述跨行业的股票数据筛选方法的步骤s32~34。
本领域技术人员应当理解,图4实施例中的各个模块的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个或多个物理实体上。且这些模块可以全部以软件通过处理元件调用的形式实现,也可以全部以硬件的形式实现,还可以部分模块通过处理元件调用软件的形式实现,部分模块通过硬件的形式实现。
综上所述,本发明的牛股选择方法与装置、跨行业的股票数据筛选方法与装置,对任一股票市场,在任一时间点,能够实时选出一组股票,它们具备与当下市场中受到足够人数认可的牛股集合最相似的内在逻辑特征,有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!