一种文本检测的方法、装置、电子设备和存储介质与流程
本发明涉及文本检测技术领域,具体涉及一种文本检测的方法、装置、电子设备和存储介质。
背景技术:
在文本识别技术中,拍照图像受环境影响很大,在文字识别中,需要对文本行进行检测,获取最佳的文本行外接框,从而对外接框内的文本进行识别。
现有经典的文本检测技术是主要是基于psenet的文本行检测算法,其将fpn和pse技术相结合,先通过fpn检测出各个文本行,然后在基于pse的后处理,即渐进式尺度扩展算法后,输出的是一个针对文本区域和背景多分类的mask图,即输出一个尺寸与输入图像相同的只有一个通道的矩阵,每个的值为0、1、2......n(n为输入图像中完整的文本行区域数量),表明输入图像中为背景或者是文本区域,该矩阵可以对应一个掩码图,掩码图的尺寸与输入图像的尺寸相同,掩码图中的各个值对应一个文本行区域掩码,例如值为1的点的集合构成第一个文本行区域掩码,值为0的点的集合为输入图像的背景区域。
得到了多分类的mask图像后,还需要通过opencv中的findcontours函数,针对每个文本行区域掩码进行遍历,以找出每个文本行区域的轮廓范围。但是这里需要针对每个文本行区域掩码进行找轮廓的操作,而且针对文本行区域较为密集的输入图像,找轮廓的整体耗时较高,达到了400ms以上,占整体文本行检测算法的80%-90%左右,因此影响了ocr整体的耗时。
技术实现要素:
针对所述缺陷,本发明实施例公开了一种文本检测的方法、装置、电子设备和存储介质,其可以快速确定各个文本行的轮廓,降低整个文本识别的耗时。
本发明实施例第一方面公开一种文本检测的方法,所述方法包括:
获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同;
确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数;
将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数;
所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息;
利用所述第一边界信息和第二边界信息构造编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,在本发明实施例第一方面中,获取目标图片的文本行区域掩码的掩码图,包括:
获取目标图片;
将所述目标图片输入预先训练过的基于深度学习的文本行检测网络模型,输出带有各个文本行区域掩码的掩码图。
作为一种可选的实施方式,在本发明实施例第一方面中,所述利用所述第一边界信息和第二边界信息构成构造编号为i的文本行区域掩码对应的文本行轮廓,包括:
根据所述第一边界信息和第二边界信息确定编号为i的文本行区域掩码对应的中线位置和高度。
作为一种可选的实施方式,在本发明实施例第一方面中,所述根据所述第一边界信息和第二边界信息确定编号为i的文本行区域掩码对应的中线位置和高度,包括:
确定所述新值中等于-i的像素点的第一坐标对应的新值中等于i的像素点的第二坐标,所述第一坐标和第二坐标的横坐标相同;
将所述第一坐标和第二坐标的纵坐标相加后求平均,得到中点位置;所有中点位置的集合构成编号为i的文本行区域掩码对应的中线位置;
将所述第一坐标和第二坐标的纵坐标相减后取绝对值,得到高度信息;所有高度信息的集合构成编号为i的文本行区域掩码对应的高度;
基于所述编号为i的文本行区域掩码对应的中线位置和高度构造编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,在本发明实施例第一方面中,所述利用所述第一边界信息和第二边界信息构成构造编号为i的文本行区域掩码对应的文本行轮廓,包括:
将所述新值中等于-i的像素点依次相连,形成编号为i的文本行区域掩码对应的第一边界;将所述新值中等于i的像素点依次相连,形成编号为i的文本行区域掩码对应的第二边界;
确定所述新值等于-i的像素点中横坐标最小的像素点为第一像素点,确定所述新值等于i的像素点中横坐标最小的像素点为第二像素点;确定所述新值等于-i的像素点中横坐标最大的像素点为第三像素点,确定所述新值等于i的像素点中横坐标最大的像素点为第四像素点;
将第一像素点和第二像素点连接,作为编号为i的文本行区域掩码对应的左边界;将第三像素点和第四像素点连接,作为编号为i的文本行区域掩码的右边界;
将所述左边界、第一边界、右边界以及第二边界构成的闭合框形成所述编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,在本发明实施例第一方面中,所述方法,还包括:
确定编号为i的文本行区域掩码对应的文本行轮廓在所述目标图片中的位置,将所述文本行轮廓合成于所述目标图片中。
本发明实施例第二方面公开一种文本检测的装置,所述装置包括:
获取单元,用于获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同;
确定单元,用于确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数;
计算单元,用于将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数;
信息形成单元,用于所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息;
轮廓构造单元,用于利用所述第一边界信息和第二边界信息构造编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,在本发明实施例第二方面中,所述获取单元,包括:
图片获取子单元,用于获取目标图片;
识别子单元,用于将所述目标图片输入预先训练过的基于深度学习的文本行检测网络模型,输出带有各个文本行区域掩码的掩码图。
作为一种可选的实施方式,在本发明实施例第二方面中,所述轮廓构造单元,包括:
中线和高度获取子单元,用于根据所述第一边界信息和第二边界信息确定编号为i的文本行区域掩码对应的中线位置和高度。
作为一种可选的实施方式,在本发明实施例第二方面中,所述中线和高度获取子单元,包括:
第一孙单元,用于确定所述新值中等于-i的像素点的第一坐标对应的新值中等于i的像素点的第二坐标,所述第一坐标和第二坐标的横坐标相同;
第二孙单元,用于将所述第一坐标和第二坐标的纵坐标相加后求平均,得到中点位置;所有中点位置的集合构成编号为i的文本行区域掩码对应的中线位置;
第三孙单元,用于将所述第一坐标和第二坐标的纵坐标相减后取绝对值,得到高度信息;所有高度信息的集合构成编号为i的文本行区域掩码对应的高度;
第四孙单元,用于基于所述编号为i的文本行区域掩码对应的中线位置和高度构造编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,在本发明实施例第二方面中,所述轮廓构造单元,包括:
第一信息构建子单元,用于将所述新值中等于-i的像素点依次相连,形成编号为i的文本行区域掩码对应的第一边界;将所述新值中等于i的像素点依次相连,形成编号为i的文本行区域掩码对应的第二边界;
目标像素点确定子单元,用于确定所述新值等于-i的像素点中横坐标最小的像素点为第一像素点,确定所述新值等于i的像素点中横坐标最小的像素点为第二像素点;确定所述新值等于-i的像素点中横坐标最大的像素点为第三像素点,确定所述新值等于i的像素点中横坐标最大的像素点为第四像素点;
第二信息构建子单元,用于将第一像素点和第二像素点连接,作为编号为i的文本行区域掩码对应的左边界;将第三像素点和第四像素点连接,作为编号为i的文本行区域掩码的右边界;
第三信息构建子单元,用于将所述左边界、第一边界、右边界以及第二边界构成的闭合框形成所述编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,在本发明实施例第二方面中,所述装置,还包括:
合成单元,用于确定编号为i的文本行区域掩码对应的文本行轮廓在所述目标图片中的位置,将所述文本行轮廓合成于所述目标图片中。
本发明实施例第三方面公开一种电子设备,包括:存储有可执行程序代码的存储器;与所述存储器耦合的处理器;所述处理器调用所述存储器中存储的所述可执行程序代码,用于执行本发明实施例第一方面公开的一种文本检测的方法的部分或全部步骤。
本发明实施例第四方面公开一种计算机可读存储介质,其存储计算机程序,其中,所述计算机程序使得计算机执行本发明实施例第一方面公开的一种文本检测的方法的部分或全部步骤。
本发明实施例第五方面公开一种计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行本发明实施例第一方面公开的一种文本检测的方法的部分或全部步骤。
本发明实施例第六方面公开一种应用发布平台,所述应用发布平台用于发布计算机程序产品,其中,当所述计算机程序产品在计算机上运行时,使得所述计算机执行本发明实施例第一方面公开的一种文本检测的方法的部分或全部步骤。
与现有技术相比,本发明实施例具有以下有益效果:
本发明实施例中,获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同;确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数;将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数;所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息;利用所述第一边界信息和第二边界信息构造编号为i的文本行区域掩码对应的文本行轮廓。可见,实施本发明实施例,针对文本行区域和背景多分类的mask图进行逐行相减运算,通过此找出对应文本行的上下边界,从而计算出对应文本行的轮廓信息,极大程度上降低了该模块的耗时,使其不受文本行区域的密集程度影响,将找轮廓的平均耗时降低到了50ms以内,很大程度上解决了ocr整体延时过高的问题。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例公开的一种文本检测的方法的流程示意图;
图2是本发明实施例公开的一个掩码图的示意图;
图3为图2的掩码图经过逐行相减运算后的新值示意图;
图4为基于图3的新值确定的第一边界和第二边界的示意图;
图5是本发明实施例公开的另一种文本检测的方法的流程示意图;
图6是本发明实施例公开的另一种文本检测的方法的流程示意图;
图7为基于图3的新值确定的文本行轮廓的示意图;
图8是本发明实施例公开的另一个掩码图的示意图;
图9为图8的掩码图经过逐行相减运算后的新值示意图;
图10为基于图9的新值确定的文本行轮廓的示意图;
图11是本发明实施例公开的一种文本检测的装置的结构示意图;
图12是本发明实施例公开的另一种文本检测的装置的结构示意图;
图13是本发明实施例公开的一种电子设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书中的术语“第一”、“第二”、“第三”、“第四”等是用于区别不同的对象,而不是用于描述特定顺序。本发明实施例的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,示例性地,包含了一系列步骤或单元的过程、方法、装置、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
本发明实施例公开了一种文本检测的方法、装置、电子设备和存储介质,其针对文本行区域和背景多分类的mask图进行逐行相减运算,通过此找出对应文本行的上下边界,从而计算出对应文本行的轮廓信息,极大程度上降低了该模块的耗时,使其不受文本行区域的密集程度影响,将找轮廓的平均耗时降低到了50ms以内,很大程度上解决了ocr整体延时过高的问题,以下结合附图进行详细描述。
实施例一
请参阅图1,图1是本发明实施例公开的一种文本检测方法的流程示意图。如图1所示,该文本检测方法包括以下步骤:
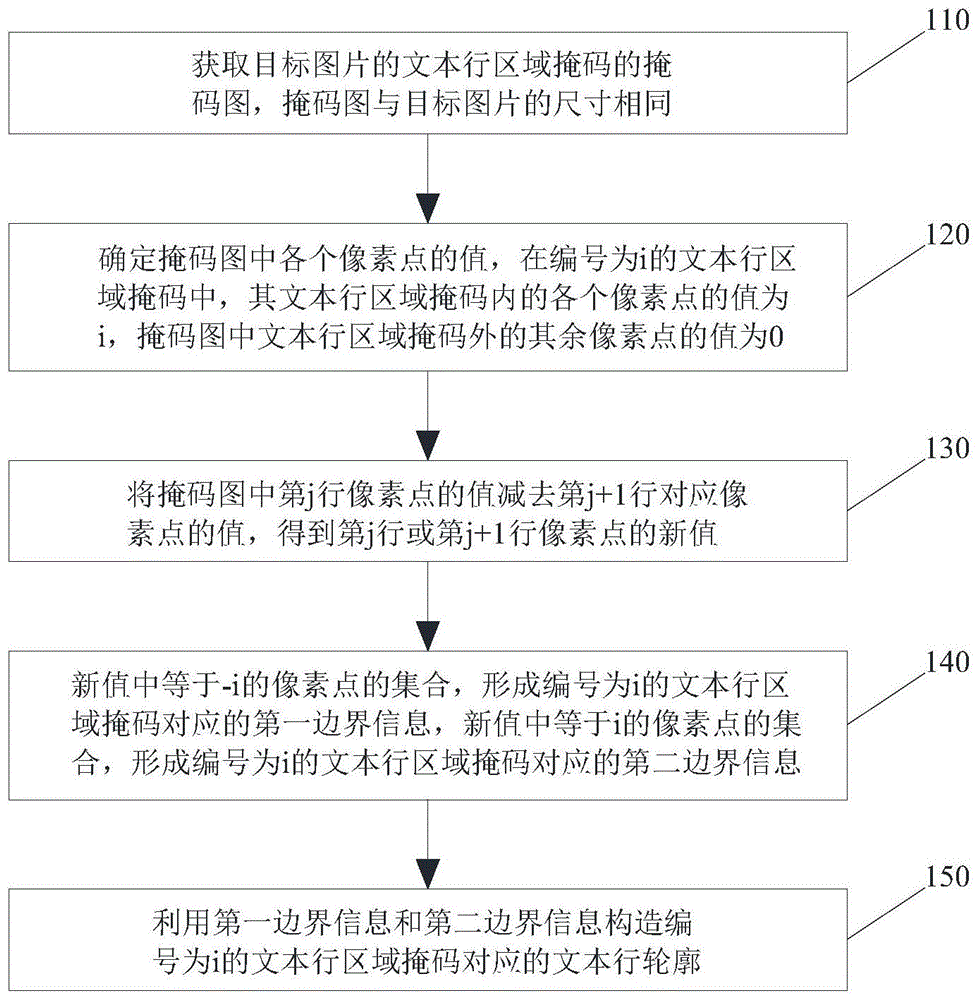
110、获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同。
目标图片为用户输入的图像,用户输入图像的方式可以是通过图像采集装置对文档进行拍照得到的图像,也可以是用户从网上下载的图像,这里不做限定。目标图片中存在一个或多个文本行,文本行是否处于水平状态不做限定。
获取目标图片的文本行区域掩码的方式可以有多种,在本发明实施例中,采用基于深度学习的文本行检测网络模型实现,文本行检测网络模型可以采用yolo、ctpn、psenet等任意的深度学习网络。示例性地,采用psenet文本行检测网络模型,使得检测结果对光照、颜色、纹理、模糊等情况具有很强的鲁棒性。
创建psenet文本行检测网络模型后,通过样本集合对其进行训练,样本的标签为每个文本行的外接框。将目标图片输入psenet文本行检测网络模型,通过fpn检测出各个文本行区域,然后在基于pse的后处理,即渐进式尺度扩展算法后,输出的是一个针对文本区域和背景多分类的掩码(mask)图。
掩码图为一个尺寸与目标图片相同的只有一个通道的矩阵的呈现方式,该矩阵为n*m的二维矩阵,其中,n为目标图片和掩码图的像素点的行数,m为目标图片和掩码图的像素点的列数,每个像素点的值为0、1、2......m,表明目标图片中为背景或者是文本区域,掩码图中的各个值及其位置对应相应的文本行区域掩码,例如值为1的点的集合对应目标图片的第一个文本行区域掩码,值为0的点的集合对应目标图片的背景区域。
对于用户而言,由于矩阵无法直观显示各个文本行区域掩码,事实上,psenet文本行检测网络模型最终的结果为掩码图,每个文本行区域掩码的值不同,所以呈现多分类的不同颜色的文本行区域掩码。
120、确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数。
基于步骤110的原理,可以得到所有像素点的值,以各个像素点的值的不同,为每个文本行区域掩码进行编号,其中,编号为i的文本行区域掩码中的各个像素点的值均为i,编号为k的文本行区域掩码中的各个像素点的值均为k。掩码图中文本行区域掩码外的其余像素点的值为0。1≤i≤m,m为目标图片对应由psenet文本行检测网络模型识别到的文本行区域掩码的总数。
130、将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数。
新值计算可以使用python的科学计算库numpy中的高效的矩阵运算方法实现,将掩码图对应的n*m的二维矩阵进行逐行相减,得到一个新值矩阵。具体地,将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数。
第j行像素点的值减去第j+1行对应像素点的值是指将第j行每个像素点的值减去第j行每个像素点所在列的第j+1行对应像素点的值。
可以将掩码图首行作为第一行,则上述新值的计算为从上到下实现逐步相减操作。也可以将掩码图的尾行作为第一行,则上述新值的计算为从下到上实现逐步相减操作。当然,二者也可以相互转换,例如如果以掩码图首行为第一行,将掩码图中第j行像素点的值减去第j-1行对应像素点的值,得到第j行或第j-1行像素点的新值,则该新值的计算也是从下到上实现逐步相减操作。相减得到的差值作为相减的两行中任意一行的新值,最后无新值的一行取值为0,例如,从下往上实现相减操作,尾行的一行减去倒数第二行的差值作为尾行的新值,则首行无新值,将首行的值均置于0,如果差值作为倒数第二行的新值,则尾行没有新值,最下面一行的值均置于0。
类似的方式,还可以通过相邻的列相减得到新值来确定各个文本行的轮廓。
140、所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息。
这里以自下而上的逐行相减方式,得到编号为i的文本行区域掩码的新值为例,确定编号为i的文本行区域掩码对应的第一边界信息(即下边界信息,如果自上而下,则第一边界信息为上边界信息)和第二边界信息(即上边界信息,如果自上而下,则第二边界信息为下边界信息)。
具体地,请参照图2所示含有一个矩形文本行区域掩码的掩码图(i=7),通过自下而上逐行相减得到图3的新值,图3的新值中,新值为-7的像素点构成下边界信息,新值为7的像素点构成上边界信息。
150、利用所述第一边界信息和第二边界信息构造编号为i的文本行区域掩码对应的文本行轮廓。
如图4所示,将第一边界信息的各个像素点和第二边界信息的各个像素点分别依次相连,可以得到编号为7的文本行区域掩码对应的下边界21和上边界22,该上边界和下边界可以作为编号为7的文本行区域掩码对应的文本行轮廓,其中,左边界和右边界可以是上下边界延伸(平行于掩码图水平方向进行延伸)到掩码图的首列和尾列,以掩码图的左右边界作为编号7的文本行区域掩码的左右边界。
相同方式得到每个文本行区域掩码对应的文本行轮廓,因为文本行轮廓的像素点位置确定,并且掩码图和目标图片的尺寸完全相同,则可以将所有文本行轮廓上各个像素点的值均调整成与其编号相同的值,得到掩码图对应的文本行轮廓图,然后直接将目标图片和掩码图合成一张新的图纸,这种图纸含有目标图片的各个文本行,并且各个文本行的外围都被相应的文本行轮廓包裹。
可以通过该新的图纸,对每个文本行轮廓进行分割,分割后送入文字识别模型进行文字识别(当然,也可以不分割识别),识别结果可以用于搜题等。
实施本发明实施例,针对文本行区域和背景多分类的mask图进行逐行相减运算,通过此找出对应文本行的上下边界,从而计算出对应文本行的轮廓信息,极大程度上降低了该模块的耗时,使其不受文本行区域的密集程度影响,将找轮廓的平均耗时降低到了50ms以内,很大程度上解决了ocr整体延时过高的问题。
实施例二
请参阅图5,图5是本发明实施例公开的另一种文本检测方法的流程示意图。如图5所示,该文本检测方法包括以下步骤:
310、获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同。
320、确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数。
330、将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数。
340、所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息。
350、根据所述第一边界信息和第二边界信息确定编号为i的文本行区域掩码对应的中线位置和高度。
360、基于所述编号为i的文本行区域掩码对应的中线位置和高度构造编号为i的文本行区域掩码对应的文本行轮廓。
其中,步骤310-340可以与实施例一中的步骤110-140相同,这里不再赘述。
步骤350和步骤360,以中线位置和高度确定文本行的轮廓。
步骤350中,先确定所述新值中等于-i的像素点的第一坐标对应的新值中等于i的像素点的第二坐标,所述第一坐标和第二坐标的横坐标相同。通过二者横坐标的对应关系,即二者在新值构成的矩阵中位于同一列,基于上述逐行相减的方式,每一个第一坐标均会对应有一个第二坐标。
将所述第一坐标和第二坐标的纵坐标相加后求平均,得到中点位置;所有中点位置的集合构成编号为i的文本行区域掩码对应的中线位置。这里需要说明的是,像素点坐标为像素点在新值构建的矩阵中的位置,例如点(x,y)的横坐标值为x,纵坐标值为y,代表该像素点位于新值构建的矩阵中的第x行第y列,因此,第一坐标和第二坐标的纵坐标相加后求平均后可能不是整数,而中线位置也是以像素点位置呈现,因此如果不是整数,可以向上或向下取整。
将所述第一坐标和第二坐标的纵坐标相减后取绝对值,得到高度信息;所有高度信息的集合构成编号为i的文本行区域掩码对应的高度;因此,高度信息是以像素点数呈现。
步骤360中,基于所述编号为i的文本行区域掩码对应的中线位置和高度构造编号为i的文本行区域掩码对应的文本行轮廓。确定了文本行轮廓的中线位置和高度,也可以得到相应的文本行轮廓,同样地,可以将相连后的中线的首尾两端分别延伸,得到文本行轮廓的左右端,文本行轮廓的左右端至中线首尾两端的高度可以分别采用中线首尾两端对应的高度信息。
当然,在其他的实施例中,也可以将实施例一和实施例二相结合,通过第一边界信息、第二边界信息以及中线位置和高度来构造文本行轮廓。
相同方式得到每个文本行区域掩码对应的文本行轮廓,因为文本行轮廓的像素点位置确定,并且掩码图和目标图片的尺寸完全相同,则可以将所有文本行轮廓上各个像素点的值均调整成与其编号相同的值,得到掩码图对应的文本行轮廓图,然后直接将目标图片和掩码图合成一张新的图纸,这种图纸含有目标图片的各个文本行,并且各个文本行的外围都被相应的文本行轮廓包裹。
可以通过该新的图纸,对每个文本行轮廓进行分割,分割后送入文字识别模型进行文字识别(当然,也可以不分割识别),识别结果可以用于搜题等。
实施本发明实施例,针对文本行区域和背景多分类的mask图进行逐行相减运算,通过此找出对应文本行的上下边界,从而计算出对应文本行的轮廓信息,极大程度上降低了该模块的耗时,使其不受文本行区域的密集程度影响,将找轮廓的平均耗时降低到了50ms以内,很大程度上解决了ocr整体延时过高的问题。
实施例三
请参阅图6,图6是本发明实施例公开的又一种文本检测方法的流程示意图。如图6所示,该文本检测方法包括以下步骤:
410、获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同。
420、确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数。
430、将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数。
440、所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息。
450、根据所述第一边界信息和第二边界信息确定编号为i的文本行区域掩码对应的上、下、左、右边界。
460、基于所述编号为i的文本行区域掩码对应的上、下、左、右边界构造编号为i的文本行区域掩码对应的文本行轮廓。
其中,步骤410-440可以与实施例一中的步骤110-140相同,这里不再赘述。
如果目标图片为多版式排列,则上述文本行轮廓划分的方式可能会造成对其他行的文本进行覆盖,造成识别不准确,在本发明实施例的步骤350和步骤360中,以上、下、左、右边界确定文本行的轮廓。
步骤450中,将所述新值中等于-i的像素点依次相连,形成编号为i的文本行区域掩码对应的第一边界;将所述新值中等于i的像素点依次相连,形成编号为i的文本行区域掩码对应的第二边界。仍以图2所示掩码图为例,采用图3所示的自下而上的逐行相减算法,通过新值像素点相连的方式可以得到图7中上边界为线段ab的第二边界以及下边界为线段ef的第一边界。
然后确定所述新值等于-i的像素点中横坐标最小的像素点为第一像素点,确定所述新值等于i的像素点中横坐标最小的像素点为第二像素点;确定所述新值等于-i的像素点中横坐标最大的像素点为第三像素点,确定所述新值等于i的像素点中横坐标最大的像素点为第四像素点。将第一像素点和第二像素点连接作为编号为i的文本行区域掩码对应的左边界;将第三像素点和第四像素点连接作为编号为i的文本行区域掩码的右边界。
因为采用逐行相减方式,则每个第一像素点和第二像素点的纵坐标相同,第三像素点和第四像素点的纵坐标相同。将第一像素点和第二像素点相连,将第三像素点和第四像素点相连后,可以得到图7中上边界为线段af的左边界以及下边界为线段be的右边界。
步骤460中,将左边界、第一边界、右边界以及第二边界构成的闭合框形成所述编号为7的文本行区域掩码对应的文本行轮廓,即图7中的线段ab、be、ef、af构成的闭合框作为编号7的文本行区域掩码对应的文本行轮廓。
在图7中,abcd构成的闭合框可以认为是理论上编号7的文本行区域掩码对应的文本行轮廓,由此可以看出,本发明方式得到的文本行轮廓相对于其而言,囊括了理论上文本行轮廓且仅仅大了一行像素点位置,这种偏离相对于整个掩码图而言,可以忽略,因为一般两个文本行之间的像素点远远大于1行像素点,但是计算速度却提升了数倍。
同样的方式,本发明实施例也可以适用于具有弯曲文本行的轮廓的确定,图8-10为对于编号为8的弯曲文本行实现逐行相减并确定其文本行轮廓的示意图。从图10可以看出,本发明实施例确定的文本行轮廓(细线部分)包裹了理论上文本行轮廓(粗线部分),且仅仅在部分区域,向外侧偏离了一个像素点的位置,这种偏离可以忽略,但是计算速度却提升了数倍。
相同方式得到每个文本行区域掩码对应的文本行轮廓,因为文本行轮廓的像素点位置确定,并且掩码图和目标图片的尺寸完全相同,则可以将所有文本行轮廓上各个像素点的值均调整成与其编号相同的值,得到掩码图对应的文本行轮廓图,然后直接将目标图片和掩码图合成一张新的图纸,这种图纸含有目标图片的各个文本行,并且各个文本行的外围都被相应的文本行轮廓包裹。
可以通过该新的图纸,对每个文本行轮廓进行分割,分割后送入文字识别模型进行文字识别(当然,也可以不分割识别),识别结果可以用于搜题等。
实施本发明实施例,针对文本行区域和背景多分类的mask图进行逐行相减运算,通过此找出对应文本行的上下边界,从而计算出对应文本行的轮廓信息,极大程度上降低了该模块的耗时,使其不受文本行区域的密集程度影响,将找轮廓的平均耗时降低到了50ms以内,很大程度上解决了ocr整体延时过高的问题。
实施例四
请参阅图11,图11是本发明实施例公开的一种文本检测装置的结构示意图。如图11所示,该文本检测装置可以包括:
获取单元510,用于获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同;
确定单元520,用于确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数;
计算单元530,用于将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数;
信息形成单元540,用于所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息;
轮廓构造单元550,用于利用所述第一边界信息和第二边界信息构造编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,所述获取单元510,可以包括:
图片获取子单元511,用于获取目标图片;
识别子单元512,用于将所述目标图片输入预先训练过的基于深度学习的文本行检测网络模型,输出带有各个文本行区域掩码的掩码图。
作为一种可选的实施方式,所述轮廓构造单元540,可以包括:
中线和高度获取子单元541,用于根据所述第一边界信息和第二边界信息确定编号为i的文本行区域掩码对应的中线位置和高度。
作为一种可选的实施方式,所述中线和高度获取子单元541,包括:
第一孙单元5411,用于确定所述新值中等于-i的像素点的第一坐标对应的新值中等于i的像素点的第二坐标,所述第一坐标和第二坐标的横坐标相同;
第二孙单元5412,用于将所述第一坐标和第二坐标的纵坐标相加后求平均,得到中点位置;所有中点位置的集合构成编号为i的文本行区域掩码对应的中线位置;
第三孙单元5413,用于将所述第一坐标和第二坐标的纵坐标相减后取绝对值,得到高度信息;所有高度信息的集合构成编号为i的文本行区域掩码对应的高度;
第四孙单元5414,用于基于所述编号为i的文本行区域掩码对应的中线位置和高度构造编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,所述装置,还可以包括:
合成单元560,用于确定编号为i的文本行区域掩码对应的文本行轮廓在所述目标图片中的位置,将所述文本行轮廓合成于所述目标图片中。
图11所示的文本检测装置,针对文本行区域和背景多分类的mask图进行逐行相减运算,通过此找出对应文本行的上下边界,从而计算出对应文本行的轮廓信息,极大程度上降低了该模块的耗时,使其不受文本行区域的密集程度影响,将找轮廓的平均耗时降低到了50ms以内,很大程度上解决了ocr整体延时过高的问题。
实施例五
请参阅图12,图12是本发明实施例公开的另一种文本检测装置的结构示意图。如图12所示,该文本检测装置可以包括:
获取单元610,用于获取目标图片的文本行区域掩码的掩码图,所述掩码图与目标图片的尺寸相同;
确定单元620,用于确定所述掩码图中各个像素点的值,在编号为i的文本行区域掩码中,其文本行区域掩码内的各个像素点的值为i,掩码图中文本行区域掩码外的其余像素点的值为0;1≤i≤m,m为目标图片对应的文本行区域掩码的总数;
计算单元630,用于将掩码图中第j行像素点的值减去第j+1行对应像素点的值,得到第j行或第j+1行像素点的新值,其中,1≤j≤n,n为掩码图的总行数;
信息形成单元640,用于所述新值中等于-i的像素点的集合,形成编号为i的文本行区域掩码对应的第一边界信息,所述新值中等于i的像素点的集合,形成编号为i的文本行区域掩码对应的第二边界信息;
轮廓构造单元650,用于利用所述第一边界信息和第二边界信息构造编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,所述获取单元610,可以包括:
图片获取子单元611,用于获取目标图片;
识别子单元612,用于将所述目标图片输入预先训练过的基于深度学习的文本行检测网络模型,输出带有各个文本行区域掩码的掩码图。
作为一种可选的实施方式,所述轮廓构造单元640,可以包括:
第一信息构建子单元641,用于将所述新值中等于-i的像素点依次相连,形成编号为i的文本行区域掩码对应的第一边界;将所述新值中等于i的像素点依次相连,形成编号为i的文本行区域掩码对应的第二边界;
目标像素点确定子单元642,用于确定所述新值等于-i的像素点中横坐标最小的像素点为第一像素点,确定所述新值等于i的像素点中横坐标最小的像素点为第二像素点;确定所述新值等于-i的像素点中横坐标最大的像素点为第三像素点,确定所述新值等于i的像素点中横坐标最大的像素点为第四像素点;
第二信息构建子单元643,用于将第一像素点和第二像素点连接作为编号为i的文本行区域掩码对应的左边界;将第三像素点和第四像素点连接作为编号为i的文本行区域掩码的右边界;
第三信息构建子单元644,用于将所述左边界、第一边界、右边界以及第二边界构成的闭合框形成所述编号为i的文本行区域掩码对应的文本行轮廓。
作为一种可选的实施方式,所述装置,还可以包括:
合成单元660,用于确定编号为i的文本行区域掩码对应的文本行轮廓在所述目标图片中的位置,将所述文本行轮廓合成于所述目标图片中。
图12所示的文本检测装置,针对文本行区域和背景多分类的mask图进行逐行相减运算,通过此找出对应文本行的上下边界,从而计算出对应文本行的轮廓信息,极大程度上降低了该模块的耗时,使其不受文本行区域的密集程度影响,将找轮廓的平均耗时降低到了50ms以内,很大程度上解决了ocr整体延时过高的问题。
实施例六
请参阅图13,图13是本发明实施例公开的一种电子设备的结构示意图。如图13所示,该电子设备可以包括:
存储有可执行程序代码的存储器710;
与存储器710耦合的处理器720;
其中,处理器720调用存储器710中存储的可执行程序代码,执行实施例一至实施例三任意一种文本检测的方法中的部分或全部步骤。
本发明实施例公开一种计算机可读存储介质,其存储计算机程序,其中,该计算机程序使得计算机执行实施例一至实施例三任意一种文本检测的方法中的部分或全部步骤。
本发明实施例还公开一种计算机程序产品,其中,当计算机程序产品在计算机上运行时,使得计算机执行实施例一至实施例三任意一种文本检测的方法中的部分或全部步骤。
本发明实施例还公开一种应用发布平台,其中,应用发布平台用于发布计算机程序产品,其中,当计算机程序产品在计算机上运行时,使得计算机执行实施例一至实施例三任意一种文本检测的方法中的部分或全部步骤。
在本发明的各种实施例中,应理解,所述各过程的序号的大小并不意味着执行顺序的必然先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物单元,即可位于一个地方,或者也可以分布到多个网络单元上。可根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。
另外,在本发明各实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。所述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元若以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可获取的存储器中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或者部分,可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储器中,包括若干请求用以使得一台计算机设备(可以为个人计算机、服务器或者网络设备等,具体可以是计算机设备中的处理器)执行本发明的各个实施例所述方法的部分或全部步骤。
在本发明所提供的实施例中,应理解,“与a对应的b”表示b与a相关联,根据a可以确定b。但还应理解,根据a确定b并不意味着仅仅根据a确定b,还可以根据a和/或其他信息确定b。
本领域普通技术人员可以理解所述实施例的各种方法中的部分或全部步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质包括只读存储器(read-onlymemory,rom)、随机存储器(randomaccessmemory,ram)、可编程只读存储器(programmableread-onlymemory,prom)、可擦除可编程只读存储器(erasableprogrammableread-onlymemory,eprom)、一次可编程只读存储器(one-timeprogrammableread-onlymemory,otprom)、电子抹除式可复写只读存储器(electrically-erasableprogrammableread-onlymemory,eeprom)、只读光盘(compactdiscread-onlymemory,cd-rom)或其他光盘存储器、磁盘存储器、磁带存储器、或者能够用于携带或存储数据的计算机可读的任何其他介质。
以上对本发明实施例公开的一种文本检测的方法、装置、电子设备和存储介质进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!