一种固定环境内异常物品实时检测方法与流程
本发明涉及异常物品实时监测方法,属于深度强化学习技术领域。
背景技术:
通常,对于某一特定的环境中,异常物品的出现容易引发不安全性。比如消防通道中的占道物品、地铁站内的异常物品等,对异常物品的实时检测具有重要的社会意义和经济价值。
然而,在现有的监控系统中,主要还是依靠视频监控系统,有工作人员进行人眼识别,虽然已经存在一些人体行为的异常检测及预警方式,但是地铁站内的各类异常也可能是由其他原因导致的;由此可见,现有的检测和预警方式无法让控制中心直观的获取各类信息,同时各类应急方案也无法进行预演,无法验证应急方案的准确性。
技术实现要素:
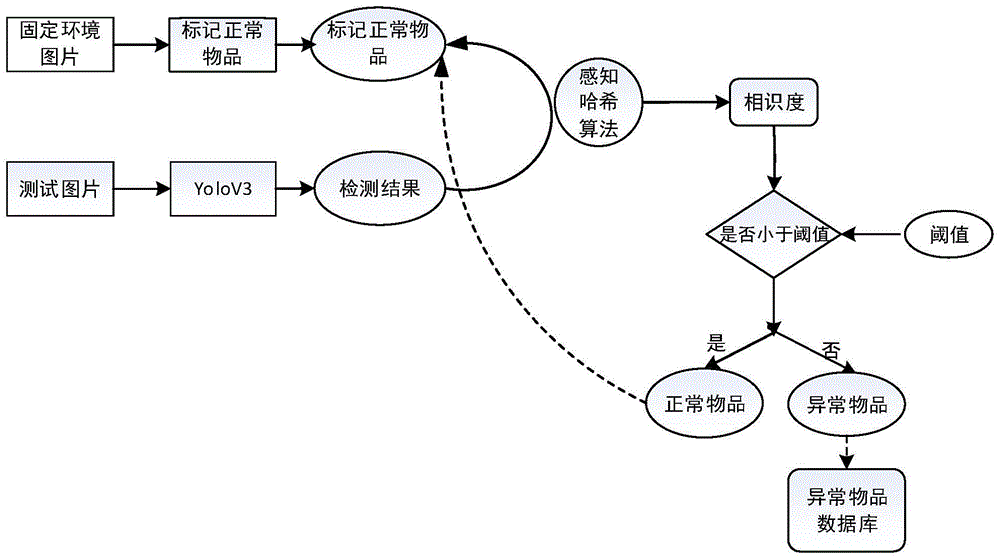
因此,本发明的目的在于克服上述现有技术的缺陷,提供一种固定环境内异常物品实时检测方法,能够对固定环境中的正常物品和异常物品进行识别。建立固定环境内正常物品数据库,运用目标识别算法将固定环境中所有物体进行检测,设计感知哈希算法对检测物品和正常物品数据库中物品进行一一比对,获得相似度值。当相似度值低于设定阈值时,即视为异常物品,并加入异常物品数据库。具体方案如下:
标记原始固定环境内的正常物品,并将其从原图片中取出放入正常物品数据库。
初始化标定:标记原始固定环境内的正常物品,采用的方式为人工标定主导,自动检测辅助的方式。当模型首次运行时,采用人工标记的方式标记已有的固定物品,框定物品的区域,保存到正常物品数据库。随后模型对输入的视频帧进行检测,输出模型识别的目标,框定到图片中,由人工继续操作,确认模型框定的区域为正常物品,并且添加到正常物品数据库。
动态标定:随着模型的运行,环境可能存在细微的变化,每当因环境变化产生物品增加或者减少的情况,可在模型检测出异常的情况下,进行人工干预,修正正常物品数据库。
利用voc数据集训练yolov3算法模型。
pascalvoc作为基准数据集之一,在对象检测、图像分割网络对比实验与模型效果评估中被频频使用。本发明采用pascalvoc2012对模型进行训练,主要使用的数据为main(存放的是图像物体识别的数据,总共分为20类)和segmentation(存放的是可用于分割的数据)两类数据来训练yolov3目标识别模型。
在基本的图像特征提取方面,yolo3采用了称之为darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络residualnetwork的做法,在一些层之间设置了快捷链路(shortcutconnections)。yolov3一共有9个anchor,不过被平均分在了3个特征层中,这也实现了多尺度检测。
对预测的中心坐标做损失:
该等式计算了相对于预测的边界框位置(x,y)的loss数值。该函数计算了每一个网格单元(i=0,...,s2)的每一个边界框预测值(j=0,...,b)的总和。λcoord表示做x相对坐标回归的系数。
对边界框的宽高做损失:
yolov3的误差度量反应出大箱子的小偏差要小于小箱子。为了逐步解决这个问题,yolov3预测了边界框的宽度和高度的平方根,而不是直接预测宽度和高度。wi表示预测宽度,
对预测的类别做损失
pi(c)为预测类别,
除了
对预测的置信度做损失
此处yolov3模型计算了与每个边界框预测值的置信度得分相关的损失。c是置信度得分,
将训练好的模型输出h5文件保存到本地,以便调用。
测试图片首先通过yolov3算法进行目标识别,检测结果依次和正常物品数据库中的图片共同送入感知哈希算法,进行一一计算,并获得相似度的值。
yolov3识别场景中出现的物品,得到框选之后的图片,使用opencv对框选物体进行裁剪,将图片缩小到8x8的尺寸,总共64个像素。摒弃不同尺寸、比例带来的图片差异。使得一张图片中的物品分离成各个单独的图像,送入感知哈希检测模型。
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。然后使用dct是把图片分解频率聚集和梯状形,虽然jpeg使用8*8的dct变换,在本发明中是使用的32*32的dct变换。虽然dct的结果是32*32大小的矩阵,但只要保留左上角的8*8的矩阵,这部分呈现了图片中的最低频率。式(5)为dct算法计算公式,c(u)定义为(6)式。其中,f(i)为原始的信号,f(u)是dct变换后的系数,n为原始信号的点数,c(u)可以认为是一个补偿系数,可以使dct变换矩阵为正交矩阵。
得到8*8矩阵之后,通过计算64个值的平均值,根据8*8的dct矩阵,设置0或1的64位的哈希值,大于等于dct均值的设为1,小于dct均值的设为0。但是,结果并不能表示真实性的低频率,只能粗略地表示相对于平均值频率的相对比例。只要图片的整体结构保持不变,哈希结果值就不变。能够避免伽马校正或颜色直方图被调整带来的影响。
组合64个bit位生成hash值,顺序随意但前后保持一致性即可,将32*32的dct转换成32*32的图像,得到图片的指纹。得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算汉明距离(hammingdistance)。
当相似度的值大于阈值时,则认为该检测结果为正常物品,并将该图片放置正常物品数据库。
本质上两张图片经过感知哈希算法计算之后,等同于得到了二进制化的一个输出数组,有多那么只需要计算两个输出数组有多少个不同的位,就得到了汉明距离是多少,式(7)为汉明距离的计算方法,x,y为两个数组。如果不相同的数据位不超过5,就说明两张图片很相似;则检测物品为正常物品。否则,如果汉明距离大于10,可以认为这是两张不同的图片。则将该图片放置于异常物品数据库。
与现有技术相比,本发明的优点在于:
可以检测到场景中本来不应该出现的异常物品,极大地解放了人力,提高了人们的生活质量。对于环境中的物品,可以实时动态监测,加快了预警,提高安全性能。
附图说明
图1为根据本发明一个实施例的系统框架图;
图2为根据本发明一个实施例的yolov3模型框架图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。具体技术方案如下:
本发明公开了一种固定环境内异常物品实时检测方法,能够对固定环境中的正常物品和异常物品进行识别。建立固定环境内正常物品数据库,运用目标识别算法将固定环境中所有物体进行检测,设计感知哈希算法对检测物品和正常物品数据库中物品进行一一比对,获得相似度值。当相似度值低于设定阈值时,即视为异常物品,并加入异常物品数据库。具体方案如下:
1)标记原始固定环境内的正常物品,并将其从原图片中取出放入正常物品数据库。
初始化标定:标记原始固定环境内的正常物品,采用的方式为人工标定主导,自动检测辅助的方式。当模型首次运行时,采用人工标记的方式标记已有的固定物品,框定物品的区域,保存到正常物品数据库。随后模型对输入的视频帧进行检测,输出模型识别的目标,框定到图片中,由人工继续操作,确认模型框定的区域为正常物品,并且添加到正常物品数据库。
动态标定:随着模型的运行,环境可能存在细微的变化,每当因环境变化产生物品增加或者减少的情况,可在模型检测出异常的情况下,进行人工干预,修正正常物品数据库。
2)利用voc数据集训练yolov3算法模型。
在yolo算法问世之前,有效的目标检测方法以r-cnn为代表两阶段算法,他们存在一个通用的响应速度过慢的问题。yolo提出直接一步完成检测的思想,创新性地提出了将输入图片进行n*n的栅格化(每个小单元叫gridcell),然后将图片中某个对象的位置的预测任务交与该对象中心位置所在的gridcell的boudingbox。简单理解的话,可以认为这也是一种很粗糙的区域推荐(regionproposal),在训练的时候,我们通过gridcell的方式告诉模型,图片中对象a应该是由中心落在特定gridcell的某个范围内的某些像素组成,模型接收到这些信息后就在gridcell周围以一定大小范围去寻找所有满足对象a特征的像素,经过很多次带惩罚的尝试训练后,它就能找到这个准确的范围了。
pascalvoc作为基准数据集之一,在对象检测、图像分割网络对比实验与模型效果评估中被频频使用。本发明采用pascalvoc2012对模型进行训练,主要使用的数据为main(存放的是图像物体识别的数据,总共分为20类)和segmentation(存放的是可用于分割的数据)两类数据来训练yolov3目标识别模型。
在基本的图像特征提取方面,yolo3采用了称之为darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络residualnetwork的做法,在一些层之间设置了快捷链路(shortcutconnections)。
如图2模型框架图所示,结构表示yolov3有三个输出,输出的维度分别是(batchsize,52,52,75),(batchsize,26,26,75),(batchsize,13,13,75)。这里的75代表的3×(20+5),其中20代表的是voc数据集目标类别数,5代表的是每个目标预测框的t_x,t_y,t_w,t_h,t_o,3代表的是某一个特征图的anchor,也即先验框的数目。所以yolov3一共有9个anchor,不过被平均分在了3个特征层中,这也实现了多尺度检测。
对预测的中心坐标做损失:
该等式计算了相对于预测的边界框位置(x,y)的loss数值。该函数计算了每一个网格单元(i=0,...,s2)的每一个边界框预测值(j=0,...,b)的总和。λcoord表示做x相对坐标回归的系数。
对边界框的宽高做损失:
yolov3的误差度量反应出大箱子的小偏差要小于小箱子。为了逐步解决这个问题,yolov3预测了边界框的宽度和高度的平方根,而不是直接预测宽度和高度。wi表示预测宽度,
对预测的类别做损失
pi(c)为预测类别,
除了
对预测的置信度做损失
此处yolov3模型计算了与每个边界框预测值的置信度得分相关的损失。c是置信度得分,
将训练好的模型输出h5文件保存到本地,以便调用。
测试图片首先通过yolov3算法进行目标识别,检测结果依次和正常物品数据库中的图片共同送入感知哈希算法,进行一一计算,并获得相似度的值。
yolov3识别场景中出现的物品,得到框选之后的图片,使用opencv对框选物体进行裁剪,将图片缩小到8x8的尺寸,总共64个像素。摒弃不同尺寸、比例带来的图片差异。使得一张图片中的物品分离成各个单独的图像,送入感知哈希检测模型。
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。然后使用dct是把图片分解频率聚集和梯状形,虽然jpeg使用8*8的dct变换,在本发明中是使用的32*32的dct变换。虽然dct的结果是32*32大小的矩阵,但只要保留左上角的8*8的矩阵,这部分呈现了图片中的最低频率。式(5)为dct算法计算公式,c(u)定义为(6)式。其中,f(i)为原始的信号,f(u)是dct变换后的系数,n为原始信号的点数,c(u)可以认为是一个补偿系数,可以使dct变换矩阵为正交矩阵。
得到8*8矩阵之后,通过计算64个值的平均值,根据8*8的dct矩阵,设置0或1的64位的哈希值,大于等于dct均值的设为1,小于dct均值的设为0。但是,结果并不能表示真实性的低频率,只能粗略地表示相对于平均值频率的相对比例。只要图片的整体结构保持不变,哈希结果值就不变。能够避免伽马校正或颜色直方图被调整带来的影响。
组合64个bit位生成hash值,顺序随意但前后保持一致性即可,将32*32的dct转换成32*32的图像,得到图片的指纹。得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算汉明距离(hammingdistance)。
当相似度的值大于阈值时,则认为该检测结果为正常物品,并将该图片放置正常物品数据库。
本质上两张图片经过感知哈希算法计算之后,等同于得到了二进制化的一个输出数组,有多那么只需要计算两个输出数组有多少个不同的位,就得到了汉明距离是多少,式(7)为汉明距离的计算方法,x,y为两个数组。如果不相同的数据位不超过5,就说明两张图片很相似;则检测物品为正常物品。否则,如果汉明距离大于10,可以认为这是两张不同的图片。则将该图片放置于异常物品数据库。
本发明不限于上述实施例,对于本领域技术人员来说,对本发明的上述实施例所做出的任何改进或变更都不会超出仅以举例的方式示出的本发明的实施例和所附权利要求的保护范围,所描述的实施例仅旨在便于对本发明的理解,而对其不起任何限定作用。
- 还没有人留言评论。精彩留言会获得点赞!