基于Hive数据仓库的数据列级血缘处理系统及方法与流程
本发明涉及数据处理技术领域,特别涉及一种基于hive数据仓库的数据列级血缘处理系统及方法。
背景技术:
对于大数据而言,数据仓库存储着整个企业的全部业务数据。当前的大数据技术都是基于hadoop生态的大数据框架,而数据仓库也基本上是基于hive的数据仓库。hive是基于hadoop的一个数据仓库工具,hive本身并不提供数据的存储功能,而是使用hadoop中的hdfs组件实现数据的分布式存储。hive的主要作用是将hdfs中的结构化的数据映射为一张二维的数据库表,并且提供sql的查询功能。hive会将用户的sql语句通过解释器转换为mapreduce作业提交到hadoop集群上,由hadoop监控作业执行过程,然后返回作业执行结果给用户。
数据血缘表示的是数据生产过程中的链路关系。在数据仓库中的数据集合会通过数据的融合、联合、转换、变换等操作,又生成新的数据集合。数据与数据之间会串成一条链路,从而自然的形成一种上下游的依赖关系,这种关系我们称为数据血缘。目前实现hive数据血缘的方法主要有三种:
第一种是使用hive的原生api,利用hive自身提供的事件拦截机制hivehooks,在hive任务执行完成之后,获取hive中的任务执行上下文,同时结合hive的lineageinfoapi来解析当前hive任务的数据血缘关系。这种方案是较为常见的解决方案,在hadoop生态中的数据治理组件apacheatlas中有着广泛的使用。该方案有使用简单、解析准确的优点,并且数据血缘的粒度可达到列级血缘。但是缺点也很明显,利用hive的hooks事件会导致数据血缘解析功能与hive组件之间的强耦合,无法在任意时刻独立的进行数据血缘分析,只有在hive完成任务之后下才能实现数据血缘分析。
第二种是直接对sql语句进行解析,将sql语句进行词法分析、语法分析,把sql语句转化为ast抽象语法树。再由抽象语法树中的节点,递归分析从而得到数据血缘关系。这种方案克服了第一种方案中耦合性强的缺点,通过单独的对sql进行解析实现了数据血缘功能和hive之间的完全解耦。但是这种方案明显增加了数据血缘功能的实现难度,并且由于该方案完全脱离hive组件,所以解析结果会缺失对hive上下文的理解,例如:*关键字、${}变量、udf函数等,所以该方案会缺失部分解析精度和准确性。
第三种是针对mapreduce作业解析,hive执行的sql最终会提交为mapreduce作业。通过mapreduce作业日志中的输入输出解析数据血缘关系。该方案兼容性差对于不同的hadoop版本需要适配不同的解析方案,并且该方案的数据血缘解析粒度只能到达表级。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的一个目的在于提出一种基于hive数据仓库的数据列级血缘处理系统,该系统在保证数据血缘功能和hive数据仓库之间的低耦合的前提下,实现了数据血缘解析结果的细粒度和高准确性。
本发明的另一个目的在于提出一种基于hive数据仓库的数据列级血缘处理方法。
为达到上述目的,本发明一方面实施例提出了一种基于hive数据仓库的数据列级血缘处理系统,包括:
sql预处理模块,用于对用户输入的sql信息进行预处理;
sql解析模块,用于将预处理后的sql信息解析为具体hive执行计划;
数据血缘解析模块,用于根据所述具体hive执行计划,结合hive执行上下文信息,解析出对应的数据血缘依赖关系;
数据存储模块,用于将所述数据血缘依赖关系,以数据上下游依赖关系的形式存储进入数据库。
本发明实施例的基于hive数据仓库的数据列级血缘处理系统,通过在使用hive底层的sql解析工具,实现了在本地对数据血缘的解析,克服了强耦合性的缺点,将数据血缘解析功能与hive任务执行过程解耦。同时通过使用hive原生的sql解析工具与hivemetastore服务,并且设置元数据信息缓存,解决了对于hivesql语法解析准确性差、无法进行元数据信息校验、对hive上下文理解缺失等问题。该系统在保证数据血缘功能和hive数据仓库之间的低耦合的前提下,实现了数据血缘解析结果的细粒度和高准确性。
另外,根据本发明上述实施例的基于hive数据仓库的数据列级血缘处理系统还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,所述sql信息包括:sql文件、sql字符串、sql字符流;
所述预处理包括:去除注释、去除换行转义字符、对sql用分号分割、对sql语句进行分类。
进一步地,在本发明的一个实施例中,所述sql解析模块包括:语法树解析单元、生成解析树单元和生成执行计划单元;
所述语法树解析单元,用于将预处理后的sql信息进行词法解析、语法解析,生成相应的ast抽象语法树;
所述生成解析树单元,用于通过所述ast抽象语法树节点的深度遍历,解析出每个ast抽象语法树节点所包含的查询信息,从而得到sql信息相应的解析树,并且会填充对应的元数据信息和hive执行上下文信息;
生成执行计划单元,用于遍历所述解析树每一个节点,读取节点的信息从而生成相应的操作树,并且将所述操作树构建为所述具体hive执行计划。
进一步地,在本发明的一个实施例中,所述sql解析模块与元数据信息缓存和hivemetastore进行元数据信息交互。
进一步地,在本发明的一个实施例中,所述生成解析树单元,具体用于,首先在所述元数据信息缓存中获取元数据信息,如果获取不到再从所述hivemetastore服务中获取元数据信息,获取到元数据信息后,对所述ast抽象语法树中的节点进行元数据信息的替换,并且对相应的元数据信息进行校验,元数据信息填充校验完成之后输出所述解析树。
进一步地,在本发明的一个实施例中,所述生成执行计划单元,具体用于,将所述解析树转化为包含具体操作类型的操作树,并且结合所述操作树与hive执行上下文信息,生成逻辑执行计划和物理执行计划,将所述物理执行计划中涉及到的元数据信息提取出来,并且存储到所述元数据信息缓存中,输出所述具体hive执行计划至所述数据血缘模块处理。
进一步地,在本发明的一个实施例中,所述数据血缘解析模块,具体用于,
在所述sql信息包括多条sql语句文件时,判断每条sql语句的具体hive执行计划的计划类型;
在所述计划类型为与执行上下文相关的计划时,则提取具体hive执行计划中设置的信息,并对本地的执行器对象修改信息;
在所述计划类型为与数据血缘相关的执行计划时,则将当前的执行计划与当前的上下文信息合并,再进行数据血缘信息的提取;
若所述计划类型不是与执行上下文相关的执行计划,也不是与数据血缘相关的执行计划时,则会跳过解析处理的过程,处理下一个sql语句。
进一步地,在本发明的一个实施例中,所述数据血缘信息的提取包括:
依靠所述具体hive执行计划中的数据依赖提取所述具体hive执行计划中的数据列血缘关系;
将提取到的数据列血缘关系与列血缘缓存中的血缘关系进行比对合并,得到合并优化后的血缘关系;
依据数据列血缘关系,获取对应的列信息,并且保存在缓存中。
为达到上述目的,本发明另一方面实施例提出了一种基于hive数据仓库的数据列级血缘处理方法,包括:
对用户输入的sql信息进行预处理;
将预处理后的sql信息解析为具体hive执行计划;
根据所述具体hive执行计划,结合hive执行上下文信息,解析出对应的数据血缘依赖关系;
将所述数据血缘依赖关系,以数据上下游依赖关系的形式存储进入数据库。
本发明实施例的基于hive数据仓库的数据列级血缘处理方法,通过在使用hive底层的sql解析工具,实现了在本地对数据血缘的解析,克服了强耦合性的缺点,将数据血缘解析功能与hive任务执行过程解耦。同时通过使用hive原生的sql解析工具与hivemetastore服务,并且设置元数据信息缓存,解决了对于hivesql语法解析准确性差、无法进行元数据信息校验、对hive上下文理解缺失等问题。该方法在保证数据血缘功能和hive数据仓库之间的低耦合的前提下,实现了数据血缘解析结果的细粒度和高准确性。
另外,根据本发明上述实施例的基于hive数据仓库的数据列级血缘处理方法还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,将预处理后的sql信息解析为具体hive执行计划进一步包括:
将预处理后的sql信息进行词法解析、语法解析,生成相应的ast抽象语法树;
通过所述ast抽象语法树节点的深度遍历,解析出每个ast抽象语法树节点所包含的查询信息,从而得到sql信息相应的解析树,并且会填充对应的元数据信息和hive执行上下文信息;
遍历所述解析树每一个节点,读取节点的信息从而生成相应的操作树,并且将所述操作树构建为所述具体hive执行计划。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
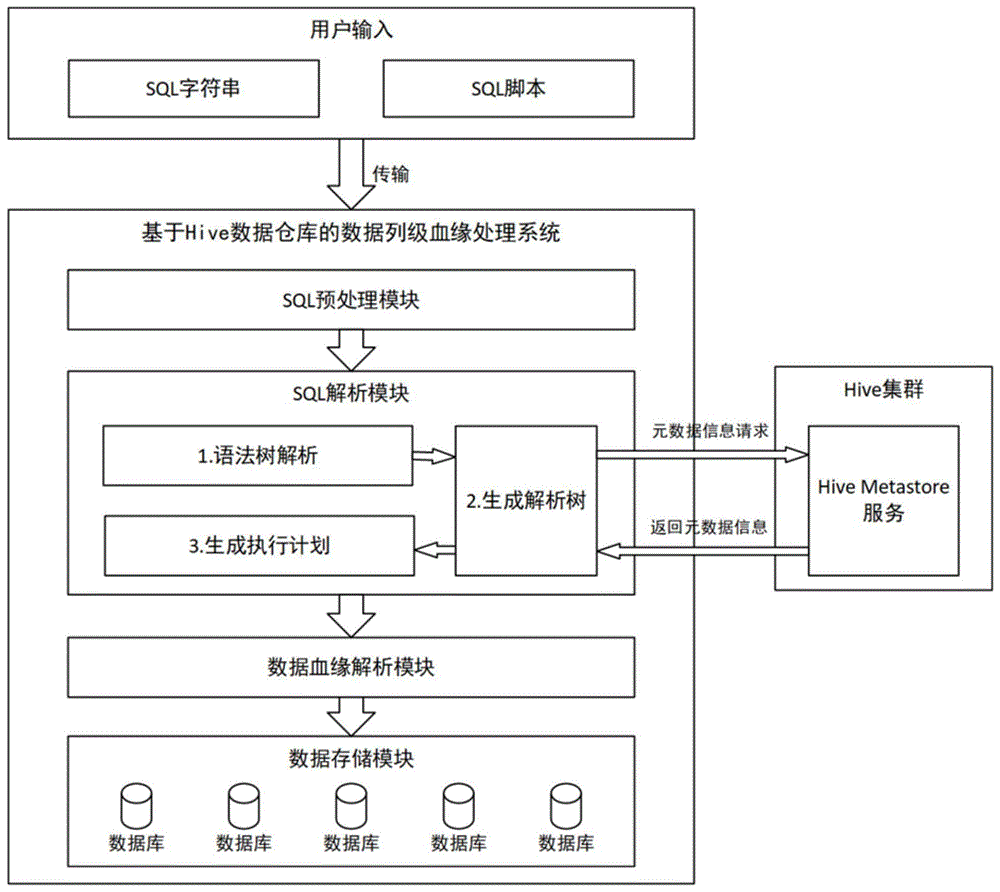
图1为根据本发明一个实施例的基于hive数据仓库的数据列级血缘处理系统结构框架图;
图2为根据本发明一个实施例的sql解析模块处理流程图;
图3为根据本发明一个实施例的数据血缘解析模块处理流程图;
图4为根据本发明一个实施例的基于hive数据仓库的数据列级血缘处理方法流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参照附图描述根据本发明实施例提出的基于hive数据仓库的数据列级血缘处理系统及方法。
首先将参照附图描述根据本发明实施例提出的基于hive数据仓库的数据列级血缘处理系统。
图1为根据本发明一个实施例的基于hive数据仓库的数据列级血缘处理系统结构框架图。
如图1所示,该基于hive数据仓库的数据列级血缘处理系统包括:sql预处理模块、sql解析模块、数据血缘解析模块和数据存储模块。
sql预处理模块,用于对用户输入的sql信息进行预处理。
sql预处理模块主要是对输入的sql信息进行简单的预处理,如去除注释、去除换行转义字符、对sql用分号分割、对sql语句进行简单的分类等。输入的形式可以包括:sql文件、sql字符串、sql字符流。
sql解析模块,用于将预处理后的sql信息解析为具体hive执行计划。
sql解析模块是对于hive的原始流程进行简化重构,该模块能将预处理的sql信息解析为具体hive执行计划。
其中,sql解析模块与元数据信息缓存和hivemetastore进行元数据信息交互,可以解决本地解析时临时表元数据信息缺失的问题。
sql解析模块包括:语法树解析单元、生成查询块单元、生成逻辑执行计划单元三个部分。
语法树解析单元,用于将预处理后的sql信息进行词法解析、语法解析,生成相应的ast抽象语法树。
生成解析树单元,用于通过ast抽象语法树节点的深度遍历,解析出每个ast抽象语法树节点所包含的查询信息,从而得到该sql信息相应的解析树,并且会填充对应的元数据信息和hive执行上下文信息。
生成执行计划单元,用于遍历解析树每一个节点,读取节点的信息从而生成相应的操作树,并且将操作树构建为具体hive执行计划。
数据血缘解析模块,用于根据具体hive执行计划,结合hive执行上下文信息,解析出对应的数据血缘依赖关系。
具体地,针对sql解析模块生成的执行计划,该模块会结合hive执行上下文,解析出对应的数据血缘依赖关系。
可以理解的是,由执行计划转换为数据血缘的解析方法,解决了临时表导致无效血缘的问题,以及优化了执行计划转换为数据血缘的执行效率。
数据存储模块,用于将数据血缘依赖关系,以数据上下游依赖关系的形式存储进入数据库。
结合实施例及附图对各个模块进行详细说明。
本发明的实施例基于hive底层对sql语句的解析工具,以及hivemetastore所提供的元数据服务,对hive数据仓库解析sql的原始流程进行重构与模拟。减少了hive执行过程中的各种hooks调用、并发锁的抢占等流程,提高了对sql解析的执行效率。并且由于本发明使用的是原生hive底层对sql语句的解析工具,所以能保证sql语句解析结果的高准确性,以及列级粒度的数据血缘关系。
在执行sql解析的过程中,本发明只需和hivemetastore服务进行元数据信息的交互,完整的sql解析过程只在本地进行不依赖与hive集群任务的执行,大大的降低了数据血缘处理系统与hive集群之间的耦合性,从而能够在hive任务执行之前,实现对数据血缘处理结果的预览。并且通过与hivemetastore服务进行元数据信息的交互能实现对*关键字、${}变量等语法的安全性、可靠性检测。
在sql解析模块中,生成解析树单元,具体用于,首先在元数据信息缓存中获取元数据信息,如果获取不到再从hivemetastore服务中获取元数据信息,获取到元数据信息后,对ast抽象语法树中的节点进行元数据信息的替换,并且对相应的元数据信息进行校验,元数据信息填充校验完成之后输出解析树。生成执行计划单元,具体用于,将解析树转化为包含具体操作类型的操作树,并且结合操作树与hive执行上下文信息,生成逻辑执行计划和物理执行计划,将物理执行计划中涉及到的元数据信息提取出来,并且存储到元数据信息缓存中,输出具体hive执行计划至数据血缘模块处理。
图2为根据本发明一个实施例的sql解析模块处理流程图。如图2所示,sql解析模块首先会将传入的sql语句,按照antlr4所定义的语法文件进行一个初步的语法解析,输出ast抽象语法树。此时的ast语法树只能分析校验sql语法的正确,无法理解具体的元数据信息。
下一步,将对ast抽象语法树继续进行解析,该模块会首先在元数据信息缓存中获取,如果获取不到再从hivemetastore服务中获取元数据信息。获取到元数据信息之后,对ast抽象语法树中的节点进行元数据信息的替换,并且对相应的元数据信息进行校验。元数据信息填充校验完成之后输出解析树。
接下来会将解析树转化为包含具体操作类型的操作树,并且会结合操作树与hive上下文信息,生成逻辑执行计划和物理执行计划。然后较为关键的步骤是会将物理执行计划中涉及到的元数据信息提取出来,并且存储到元数据信息的缓存中,此步操作是为了提高本地执行元数据信息查询效率,并且可以防止sql语句中临时表元数据的信息缺失。最后会输出最终的执行计划,给下一步的数据血缘模块处理。
sql解析模块的伪代码如下:
从物理计划中提取元数据信息的伪代码如下:
数据血缘解析模块,具体用于,
在sql信息包括多条sql语句文件时,判断每条sql语句的具体hive执行计划的计划类型;
在计划类型为与执行上下文相关的计划时,则提取具体hive执行计划中设置的信息,并对本地的执行器对象修改信息;
在计划类型为与数据血缘相关的执行计划时,则将当前的执行计划与当前的上下文信息合并,再进行数据血缘信息的提取;
若计划类型不是与执行上下文相关的执行计划,也不是与数据血缘相关的执行计划时,则会跳过解析处理的过程,处理下一个sql语句。
数据血缘信息的提取包括:
依靠具体hive执行计划中的数据依赖提取具体hive执行计划中的数据列血缘关系;
将提取到的数据列血缘关系与列血缘缓存中的血缘关系进行比对合并,得到合并优化后的血缘关系;
依据数据列血缘关系,获取对应的列信息,并且保存在缓存中。
根据上述的sql解析处理流程可知,最终数据血缘的解析还需要从执行计划中获取。但是sql解析处理后的执行计划只是针对于单独的sql语句。如果在执行sql文件时,需要处理多条sql语句之间的上下文关系。所以本发明针对处理sql文件的数据血缘做了特殊的处理和优化,以保证对于存在上下文关联的sql语句能顺利解析,并且消除了sql文件执行过程中中间表对最终输出的数据血缘的影响。同时在保证数据血缘解析准确性的前提下,去除了与数据血缘无关的sql语句,从而提高了程序的执行效率。数据血缘解析方法流程如下图3所示。
数据血缘解析模块首先会对执行计划进行优化处理,执行计划主要划分为三类:与执行上下文相关、涉及到数据血缘相关、其他无关类型。针对与上下文相关的执行计划,程序会提取其中设置的信息,例如:切换当前数据库。并且对本地的执行器对象修改信息,从而保证接下来的sql解析时能读取到正确的上下文信息。针对与到数据血缘相关的执行计划,程序会将当前的执行计划与当前的上下文信息合并,传入到下一步骤,对其进行血缘信息提取。针对其他无关类型的执行计划,程序会跳过对其解析处理的过程,直接处理下一个sql语句。
解析优化伪代码:
下一步将数据血缘的信息进行提取,依靠执行计划中的数据依赖提取其中的数据血缘关系。数据依赖中可能存在重复依赖、无效依赖,这都需要除去。之后将提取到的数据列血缘关系与列血缘缓存中的血缘关系进行比对合并,最终得到合并优化后的血缘关系。然后在依据列血缘关系,获取对应的列信息,并且将其保存在缓存中。
血缘信息提取伪代码:
血缘关系合并伪代码:
最终在对全部的sql语句执行完成之后,将缓存中的数据列血缘关系和数据列信息合并输出,得到最终的数据列级血缘信息。
数据列级血缘信息样例:
根据本发明实施例提出的基于hive数据仓库的数据列级血缘处理系统,通过在使用hive底层的sql解析工具,实现了在本地对数据血缘的解析,克服了强耦合性的缺点,将数据血缘解析功能与hive任务执行过程解耦。同时通过使用hive原生的sql解析工具与hivemetastore服务,并且设置元数据信息缓存,解决了对于hivesql语法解析准确性差、无法进行元数据信息校验、对hive上下文理解缺失等问题。该系统在保证数据血缘功能和hive数据仓库之间的低耦合的前提下,实现了数据血缘解析结果的细粒度和高准确性。
其次参照附图描述根据本发明实施例提出的基于hive数据仓库的数据列级血缘处理方法。
图4为根据本发明一个实施例的基于hive数据仓库的数据列级血缘处理方法流程图。
如图4所示,该基于hive数据仓库的数据列级血缘处理方法包括以下步骤:
s1,对用户输入的sql信息进行预处理;
s2,将预处理后的sql信息解析为具体hive执行计划;
s3,根据具体hive执行计划,结合hive执行上下文信息,解析出对应的数据血缘依赖关系;
s4,将数据血缘依赖关系,以数据上下游依赖关系的形式存储进入数据库。
进一步地,在本发明的一个实施例中,将预处理后的sql信息解析为具体hive执行计划进一步包括:
将预处理后的sql信息进行词法解析、语法解析,生成相应的ast抽象语法树;
通过ast抽象语法树节点的深度遍历,解析出每个ast抽象语法树节点所包含的查询信息,从而得到sql信息相应的解析树,并且会填充对应的元数据信息和hive执行上下文信息;
遍历解析树每一个节点,读取节点的信息从而生成相应的操作树,并且将操作树构建为具体hive执行计划。
需要说明的是,前述对基于hive数据仓库的数据列级血缘处理系统实施例的解释说明也适用于该实施例的方法,此处不再赘述。
根据本发明实施例提出的基于hive数据仓库的数据列级血缘处理方法,通过在使用hive底层的sql解析工具,实现了在本地对数据血缘的解析,克服了强耦合性的缺点,将数据血缘解析功能与hive任务执行过程解耦。同时通过使用hive原生的sql解析工具与hivemetastore服务,并且设置元数据信息缓存,解决了对于hivesql语法解析准确性差、无法进行元数据信息校验、对hive上下文理解缺失等问题。该方法在保证数据血缘功能和hive数据仓库之间的低耦合的前提下,实现了数据血缘解析结果的细粒度和高准确性。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!