一种能源化工生产系统多元监测时间序列回归预测方法与流程
本发明属于能源化工生产系统监测时间序列回归预测领域,具体涉及一种能源化工生产系统多元监测时间序列回归预测方法。
背景技术:
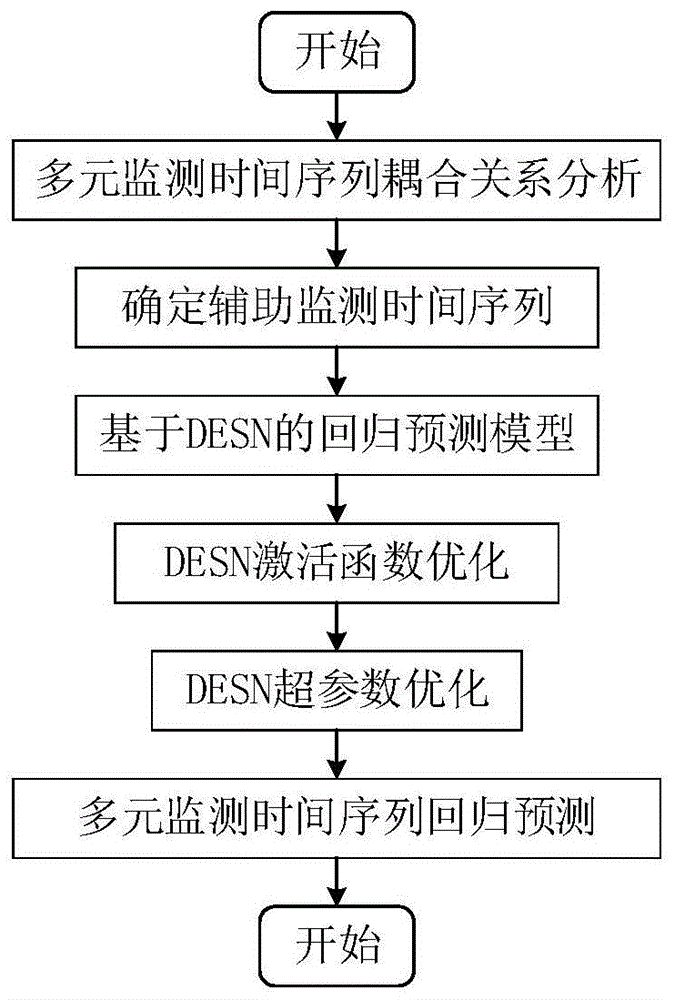
:在能源化工生产系统中,各类测量仪表、传感器等测量设备的监测数据是实现设备状态监测和生产精准化管控的基础,然而系统中许多测量设备经常因为出现故障而向控制系统传送虚假数据,从而影响系统的平稳运行,通过基于能源化工生产系统多元监测时间序列回归预测的方式来实现异常仪表的检测及数据重构对于维持系统的安全平稳运行具有重大意义。当前,随着传感控制技术及计算机集成技术的普及和不断发展,能源化工生产系统不断向大型化、集成化、信息化、智能化方向高速发展,与此同时,对系统运行状态监测的要求也越来越高。因此,能源化工企业需要通过大量的各种测量仪表充分采集反映设备运行状态、产品质量等相关工业数据以实现对系统运行状态的准确评估,从而实现生产系统的高效、精准化控制。准确、可靠的测量数据是实现系统服役状态准确评估的基础,然而许多生产装置中的测量仪表因为受恶劣生产环境的影响而经常出现各种故障,这些故障仪表的虚假测量数据极易引起对系统服役状态的错误评估,进而引起控制系统的误操作,影响系统的安全平稳运行。因此,通过基于多元监测时间序列回归预测的方式来实现异常仪表的检测及数据重构对于维持能源化工生产系统的安全平稳运行具有重大意义。能源化工生产系统多元监测时间序列回归预测研究作为一个具有重大意义地研究课题,引起了国内外许多学者的关注。然而,现有的能源化工生产系统多元监测时间序列的回归预测研究没有严格的辅助监测时间序列选择方法,而且采用的回归预测模型一般都是基于主元回归分析、卡尔曼滤波器等只具备线性映射能力的模型。然而,在实际的工程应用中,能源化工生产系统中监测时间序列间耦合关系强度大不相同,部分监测时间序列耦合关系紧密,有的则只具有较弱的耦合关系,前者有助于目标监测时间序列的回归预测,后者则相反;更为重要的是能源化工生产系统中的监测时间序列具有混沌性、非线性、非平稳性等特征,传统的多元监测时间序列回归预测在针对此类回归预测任务时获得结果不甚理想。因此,亟需一种考虑能源化工生产系统监测时间序列间耦合关系,并且具备较强非线性映射能力的高精度多元监测时间序列回归预测方法。技术实现要素:本发明的目的在于提供一种能源化工生产系统多元监测时间序列回归预测方法,以克服现有技术的不足。为达到上述目的,本发明采用如下技术方案:一种能源化工生产系统多元监测时间序列回归预测方法,包括以下步骤:步骤1)、收集能源化工生产系统多元监测时间序列历史数据,利用符号传递熵计算方法度量多元监测时间序列历史数据的耦合关系,根据耦合关系强弱程度确定目标监测时间序列回归预测的辅助监测时间序列;步骤2)、根据步骤1)得到辅助监测时间序列,采用深度回声状态网络建立目标监测时间序列的回归预测模型;步骤3)、采用leaky-relu激活函数优化回归预测模型的激活函数;步骤4)、利用差分进化算法对步骤3)优化后的回归预测模型的超参数进行优化,利用超参数优化后的回归预测模型进行目标监测时间序列的回归预测。进一步的,步骤1)中多元监测时间序列耦合关系计算具体包括以下步骤:1.1)、对能源化工生产系统中每个监测时间序列进行相空间重构,相空间重构的延迟时间t和嵌入维数m分别采用互信息法和cao方法确定;1.2)、对于进行符号传递熵计算的两个监测时间序列应该有相同的相空间重构参数,其公共相空间重构参数为:式中,m—表示公共嵌入维数,t—表示公共延迟时间,int—表示取整;1.3)、通过步骤1.2)获得公共相空间重构参数后,进行监测时间序列的相空间重构,设监测时间序列x={x1,x2,…,xn-1,xn}的长度为n,按照嵌入理论,其相空间重构矩阵为:式中,nm——重构的相空间矩阵中相点个数,且nm=n-(m-1)τ;τ——延迟时间;m——嵌入维数,且m≥2d+1;1.4)、对步骤1.3)获得的相空间矩阵进行符号化以获得符号序列,对每一个m维xt=(xt,xt+τ,...,xt+(m-1)τ)向量,时间t按等级kt1升序排列为相等幅值则按时间指数排列;每个m维向量的符号序列排列为:1.5)、通过步骤1.4)得到nm个符号序列,统计每个符号序列出现的频率,计算相关条件概率和联合概率,按照公式(4)计算符号传递熵:1.6)、根据步骤1.5)符号传递熵的计算结果,选取与目标监测时间序列有较强耦合关系的监测时间序列作为辅助监测时间序列。进一步的,监测时间序列之间的耦合关系值若大于设定的耦合阈值,则作为辅助监测时间序列,监测时间序列之间的耦合关系值小于设定的耦合阈值,则舍弃。进一步的,将选择的辅助监测时间序列作为输入,采用回声状态网络desn建立目标监测时间序列的回归预测模型,并对回归预测模型进行学习训练。进一步的,回声状态网络模型学习训练过程具体包括以下步骤:2.1)、初始化回声状态网络模型,在选取储备池参数l、n、sr、is和sd的基础上生成储备池及其对应的邻接矩阵wi,随机生成权值矩阵wiin和wback,设置储备池的初始状态x(0);在之后的训练过程中,wiin、wi和wback均不再更新;l—深度储备池的层数,n—单层储备池神经元个数,sr—储备池谱半径,is—储备池输入单元尺度,sd—储备池稀疏程度;2.2)、深度储备池状态更新,回声状态网络模型的深度储备池层的状态更新方程方式如下:xi(t+1)=(1-ξ)xt(t)+fout(wiinli(t+1)+wixi(t))(5)其中,xi代表第i个储备池的状态,代表第i个储备池的内部神经元间的连接权值矩阵,ni代表第i个储备池内部的神经元个数;wiin表示第i个储备池与外部输入间的输入权值矩阵,各储备池的输入矩阵大小符合如下公式:其中,nu表示输入层的神经元个数;2.3)、网络状态收集:回声状态网络模型具有多个储备池,需要将各储备池每一步的网络状态矩阵都进行收集,组成一个状态收集矩阵s,即:s(t)=[x1(t),x2(t)…,xl(t)](7)其中,l表示储备池层数;2.4)、计算输出权值矩阵,回声状态网络模型的输出状态矩阵d和网络状态矩阵s以及输出权值矩阵wout有如下关系:d=swout(8)采用线性回归的方式求解wout,即:wout=s-1d(9)使用状态矩阵s伪逆s+1代替s-1,即:wout=s+1d(10)。进一步的,对差分进化算法模型进行初始化:确定适应度函数、设置基本参数和确定解空间及解分量控制限,完成初始化后初始化种群并计算初始种群的适应度值,若初始种群中有个体的适应度值为零或者初始化达到设定的最大的进化代数,则停止进化并输出最优解,否则继续迭代进化直至达到设定的最大的进化代数则停止进化。进一步的,步骤4)具体包括以下步骤:4.1、确定回声状态网络模型的适应度函数,设置适应度函数的适应度值,即将回声状态网络模型desn在测试集上的回归预测误差作为适应度值;4.2、设置差分进化算法的基本参数;4.3、设置解空间所有分量的上下限,将desn模型每个超参数都对应解空间中的一个解分量,根据各超参数的取值范围,设置对应解分量的上下限,根据相应参数初始化种群;4.4、计算初始化后种群的适应度值。进一步的,在迭代进化过程中,对种群间个体进行变异操作:首先在种群中随机选取三个不同个体xr1(t)、xr2(t)、xr3(t),将第一个视为待变异个体,然后计算其余两个个体的向量差并用缩放因子对其进行缩放,最后将待变异个体和经过缩放的向量差进行向量求和得到变异中间体,其计算公式如下:hi(t+1)=xr1(t)+f*(xr2(t)-xr3(t))(11)式中:hi(t+1)表示变异个体;r1、r2、r3是三个随机取得的整数,取值区间为[1,np];f是缩放因子,t表示第t代;在迭代进化过程中,对种群间个体进行交叉操作:在第t进化过程中,在当前种群{xi(t)}和变异中间体{vi(t+1)}中进行个体间的交叉操作,其公式如下:其中,cr表示交叉概率;在迭代进化过程中,对种群间个体进行选择操作:根据贪婪选择的策略挑选出适应度值更优的个体进入下一代种群,其公式如下:式中,f(·)表示适应度函数。进一步的,将回声状态网络模型在测试集上的回归预测误差作为适应度值。进一步的,差分进化算法的基本参数包括种群规模nr、缩放因子f和交叉概率cr。与现有技术相比,本发明具有以下有益的技术效果:本发明提出一种能源化工生产系统多元监测时间序列回归预测方法,采用符号传递熵计算方法度量能源化工系统多元监测时间的耦合关系,根据耦合关系强弱程度确定有助于目标监测时间序列回归预测精度的辅助监测时间序列,从而避免无关监测时间序列对目标监测时间序列回归预测的影响,在此基础上,采用深度回声状态网络模型作为回归预测模型,为提高模型的非线性映射能力,采用leaky-relu激活函数优化回归预测模型的激活函数,使得模型的非线性映射能力更强,采用差分进化算法进行回归预测模型超参数优化,从而使得多元监测时间序列的回归预测精度更高,本发明为实现异常仪表的检测及数据重构提供一种有效的解决方案,对于维持能源化工生产系统的安全平稳运行具有重大意义,有利于实现能源化工企业生产系统地稳定、高效、优质运行。附图说明图1为本发明实施例中流程框图。具体实施方式下面结合附图对本发明做进一步详细描述:如图1所示,本发明一种能源化工生产系统多元监测时间序列回归预测方法,包括以下步骤:步骤1)、多元监测时间序列耦合关系分析:收集能源化工生产系统多元监测时间序列历史数据,利用符号传递熵计算方法度量多元监测时间序列历史数据的耦合关系,根据耦合关系强弱程度确定目标监测时间序列回归预测的辅助监测时间序列;具体过程如下:1.1)、为准确度量多元监测时间序列的耦合关系,符号传递熵计算过程中需要对所有监测的多元监测时间序列历史数据进行相空间重构;根据嵌入理论,相空间重构的延迟时间t和嵌入维数m分别采用互信息法和cao方法确定;首先分别计算两个时间序列的相空间重构参数,进行传递熵计算的两个时间序列的相空间重构参数相同;1.2)、确定两个时间序列的公共相空间重构参数:式中,m—表示公共嵌入维数,t—表示公共延迟时间,int—表示取整。1.3)、通过步骤1.2)获得公共相空间重构参数后,进行监测时间序列的相空间重构,设监测时间序列x={x1,x2,…,xn-1,xn}的长度为n,则其相空间重构矩阵为:式中,nm——重构的相空间矩阵中相点个数,且nm=n-(m-1)τ;τ——延迟时间;m——嵌入维数,且m≥2d+1;1.4)、对步骤1.3)获得的相空间矩阵进行符号化以获得符号序列,对每一个m维xt=(xt,xt+τ,...,xt+(m-1)τ)向量,时间t按等级kt1升序排列为相等幅值则按时间指数排列。这样就保证了每一个xt都唯一的与m!种排列对应,则每个m维向量的符号序列排列为:1.5)、通过步骤1.4)得到nm个符号序列,统计每个符号出现的频率并计算相关联合概率和条件概率,按照公式(4)计算符号传递熵:1.6)、根据步骤1.5)计算结果,选取与目标监测时间序列有较强耦合关系的监测时间序列作为辅助监测时间序列;具体的,根据计算结果,监测时间序列之间的耦合关系值若大于设定的耦合阈值,则作为辅助监测时间序列,监测时间序列之间的耦合关系值小于设定的耦合阈值,则舍弃;本申请设定的耦合阈值为0.2。步骤2)、将选择的辅助监测时间序列作为输入,采用回声状态网络模型desn建立目标监测时间序列的回归预测模型;desn的学习训练过程如下:2.1)、初始化desn,在选取储备池参数l、n、sr、is和sd的基础上生成储备池及其对应的邻接矩阵wi,随机生成权值矩阵wiin和wback,设置储备池的初始状态x(0);在之后的训练过程中,wiin、wi和wback均不再更新;其中,l—深度储备池的层数,n—单层储备池神经元个数,sr—储备池谱半径,is—储备池输入单元尺度,sd—储备池稀疏程度。2.2)、深度储备池状态更新,回声状态网络模型desn的深度储备池层的状态更新方程方式如下:xi(t+1)=(1-ξ)xt(t)+fout(wiinli(t+1)+wixi(t))(5)其中,xi代表第i个储备池的状态,代表第i个储备池的内部神经元间的连接权值矩阵,ni代表第i个储备池内部的神经元个数。wiin表示第i个储备池与外部输入间的输入权值矩阵,由于深度储备池最底层储备池与输入层连接,而其余储备池与其下层的储备池连接,因此各储备池的输入矩阵大小符合如下公式:其中,nu表示输入层的神经元个数。2.3)、网络状态收集,回声状态网络模型desn具有多个储备池,需要将各储备池每一步的网络状态矩阵都进行收集,组成一个状态收集矩阵s,即:s(t)=[x1(t),x2(t)…,xl(t)](7)其中,l表示储备池层数。2.4)、计算输出权值矩阵,回声状态网络模型desn的输出状态矩阵d和网络状态矩阵s以及输出权值矩阵wout有如下关系:d=swout(8)因此,可以采用线性回归的方式求解wout,即:wout=s-1d(9)但是由于状态矩阵s一般情况下不为方阵,因而无法获取其逆矩阵s-1,通常使用s伪逆s+1代替s-1,即:wout=s+1d(10)步骤3)、对回声状态网络模型desn的激活函数进行优化,采用leaky-relu激活函数代替回声状态网络模型desn中的tanh激活函数;步骤4)、利用差分进化算法对步骤3)优化后的回归预测模型的超参数进行优化,利用超参数优化后的回归预测模型进行目标监测时间序列的回归预测。具体步骤如下:对差分进化算法模型进行初始化,进行初始化过程中对差分进化算法模型进行变异、交叉和选择,获取初始化后差分进化算法模型的种群的适应度值,若第一个适应度值为零或者初始化达到设定的最大的进化代数,则停止进化并输出最优解。具体的,4.1、确定回声状态网络模型的适应度函数,设置适应度函数的适应度值,即将回声状态网络模型desn在测试集上的回归预测误差作为适应度值;4.2、设置差分进化算法de的基本参数,差分进化算法de的基本参数包括:种群规模nr、缩放因子f、交叉概率cr;4.3、设置解空间所有分量的上下限,将desn模型每个超参数都对应解空间中的一个解分量,根据各超参数的取值范围,设置对应解分量的上下限,根据相应参数初始化种群;4.4、计算初始化后种群的适应度值,若第一个适应度值为零或者达到设定的最大的进化代数t,停止进化并输出最优解;本申请进化代数t取80。进行初始化过程中对差分进化算法模型进行变异、交叉和选择具体操作如下:4.5.1、变异操作,变异规则如下:首先在种群中随机选取三个不同个体xr1(t)、xr2(t)、xr3(t),将第一个视为待变异个体,然后计算其余两个个体的向量差并用缩放因子对其进行缩放,最后将待变异个体和经过缩放的向量差进行向量求和得到变异中间体,其计算公式如下:hi(t+1)=xr1(t)+f*(xr2(t)-xr3(t))(11)式中:hi(t+1)表示变异个体;r1、r2、r3是三个随机取得的整数,取值区间为[1,np];f是缩放因子,t表示第t代。4.5.2、交叉操作,在第t进化过程中,在当前种群{xi(t)}和变异中间体{vi(t+1)}中进行个体间的交叉操作,其公式如下:其中,cr表示交叉概率。4.5.3、选择操作,根据贪婪选择的策略挑选出适应度值更优的个体进入下一代种群,其公式如下:式中,f(·)表示适应度函数。实施例:应用某能源化工企业生产系统中的压缩机组实际监测数据对基于改进desn多元监测时间序列回归预测方法进行详细说明。选择压缩机组中12个监测时间序列的历史数据,各监测时间序列的相关信息如下表所示:表1监测时间序列信息表从压缩机组集散控制系统中导出以上监测点位1天内的实际监测数据作为样本数据,取样间隔一分钟,数据总量为1440。根据本发明的研究方案,以6号点位的监测数据序列作为要预测目标监测时间序列,首先通过符号传递熵计算方法分析目标监测时间序列和其余监测时间序列的耦合关系,选出对目标监测时间序列有较强影响关系的辅助监测时间序列,并将其作为回归预测模型的输入数据,将目标监测时间序列作为输出;在此基础上,采用深度回声状态网络desn作为回归预测模型,为提高模型的非线性映射能力,将原模型中的神经元激活函数替换为性能更优的激活函数,进一步的,采用差分进化算法进行desn超参数优化,从而使得多元监测时间序列的回归预测精度更高,具体实现步骤如下:根据嵌入理论计算所有监测时间序列的相空间重构参数,采用延迟时间τ和嵌入维数m分别通过互信息法和cao方法确定,获得的相空间重构参数如下:表2多变量相空间重构参数序号123456789101112延迟时间10142015721121512182217嵌入维数644574365546以计算4号监测时间序列与6号目标监测时间序列的耦合关系为例说明符号传递熵计算流程。依据公式(1)可知公共嵌入维数为5,延迟时间为18,然后根据公式(2)分别对两个时间序列进行相空间重构,然后按照公式(4)对重构的相空间进行符号化,统计每个符号出现的频率并计算相关联合概率和条件概率,按照公式(4)计算得到4号监测时间序列和6号监测时间序列之间的信息传递强度为0.18,方向为4号到6号。与此类似,计算其余监测时间序列和6号监测时间序列的耦合强度,结果表明4号、5号、9号、10号、12号5个监测时间序列对6号监测时间序列有较强的信息传递关系。故此,以4号、5号、9号、10号、12号5个监测时间序列作为输入数据,采用传统desn对6号监测时间序列进行回归预测。为了提高回归预测精度,激活函数和超参数两个方面对传统desn模型进行优化,其中激活函数的优化采用leaky-relu激活函数;超参数优化按照步骤4)进行,首先将样本数据的前700个点作为训练集,701-1000的数据作为测试集,将经过优化后的desn在测试集上的误差作为适应度值,差分进化算法的进化代数、种群规模、缩放因子、交叉概率分别设为80、30、0.35、0.85,初步设置desn的6个超参数,即将储备池层数、储备池神经元个数、泄露率、储备池谱半径、储备池缩放因子、储备池稀疏程度分别设置为15、30、0.90、0.90、0.100、0.02,并将设定各个超参数的取值范围,然后进行进化迭代优化,最终得到当desn模型的超参数储备池层数、储备池神经元个数、泄露率、储备池谱半径、储备池缩放因子、储备池稀疏程度分别为8、17、0.82、0.77、0.14、0.03时在测试集上的误差最小。为了验证本发明所提出的多元监测时间序列回归预测模型较之传统的回归预测模型有更高的回归预测精度,采用传统的多元监测时间序列回归预测方法和本发明提出的多元监测时间序列回归预测方法(idesn)进行对比,传统的多元时间序列预测方法分别为主元回归分析(pca)、深度回声状态网络(desn)。采用准均方根误差enrms作为评价回归预测精度的指标,enrms的计算表达式如下所示:式中:yt——实际值;——回归预测值;m——回归预测的样本数量;σ2——预测时间序列样本的方差。采用前文中提到的监测数据的300至1100的样本作为训练集,后340的样本作为测试集,各预测模型的结果如下表所示。表3多元监测时间序列回归预测结果对比回归预测模型pcrdesnidesn回归预测精度3.362×10-21.758×10-27.763×10-3从回归预测结果可以看出:本文提出的多元监测时间序列预测方法比传统的多元监测时间序列预测方法具有更高回归预测精度。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1