一种检测行人是否佩戴安全帽的方法及装置与流程
本发明属于目标检测和识别技术领域,具体涉及一种检测行人是否佩戴安全帽的方法及装置。
背景技术:
安全帽是防物体打击和坠落时头部碰撞的头部防护装置,施工工人通过佩戴安全帽,用以防护头部,免受坠落的物件伤害。但经常存在施工工人没有佩戴安全帽的情况发生,对安全帽的佩戴情况进行实时的监控至关重要。
现有技术中,对工作人员安全帽佩戴的检测方法采用机器学习的方式。但是,现有的检测算法不能使用标签缺失的数据,比如想要同时检测安全帽和行人,通常需要分别训练安全帽检测网络或行人检测网络,或者在同一个神经网络中训练安全帽检测通道和行人检测通道。但在上述检测网络的训练过程中,需要完整的、单独带有安全帽标签的图像样本和单独带有行人标签的图像样本,而若训练集合中出现标签缺失,则会影响检测网络检测结果的准确度。
另一方面,现有的工作人员安全帽佩戴的检测方法无法进行人物对象跟踪,如专利2018115389580公开了一种实现安全帽穿戴识别的方法,该方法通过安全帽检测网络提取安全帽框,通过人体检测网络提取人体框。检测完成后,根据人体框的尺寸预测人体姿态,再根据人体姿态计算出不同姿态下安全帽正确的佩戴区域,对每个人体框,判断是否有安全帽框位于其相应的正确的佩戴区域内,若有匹配不上的,则进行告警。
也就是说,这类现有技术仅能判断当前帧中是否所有人均佩戴安全帽,只要检测出有人没有佩戴就进行告警,但是,这类现有技术无法识别是哪个人没有佩戴安全帽,更无法在接下来的视频中对特定的人进行跟踪,得到这个人在一段时间内的安全帽佩戴情况。而单张图像的检测很容易存在误差,若图像中存在多个人的人体图像重合,采用上述方法很容易误检。
技术实现要素:
发明目的:针对于上述现有技术的不足,本发明提供一种检测行人是否佩戴安全帽的方法及装置,本发明提出的技术方案能够基于标签缺失的训练数据进行训练,训练后的检测网络检测结果更准确,另一方面,本发明提出的技术方案能够基于检测网络的检测结果对目标行人进行跟踪,基于一段时间目标行人的安全帽佩戴情况判断其真实的安全帽佩戴情况,判断结果更加准确,能够很大程度上避免误检。
发明内容:为实现上述技术效果,本发明提出的技术方案为:
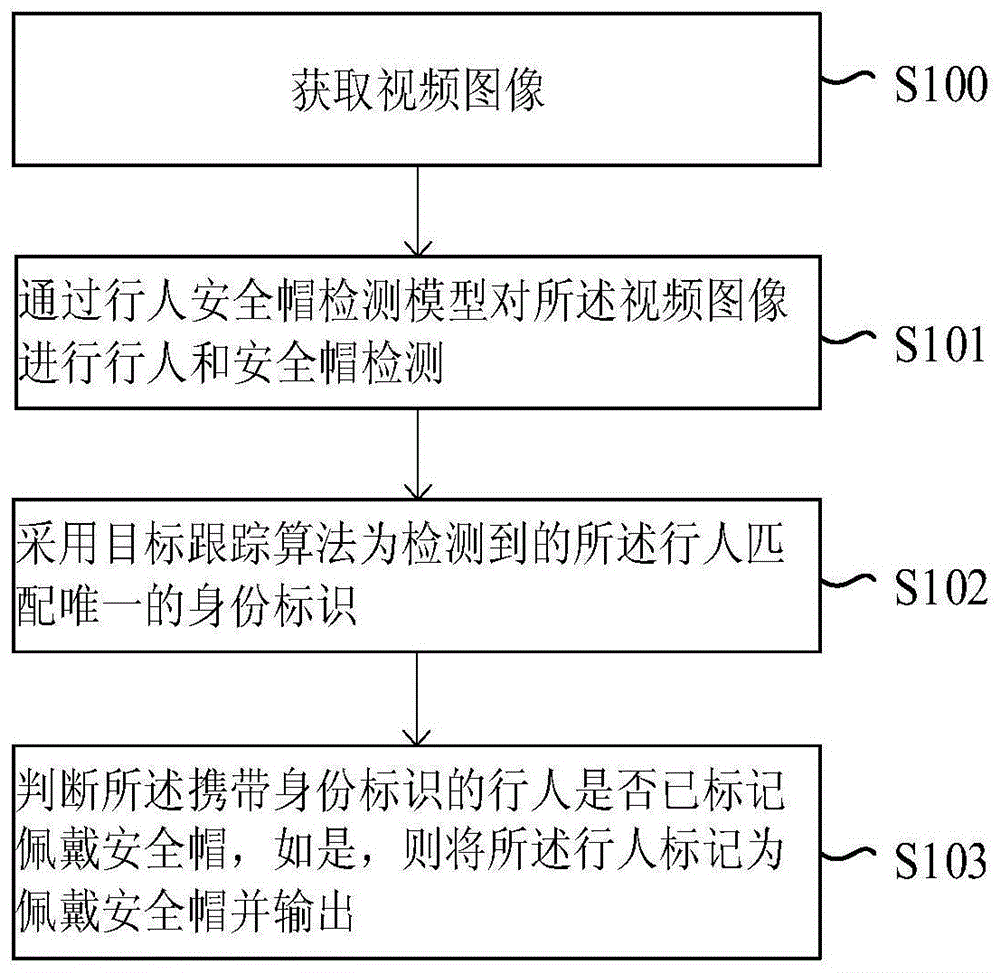
一种检测行人是否佩戴安全帽的方法,包括以下步骤:
(1)构建第一训练图像集合:将以下至少两种图像的组合作为第一训练图像集合:仅添加了安全帽标签的图像、仅添加了人体标签的图像、同时带有安全帽标签和人体标签的图像;为第一训练图像添加分类标注t[n,b],得到第二训练图像;t[n,b]表示第b个第一训练图像中第n个检测任务的标记情况,若已标注,则t[n,b]取值为1,若未标注,t[n,b]取值为0;n有两个不同的取值,分别对应安全帽检测任务和人体检测任务;
(2)训练行人-安全帽检测模型:搭建基于神经网络的行人-安全帽检测模型,行人-安全帽检测模型具有一个输入通道和两个输出通道,两个输出通道分别为安全帽检测通道和人体检测通道;通过梯度更新法在第二训练图像集合上训练行人-安全帽检测模型,直至损失函数的值收敛至预设阈值;行人-安全帽检测模型的损失函数为:loss=∑n∑blossn,b*t[n,b],用第b个第二训练图像对行人-安全帽检测模型进行训练时,行人-安全帽检测模型的权重更新为:
(3)人体和安全帽检测:将待检测视频的视频帧图像输入训练好的人体-安全帽检测模型,得到每一帧视频帧图像中的人体目标矩形框和安全帽矩形框;
(4)通过特征提取网络提取每一帧视频帧中人体目标矩形框中的行人的人体特征;为每个行人分配一个身份标识,根据人体目标矩形框将属于同一个行人的人体目标矩形框与相应的身份标识关联;
(5)选取任意未标记佩戴安全帽的行人作为跟踪目标,在连续n帧中对跟踪目标进行安全帽匹配:计算当前帧中跟踪目标的人体目标矩形框中心点与每个安全帽矩形框中心点之间的相对距离,若存在某个安全帽矩形框中心点与跟踪目标的人体目标矩形框中心点之间的相对距离小于最小阈值d,则判定当前帧中跟踪目标匹配安全帽成功,否则,判定匹配失败;若连续n帧中跟踪目标均成功匹配安全帽,则判定跟踪目标佩戴安全帽,为跟踪目标添加表示佩戴安全帽的标记;否则,判定跟踪目标未佩戴安全帽,输出跟踪目标的身份标识。
进一步的,所述行人-安全帽检测模型基于yolov3神经网络实现。
进一步的,所述特征提取网络为卷积神经网络cnn。
本发明还提出一种检测行人是否佩戴安全帽的装置,包括:
获取单元,用于获取视频图像并将视频图像分解为视频帧图像;
检测单元,用于通过行人-安全帽检测模型对视频帧图像进行行人和安全帽检测;
跟踪单元,用于对每一帧视频帧图像中检测出的行人进行人体特征提取,并为相同的人体特征分配同一个身份标识;
判断单元,用于对每一个携带身份标识的行人进行安全帽匹配,根据连续n帧的匹配结果判断行人是否佩戴安全帽,并将佩戴安全帽的行人标记为佩戴安全帽并输出。
本发明的有益效果:
本方案能够基于标签缺失的不平衡数据训练出高准确度的检测模型,节省了大量人工标注成本;并且使得安全帽检测准确率泛化性增强,准确率提高。
其次,采用目标跟踪方法,使得视频内的行人对象化,为每一个出现在视频内的行人都分配唯一id,并对其是否佩戴安全帽进行多帧长时间检测,极大的降低了误报率。
附图说明
图1为本发明实施例中涉及的检测行人是否佩戴安全帽的方法的流程图;
图2为本发明实施例中涉及的行人与安全帽匹配流程图;
图3为本发明实施例中涉及的yolov3神经网络结构示意图。
具体实施方式
为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。
图1所示为检测行人是否佩戴安全帽的方法的流程图,具体包括以下步骤:
步骤1、构建第一训练图像集合:将同时带有安全帽标签和人体标签的图像的集合作为第一训练图像集合;或,将以下至少两种图像的组合作为第一训练图像集合:仅添加了安全帽标签的图像、仅添加了人体标签的图像、同时带有安全帽标签和人体标签的图像;为第一训练图像添加分类标注t[n,b],得到第二训练图像;t[n,b]表示第b个第一训练图像中第n个检测任务的标记情况,若已标注,则t[n,b]取值为1,若未标注,t[n,b]取值为0;n有两个不同的取值,分别对应安全帽检测任务和人体检测任务;
步骤2、训练行人-安全帽检测模型:搭建基于神经网络的行人-安全帽检测模型,行人-安全帽检测模型具有一个输入通道和两个输出通道,两个输出通道分别为安全帽检测通道和人体检测通道;通过梯度更新法在第二训练图像集合上训练行人-安全帽检测模型,直至损失函数的值收敛至预设阈值;行人-安全帽检测模型的损失函数为:loss=∑n∑blossn,b*t[n,b],用第b个第二训练图像对行人-安全帽检测模型进行训练时,行人-安全帽检测模型的权重更新为:
步骤3、人体和安全帽检测:将待检测视频的视频帧图像输入训练好的人体-安全帽检测模型,得到每一帧视频帧图像中的人体目标矩形框和安全帽矩形框;
步骤4、通过特征提取网络提取每一帧视频帧中人体目标矩形框中的行人的人体特征;为每个行人分配一个身份标识,根据人体目标矩形框将属于同一个行人的人体目标矩形框与相应的身份标识关联;
步骤5、选取任意未标记佩戴安全帽的行人作为跟踪目标,在连续n帧中对跟踪目标进行安全帽匹配:计算当前帧中跟踪目标的人体目标矩形框中心点与每个安全帽矩形框中心点之间的相对距离,若存在某个安全帽矩形框中心点与跟踪目标的人体目标矩形框中心点之间的相对距离小于最小阈值d,则判定当前帧中跟踪目标匹配安全帽成功,否则,判定匹配失败;若连续n帧中跟踪目标均成功匹配安全帽,则判定跟踪目标佩戴安全帽,为跟踪目标添加表示佩戴安全帽的标记;否则,判定跟踪目标未佩戴安全帽,输出跟踪目标的身份标识。
步骤1构建了第一训练图像集合,这个集合可以是数据平衡的样本集合,也可以是标签缺失的不平衡样本集合。下面以标签缺失的不平衡样本集合为例,阐述本发明如何实现行人-安全帽检测模型的训练。
例如,原始的样本图像包括:部分行人图片数据,其中标注行人的图片(仅标注行人,60000+张);标注安全帽与行人的图片9000张。在该样本图像中,缺少仅标注安全帽的图片,造成数据集不平衡,标签缺失。
为解决该问题,本发明实施例中引入了新的分类标注,即:对所述第一训练图像进行标注以获取第二训练图像。具体的,将行人与安全帽检测任务分离,并为每张训练数据添加一个分类标注,即是否包含行人检测任务或安全帽检测任务的标注,如表1所示。
表1
在本实施方式中,每个图像的分类标注由两位数字组成,我们用t[n,b]表示新增的分类标注,t[n,b]=[t[1,b],t[2,b]];其中,b表示第b张图像,n表示检测任务,如表1所示,n取1表示行人检测任务,n取2表示安全帽检测任务。t[1,b]=1就表示在第b个样本图像中行人检测任务已经标注,t[1,b]=0就表示在第b个样本图像中行人检测任务没有标注,t[2,b]=1表示在第b个样本图像中安全帽检测任务已经标注,t[2,b]=0表示在第b个样本图像中安全帽检测任务未标注。
步骤2训练了行人-安全帽检测模型,下面详细描述通过上述第二训练图像训练卷积神经网络以获取行人-安全帽检测模型的方法。
在本实施例中,我们选取yolov3目标检测网络作为行人-安全帽检测模型,我们重新设计了yolov3目标检测算法的网络结构以及损失函数,重新设计后的网络结构如图3所示,其中,每个输出张量包括2个并行的卷积核,分别对应行人、安全帽检测输出。损失函数的设计过程如下:
对于每一张图片的每一个任务的损失有lossn,b,n=[1,2],则网络最终损失函数loss为:
loss=∑n∑blossn,b*t[n,b]=∑n∑bt[n,b]*(losscoorderr+lossiouerr)n,b
其中,losscoorderr为边框误差,lossiouerr为边框iou误差,(losscoorderr+lossiouerr)n,b表示第b个样本图像中第n个任务的边框误差与边框iou误差之和。
用第b个第二训练图像对行人-安全帽检测模型进行训练时,行人-安全帽检测模型的权重更新为:
其中,lossn,b表示第b个第二训练图像中第n个检测任务的损失函数,η为学习效率,
从上数损失函数可知,当t[n,b]=0时,第b张图片的第n个任务的损失函数对任意一个w的更新为0,即权重参数的更新贡献为0,也就是w′=w;而当t[n,b]=1时,第b张图片的第n个任务的损失才可以正常更新网络权重参数,即:
通过对样本图像数据集增加标签,可以使得当样本图像对某个任务标注后,该任务的损失才允许更新网络权重参数,即对该任务进行学习。当样本图像未标注该任务的标签,则该任务的损失不允许更新网络权重参数,即不允许该任务学习。由于进行了任务分离,相当于每一个任务都是一个单类别目标检测器。虽然进行了任务分离,但是网络的训练依然是一次性端到端的训练,无需分任务分批次训练网络。通过上述训练方法,可以获得行人-安全帽检测模型。
重新设计的网络结构与损失函数,通过任务分离解决了数据集不平衡问题,通过为训练集中的每张图像设置新标签t解决了标签缺失问题。这种方法同时也减轻了数据标注成本太高的问题,可以收集不同数据库的数据并通过新增标签融合数据,无需重新标注大量的样本来训练网络。
步骤3、人体和安全帽检测:将待检测视频的视频帧图像输入训练好的人体-安全帽检测模型,得到每一帧视频帧图像中的人体目标矩形框[coord]和安全帽矩形框[helmet_coord],具体如图3所示,这里的人体目标矩形框[coord]和安全帽矩形框[helmet_coord]在输出时都是通过矩形框的坐标来描述的。
步骤4:具体来说,本步骤实质上是通过特征提取网络提取人体目标矩形框中的行人的人体特征,根据人体特征就可以判断出那些人体目标框是属于同一个行人的,此时为行人分配一个id,然后将属于同一个行人人体目标框与这个id关联;这样处理是为了便于后续在连续的视频帧中对目标行人进行跟踪。此处的特征提取网络优选为cnn卷积神经网络。
在步骤4中,因为属于同一个行人的人体特征相同或高度相似,此处优选可以通过计算人体特征相似度的方法判断哪些人体特征属于同一个行人。需要说明的是,采用现有的其他方法对属于同一个行人的人体特征进行分类的,也应纳入本申请的保护范围。
步骤5:步骤5具体是一个行人目标跟踪和并对跟踪的行人目标在连续的一定数量的视频帧中进行安全帽匹配的过程,其流程如图2所示:
选取任意未标记佩戴安全帽的行人作为跟踪目标,在连续n帧中对跟踪目标进行安全帽匹配:计算当前帧中跟踪目标的人体目标矩形框中心点与每个安全帽矩形框中心点之间的相对距离,若存在某个安全帽矩形框中心点与跟踪目标的人体目标矩形框中心点之间的相对距离小于最小阈值d,则判定当前帧中跟踪目标匹配安全帽成功,否则,判定匹配失败;若连续n帧中跟踪目标均成功匹配安全帽,则判定跟踪目标佩戴安全帽,为跟踪目标添加表示佩戴安全帽的标记;否则,判定跟踪目标未佩戴安全帽,输出跟踪目标的身份标识。
在本实施例中,采用目标跟踪的机制对于将视频中的行人对象化(为视频中出现的每个人都分配唯一id)十分重要,能够通过多帧综合判定同一id的行人是否佩戴安全帽,使得极大的降低视频中出现未佩戴安全帽的工人误报率。
本实施例还提出一种检测行人是否佩戴安全帽的装置,包括:
获取单元,用于获取视频图像并将视频图像分解为视频帧图像;
检测单元,用于通过行人-安全帽检测模型对视频帧图像进行行人和安全帽检测;
跟踪单元,用于对每一帧视频帧图像中检测出的行人进行人体特征提取,并为相同的人体特征分配同一个身份标识;
判断单元,用于对每一个携带身份标识的行人进行安全帽匹配,根据连续n帧的匹配结果判断行人是否佩戴安全帽,并将佩戴安全帽的行人标记为佩戴安全帽并输出。
具体来说,所述装置中:
获取单元包括摄像头,摄像头可以包括输入设备、处理器、存储介质、接口,输入设备用于采集视频图像,处理器可以对采集到的视频进行预处理,将视频拆解为一帧一帧的视屏帧图像,并将图像归一化至所述行人-安全帽检测模型输入层所要求的标准大小。存储介质可用于保存采集到的视频帧图像,接口用于与检测单元进行数据传递,接口可为数据线接口或无线接口等。
检测单元、跟踪单元和判断单元均可由存储器和处理器组成,存储器用于存储能够实现各单元功能的相应计算机程序,处理器用于执行程序以实现相应功能。例如:检测单元包括存储器和图像处理器,存储器存储用于实现所述行人-安全帽检测模型功能的计算机程序,以及运行所述行人-安全帽检测模型程序的系统环境参数。图像处理器用于执行存储器存储的程序以实现行人-安全帽检测模型的功能,即对新采集到的视频帧图像进行行人、安全帽检测。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!