基于最长公共子轨迹密度聚类的热点路径挖掘方法与流程
本发明涉及目标路径分析挖掘领域,尤其涉及一种基于最长公共子轨迹之间相似性度量方案的密度聚类的热点路径分析方法。
背景技术:
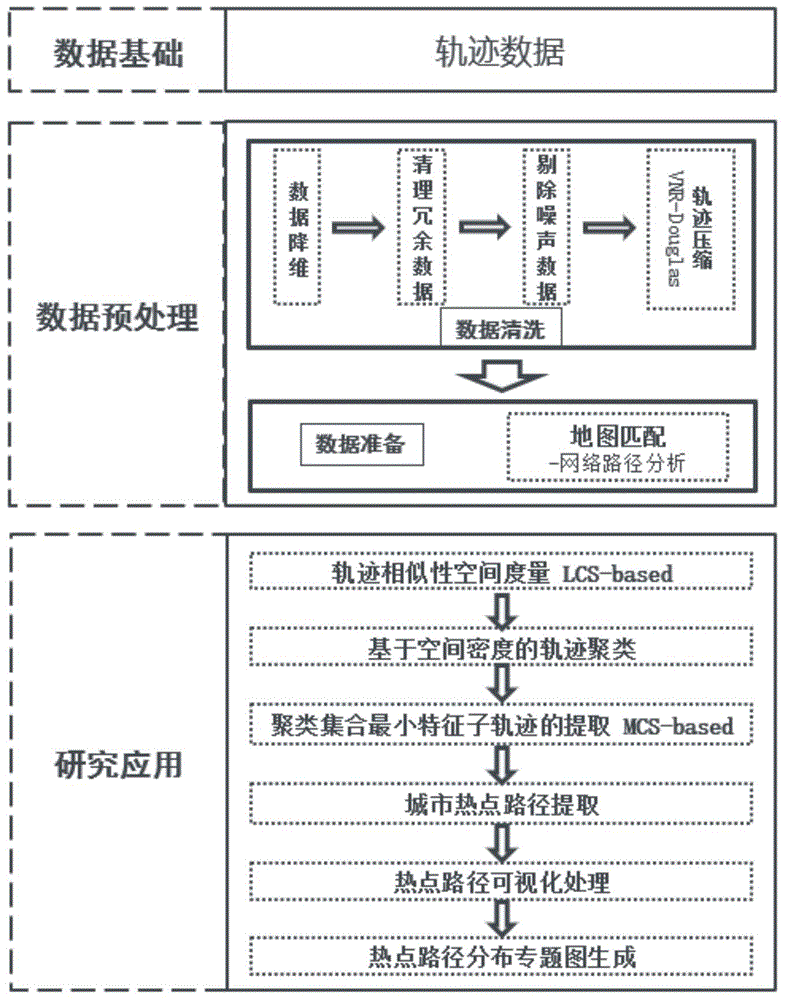
:随着地理信息采集设备快速发展,道路上移动对象的位置信息越来越丰富,数据量也越来越大,轨迹数据直接体现了移动对象的行驶状态和运动规律,热点路径挖掘的应用方向非常广泛,为研究群体运动模式、路线推荐以及交通规划与管理等问题提供重要参考。传统的目标路径分析预测技术仅基于移动对象的位置信息,没有对轨迹进行科学的类别划分,无法通过聚焦高层次的路径特征高效挖掘热点路径的分布,同时,由于轨迹数据一般内嵌于联系的空间中,各个数据中拥有较强的相关性,如果将传统数据挖掘的算法直接应用于轨迹数据的挖掘中,在数据处理以及性能方面都难以达到要求,对挖掘结果的应用也有很大局限性。本发明针对热点路径挖掘的需求,对传统数据挖掘算法的轨迹相似性度量方式进一步修改与优化,使其能够更好的完成对热点路径挖掘需求的目标。技术实现要素:发明目的:针对现有技术问题,本发明提供基于最长公共子轨迹密度聚类的热点路径挖掘方法。技术方案:本发明的基于最长公共子轨迹密度聚类的热点路径挖掘方法,具体包括以下步骤:(1)依据移动设备上的位置信息采集设备得到的位置信息,对采样点构成的轨迹数据集进行轨迹清洗、轨迹压缩以及地图匹配等预处理工作,保留轨迹语义信息的前提下减少采样点数量,便于提升轨迹相似度计算的效率;(2)对轨迹数据集中的每两段轨迹数据,计算它们每个最小轨迹段之间的相似性seg_sim;(3)基于步骤(2)中得到的最小轨迹段之间的相似性,采用动态规划法计算每两条轨迹形成的最长公共子轨迹的长度lcss_n以及相似度lcss_sim;(4)基于步骤(3)计算得到的最长公共子轨迹长度lcss_n、相似度lcss_sim以及两段轨迹的长度tri_n,trj_n,计算得到两条轨迹之间的相似度tr(ij)_sim,计算所有轨迹之间的相似度,形成轨迹相似度的二维矩阵;(5)遍历轨迹数据集中所有轨迹,根据预先输入的轨迹的空间邻域范围阈值eps和核心轨迹近邻数量阈值minpts查找出所有核心轨迹,添加至核心轨迹序列,再遍历核心轨迹数据集中所有轨迹,记录每个与核心轨迹的相似度小于给定阈值eps的直接空间可达轨迹的序号;(6)再次遍历核心轨迹数据集中所有轨迹,依次将不属于任何聚类簇的核心轨迹作为中心轨迹进行聚类簇的生成,将中心轨迹的空间连通轨迹都加入到相应的聚类簇。最终使得每一条核心轨迹都只属于一个聚类簇;(7)对边缘轨迹进行处理,遍历除核心轨迹之外的其他轨迹,根据轨迹相似度判断将边缘轨迹加入相应的聚类簇中,同时不属于任何聚类簇的轨迹则为离群轨迹;(8)遍历每个聚类簇中每条轨迹中的最小子轨迹,计算其与聚类簇中其他轨迹的最小子轨迹之间的距离,小于热点子轨迹距离阈值mcs_thre的最小子轨迹加入相应的栈文件中;(9)遍历所有最小子轨迹的栈文件,对栈中轨迹数量大于热点子轨迹数量阈值mcs_num的轨迹标识为mcs_before;(10)遍历mcs_before集合,得到其对应的栈文件中轨迹起讫点的均值,作为这段mcs_before所生成的最终的最小热点轨迹段,并将其他参与运算的子轨迹段从原始轨迹数据的聚类簇中删除,避免之后二次计算,同时记录最小热点轨迹段是由多少条路径求出的均值作为当前轨迹段的热点等级。步骤(2)-1首先计算两段轨迹tri.k{pt1,pt2}、trj.l{pt3,pt4}的端点之间欧氏距离的均值,具体计算过程参考公式(1)、(2)、(3);dis(tri.k,trj.l)=1/2(dis1+dis2)(3)以设置阈值的方式来得到两段最小轨迹段之间的相似度sim_seg,具体计算过程参考公式(4);如果dis(tri.k,trj.l)>δ则认为两段子轨迹相似度为零,如果dis(tri.k,trj.l)≤δ则认为两段子轨迹具有相似度,也称这两段子轨迹是可以匹配的;由公式也可知0≤dis(tri.k,trj.l)≤1,相似度的值越接近1,表明这两段子轨迹相似程度越高,之后对于最长公共子轨迹相似度的计算、轨迹之间相似度的计算都是基于最小轨迹段之间的相似度。有益效果:本发明提出了一种新的轨迹相似性度量方案,改进轨迹聚类以更好的进行热点路径挖掘,具有较好的可靠性和鲁棒性,通过前期数据的预处理提升计算效率,方法可工程化实现。附图说明图1为本发明的流程图。图2为最小轨迹段相似度计算示意图。图3为信息熵随eps影响变化图。图4为信息熵随minpts影响变化图。图5为热点路径挖掘结果展示图。具体实施方式下面结合附图及实施例对本发明进行详细说明。本发明针对移动对象位置采样点所构成的轨迹数据,依据最长公共子轨迹的方法对轨迹之间的相似性进行度量并利用密度聚类进行轨迹的聚类划分,在此基础上,对每种聚类的簇提取满足核心子轨迹的最小特征子轨迹,其交集作为热点路径挖掘的成果。如图1,基于最长公共子轨迹密度聚类的热点路径挖掘方法,具体包括以下步骤:(1)在移动对象上安装地理位置采集设备,并对车辆不同时间段内的行驶轨迹进行编号区分tr1、tr2、tr3、…,记录各编号对应的车辆实时地理位置信息tr1{pt1,pt2,pt3,…,pti}、tr2{pt1,pt2,pt3,…,ptj}、tr3{pt1,pt2,pt3,…,ptk},为便于之后的数据处理分析,需要先进行数据降噪、冗余数据剔除、噪声数据剔除以及轨迹压缩等数据清洗步骤,然后对所有采样点依据底层路网进行地图匹配的处理,完成数据准备的所有工作;(2)基于步骤(1)所得已经预处理的数据,对(1)中每两段轨迹数据,计算每个最小轨迹段之间的相似性seg_sim,生成轨迹段相似度的二维矩阵;(3)基于步骤(2)中得到的最小轨迹段之间的相似度,来计算每两条轨迹形成的最长公共子轨迹的长度lcss_n以及相似度lcss_sim,具体计算过程参考公式(1);(4)基于步骤(3)计算的得到的最长公共子轨迹长度lcss_n、相似度lcss_sim以及两段轨迹分别的长度tri_n,trj_n,计算得到两条轨迹之间的相似度tr(ij)_sim,具体计算过程参考公式(2);:(5)计算得到所有轨迹两两之间的相似度,生成包含所有轨迹之间相似度的二维矩阵,然后遍历轨迹数据集中所有轨迹,根据预先输入的轨迹的空间邻域范围阈值eps和核心轨迹近邻数量阈值minpts,通过比较轨迹之间相似度与eps的大小以及相似度小于eps的数量查找出所有核心轨迹,添加至核心轨迹序列;(6)遍历核心轨迹数据集中所有轨迹,记录每个与核心轨迹的相似度小于给定阈值eps的轨迹,即直接空间可达轨迹的序号;(7)再次遍历核心轨迹数据集中所有轨迹,依次将不属于任何聚类簇的核心轨迹作为中心轨迹进行聚类簇的生成,将中心轨迹的空间连通轨迹都加入到相应的聚类簇,最终使得每一条核心轨迹都只属于一个聚类簇;(8)对边缘轨迹进行处理:遍历除核心轨迹之外的其他轨迹,根据轨迹相似度判断将边缘轨迹加入相应的聚类簇中;(9)此时不属于任何聚类簇的轨迹则为离群轨迹(噪声轨迹);(10)遍历每个聚类簇中每条轨迹中每段的最小子轨迹,计算其与簇中其他轨迹的最小子轨迹之间的距离,小于热点子轨迹距离阈值mcs_thre的最小子轨迹加入相应的栈文件中;(11)遍历所有最小子轨迹的栈文件,对栈中轨迹数量大于热点子轨迹数量阈值mcs_num的轨迹标识为mcs_before;(12)遍历mcs_before,得到其对应的栈文件中轨迹起终点的均值,作为这段mcs_before所生成的最终的最小热点轨迹段,并将其他参与运算的子轨迹段从原始轨迹数据的聚类簇中删除,避免之后二次计算,同时记录最小热点轨迹段是由多少条路径求出的均值最为当前轨迹段的热点等级。步骤(2)-1首先计算两段轨迹tri.k{pt1,pt2}、trj.l{pt3,pt4}的端点之间欧氏距离的均值,具体计算过程参考公式(3)、(4)、(5);dis(tri.k,trj.l)=1/2(dis1+dis2)(5)以设置阈值的方式来得到两段最小轨迹段之间的相似度sim_seg,具体计算过程参考公式(6);如果dis(tri.k,trj.l)>δ则认为两段子轨迹相似度为零,如果dis(tri.k,trj.l)≤δ则认为两段子轨迹具有相似度,也称这两段子轨迹是可以匹配的;由公式也可知0≤dis(tri.k,trj.l)≤1,相似度的值越接近1,表明这两段子轨迹相似程度越高。实施例:下面以四川省成都市出租车轨迹数据为例,说明本发明基于最长公共子轨迹密度聚类的热点路径挖掘方法。本实施例中采用的轨迹数据采样点包括车辆编号、订单编号、经度,纬度和时间戳共五个属性其中为保护驾驶员和订单信息的隐私性,已做hash编码散列处理,其数据描述如表1所示,表1轨迹数据集描述步骤1,对原始数据进行预处理,完成冗余数据和异常数据剔除,轨迹压缩和地图匹配等工作;步骤2,计算轨迹之间相似度,首先计算最短轨迹段之间的相似度,其计算思想如图2所示,根据两条轨迹段的四个端点之间的距离来定义他们之间的相似度,其中轨迹tri长度为n,轨迹trj长度为m,首先计算tri.k{pt1,pt2}构成的轨迹段tri.k和trj.l{pt3,pt4}构成的轨迹段trj.l之间的相似度,具体计算过程参考公式(1)、(2)、(3)、(4),dis(tri.k,trj.l)=1/2(dis1+dis2)(3)步骤3,基于最小子轨迹段之间的相似度来计算最长公共子轨迹的相似度lcss_sim(tri,trj),具体计算过程参考公式(5),步骤4,基于最长公共子轨迹的相似度lcss_sim(tri,trj),其构成点数量lcss_n以及两段轨迹的长度tri_n,trj_m,来计算轨迹之间的相似度tr(ij)_sim,具体计算过程参考公式(6),生成一个包含所有轨迹之间相似度的长宽相同的二维矩阵,本实例生成轨迹相似度矩阵为长宽均为1040的矩阵,其形式如表2所示,表2轨迹相似度表轨迹编号tr1tr2…trntr1----tr2----…----trn----步骤5,依据轨迹相似性矩阵,遍历核心轨迹数据集中所有轨迹,记录每个与核心轨迹的相似度小于给定阈值eps的轨迹,即直接空间可达轨迹的序号;步骤6,再次遍历核心轨迹数据集中所有轨迹,依次将不属于任何聚类簇的核心轨迹作为中心轨迹进行聚类簇的生成,将中心轨迹的空间连通轨迹都加入到相应的聚类簇,最终使得每一条核心轨迹都只属于一个聚类簇;步骤7,对边缘轨迹进行处理:遍历除核心轨迹之外的其他轨迹,根据轨迹相似度判断将边缘轨迹加入相应的聚类簇中,此时不属于任何聚类簇的轨迹则为离群轨迹(噪声轨迹);步骤8,通过基于启发式参数q_measure来判断当前eps和minpts对聚类结果所造成的影响,q_measure使用平方误差(sumofsquarederror(sse))和噪声惩罚(noisepenalty(np))来度量轨迹聚类效果,具体计算过程参考公式(7),采用控制变量方式判断eps和minpts两个参数对轨迹聚类结果的影响,分别可以得到图3信息熵随eps影响变化图和图4信息熵随minpts影像变化图,综合两个图像可以得到,最适于成都市出租车轨迹数据聚类的eps和minpts值分别为:0.77和19;步骤9,遍历每个聚类簇中每条轨迹中每段的最小子轨迹,计算其与聚类簇中其他轨迹的最小子轨迹之间的距离,小于热点子轨迹距离阈值mcs_thre的最小子轨迹加入相应的栈文件中;步骤10,遍历包含所有最小子轨迹的栈文件,对栈中轨迹数量大于热点子轨迹数量阈值mcs_num的轨迹标识为mcs_before;步骤11,遍历mcs_before,得到其对应的栈文件中轨迹起终点的均值,作为这段mcs_before所生成的最终的最小热点轨迹段,并将其他参与运算的子轨迹段从原始轨迹数据的聚类簇中删除,避免之后二次计算,同时记录最小热点轨迹段是由多少条路径求出的均值最为当前轨迹段的热点等级。最后得到的热点路径挖掘成果可视化展示如图5所示。上述实施例只为说明本发明的技术构思及特点,目的在于熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应该涵盖在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1