一种生成式对抗网络估值的不完整数据聚类方法与流程
本发明涉及一种生成式对抗网络估值的不完整数据聚类方法,属于不完整数据聚类技术领域。
背景技术:
在信息时代数据量激增,每时每刻都能产生大量数据,如何对数据进行高效处理和利用成为一个研究热点,聚类分析作为一种无监督算法在数据分析领域有着愈发重要的意义。模糊c均值方法(fcm)区别于传统的硬划分,隶属度取值不只局限在0和1两个值,充分表现了事物之间的模糊性与相似性,成为一种有效且广泛应用的聚类分析方法。但是fcm方法存在一定的局限性,fcm算法不能直接对不完整数据进行聚类分析。然而现实世界中不完整数据的产生问题无法避免,数据采集失败、数据存储泄露、噪声干扰等经常会有属性数据丢失,造成不完整数据集,为数据聚类分析带来困难。如何充分挖掘不完整数据中的有效信息至关重要,要对不完整数据集进行高效的聚类分析是一个必须解决的难题,因此对不完整数据的模糊聚类研究具有重要的实际意义。
技术实现要素:
为了解决上述存在的问题,本发明提供一种生成式对抗网络估值的不完整数据聚类方法。
本发明的目的是通过以下技术方案实现的:一种生成式对抗网络估值的不完整数据聚类方法,其步骤为:
一种生成式对抗网络估值的不完整数据聚类方法,其特征在于,其步骤为:
1)确定最近邻样本:根据最近邻规则为不完整数据的选取相应的训练样本集;不完整数据样本集中的不完整数据样本xa与数据样本xb的相似性度量公式如公式(1):
其中,xia是样本xa的第i个属性,xib是样本xb的第i个属性;
ii表达式为式(2):
其中,n表示数据集中样本总数;
通过属性相关的相似度计算公式(1)和(2),得到不完整数据样本的最近邻样本,构成缺失数据的训练样本集,计算不完整数据样本和其最近邻样本之间相似度;
2)生成对抗网络填补缺失数据,区间化填补数据:将vae作为生成对抗网络gan的生成器,与gan的判别器融合建立不完整数据填补模型网络的拓扑结构,将最近邻样本集的属性中值作为不完整数据构造特征标签,训练样本集训练网络,完成不完整数据对缺失属性的估值填补,得到完整的数值型数据集;
变分自动编码器中的隐变量z由变分分布q(z|x)进行选择,通过假设简单的高斯分布,及贝叶斯算法计算其中的kl散度:
最大似然估计的混合损失函数的优化目标函数:
其中,x为输入样本,z为隐变量,z~p(z),x|z~pθ(xz),z满足高斯分布p(z),从z中采样通过神经网络计算pθ(x|z)进而生成数据;
不完整数据区间化填补:利用上述模型填补缺失数据属性,得到完整的数值型数据集,进一步将得到的数值型数据区间化,由属性误差均值绝对值确定区间大小;假设缺失属性估值为x,对完整数据的估值误差取平均值为e,则缺失属性区间为[x-e,x+e];
3)生成对抗网络估值的区间型数据模糊c均值聚类:首先对步骤2)得到的缺失属性区间利用近邻样本属性极值进行约束,然后对区间型数据进行模糊聚类分析;
3.1)最近邻样本属性极值对区间的约束:在最近邻样本集中,选取缺失属性的数据,以缺失属性的最小值与最大值构造属性区间[min,max],将由属性误差均值绝对值构造的属性区间[x-e,x+e]与属性最小值最大值构造的属性区间[min,max]取交,得到新的区间[min,max]作为属性估值区间;如果,两个区间不存在交集,说明不完整数据样本点很可能是离群点,此时直接取属性误差均值绝对值构造的属性区间即可完成区间估计;
3.2)设属性维度为s区间数据集
利用拉格朗日乘子法迭代计算得到聚类中心更新公式为:
若存在区间型数据样本
否则:
4)利用生成对抗网络估值的区间型模糊c均值聚类方法对步骤2)中得到的区间型数据集进行聚类,得到聚类结果。
所述的步骤4)中,具体步骤如下:
4.1)构造对不完整数据样本的最近邻样本集:依据最近邻规则选择最近邻样本,确定最近邻样本数q,构建不完整数据的q个最近邻样本集;
4.2)输入样本归一化:将所有的数据均转化为区间[0,1]之间的数,从而消除各维度间数量级的差别;
4.3)数据填补模型初始化:对模型中的各网络参数进行初始化,权值,偏置值,最大迭代次数,训练误差;
4.4)训练模型:使用训练样本集对模型进行训练;
4.5)填补缺失属性:生成对抗网络模型对不完整数据中的各个缺失数据属性进行估值预测,同时得到网络对于数据集中的完整属性的估值误差;
4.6)区间化数据集:根据区间型转化规则,将数值型数据集中的数据全部转化为区间型,进而构造区间型矩阵:
4.7)初始化区间型fcm算法参数:初始化隶属度矩阵,并对聚类类别数
4.8)按照公式(9)和公式(10)更新聚类中心矩阵:依据u(l-1)对聚类中心矩阵v(l)进行更新;
4.9)按照公式(11)和公式(12)更新隶属度矩阵:语句v(l)对隶属度矩阵u(l)进行更新;
4.10)算法条件判断:当迭代次数达到最大,或max|u(l+1)-u(l)|≤ε时,算法迭代停止;否则l=l+1,返回4.8)。
本发明创造的有益效果为:本发明采用上述方案,通过相似度计算公式来计算待填补样本和其他样本之间的距离,利用构成的近邻样本作为不完整数据填补模型的训练样本,训练完成后用生成对抗网络模型填补缺失数据。同时,为了解决不完整数据的不确定性问题,区间化填补缺失数据,形成完整的区间数据集。为进一步减小区间化填补数据的误差,对区间大小进行优化。本发明在区间型数据集上对数据进行模糊聚类分析。
附图说明
图1是vae网络结构模型图。
图2是gan网络模型结构图。
图3是ivaegan模型结构图。
具体实施方式
一种自适应区间的不完整数据加权聚类方法,其步骤为:
1)确定最近邻样本:根据最近邻规则为不完整数据的选取相应的训练样本集。不完整数据样本集中的不完整数据样本xa与数据样本xb,存在缺失属性或者不存在缺失属性均可,相似性度量公式如公式(1):
其中,xia和xib分别是样本xa和样本xb的第i个属性;
ii表达式为式(2):
n表示数据集中样本总数。
通过属性相关的相似度计算公式(1)和(2),可以得到不完整数据样本的最近邻样本,构成缺失数据的训练样本集。具体的不完整数据样本和其最近邻样本之间相似度的计算过程为:假设有一个包含有5个数据属性值的不完整数据样本表示为xa=(5,?,?,3,?),其中“?”表示丢失的数据属性值,它的最近邻数据样本之一表示为xb=(5,8,?,2,6),其相似度的计算过程如式(3)所示:
2)生成对抗网络填补缺失数据,区间化填补数据:将vae的特征提取、数据生成与gan的数据判别融合构造不完整数据填补模型。将最近邻样本集的属性中值作为不完整数据构造特征标签。改进后的网络模型ivaegan的拓扑结构如图3所示。完成不完整数据对缺失属性的估值填补,得到完整的数值型数据集。
变分自动编码器中的隐变量z由变分分布q(z|x)进行选择。通过假设简单的高斯分布,及贝叶斯算法计算其中的kl散度:
最大似然估计的混合损失函数的优化目标函数:
其中,x为输入样本,z为隐变量,z~p(z),x|z~pθ(x|z),z满足高斯分布p(z),从z中采样通过神经网络计算pθ(x|z)进而生成数据。
不完整数据区间化填补:利用上述模型填补缺失数据属性,得到完整的数值型数据集,为了表达缺失数据的不确定性,进一步将得到的数值型数据区间化。由属性误差均值绝对值确定区间大小。假设缺失属性估值为x,对完整数据的估值误差取平均值为e,则缺失属性区间为[x-e,x+e]。
3)生成对抗网络区间型数据模糊c均值聚类:为进一步减小区间填补误差,首先步骤2)得到的缺失属性区间利用近邻样本属性极值进行约束,在对区间型数据进行模糊聚类分析。
3.1)最近邻样本属性极值对区间的约束。在最近邻样本集中,选取缺失属性的数据,以缺失属性的最小值与最大值构造属性区间[min,max]。将由属性误差均值绝对值构造的属性区间[x-e,x+e]与属性最小值最大值构造的属性区间[min,max]取交,得到新的区间[min,max]作为属性估值区间。如果,两个区间不存在交集,说明不完整数据样本点很可能是离群点,此时直接取属性误差均值绝对值构造的属性区间即可完成区间估计。
3.2)设属性维度为s区间数据集
利用拉格朗日乘子法迭代计算得到聚类中心更新公式为:
若存在区间型数据样本
否则:
4)利用生成对抗网络估值的区间型模糊c均值聚类方法对步骤2)中得到的区间型数据集进行聚类,得到聚类结果,具体步骤如下:
4.1)构造对不完整数据样本的最近邻样本集。依据最近邻规则选择最近邻样本,构建不完整数据的最近邻样本集。
4.2)输入样本归一化。将所有的数据均转化为区间[0,1]之间的数,从而消除各维度间数量级的差别。
4.3)模型初始化。对ivaegan模型中的各网络参数进行初始化,权值,偏置值,最大迭代次数,训练误差。
4.4)训练模型。使用训练样本集对ivaegan模型进行训练。
4.5)填补缺失属性。本发明提出的模型对不完整数据中的各个缺失数据属性进行估值预测,同时得到网络对于数据集中的完整属性的估值误差。
4.6)区间型化数据集。根据发明提出的区间型转化规则,将数值型数据集中的数据全部转化为区间型,进而构造区间型矩阵。
4.7)初始化区间型fcm算法参数。初始化隶属度矩阵,并对聚类类别数
4.8)更新聚类中心矩阵。依据u(l-1)对聚类中心矩阵v(l)进行更新;
4.9)更新隶属度矩阵。语句v(l)对隶属度矩阵u(l)进行更新;
4.10)算法条件判断。当迭代次数达到最大,或max|u(l+1)-u(l)|≤ε时,算法迭代停止;否则l=l+1,返回4.8)。
实施例1:
一、本发明方案的理论依据:
1、模糊c均值算法(fcm)
fcm算法主要由三个部分组成:模糊隶属度函数、目标函数、分区矩阵。首先,建立模糊聚类的目标函数,利用迭代优化思想,进行目标函数最小化。其次,在目标函数的迭代优化过程中,对满足条件的样本进行分类,优化目标函数值不断减小达到聚类的效果。最后,模糊隶属度矩阵u(c×n)根据不同数据样本的属性及类别进行不断更新以达到分类的目的。其中,数据样本的数量为n,聚类中心的数量为c。对于某一样本,它可以从属于多个类别,但不能属于目标类别集合以外的类别。隶属度矩阵中的元素uij满足以下条件:
uij∈[0,1](14)
fcm算法的极小化目标函数为:
其中,m为模糊加权系数,通常m∈(1,+∞),本发明设置m=2。数据xj到聚类中心vi之间的欧氏距离为
fcm利用拉格朗日乘子法,聚类中心与隶属度更新公式如(17)和(18):
2、区间型模糊c均值
区间模糊c均值的数据均是区间表示。设属性维度为s区间数据集
其中
公式(19)达到极小值的条件为:
若存在区间型数据样本
否则
3、变分自动编码器vae
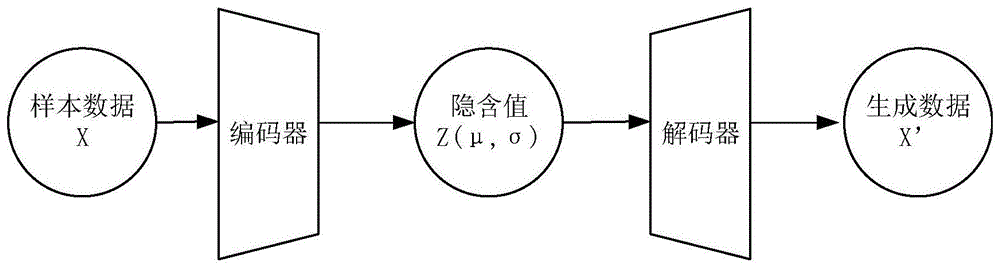
变分自动编码器作为一种生成模型,其网络模型结构由编码器、解码器两部分组成。其中编码器需要学习后验分布的近似值,编码器为了学习这种分布采用变分法而没有采用计算复杂的马尔科夫蒙特卡洛算法,即编码器通过变分推断来获得后验分布的近似值。自动编码器的模型结构图如图1所示,x为输入样本,
(1)编码器
编码器作为数据的输入端,输入层对数据样本直接输入传导入隐含层。输入层的节点数与数据的属性维数相等。隐含层对输入数据通过激活函数开始计算得出数据的均值和中心构成隐变量z,在训练的数据集中每个数据样本点都存在着一个相应的隐变量,保留着样本的均值和方差信息。
(2)解码器
解码器通过对隐含层中计算得到的隐变量进行矩阵加权计算得到输出结果,然后将得到的结果输出。
4、生成对抗网络(gan)
生成对抗网络由两个模型组成:生成器和鉴别器。这两个模型通常由神经网络来实现,但它们可以用任何形式的可微系统来实现,该系统将数据从一个空间映射到另一个空间。生成器试图捕获真实示例的分布,以便生成新的数据示例。鉴别器通常是一个二进制分类器,尽可能准确地将生成的示例与真实示例区分开来。gan优化问题是一个极大极小优化问题。优化终止于相对于生成器的最小值和相对于鉴别器的最大值的鞍点,即优化的目标是达到纳什均衡。然后,可以认为生成器捕获了真实示例的真实分布。
生成器与判别器进行对抗博弈,生成器要生成接近真实的数据,判别器对生成的数据的真伪进行判断,相互提高并获取平衡的最大值。
生成器的损失函数为:
lg=e[log(d(g(z)))](26)
判别器的损失函数为:
ld=e[log(d(x))]+e[log(1-d(g(z)))](27)
其中,x为输入样本,z为隐变量。
二、本发明技术方案的实现过程:
1.确定最近邻样本:根据最近邻原则选取近邻样本,提出相似度计算公式计算缺失样本和其他样本之间的距离,根据样本数据之间得到的相似度距离来确定不完整样本的
2.生成对抗模型填补缺失数据:将vae作为gan的生成器,与gan的判别器融合构造不完整数据填补模型。训练网络,完成缺失数据的填补。区间化填补缺失数据,更好表达缺失数据的不确定性,把数据改成区间的形式进行填补;
3.提出生成对抗模型填补缺失数据的区间型模糊c均值聚类方法(ivaegan-ifcm),对步骤2的区间型数据进行区间优化,减少区间填补误差。再对区间型数据进行模糊聚类分析。
4.生成对抗网络区间型数据模糊c均值聚类方法与四种不完整数据聚类方法进行对比。方法评价标准选取平均聚类错分数、迭代次数进行分析,实验对比使用三个数据集:iris、breast、bupa在缺失比例5%,10%,15%和20%的十次均值。实验结果如下所示。其中最优结果为黑体标记,次优结果用下划线标记。
表1iris平均聚类错分数
表2breast平均聚类错分数
表3bupa平均聚类错分数
表4不完整数据集iris的聚类错分数标准差
表5不完整数据集bupa的聚类错分数标准差
表6不完整数据集breast的聚类错分数标准差
由表1至表3可以得出,各个数据集在不同缺失率的情况下,从全局上看,本发明所提出的ivaegan-ifcm算法与其他四种对比算法相比,得到的结果是相对来说最好的。从表4到6中的聚类错分数标准差来看,提出的ivaegan-ifcm算法在不同数据集的不同缺失率条件下,都能保持较低的聚类错分数标准差,体现了算法稳定性。
对于平均误分数这一评价指标而言。当各个数据集在不同的非零缺失率的情况下,从整体上看,本发明所提出的算法相比于其他四种对比算法,能够得到相对来说更好的实验结果。
本发明提出的不完整数据聚类方法可应用在模式识别领域中,解决缺失数据情况下设备的故障诊断问题,在设备诊断过程中,可以对正常、亚健康、故障工况下的设备各参数运行数据进行聚类分析,得到聚类中心。在设备智能诊断过程中,设备运行的新数据将会与训练得到的聚类中心进行相似度检验,通过相似度的高低来决定设备处于何种工况类别。
- 还没有人留言评论。精彩留言会获得点赞!