面向多维指标分析的评估方法及装置与流程
本发明涉及数据分析技术领域。更具体地说,本发明涉及一种面向多维指标分析的评估方法及装置。
背景技术:
随着信息技术的高速发展,各类评估需求不断衍生。目前,对于产业发展的评估主要还是人为评估,耗时费力,无法满足快速评估的要求,而且人为评估考虑的因素有限,较不全面。因此,亟需设计一种能够一定程度克服上述缺陷的技术方案。
技术实现要素:
本发明的一个目的是提供一种面向多维指标分析的评估方法及装置,通过对多个角度的指标数据信息进行获取和计算,实现了全方面、多维度、快速评估。
为了实现根据本发明的这些目的和其它优点,根据本发明的一个方面,提供了获取预定地区的产业发展相关指标的数据,所述产业发展相关指标至少包括产业指标、科研机构指标及政策法规指标;
对所述产业发展相关指标的数据执行无量纲化处理;
根据无量纲化处理得到的数据,计算所述产业发展相关指标的熵值,根据所述熵值计算所述产业发展相关指标的权值;
根据无量纲化处理得到的数据和权值,评估预定地区的产业发展。
进一步地,所述的面向多维指标分析的评估方法,所述产业指标至少包括产品数量、产品标签数量、产品标签种类、员工规模、人员标签数量、人员标签种类、产业领域数量、产品标签数量、产品标签种类、公司市值、公司注册资金、公司国际排名、公司国内排名、事件条数;
所述研究机构指标至少包括研究领域数量、研究领域标签数量、研究领域标签种类、研究成果数量、研究成果标签数量、研究成果标签种类、发布报告数量、发布报告标签数量、发布报告标签种类、研究人员数量、研究人员标签数量、研究人员标签种类、学术活动数量、学术活动标签数量、学术活动标签种类、新闻报道数量;
所述政策法规指标至少包括法律法规数量、法律法规关联事件数、战略立法数量、战略立法关联事件数、政策法规标准数量、政策法规关联事件数。
进一步地,所述的面向多维指标分析的评估方法,所述产业发展相关指标包括正指标和负指标,对于所述正指标和所述负指标,无量纲化处理的方法包括:
其中,xj={xij|i=1,2,…,n}表示预定地区的第j项所述产业发展相关指标的数据集合,max(xj)和min(xj)分别表示预定地区在第j项所述产业发展相关指标的数据的最大值和最小值。
进一步地,所述的面向多维指标分析的评估方法,所述权值的计算方法包括:
其中,k>0,
进一步地,所述的面向多维指标分析的评估方法,通过计算预定地区的综合评分评估预定地区的产业发展,所述综合评分为无量纲化处理得到的数据的加权和。
进一步地,所述的面向多维指标分析的评估方法,获取预定地区在预定时间段内的所述产业发展相关指标的数据。
进一步地,所述的面向多维指标分析的评估方法,还包括:
对于任一所述产业发展相关指标,获取预定历史时间段内各历史时间点的数据,以上一历史时间点的数据为输入,以下一历史时间点的数据为输出,训练获得神经网络预测模型;
在对所述产业发展相关指标的数据执行无量纲化处理之前,将上一时间点的所述产业发展相关指标的数据输入对应的所述神经网络预测模型,获得所述产业发展相关指标的预测数据;
将所述产业发展相关指标的预测数据与实际数据进行比较,获得比较误差,若比较误差大于预定阈值,则重新获取对应所述产业发展相关指标的数据或重新选择所述产业发展相关指标。
根据本发明的另一个方面,提供了面向多维指标分析的评估装置,包括:
获取模块,用于获取预定地区的产业发展相关指标的数据,所述产业发展相关指标至少包括产业指标、科研机构指标及政策法规指标;
处理模块,用于对所述产业发展相关指标的数据执行无量纲化处理;
计算模块,用于根据无量纲化处理得到的数据,计算所述产业发展相关指标的熵值,根据所述熵值计算所述产业发展相关指标的权值;
评估模块,用于根据无量纲化处理得到的数据和权值,评估预定地区的产业发展。
进一步地,所述的面向多维指标分析的评估装置,所述产业发展相关指标包括正指标和负指标,对于所述正指标和所述负指标,无量纲化处理的方法包括:
其中,xj={xij|i=1,2,…,n}表示预定地区的第j项所述产业发展相关指标的数据集合,max(xj)和min(xj)分别表示预定地区在第j项所述产业发展相关指标的数据的最大值和最小值;
所述权值的计算方法包括:
其中,k>0,
根据本发明的又一个方面,提供了面向多维指标分析的评估装置,包括:
处理器;
存储器,其存储有可执行指令;
其中,所述处理器被配置为执行所述可执行指令,以执行所述的面向多维指标分析的评估方法。
本发明至少包括以下有益效果:
本发明从多角度构建评价指标体系,获取指标的数据并进行计算,能够迅速对预定地区的产业发展进行评估,相比于现有技术,考虑的因素更全面、维度更多,评估速度更快。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
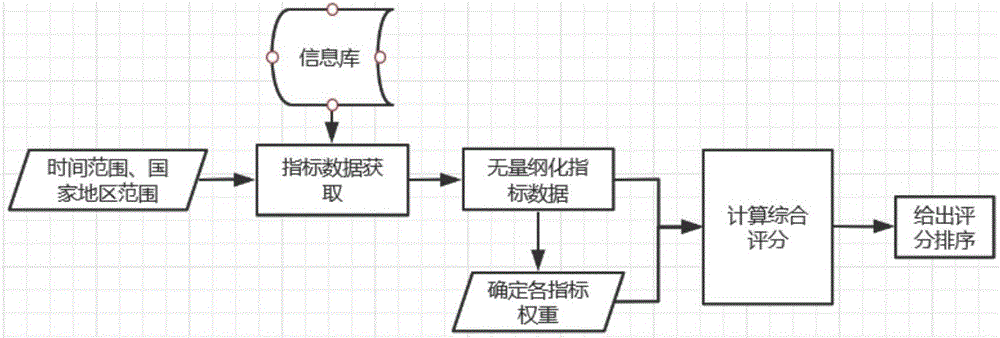
图1为本发明的流程图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加。
如图1所示,本申请的实施例提供了面向多维指标分析的评估方法,包括:
步骤s101,获取预定地区的产业发展相关指标的数据,所述产业发展相关指标至少包括产业指标、科研机构指标及政策法规指标;步骤s102,对所述产业发展相关指标的数据执行无量纲化处理;步骤s103,根据无量纲化处理得到的数据,计算所述产业发展相关指标的熵值,根据所述熵值计算所述产业发展相关指标的权值;步骤s104,根据无量纲化处理得到的数据和权值,评估预定地区的产业发展。
在本实施例中,预定地区可以是一个或多个国家,也可以是一个或多个城市。产业发展相关指标的具体类型不作限定,可以是任意与产业发展有正关联或反关联的指标,优选地,包括产业指标、科研机构指标及政策法规指标。可选地,预先建立包括产业信息库、研究机构信息库、政策法规信息库、事件信息库,包含时间、地域、产业、公司、机构、技术、研究方向、政策法规、事件等多方面。无量纲化处理处理的具体方法不作限定,能够去除量纲对数据的影响即可。利用熵值法计算得到权值。根据权值和无量纲化处理得到的数据即可对产业发展进行评估,可选地,可以将所有数据整体用于评估,也可以分别用于评估。可以看出,本技术方案从多角度构建评价指标体系,获取指标数据并计算,能够迅速对预定地区的产业发展进行评估,相比于现有技术,考虑的因素更全面、维度更多,评估速度更快。
在另一些实施例中,提供了可选地的产业指标、研究机构指标和政策法规指标,所述产业指标至少包括产品数量、产品标签数量、产品标签种类、员工规模、人员标签数量、人员标签种类、产业领域数量、产品标签数量、产品标签种类、公司市值、公司注册资金、公司国际排名、公司国内排名、事件条数;所述研究机构指标至少包括研究领域数量、研究领域标签数量、研究领域标签种类、研究成果数量、研究成果标签数量、研究成果标签种类、发布报告数量、发布报告标签数量、发布报告标签种类、研究人员数量、研究人员标签数量、研究人员标签种类、学术活动数量、学术活动标签数量、学术活动标签种类、新闻报道数量;所述政策法规指标至少包括法律法规数量、法律法规关联事件数、战略立法数量、战略立法关联事件数、政策法规标准数量、政策法规关联事件数。
在另一些实施例中,提供了可选地无量纲化处理方法,所述产业发展相关指标包括正指标和负指标,对于所述正指标和所述负指标,无量纲化处理的方法包括:
其中,xj={xij|i=1,2,…,n}表示预定地区的第j项所述产业发展相关指标的数据集合,max(xj)和min(xj)分别表示预定地区在第j项所述产业发展相关指标的数据的最大值和最小值。指标评估体系中共有m个指标,xij(i=1,2,…,n;j=1,2,…,m)表示第i国家地区的第j项原始指标值。正指标是指指标值越大越好的指标,逆指标是指指标值越小越好的指标。
在另一些实施例中,提供了可选地权值计算方法,包括:
其中,k>0,
在另一些实施例中,通过计算预定地区的综合评分评估预定地区的产业发展,所述综合评分为无量纲化处理得到的数据的加权和,即采用线性加权和法,计算公式如下:
在另一些实施例中,获取预定地区在预定时间段内的所述产业发展相关指标的数据,即可选定特定的时间、空间进行产业发展评估,方便进行比较。
在另一些实施例中,还包括:对于任一所述产业发展相关指标,获取预定历史时间段内各历史时间点的数据,以上一历史时间点的数据为输入,以下一历史时间点的数据为输出,训练获得神经网络预测模型;在对所述产业发展相关指标的数据执行无量纲化处理之前,将上一时间点的所述产业发展相关指标的数据输入对应的所述神经网络预测模型,获得所述产业发展相关指标的预测数据;将所述产业发展相关指标的预测数据与实际数据进行比较,获得比较误差,若比较误差大于预定阈值,则重新获取对应所述产业发展相关指标的数据或重新选择所述产业发展相关指标。
本实施例提供了对指标数据进行鉴别的方法,避免使用可能存在异常的数据。产业发展一般具有一定的规律,产业发展相关指标也是具有规律,上一历史时间点的数据与下一历史时间点的数据存在关联性。通过采集历史数据,训练获得神经网络预测模型。当需要使用一实际数据时,需找到对应指标的神经网络预测模型,并输入,得到预测数据,并与实际数据比较,计算比较误差,当比较误差大于预定阈值,则需要重新获取该指标的数据。当重新获取的数据仍无法满足要求,则需要更换同类指标。可选地,比较误差为30%。可选地,上一历史时间点与下一历史时间点的间隔为6个月或12个月。
基于与面向多维指标分析的评估方法相同的发明构思,还提供了面向多维指标分析的评估装置,包括:
获取模块,用于获取预定地区的产业发展相关指标的数据,所述产业发展相关指标至少包括产业指标、科研机构指标及政策法规指标;处理模块,用于对所述产业发展相关指标的数据执行无量纲化处理;计算模块,用于根据无量纲化处理得到的数据,计算所述产业发展相关指标的熵值,根据所述熵值计算所述产业发展相关指标的权值;评估模块,用于根据无量纲化处理得到的数据和权值,评估预定地区的产业发展。
基于与面向多维指标分析的评估方法相同的发明构思,还提供了面向多维指标分析的评估装置,包括:处理器;存储器,其存储有可执行指令;其中,所述处理器被配置为执行所述可执行指令,以执行所述的面向多维指标分析的评估方法。本实施例可参考方法部分的描述。本技术方案的装置不限于pc、终端、服务器。比如此装置可以设置在服务器中,间隔设定时间获取数据并执行,实时获得评估结果。
这里说明的设备数量和处理规模是用来简化本发明的说明的。对本发明面向多维指标分析的评估方法及装置的应用、修改和变化对本领域的技术人员来说是显而易见的。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!