一种分布式模型搜索方法及系统与流程
本申请涉及神经网络深度学习技术领域,特别是涉及一种分布式模型搜索方法及系统。
背景技术:
随着人工智能技术的发展,深度学习模型已经广泛应用到很多领域中,如图像识别、语音识别以及机器翻译等。在深度学习模型中,如何快速而有效地构建网络模型,构造面向神经网络结构的搜索空间,通过模型搜索,寻找适合于给定任务的模型结构,是个重要的技术问题。
目前利用enas(efficientneuralarchitecturesearch,有效神经网络架构搜索)算法进行模型搜索的方法,该算法采用参数共享原理改进神经结构搜索,进行单卡模型搜索。具体地,如图1所示,是enas算法构建的一个超网络,即整个搜索空间。enas的超网络是nas搜索空间中所有可能子模型的叠加,其中节点表征局部计算,边缘表征信息流。每一个节点的局部计算有其自己的参数,这些参数只有当特定计算被激活时才使用。因此在搜索空间中,enas的设计允许参数在所有子模型之间共享。
然而,由于enas算法是在单卡上进行模型搜索,效率较低。经验证enas采用单卡nvidiagtx1080tigpu(graphicsprocessingunit,图形处理器)在cifar10数据集上进行搜索,获得最佳模型需花费16小时。而在实际应用中随着输入图片尺寸增大、数量增多,其搜索效率会更低。
技术实现要素:
本申请提供了一种分布式模型搜索方法及系统,以解决现有技术中模型搜索方法搜索效率较低的问题。
为了解决上述技术问题,本申请实施例公开了如下技术方案:
执行控制器训练并行化,所述控制器为设定的rnn(
一种分布式模型搜索方法,所述方法包括:
参数初始化,所述参数包括数据库和用户参数;
执行超网络训练并行化;
执行控制器训练并行化,所述控制器为设定的rnn(recurrentneuralnetworks,循环神经网络)网络;
判断当前训练是否达到设定的epoch数目;
如果没有达到设定的epoch数目,循环执行超网络训练并行化和控制器训练并行化,直到达到设定的epoch数目;
如果达到设定的epoch数目,执行模型评估并行化;
根据模型评估并行化的结果,获取模型评估并行化输出的最高精度;
将所述最高精度对应的子网络结构作为最佳子模型结构。
可选地,所述参数初始化包括:
读入数据库;
配置用户参数,所述用户参数包括:数据集划分比例、超网络训练参数、控制器训练参数以及用于训练的设定的epoch数目。
可选地,所述执行超网络训练并行化,具体为:采用多个gpu梯度求和的方式进行超网络训练。
可选地,所述采用多个gpu梯度求和的方式进行超网络训练,包括:
每个gpu划分
将给定的控制器和超网络在n个gpu上进行分布式封装;
在不同的gpu上控制器采样生成不同的子模型结构;
将所述子模型结构和训练数据输入至超网络中进行并行计算,获取n个loss值,任一loss值与一个gpu相匹配;
任一gpu根据其所匹配的loss值计算超网络梯度;
利用所述超网络梯度,在各gpu之间根据all-reduce算法计算得出每个gpu的梯度和;
判断任一gpu的输入数据是否为空;
如果否,重新在不同的gpu上控制器采样生成不同的子模型结构,并将所述子模型结构和训练数据输入至超网络中进行并行计算,直到所述任一gpu的输入数据为空。
可选地,所述执行控制器训练并行化,具体为:采用多个gpu梯度求平均的方式进行控制器训练。
可选地,所述采用多个gpu梯度求平均的方式进行控制器训练,包括:
每个gpu划分
将给定的控制器和超网络在n个gpu上进行分布式封装;
在不同的gpu上控制器采样生成不同的子模型结构;
将所述子模型结构和验证数据输入至超网络中进行并行计算,获取n个验证集精度值;
根据所述验证集精度值和logit,计算得出n个loss值,任一loss值与一个gpu相匹配;
任一gpu根据其所匹配的loss值计算控制器梯度;
利用所述控制器梯度,在各gpu之间根据all-reduce算法,计算得出每个gpu的梯度平均值;
判断任一gpu的输入数据是否为空;
如果否,重新在不同的gpu上控制器采样生成不同的子模型结构,并将所述子模型结构和验证数据输入至超网络中进行并行计算,直到所述任一gpu的输入数据为空。
可选地,计算loss值的方法具体为:利用公式loss=-1*logit*(val_acc-baseline)计算得出loss值,所述logit为控制器网络的输出值,其中,
可选地,所述执行模型评估并行化,包括:
每个gpu划分
将给定的控制器和超网络在n个gpu上进行分布式封装;
在不同的gpu上控制器采样生成不同的子模型结构;
将所述子模型结构和测试数据输入至超网络中进行并行计算,获取n个测试集精度值;
各gpu分别将相应的子模型结构和测试集精度值存储为列表;
判断任一gpu的输入数据是否为空;
如果gpu的输入数据为空,获取所述列表的最大acc值以及所述最大acc值所匹配的arc值;
将所述列表的最大acc值和arc值汇总至指定gpu上;
在所述指定gpu上比较n个最大acc值,确定最大测试集精度和最佳子模型结构;
如果gpu的输入数据不为空,重新在不同的gpu上控制器采样生成不同的子模型结构,并将所述子模型结构和测试数据输入至超网络中进行并行计算,直到所述任一gpu的输入数据为空。
一种分布式模型搜索系统,所述系统包括:
初始化模块,用于进行参数初始化,所述参数包括数据库和用户参数;
超网络训练模块,用于执行超网络训练并行化;
控制器训练模块,用于执行控制器训练并行化,所述控制器为设定的rnn网络;
判断模块,用于判断当前训练是否达到设定的epoch数目,如果当前训练达到设定的epoch数目,启动模型评估模块,如果当前训练没有达到设定的epoch数目,循环启动超网络训练模块和控制器训练模块,直到达到设定的epoch数目;
所述模型评估模块,用于当前训练达到设定的epoch数目时,执行模型评估并行化;
最高精度获取模块,用于根据模型评估并行化的结果,获取模型评估并行化输出的最高精度;
最佳子模型结构确定模块,用于将所述最高精度对应的子网络结构作为最佳子模型结构。
可选地,所述超网络训练模块包括:
训练集划分单元,用于将每个gpu划分
第一分布式封装单元,用于将给定的控制器和超网络在n个gpu上进行分布式封装;
第一采样单元,用于在不同的gpu上控制器采样生成不同的子模型结构;
超网络并行计算单元,用于将所述子模型结构和训练数据输入至超网络中进行并行计算,获取n个loss值,任一loss值与一个gpu相匹配;
超网络梯度计算单元,用于在任一gpu根据其所匹配的loss值计算超网络梯度;
求和单元,用于利用所述超网络梯度,在各gpu之间根据all-reduce算法,计算得出每个gpu的梯度和;
第一判断单元,用于判断任一gpu的输入数据是否为空,如果是,流程结束,如果否,重新在不同的gpu上控制器采样生成不同的子模型结构,并将所述子模型结构和训练数据输入至超网络中进行并行计算,直到所述任一gpu的输入数据为空。
本申请的实施例提供的技术方案可以包括以下有益效果:
本申请提供一种分布式模型搜索方法,该方法首先进行参数初始化,然后依次执行超网络训练并行化、控制器训练并行化,并判断当前训练是否达到设定的epoch数目,如果达到设定的epoch数目,执行模型评估并行化,否则循环执行超网络训练并行化和控制器训练并行化,知道达到设定的epoch数目,然后根据模型评估并行化的结果,获取模型评估并行化输出的最高精度;最后将最高精度对应的子网络结构作为最佳子模型结构。本实施例通过对超网络训练、控制器训练和模型评估进行并行化,能够充分利用多gpu的计算力实现模型搜索过程的并行化,从而有效节省任务的模型构建时间,提高模型搜索效率。本实施例依次执行超网络训练和控制器训练,控制子模型进行并行训练,分别在训练器和验证集,且达到设定的epoch数目时才在测试集上启动模型评估并行化,最终获取到最高精度对应的子网络结构,能够在不同的网络中实现分布式并行搜索,有利于提高网络灵活性,从而进一步提高分布式模型搜索效率。
本申请还提供一种分布式模型搜索系统。该系统主要包括:初始化模块、超网络训练模块、控制器训练模块、判断模块、模型评估模块、最高精度获取模块和最佳子模型结构确定模块。该系统通过超网络训练模块、控制器训练模块和模型评估模块,能够充分利用多gpu的计算力实现模型搜索过程的并行化,从而有效节省任务的模型构建时间,提高模型搜索效率。本实施例通过超网络训练模块、控制器训练模块和模型评估模块分别使子模型在训练集、验证集和测试集上进行并行训练,最终获取最高精度对应的子网络结构,能够在不同的网络中实现分布式并行搜索,有利于提高网络灵活性,从而进一步提高分布式模型搜索效率。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例所提供的一种分布式模型搜索方法的流程示意图;
图2为本实施例中超网络训练并行化的工作原理示意图;
图3为本实施例中all-reduce算法的原理示意图;
图4为本实施例中控制器训练并行化的工作原理示意图;
图5为本实施例中模型评估并行化的工作原理示意图;
图6为本申请实施例所提供的一种分布式模型搜索系统的结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请中的技术方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
为了更好地理解本申请,下面结合附图来详细解释本申请的实施方式。
实施例一
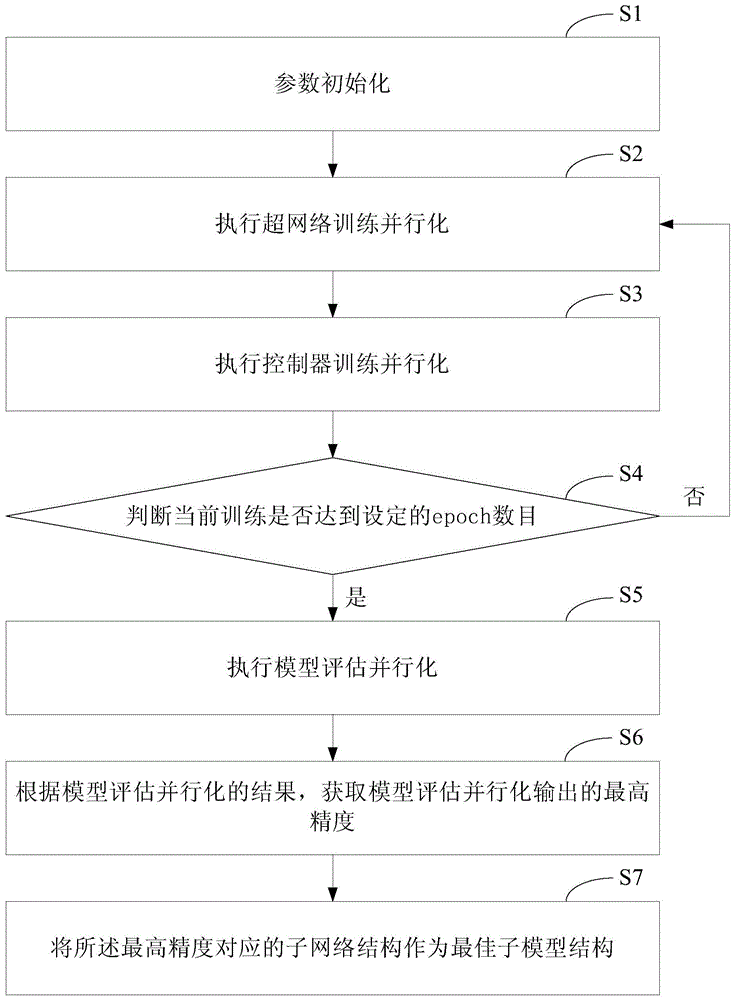
参见图1,图1为本申请实施例所提供的一种分布式模型搜索方法的流程示意图。由图1可知,本实施例中分布式模型搜索方法,主要包括如下过程:
s1:参数初始化。
本实施例中的参数包括数据库和用户参数。
其中,用户参数包括:数据集划分比例、超网络训练参数、控制器训练参数以及用于训练的设定的epoch数目。1epoch即:使用训练集中的全部样本训练一次。
根据以上参数,本实施例中的参数初始化包括:
s11:读入数据库。
s12:配置用户参数。
也就是配置数据集划分比例、超网络训练参数、控制器训练参数以及用于训练的设定的epoch数目。通过参数初始化,能够确保后续子模型训练的顺利进行,从而提高分布式模型搜索效率。
s2:执行超网络训练并行化。
超网络训练并行化,即控制器并行采样子网络结构,子模型在训练集上并行训练,超网络参数同步更新。本实施例中采用多个gpu梯度求和的方式进行超网络训练。这种超网络训练方式,能够结合超网络的特点,通过子网络参数更新实现超网络参数更新时,能够避免梯度平均导致的梯度值降低,有利于提高精度上升的速率,进而提高分布式模型搜索效率。
具体地,本实施例中超网络训练并行化的工作原理可以参见图2所示,由图2可知本实施例中步骤s2主要包括如下过程:
s21:每个gpu划分
其中,n为并行gpu的数量。
s22:将给定的控制器和超网络在n个gpu上进行分布式封装。
也就是将控制器和超网络复制到每个gpu上,每一个模型的副本处理输入的一部分。
s23:在不同的gpu上控制器采样生成不同的子模型结构,定义为:arc-1、arc-2、…、arc-n。
s24:将子模型结构和训练数据输入至超网络中进行并行计算,获取n个loss值。
其中,训练数据定义为batch-1、batch-2、…、batch-n,loss值定义为loss-1、loss-2、…、loss-n,任一loss值与一个gpu相匹配,本实施例中loss的计算方法可以采用公式:loss=-1*logit*(val_acc-baseline),
s25:任一gpu根据其所匹配的loss值计算超网络梯度。
超网络梯度定义为:grad-1、grad-2、…、grad-n。
s26:利用超网络梯度,在各gpu之间根据all-reduce算法计算得出每个gpu的梯度和。
本实施例中all-reduce算法的原理示意图可以参见图3所示。通过all-reduce算法,能够实现每个gpu对gpu内的数据进行归约。在反向传播过程中,每个gpu都得到了梯度和,使得超网络参数能够保持各gpu之间同步。
计算得出每个gpu的梯度和之后,执行步骤s27:判断任一gpu的输入数据是否为空。
如果任一gpu的输入数据不为空,执行步骤s28:重新在不同的gpu上控制器采样生成不同的子模型结构,并将子模型结构和训练数据输入至超网络中进行并行计算,直到任一gpu的输入数据为空。
如果任一gpu的输入数据为空,流程结束。
通过步骤s21-s28,能够通过多进程在多个gpu间复制模型,每个gpu都由一个进程控制,每个进程都执行相同的任务,并且每个进程都与其他所有进程通信。进程之间或者说gpu之间只传递梯度,这种方式能够有效减少广播参数所花费的时间,避免网络通信成为瓶颈,有利于提高分布式模型搜索方法的效率。
继续参见图1可知,超网络训练并行化完毕后,执行步骤s3:执行控制器训练并行化,控制器为设定的rnn网络。
控制器训练并行化也就是,控制器并行采样子网络结构,子模型在验证集上并行输出精度,控制器参数同步更新。本实施例中采用多个gpu梯度求平均的方式进行控制器训练。由于控制器为预先设定的rnn网络,这种方式,能够充分结合控制器的特点进行并行化,从而有利于提高分布式模型搜索方法的效率。
本实施例中控制器训练并行化的工作原理可以参见图4所示。由图4可知,本实施例中控制器训练并行化的方法包括如下过程:
s31:每个gpu划分
其中,n为并行gpu的数量。
s32:将给定的控制器和超网络在n个gpu上进行分布式封装。
也就是将控制器和超网络复制到每个gpu上,每一个模型的副本处理输入的一部分。
s33:在不同的gpu上控制器采样生成不同的子模型结构。
子模型结构定义为:arc-1、arc-2、…、arc-n。
s34:将子模型结构和验证数据输入至超网络中进行并行计算,获取n个验证集精度值。其中,验证数据定义为valbatch-1、valbatch-2、…、valbatch-n,验证集精度值定义为valacc-1、valacc-2、…、valacc-n。
s35:根据验证集精度值和logit,计算得出n个loss值,任一loss值与一个gpu相匹配。
本实施例中计算loss值的方法,具体为:利用公式loss=-1*logit*(val_acc-baseline)计算得出loss值。loss值定义为loss-1、loss-2、…、loss-n,任一loss值与一个gpu相匹配,logit为控制器网络的输出值,其中,
s36:任一gpu根据其所匹配的loss值计算控制器梯度。其中,控制器梯度定义为:ctrlgrad-1、ctrlgrad-2、…、ctrlgrad-n。
s37:利用控制器梯度,在各gpu之间根据all-reduce算法,计算得出每个gpu的梯度平均值。
s38:判断任一gpu的输入数据是否为空。
如果任一gpu的输入数据不为空,执行步骤s39:重新在不同的gpu上控制器采样生成不同的子模型结构,并将子模型结构和验证数据输入至超网络中进行并行计算,直到任一gpu的输入数据为空。
如果任一gpu的输入数据为空,流程结束。
通过以上步骤s31-s38可知,本实施例能够实现控制器训练并行化。
继续参见图1可知,控制器训练并行化之后,执行步骤s4:判断当前训练是否达到设定的epoch数目。
如果达到设定的epoch数目,执行步骤s5:执行模型评估并行化。
如果没有达到设定的epoch数目,返回步骤s2,循环执行超网络训练并行化和控制器训练并行化,直到达到设定的epoch数目。然后执行步骤s5。
需要注意的是,每个epoch完成后,训练集和验证集都会再次打乱顺序。
模型评估并行化也就是,控制器并行采样子网络结构,子模型在测试集上并行输出精度。本实施例中模型评估并行化的工作原理可以参见图5所示。由图5可知,本实施例中模型评估并行化的方法包括如下过程:
s50:每个gpu划分
其中,n为并行gpu的数量。
s51:将给定的控制器和超网络在n个gpu上进行分布式封装。
s52:在不同的gpu上控制器采样生成不同的子模型结构,定义为:arc-1、arc-2、…、arc-n。
s53:将子模型结构和测试数据输入至超网络中进行并行计算,获取n个测试集精度值。
本实施例中测试数据定义为testbatch-1、testbatch-2、…、testbatch-n,测试集精度值定义为testacc-1、testacc-2、…、testacc-n。
s54:各gpu分别将相应的子模型结构和测试集精度值存储为列表。
列表定义为:arc_list-1、arc_list-2、…、arc_list-n,acc_list-1、acc_list-2、…、acc_list-n。本实施例通过将相应的子模型结构和测试集精度值存储为列表,能够实现在多gpu之间进行比较,从而选择最佳精度对应的模型,有利于提高分布式模型搜索的准确性。
s55:判断任一gpu的输入数据是否为空。
s56:如果gpu的输入数据为空,获取列表的最大acc值以及最大acc值所匹配的arc值。
列表的最大acc值定义为:max_acc-1、max_acc-2、…、max_acc-n,列表的arc值定义为:best_arc-1、best_arc-2、…、best_arc-n。acc值为测试集精度值,获取列表的最大acc值即获取列表的最大测试集精度值。arc值为子模型结构。
如果gpu的输入数据不为空,重新在不同的gpu上控制器采样生成不同的子模型结构,并将子模型结构和测试数据输入至超网络中进行并行计算,直到任一gpu的输入数据为空。然后执行步骤s56获取到列表的最大acc值以及最大acc值所匹配的arc值。
s57:将列表的最大acc值和arc值汇总至指定gpu上。
s58:在指定gpu上比较n个最大acc值,确定最大测试集精度和最佳子模型结构。
继续参见图1可知,本实施例中执行模型评估并行化之后,执行步骤s6:根据模型评估并行化的结果,获取模型评估并行化输出的最高精度。
s7:将最高精度对应的子网络结构作为最佳子模型结构。
本实施例中分布式模型搜索方法可以应用于气象预警、交通监测以及医疗评估等关于目标分类的领域。
以气象预警领域为例,具体以高速公路恶劣气象预警中的团雾能见度识别为例,团雾能见度共定义3个级别,分别采用0,1,2表示,当为0时表示无雾;当为1时,表示小范围的轻微雾,提醒司机小心驾驶;当为2时,表示浓雾,提醒交管封路或司机就近离开高速。基于团雾能见度的分布式模型并行搜索技术方案流程与图1一致,只是需要前期收集高速摄像头视频,截取图像并打上相应的能见度标签,即制作团雾数据库。输入团雾数据库,多gpu并行搜索高效输出适配团雾识别的最佳模型。将该模型训练完成后,即可部署到摄像头上进行实时预警。充分利用多gpu的计算力实现模型搜索过程的并行化,能够节约构建不同气象下模型时间,实现对团雾能见度预警,并提高预警效率,有利于提高恶劣天气条件下高速公路的运营管理效率和行车安全。
实施例二
在图1-图5所示实施例的基础之上参见图6,图6为本申请实施例所提供的一种分布式模型搜索系统的结构示意图。由图6可知,本实施例中分布式模型搜索系统主要包括:初始化模块、超网络训练模块、控制器训练模块、判断模块、模型评估模块、最高精度获取模块和最佳子模型结构确定模块。
其中,初始化模块,用于进行参数初始化,参数包括数据库和用户参数,用户参数包括:数据集划分比例、超网络训练参数、控制器训练参数以及用于训练的设定的epoch数目;超网络训练模块,用于执行超网络训练并行化;控制器训练模块,用于执行控制器训练并行化,控制器为设定的rnn网络;判断模块,用于判断当前训练是否达到设定的epoch数目,如果当前训练达到设定的epoch数目,启动模型评估模块,如果当前训练没有达到设定的epoch数目,循环启动超网络训练模块和控制器训练模块,直到达到设定的epoch数目;模型评估模块,用于当前训练达到设定的epoch数目时,执行模型评估并行化;最高精度获取模块,用于根据模型评估并行化的结果,获取模型评估并行化输出的最高精度;最佳子模型结构确定模块,用于将最高精度对应的子网络结构作为最佳子模型结构。
进一步地,超网络训练模块包括:训练集划分单元、第一分布式封装单元、第一采样单元、超网络并行计算单元、超网络梯度计算单元、求和单元和第一判断单元。
其中,训练集划分单元,用于将每个gpu划分
控制器训练模块包括:验证集划分单元、第二分布式封装单元、第二采样单元、控制器并行计算单元、loss值计算单元、控制器梯度计算单元、梯度平均值计算单元和第二判断单元。
其中,验证集划分单元,用于将每个gpu划分
进一步地,模型评估模块包括:测试集划分单元、第三分布式封装单元、测试集精度值计算单元、列表存储单元、第三判断单元、最大值获取单元、汇总单元和比较单元。其中,测试集划分单元,用于将每个gpu划分
该实施例中分布式模型搜索系统的工作原理和工作方法,在图1-图5所示的实施例中已经详细阐述,在此不再赘述。
以上所述仅是本申请的具体实施方式,使本领域技术人员能够理解或实现本申请。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!