基于深度学习的语音驱动3D虚拟人表情音画同步方法及系统与流程
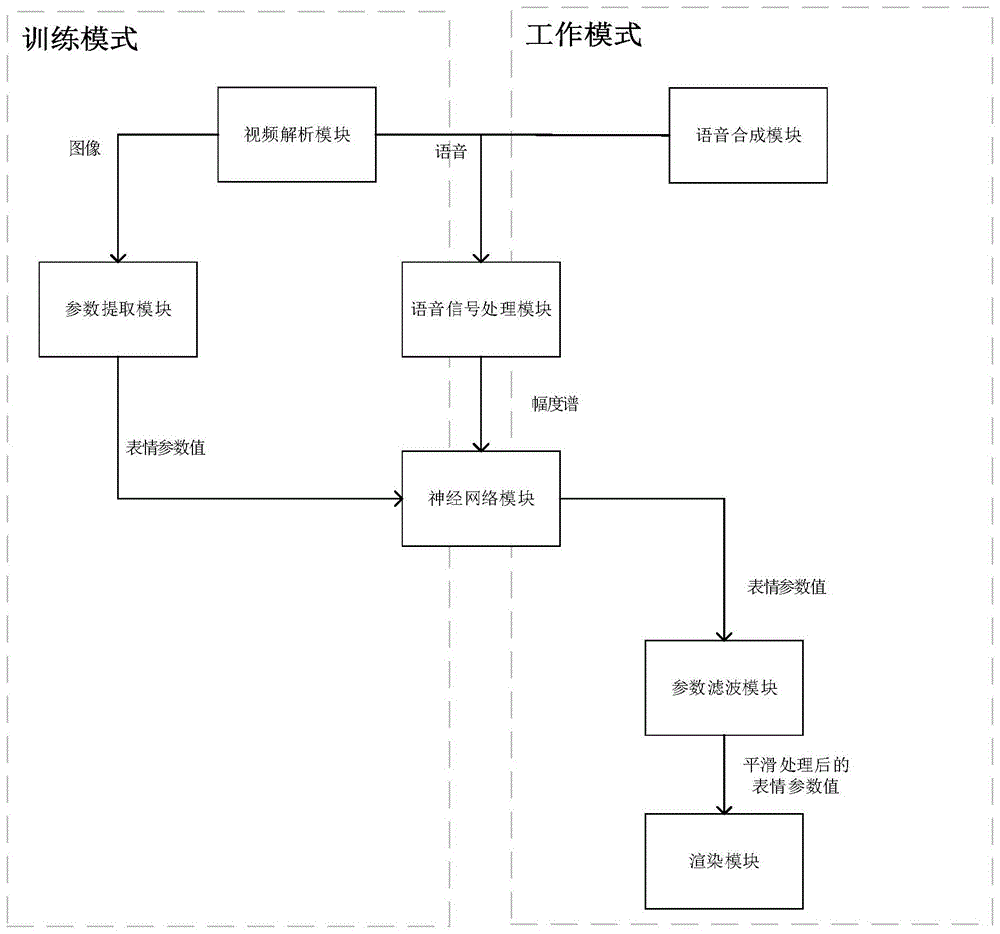
本发明涉及计算机图形学、计算机视觉、语音识别、语音合成等领域,具体是一种利用深度神经网络去拟合语音与3d模型blendshape值之间关系,实现语音驱动3d虚拟人表情音画同步的方法及系统。
背景技术:
:目前语音驱动生成虚拟人面部动画的方法有以下几种类型:(1)语音通过神经网络生成一个固定拓扑结构的3d模型的顶点坐标,这些顶点坐标在di4dpro系统上能够表现出来人脸动画。(2)语音通过对抗网络生成不同的2d图像的方式来驱动虚拟人,这些2d图像是一个3d模型的不同角度的反映。(3)语音通过音素拆分,每个音素对应到一个动画片段,通过动画片段的拼接的方式来实现。上述方法(1)和(2)能够做到比较丰富和自然的人脸表情,但是这些方法不适合用目前流行的实时渲染引擎来实时的渲染表情,不具有实时性交互能力。上述方法(3)也能够利用实时渲染引擎来渲染,同时计算速度也很快,但是自然度比不上使用神经网络参数驱动的方法,也不具有学习的能力。同时由于每个语种的音素是完全不同的,因此该方法是跟语言相关的,也就是虚拟人说一种语言,就得人工的去制作该语言每个音素所对应的动画。技术实现要素:为了克服现有的虚拟人不同时具备较高的表情音画同步自然度、实时交互能力和提升表情音画同步效果学习能力的问题,本发明提供了一种虚拟人音画同步的自监督学习方法,通过学习大量的人脸视频数据,来提升虚拟人口唇效果,使得其更加自然,更像人。本发明采用的技术方案如下:一种基于深度学习的语音驱动3d虚拟人表情音画同步方法,其特征在于,包括以下步骤:提取语音信号中的对数幅度谱,作为语音信号特征;将语音信号特征输入训练完成的参数预测模型,该参数预测模型输出表情参数值;其中的参数预测模型是利用视频数据中语音信号与图像信号的天然的标签对关系训练得到的神经网络模型;对参数预测模型输出的表情参数值进行滤波;利用滤波后的表情参数值进行3d人物模型的图像渲染,实现3d虚拟人表情音画同步。进一步地,所述的提取语音信号中的对数幅度谱,其中的语音信号采用以下两种方式之一得到:使用在线语音合成接口,将文字转换成语音;利用开源语音合成框架合成语音,合成的语音数据来自于录制的视频数据。进一步地,所述的提取语音信号中的对数幅度谱,包括:首先将视频中的语音信号进行分帧,然后将分帧的信号的对数幅度谱提取出来。进一步地,所述参数预测模型的训练步骤包括:对视频数据进行预处理,将视频数据分割成图像和声音;从视频数据的图像中提取出表情参数值即au值;对视频数据的声音进行分帧,并提取分帧的信号的对数幅度谱;利用对数幅度谱和au值进行训练,得到参数预测模型。进一步地,所述的对参数预测模型输出的表情参数值进行滤波,是利用卡尔曼滤波器进行滤波,使得口唇动作过渡平滑。进一步地,所述的利用滤波后的表情参数值进行3d人物模型的图像渲染,实现3d虚拟人表情音画同步,包括:将表情参数值即au值转换成bs值,按帧设置3d人物模型的bs值,实现面部动画的渲染,并使得每一帧的图像渲染时间与每一帧的语音信号的时间保持一致,从而实现3d虚拟人表情音画同步。一种基于深度学习的语音驱动3d虚拟人表情音画同步系统,其包括:语音合成模块,用于合成语音信号;语音信号处理模块,用于提取语音信号中的对数幅度谱,作为语音信号特征;参数预测模块,用于将语音信号特征输入训练完成的参数预测模型,该参数预测模型输出表情参数值;其中的参数预测模型是利用视频数据中语音信号与图像信号的天然的标签对关系训练得到的神经网络模型;参数滤波模块,用于对参数预测模型输出的表情参数值进行滤波;渲染模块,用于利用滤波后的表情参数值进行3d人物模型的图像渲染,实现3d虚拟人表情音画同步。进一步地,所述系统还包括视频解析模块、参数提取模块,所述视频解析模块用于对视频数据进行预处理,将视频数据分割成图像和声音,所述参数提取模块用于从视频数据的图像中提取出表情参数值即au值;所述语音信号处理模块还用于在训练模式中对视频数据的声音进行分帧,并提取分帧的信号的对数幅度谱;所述参数预测模块还用于在训练模式中利用对数幅度谱和au值进行训练,得到参数预测模型。本发明的有益效果是:1.能够低成本的获取大量的视频数据来训练神经网络模型,使得虚拟人表情有了学习的能力。2.利用语音信号与图像信号的标签对关系,形成神经网络的自监督学习途径,不需要人工对训练数据贴标签。3.通过对语音信号的特征进行建模,能够做到语言无关性,使得虚拟人口唇驱动能够适应所有的语言,比如虚拟人能够同时说英语和汉语。4.因为本发明采用了基于深度学习的blendshape值预测及基于滤波器的参数平滑方法,所以口唇停顿比传统的动画拼接方法效果更加自然。5.更轻易的增加影响表情音画同步的因素,比如神经网络除了语音作为输入,还可以接受其他方式的输入,具有比较好的可扩展性。附图说明图1是本发明系统组成模块关系框图,其中分成了训练模式和工作模式两个框图,表示各个模块可以分成两部份,分别在神经网络训练学习及工作的时候涉及到,其中语音信号处理模块和参数预测模块是两个模式都会使用到的。参数预测模块存在一个神经网络参数更新机制,训练模式下将从学习样本中更新神经网络参数,将训练好的神经网络参数同步更新到工作模式下的参数预测模块中的神经网络中。图2是视频解析模块流程图。图3是参数转换模块流程图。图4是语音信号处理模块流程图。图5是参数预测模块流程图。图6是参数滤波模块流程图。图7是渲染模块流程图。图8是神经网络结构图,属于参数预测模块。具体实施方式为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步详细说明。本发明的基于深度学习的语音驱动3d虚拟人表情音画同步系统,包括视频解析模块、参数提取模块、语音合成模块、语音信号处理模块、参数预测模块、参数滤波模块和渲染模块。所有模块分为两部份,分别在训练模式以及工作模式下进行。训练模式中用到的模块包括:视频解析模块、参数提取模块、语音信号处理模块、参数预测模块。工作模式中用到的模块包括:语音合成模块、语音信号处理模块、参数预测模块、参数滤波模块和渲染模块。视频解析模块:该模块对视频数据进行预处理,将视频数据分割成图像和声音,为后续模块提供数据基础。参数提取模块:该模块基于开源工具openface,将视频中每一帧的人脸图像的面部动作编码系统(facialactioncodesystem,facs)的au(actionunit,运动单元)的强度值提取出来,该值又称作表情参数值。语音合成模块:该模块是在工作模式中将3d虚拟人想要表达的文字,可以是输入的文字,也可以是虚拟人在多轮对话过程中回答的文字,转换成语音信号,并输入语音信号处理模块。语音信号处理模块:该模块将视频中的语音信号进行分帧,将分帧的信号的对数幅度谱提取出来。参数预测模块:该模块基于深度学习中的卷积神经网络,在训练模式中,利用语音信号处理模块提取的语音信号对数幅度谱和参数提取模块得到的au值进行训练,得到一个参数预测模型;在工作模式中,输入是语音信号处理模块提取的语音信号对数幅度谱,即一帧的语音信号特征;输出是一帧的au的参数值,即表情参数值。参数滤波模块。该模块利用卡尔曼滤波器对参数预测模块输出的参数进行滤波,减少抖动,使得口唇动作过渡更加平滑。渲染模块。该模块基于ue4(unrealengine4)开发,将au值转换成混合形状(blendshape,bs)值,通过ue4的api,即可按帧设置3d人物模型的bs值,实现面部动画的渲染。通过固定渲染帧率为30fps,与语音信号的帧率保持一致,同时播放语音和动画,即可达到音画同步的效果。训练模式。该模式是指参数预测模块的神经网络需要借助其他模块获取训练数据,对神经网络进行训练的过程。工作模式。该模式是利用训练模式得到的新的神经网络进行实时的表情参数驱动的过程。下面提供一个具体应用实例。本实例中的各模块采用以下方式实现:1.视频解析模块该模块读取的视频数据是单个人脸的视频。通过ffmpeg工具来将视频数据分割成图像和语音,其中图像按帧提取出来,并且把图像在视频中的序号给记录下来,为后续数据处理做好准备。2.参数提取模块该模块将视频解析模块中的图像数据作为输入,通过openface中的faceanalyser_interop模块来处理,从而得到每一帧图像对应的au值,其中au值来自于facs,即facs中的actionunit,au字段名和字段值如下表所示,其中字段值是浮点类型,后缀r表示回归(regression):表1表情参数和参数值范围字段名值范围字段名值范围au01_r[0,1]au14_r[0,1]au02_r[0,1]au15_r[0,1]au04_r[0,1]au17_r[0,1]au05_r[0,1]au20_r[0,1]au06_r[0,1]au23_r[0,1]au07_r[0,1]au25_r[0,1]au09_r[0,1]au26_r[0,1]au10_r[0,1]au45_r[0,1]au12_r[0,1]3.语音信号处理模块该模块将将视频解析模块中的语音数据进行分帧处理,通过计算视频的帧数,按照帧数将语音等分,使得单帧语音信号的时间长度与视频中单帧图像的时间长度对齐。由于语音信号具有短时平稳性,因此对每一段的语音信号做短时傅立叶变换(shorttimefouriertransform,stft)。stft后的语音信号具有幅度谱和相位谱,由于幅度谱包含有语音信号更多的信息,因此特征选取了幅度谱,处理之后得到的特征就是多帧语音信号的幅度谱的一个集合。4.语音合成模块该模块可以采用两种方式实现:(1)使用百度的在线语音合成接口,将文字转换成语音。优点是免费,响应速度快。(2)利用开源语音合成框架tacotron合成语音,合成的语音训练数据来自于录制的视频数据,通过视频解析模块计算得到。优点是能够合成某个特定人的声音。5.参数预测模块该模块通过神经网络来实现,神经网络结构为卷积神经网络,输入是单帧的语音信号特征,输出是单帧的au值。该模块的工作主要分为两部分:(1)在训练模式中,卷积神经网络利用参数提取模块和语音信号处理模块分别得到的语音信号特征和au参数值进行训练,得到一个参数预测模型。(2)在工作模式中,将新的多帧语音信号特征输入到参数预测模型,得到多帧au参数值组。其中神经网络框架使用的是tensorflow1.15.1。神经网络的结构见图8所示,其采用的是卷积神经网络,输入是分帧后的语音的幅度谱,特征维度是129*23维。经过多层卷积和池化,再进入全连接层,最后得到一个15维的输出。图8中,conv表示卷积层,maxpool表示最大池化层,stride表示步长,flatten表示将多维的矩阵每一行的取出平展成一个一维向量,dense表示全连接。6.参数滤波模块由于神经网络的输出参数是离散的一组值,并不是平滑的,因此需要对输出的参数进行平滑处理。该模块将模块4获得的多帧au参数值进行滤波,采用卡尔曼滤波器,消除了噪声的影响,避免了虚拟人的口唇动作出现抖动的现象。同时还对比了经典的中位值滤波算法,算术平均滤波法和加权递推平均滤波法等滤波算法,在保证口唇和语音同步的情况下,采用卡尔曼滤波器使得口唇的动作更有连续性。7.渲染模块该模块基于虚幻4引擎,将模块5得到的多帧au参数值通过虚幻4引擎的接口按帧来渲染,从而得到一个连续的人脸表情动画。渲染的同时也播放语音,语音文件来自于模块4。由于在帧数上,au参数与语音信号保持了同步,因此通过调整虚幻4的渲染速率,通常为30fps,使得每一帧的图像渲染时间与每一帧的语音信号的时间保持一致,从而使得动画的口型与语音保持了同步。基于同一发明构思,本发明的另一个实施例提供一种电子装置(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。基于同一发明构思,本发明的另一个实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。以上公开的本发明的具体实施例和附图,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例和附图所公开的内容,本发明的保护范围以权利要求书界定的范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1