一种有效提升GPU上B+树检索效率的优化方法与流程
本发明属于异构计算技术领域,具体涉及有效提升gpu上b+树检索效率的优化方法,可用于大数据系统中的索引结构。
背景技术:
近几年,随着互联网技术的迅猛发展和信息技术的革命性进步,全球已进入大数据时代。全球每年产生的数据量呈现爆炸式的增长。2020年全球产生的数据量将达到约40zb(约为2003年的8000倍)。在此背景下,利用大数据进行分析和预测的应用变得越来越普及,也在人们生活中起着越来越重要的作用,比如许多应用都使用大数据处理技术来为用户提供个性化推荐服务,以方便用户进行购物和阅读等日常活动。然而,这些应用给人们带来了许多便捷的同时,也正不断地面临着数据量爆炸所带来的挑战,如netflix2018年统计显示平均每天netflix流处理系统需要上传12pb的数据至aws数据中心并处理。
面对数据量指数式的爆发,如何在应用中高效地检索和处理大数据已经成为工业界普遍关心的重要问题。当前主要的解决方案是使用索引结构来对数据进行高效的组织以提高检索和处理效率,如在sqlserver使用哈希数据结构来对数据库表做索引,在mysql数据库中使用b+树来对数据进行聚簇索引和辅助索引等。在索引结构中,b+索引树是其中最为重要且应用最为广泛的一种,它不仅能够提供对数时间复杂度的查询(search)、更新(update)等数据访问操作,而且还能够对底层数据进行有序组织。早在20世纪70年代,人们就基于b+树的特点将其应用于各类文件系统中以减少磁盘访问的开销。如今,随着更多应用场景的出现,b+树结构逐渐被使用于各种各样的数据系统中,例如key-value存储系统、数据库和在线分析处理系统(on-lineanalyticalprocessing,olap)等。因此,随着数据量的急剧增加,b+树索引数据结构性能的优劣将直接影响着这些系统的执行效率。
伴随着“大数据”时代的到来,经典b+树索引数据结构也面临诸多的困难与挑战。首先,数据量的增大导致数据存储相关的数据结构体积急剧膨胀,这对于数据结构的设计提出了更高的要求,比如当前在google的搜索引擎系统中需要高效得索引全球数千亿个网页,即大小超过1亿gb的网页数据量。其次,在大数据时代,用户访问数据的请求数增多,系统对于并发处理请求的需求也增大,例如在阿里巴巴2017年的“天猫双十一”活动中,其阿里云系统需要每秒处理数以百万次的交易操作。因此,在当下存储数据量和并发请求数量以指数级增长的时代,提升b+树数据结构的检索效率以应对“大数据”时代的挑战成为系统领域关键性的问题之一。
当前随着硬件技术的高速发展,越来越多的新型硬件逐渐出现并被广泛应用于各领域中。其中,早在20世纪90年代,图像处理单元(gpu)就由于其丰富的计算资源而被应用于图形图像渲染这一特定领域。随着近10年gpu体系结构和编程平台的快速发展,gpu也逐渐成为除cpu外最普遍应用的多核处理器之一。它不仅能够处理图形图像方面的问题,也更加能够为其他领域的高并行计算问题提供通用化的解决方案。由于gpu具有丰富的计算和存储器资源,而并发b+树并发查找具有高并行性和大量访存的需求,所以基于gpu加速传统b+树结构的处理速度成为一种潜在的可行方案。近几年,许多研究工作都关注该方向并相继将研究成果发表。然而即使gpu提供了相较于cpu而言更为丰富的硬件资源,现有的研究成果并没有取得理想的处理效果。
针对当前gpu加速b+树检索效率不理想的问题,原b+树难以在gpu上取得理想节加速效果主要原因在于传统b+树结构的设计和优化均是针对cpu体系结构而言的。因此,面对与cpu截然不同的gpu体系结构及其编程模型时,传统b+树结构难以适应这种变化,这种不适应产生了诸多问题:首先,对于传统b+树而言,一个查询请求需要从根节点(rootnode)逐层遍历至叶节点(leftnode),这样的遍历过程会导致大量低效的间接地址访问操作。这些间接地址访问操作通常需要频繁的读取全局存储器(globalmemory),而该存储器是gpu上传输延迟最高的存储器,因此这会对程序访存和执行的效率产生较大的影响;其次,并发执行的多个查询请求通常目标值是随机的,所以这将导致并发请求在b+树上的搜索路径会存在很大的差异性,多个相邻查询之间很难共享相同的树搜索路径。当它们被gpu上的一个线程束(warp)同时处理时,这种差异性会导致各种分歧(divergence):线程束分歧(warpdivergence)及内存访问分歧(memorydivergence)。其中线程束分歧影响gpu程序的计算执行效率,而内存访问分歧则会导致gpu难以合并内存传输,从而影响了gpu上的全局存储器的数据传输吞吐率。
针对当前b+树结构与gpu存在的多种不匹配问题的分析结果,本发明提出了一种新型的b+树数据结构和优化搜索方案,通过该方案能够有效地提升gpu上b+树检索的效率。
技术实现要素:
本发明的目的在于提供一种能够有效地提升gpu上b+树检索效率的优化方法,以解决当前b+树结构与gpu的存储器层次结构不匹配问题。
本发明提供的有效地提升gpu上b+树检索效率的优化方法,包括:首先,设计一种新的b+树数据结构;然后,在此基础上进一步设计提高b+树数据结构查询效率的优化搜索方法。
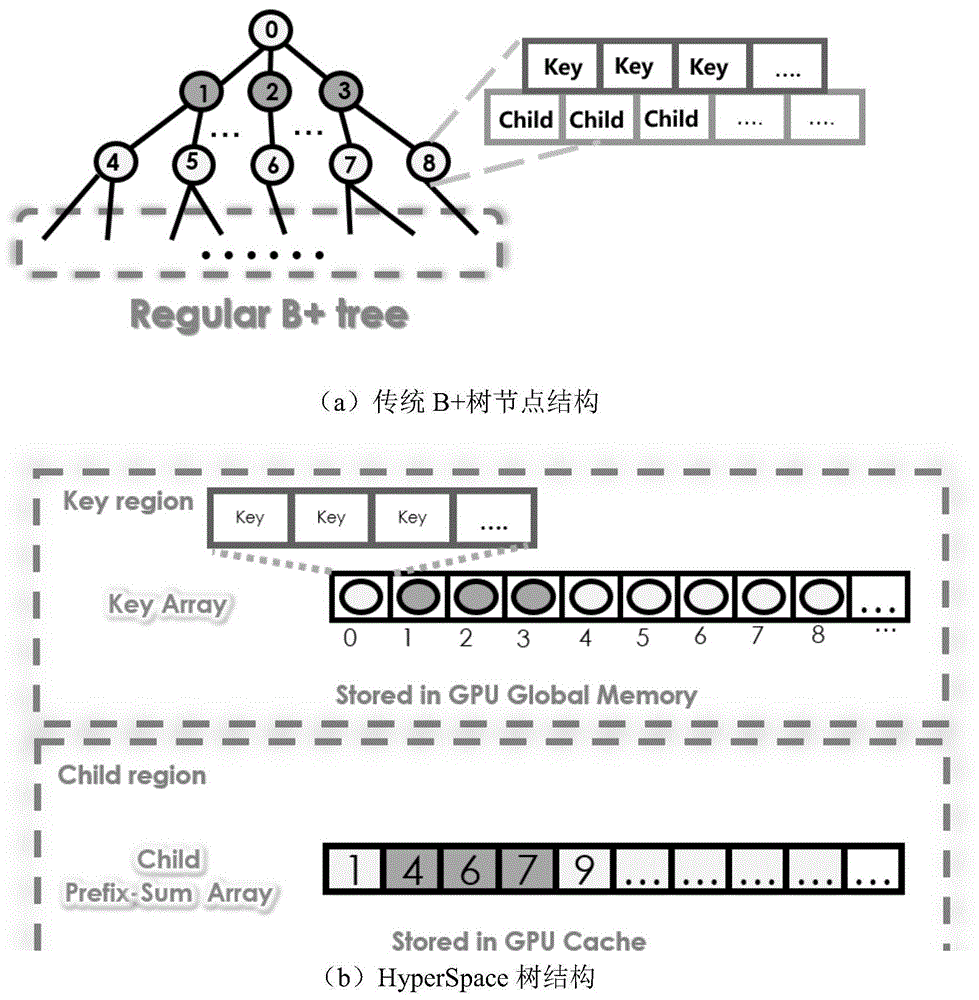
本发明首先设计了一种新b+树数据结构,称为hyperspace树结构。该结构将传统的b+树划分为两部分:键区域(keyregion)和孩子节点区域(childregion),并将b+树中体积为较大的孩子节点指针信息(childreferences)替换为体积更小的前缀和数组(prefixsumarray)。这样的结构能够为gpu上其他体积较小的低延迟存储器缓存树结构访问提供可能,并可以通过简单的计算获得孩子节点的位置。
具体的hyperspace树结构如图1(b)所示。键区域是以一维数组的方式组织,它存储传统b+树的所有树节点的键信息。这些树节点键信息以树广度优先遍历的顺序在键区域数组中从左至右依次连续存储。具体每个元素与传统b+树的节点的对应关系可由图1(a,b)可知,键区域的第一元素(索引序号为0)存储的是原树中的根节点(rootnode)的键值信息,第二个元素存储的是第二层第一个节点的所有键值信息,以此类推。数组中每个元素都具有固定的大小:
hyperspace树结构中,在孩子节点区域设计中引入了前缀和(prefixsums)的概念。前缀和是计算机领域中应用比较广泛的数据处理方式,例如在基排序(radixsort)、高阶递归(highorderrecurrences)中都有广泛的应用。前缀和数组中每项元素表示前面所有项(包含该项元素本身)的累加操作的结果。构造前缀和数组的操作需要输入一个二元关联运算符⊕和一维数组
在孩子节点区域中,前缀和数组中每个元素与键区域中的键值数组元素一一对应,即b+树孩子节点的信息也按照与键区域一致的树广度优先遍历顺序连续存储。数组中每个元素代表在层遍历过程中当前节点之前的所有树节点的孩子数量累加和(这与前缀和数组的概念相一致)。而且数组中每个元素也存在具体物理含义,即对应树节点的第一个孩子节点在键区域的索引位置。由图1(b)中可知,图1(a)传统b+树生成的前缀和数组为[1,4,6,7,9…]。它代表的含义是节点0(rootnode)的第一个孩子位于键区域数组的索引为1的位置,节点1(第二层第一个节点)的第一个孩子位于键区域序号为4的位置(即1+3),节点2(第二层第二个节点)的第一个孩子的位置位于6(即1+3+2),以此类推。依据该前缀和数组,不仅可以高效的通过计算获得本节点所有孩子节点的位置,而且每个节点包含的孩子数量可以通过后继元素值减去本节点对应的元素的值获得。
由于孩子节点信息区域使用了前缀和数组的方式进行组织,因此整颗b+树结构相比传统b+树而言体积减小了约50%。这也使得hyperspace树结构能够充分地利用gpu片上的有限的存储器进行高效缓存,从而将高延迟的全局存储器访问替代为低延迟的缓存访问。另外,该设计通过将树节点的孩子节点信息压缩为一个整型值使得访问同一个树节点的查询请求都将访问同一个内存位置,因此该设计使得b+树查询获得了更好的局部性。
基于上述设计的hyperspace树结构,本发明进一步设计了提高b+树的数据结构的查询效率的优化搜索方法,包括基于排序的搜索方法和基于缩小线程组大小的搜索方法;并且,在cpu端执行hyperspace树结构的批更新处理操作,在gpu端执行两种优化搜索方法和hyperspace树的并发查询操作;gpu端与cpu端之间树结构同步,在每次cpu端批更新操作完成之后通过pcie内存传输来实现;其中:
所述基于排序的搜索方法,是在查询请求开始执行之前,对所有的查询请求基于目标键进行排序。排序后的相邻查询能够较大概率地获得相似的查找路径,从而可以减少树遍历过程中不必要的内存访问分歧和查询分歧。其内存访问结果如图2所示,例如,给定4个查询如1、20、2、35,则先进行排序,并将相邻的查询组合成两组,一组是1、2,另一组是20、35,通过此种方式排序,可以提高访问内存地址的效率。
所述基于线程组大小的搜索方法,是将一个查询请求所需的线程数量缩减,可以有效的减少不必要的比较,并提高计算资源的利用率。如图3所示,例如,给定两个搜索2和6,原先线程组大小为8的情况下,则进行比较需要在8个线程间进行。该搜索方法可以将线程组大小缩小为4,则可有效减少线程间比较次数。基于缩小线程组大小的搜索优化则采取比传统gpu优化b+树方案而言更少的线程数量来服务一个查询请求,这样可以避免无效的比较次数,同时也提高了gpu上计算资源的利用率。当hyperspace使用较少的线程数量来为一个请求服务时,更多的查询请求可以同时被一个线程束处理,这样提高了查询的并行度。
技术效果:
本发明主要以现有的异构b+树加速研究成果hb+tree作为技术效果的比较对象并在基于nvidiatitanv实验平台对于hyperspace进行了详尽的测试。
在实际的技术效果比较中显示,hyperspace能够达到每秒35亿次的查询吞吐率,比已有的研究成果(hb+tree)提高了将近3.4倍。其中hyperspaceb+树结构比hb+tree查询性能提升了将近1.4倍,这主要归功于hyperspaceb+树带来了更好的查询执行局部性并且节约了50%的体积,该结构为更好的利用了gpu上多级片上高效缓存提供了可能。其次,在hyperspaceb+树结构加基于排序的预处理操作优化(hyperspacetree+psa)比hb+tree提升2倍的查询性能,这部分的性能提升主要归功于预先对查询排序使得同一个线程束中处理的查询请求能够访问相似的树遍历路径,这将有效地减少了影响gpu执行效率的线程束分歧问题和内存访问分歧问题。最后,在hyperspaceb+树结构上加上基于排序的预处理操作(psa)和基于线程组的搜索优化操作(ntg),查询效率大约比hb+tree提升了3.4倍,这一步的提升最主要归功于基于线程组的搜索优化操作减少了不必要的比较操作并且充分利用了现有的gpu的计算资源,最大化了gpu上b+树查询的并发度。
另外,基于在不同配置情况下的hyperspace查询性能结果可知,hyperspace设计具有良好的可拓展性,并且在不同配置下均能取得理想的查询效果。总而言之,hyperspace设计能有效的提升系统的检索效率。
附图说明
图1为传统b+树结构与hyperspace结构。其中,(a)为传统b+树节点结构,(b)为hyperspace树结构。
图2为部分有序的查询请求在内存访问中的访问模式。
图3为基于线程组大小的搜索优化方案。
图4为整体概览。
图5为hyperspace结构实现。
具体实施方式
异构系统中通常分阶段执行cpu和gpu部分,一般采用cpu执行控制逻辑较为复杂的部分,而gpu上的数据需采用阶段性的方式上传,然后执行批量的高并行操作。
在异构系统中实施本方法的具体过程如图4所示,在cpu端执行hyperspace树结构的批更新处理操作,在gpu端执行两种优化搜索方法和hyperspace树的并发查询操作。gpu端与cpu端之间树结构同步,是在每次cpu端批更新操作完成之后通过pcie内存传输来实现。
树结构
hyperspace树结构将传统b+树结构划分为两个部分:键区域和子节点区域,并且将传统的子节点引用信息区域替换为前缀和数组。所以如图5所示,在hyperspace系统中使用双层b+树节点的索引和键值部分,将它们共同存储为hyperspaceb+树结构键区域(keyregion)的数组项,而孩子区域结构仍然使用单个整型数值来存储子节点的信息。这样,可以使得在gpu上对于键区域的访问和对孩子区域的访问均有较好的访存性能。其中hyperspace键区域的双层b+树节点采用基于缓存行大小(64字节)的双层索引b+树节点实现。图5中键区域元素的展示即为该结构,该双层实现中基于扇出为64的b+树,因此树节点具有63个键值(key)和64个孩子节点引用(child)。为了保证缓存行对齐在键值区域最后补足了一个空键,即图中的
基于排序的搜索优化
在基于排序的搜索策略中,查询请求被gpu实际执行之前进行了完全排序以提高请求之间共享遍历路径的概率。然而完全排序会带来不可忽视的可能的时间开销,因此为了使得查询性能提升的收益大于排序带来的时间开销,引入了部分排序策略。在部分排序策略中,使用基于部分位的排序算法(与基于二叉树的位排序算法不同,因为不需要完全精确排序,此处的排序是为了搜索而用,可以是大致排序,是为了提高搜索效率),即仅仅需要对每个查询请求的最高n位排序,就可以取得与完全排序接近的查询效果,但排序时间开销却能够有效的减少。为了能够确定部分排序算法中的排序位数,需要一个模型来辅助该参数的选择。接下来将基于该模型和实际hyperspaceb+树的配置来计算合适的排序位数。
对于hyperspace系统而言,每个整型键值可以用64位表示(b=64),gpu的每个缓存行大小为128字节可以缓存16个键(k=16),因此对于一颗树大小为223的b+树而言(t=223),基于如下提出的模型可以计算得知,只需要排序19位(n=19)即可达到查询请求部分有序且排序开销也不会太大。
基于缩小线程组大小的搜索优化
在基于缩小线程组大小的搜索策略实现中,采用了一种缩减为一个查询请求服务的线程数量的优化方案。这样的实施方法有利于减少不必要的比较并且提高gpu计算资源的使用率。
在该方法实现中,将每个查询服务的线程组大小设置为1,且每个线程组同时处理最多n个查询(n为gpu上线程束处理的最大并行度)。具体地,例如在cpu端收集了1000个查询在不同线程组大小情况下的执行步数(s)。并且,当前最合适的线程组大小为1个线程。虽然当前b+树的扇出为64,但是由于索引层的存在,实际b+树的扇出可以认为8,该结果与我们实验验证的扇出为8的b+树在不同线程组大小下的查询执行效率一致。因此在hyperspace实现中,使用1个线程为每个查询服务,即每个线程束同时处理32个查询,该配置也同时达到了gpu上线程束处理的最大并行度。
- 还没有人留言评论。精彩留言会获得点赞!