基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法与流程
本发明涉及到信息检索技术领域,具体涉及互联网的抄袭检测的抄袭源检索技术。
背景技术:
互联网的高速发展,特别是越来越丰富的文献资源库以及搜索引擎、机器翻译的应用,使抄袭变得越来越容易。日益严重的抄袭催生和加速了抄袭检测技术(plagiarismdetection)的发展。近年来,抄袭检测吸引了学术界和工业领域的广泛关注(potthastetal.,2012;2013a;2014),成为了热点问题之一。
本发明关注抄袭检测的源检索问题。源检索的目标是获得可疑文档的抄袭源文档。该任务可以描述为:给定一篇可能包含抄袭文本的可疑文档dplg,源检索在文档集合dsrc中检索可疑文档dplg可能抄袭的文档dsrc,称dsrc为抄袭源文档,集合dsrc称为备选抄袭源文档集(potthastetal.,2013a;2014)。
应用信息检索的方法完成源检索任务是现有研究主要采取的思路。这些方法从可疑文档中获取用于表示该文档的关键词,利用这些关键词生成查询,然后将查询提交给一个搜索引擎执行检索,最后过滤检索结果,获得可疑文档的抄袭源。
现有源检索依赖于信息检索技术,对源检索本质关注不足。一方面,从可疑文档生成查询,再利用搜索引擎检索抄袭源的过程导致可疑文档的大部分信息丢失。另一方面,简单地将信息检索的方法应用在源检索中,没有考虑源检索与信息检索的区别:信息检索的目标是根据用户查询与文档的相关度排序检索结果,而源检索中,可疑文档通常并不是全文抄袭源文档,通常只有部分片段实施了抄袭,这使得源检索的目标是检索到与可疑文档抄袭部分匹配的源文档,而不是寻找与整篇可疑文档匹配的源文档。这个特性决定了抄袭源检索的局部匹配敏感性,导致现有检索模型无法高效完成源检索任务。
技术实现要素:
为了克服现有抄袭源检索的局部匹配敏感性对源检索的影响,本发明提出了一种根据源检索的局部匹配特性,采用面向源检索的局部匹配卷积神经网络模型(partialmatchingconvolutionneuralnetworkmodel,简称pm-cnn)实现获得抄袭检测中的源文档检索的方法。
本发明所述的基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法为:
一、根据待评价的原始可疑文档dplg和待检索源文档集合中d中的原始文档dsrc,构建文本片段的相似度矩阵m1;
二、学习局部匹配模式:将m1作为网络输入,应用卷积神经网学习不同粒度上可疑文档和源文档的匹配模式,构建矩阵
三、获取特征矩阵:对于表达不同粒度匹配关系的特征矩阵,执行k-maxpooling操作(参见图1中的k1-maxpooling和k2-maxpooling),获取语义匹配特征矩阵
四、学习特征的组合关系,识别抄袭源文档:将特征矩阵
预处理的方法为:
上述步骤一中在构建文本片段的相似度矩阵m1之前,对原始可疑文档dplg和原始文档dsrc进行预处理,例如,对于英语文本的预处理包括:对原始文档进行去除停用词、去除标点符号、将所有英文单词转换为小写并进行词干提取的操作,然后按每个片段n(如n=30)个词项(term)的大小划分为文本片段。
上述步骤一建文本片段的相似度矩阵m1方法为:
经过上述预处理之后,可疑文档dplg经过预处理之后获得文档dplg={s1,s2,...,si,...,sp},si为可疑文档dplg的文本片段,p为可疑文档dplg的文本片段的数目;待检索源文档集合中d中的原始文档dsrc经过前述预处理之后获得文档dsrc={r1,r2,...,rj,...,rq},rj为文档dsrc的文本片段,q为文档d中文本片段的数目。
上述相似度矩阵m1∈rm×n,m1中的mij表示可疑文档dplg中的文本片段si和文档dsrc中的文本片段rj的相似度。
上述步骤二学习局部匹配模式方法为:
相似度矩阵m1中的mij是可疑文档dplg的文本片段si和文档dsrc中的文本片段rj的相似度,可以通过但不仅限于余弦距离(cosinedistance)计算获得。
上述矩阵m2、m3等是应用卷积神经网络学习而得到的可疑文档和源文档的匹配模式:将m1作为网络输入连续使用卷积学习文本的局部匹配模式进而获得m2、m3等。具体为,首先对相似度矩阵m1使用2×2的卷积操作得到矩阵m2,捕获文档dplg和文档dsrc的相邻两个文本片段(si,si+1)、(rj,rj+1)的相似度;然后对矩阵m2进行2×2的卷积操作获得特征矩阵m3。类似地,可以继续进行卷积操作进而得到m4、m5,等等。
上述步骤三获取特征矩阵的方法为:
首先介绍获取特征矩阵的基本思想,然后,在此基础上描述获取方法。
获取特征矩阵的基本思想是:与少量部分匹配的片段相比,源文档和可疑文档中的大部分片段是不匹配的。因此,通过k-max池化操作获得重要的匹配特征矩阵是必要的。对于这个目标,对步骤二获得的局部匹配模式mi使用两个k-max池化操作来自动提取特征矩阵。
获取特征矩阵的方法为:
共有2个k-max池化操作。第一个k-max池化操作,扫描mi的每一行,并根据降序直接返回每一行的顶部前top-k1个值以形成向量ni。在ni上,我们继续执行第二个k-max池化操作,并返回每个ni的顶部前top-k2值以形成向量n′i。
进一步说明。对于相似度矩阵m1,按进行最大池化操作得到最显著特征n'1,该最显著特征n'1是可疑文档dplg与文档dsrc的每个文本片段之间相似的最显著特征;对于矩阵m2进行最大池化操作,获取了可疑文档与源文档每两个文本片段相似的最显著特征
重复上述操作,可以提取可疑文档与源文档更多文本片段存在抄袭的最显著特征;由此获得特征矩阵
上述步骤四获学习特征的组合关系、识别抄袭源文档的方法为:
上述步骤四所述的学习特征的组合关系、识别抄袭源文档的方法为:将特征矩阵
本发明所述的方法是利用卷积神经网络建模源检索的局部语义匹配,针对源检索特点进行文档间的“部分匹配”建模,而不是“完全相关”建模,即:本发明所述的方法是在充分的考虑了源检索与信息检索的本质区别,克服了抄袭源检索中的“相关检索”建模问题。实验结果表明,本发明所述的抄袭源文档的获得方法与现有方法相比较性能有了具有统计意义的提升。
附图说明
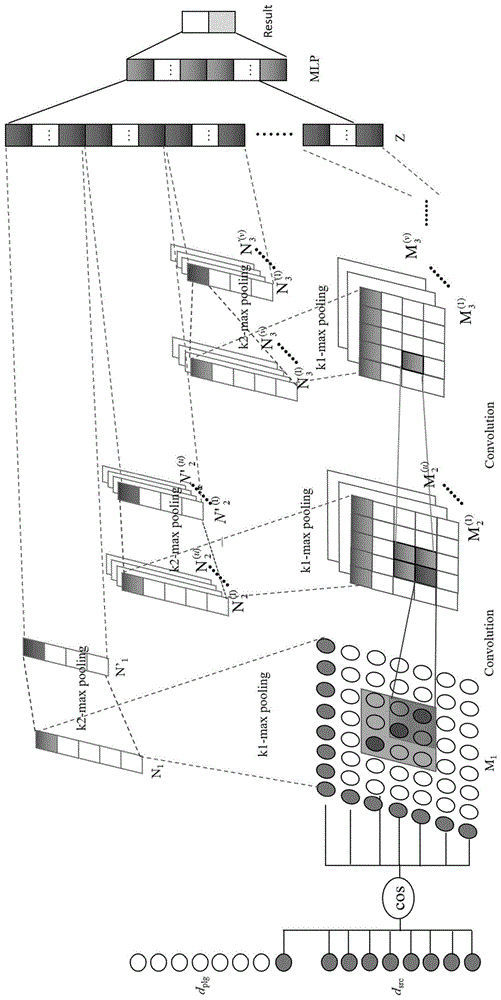
图1是本发明所述的面向源检索的局部语义匹配的卷积神经网络示意图。
图2相似度矩阵m1示意图。
实施方式
具体实施方式一.参见图1和2说明本实施方式。本实施方式中提出的一种基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法为:
一、根据待评价的原始可疑文档dplg和待检索源文档集合中d中的源文档dsrc,构建文本片段的相似度矩阵m1;
二、学习局部匹配模式:将相似度矩阵m1作为网络输入,应用卷积神经网学习不同粒度上可疑文档和源文档的匹配模式,构建矩阵
三、获取特征矩阵:对于表达不同粒度匹配关系的特征矩阵,执行ki-maxpooling操作,以该粒度下前ki个最大的文本片段的相似度来代表该粒度的语义匹配程度,获得特征矩阵
四、学习特征的组合关系,识别抄袭源文档:将特征矩阵
本实施方式是利用卷积神经网络建模源检索的局部语义匹配,针对源检索特点进行文档间的“部分匹配”建模,而不是“完全相关”建模。
本实施方式中,在构建文本片段的相似度矩阵m1之前,对原始可疑文档dplg和原始源文档dsrc进行预处理,所述预处理包含但不仅限于:对原始的源文档和可疑文档文档进行去除停用词、去除标点符号、将所有英文单词转换为小写并进行词干提取的操作,然后当p<m或者q<n时按每个片段30个词项term的大小划分为文本片段。
所述停用词表如网站https://www.ranks.nl/stopwords所示。所述词干提取可以采用现有常用的porter算法实现。
原始可疑文档dplg经过预处理之后获得可疑文档dplg={s1,s2,...,si,...,sp},si为可疑文档dplg的文本片段,p为可疑文档dplg的文本片段的数目。
待检索源文档集合中d中的原始文档dsrc经过前述预处理之后获得文档dsrc={r1,r2,...,rj,...,rq},rj为文档d的文本片段,q为文档d中的文本片段数目。
所述相似度矩阵m1∈rm×n,m1中的mij表示可疑文档dplg中的文本片段si和源文档dsrc中的文本片段rj的相似度,参见图2所示,当p<=m且q<=n时,可以通过计算si和rj令获得mi,j;当p>m或者q>n时,忽略多余部分的文本片段相似度。相似度矩阵的大小可以根据实际情况进行调整,例如可以选择m=200,n=500。
具体实施方式二.本实施方式提出了具体实施方式一所述的一种基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法中,相似度矩阵m1中的mij的获得方法,本实施方式是通过余弦距离(cosinedistance)等方法计算获得mij的。
具体方法例如:根据公式
计算获得mij,公式中
具体实施方式三.本实施方式给出了具体实施方式一所述的一种基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法中,学习局部匹配模式的一种具体方法,即:将m1作为网络输入使用连续卷积的方式学习文本的局部匹配模式进而获得矩阵
本实施方式所述使用连续卷积的方式学习文本的局部匹配模式进而获得矩阵
然后对矩阵
为在源检索中建模局部语义匹配,基于卷积神经网,本实施方式中使用连续卷积的方式学习文本的局部匹配模式。
本实施方式中所述的卷积操作为公式(2)实现,
其中
依据上述卷积操作,对相似度矩阵m1使用2×2的卷积操作得到矩阵m2的过程为:将相似度矩阵m1作为第一次层卷积的输入,该层卷积参数为ci=1,co=16,fb=2,σ=max(0,x);本方法中
依据上述卷积操作,对矩阵m2进行2×2的卷积操作获得特征矩阵m3的过程为:第二层卷积参数为ci=16,co=32,fb=2,σ=max(0,x);本方法中
具体实施方式四.本实施方式给出了具体实施方式一所述的一种基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法中,三、获取特征矩阵的一种具体方法,即采用最大池化maxpooling方法对卷积操作捕获的特征进行池化层操作,提取出最有效的特征作为最终判别抄袭源文档的特征矩阵
在该方法中,对于不同次数卷积的卷积核生成了多特征映射矩阵,而可疑文档和源文档中的大部分片段的匹配度为零。因此,过滤掉不需要的部分匹配段是必要的。对于这个目标,模型使用两次k-max池化操作来自动提取抄袭特征。具体来说,对于第一个k-max池化操作,扫描
依据上述池化操作:首先将相似度矩阵m1按kn=1,km=500,k1=1池化操作得到向量n1,在将n1进行k2=20池化操作得到n′1,n′1表示dplg与文档dsrc的每个文本片段之间相似的最显著特征;
其次,对于特征矩阵
最后,对于特征矩阵
具体实施方式五.本实施方式给出了具体实施方式一所述的一种基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法中,四、学习特征的组合关系,识别抄袭源文档的一种具体实现方法,该方法将特征矩阵
具体方法例如:将特征矩阵
(p0,p1)t=δ2(w2δ1(w1z+b1)+b2)(3)
其中,w1∈r9800×1024,w2∈r1024×2,b1∈r1024×2,b2∈r2×1,p0和p1表示模型对标签的预测概率,wi是多层感知器mlp的第i层的权重矩阵,bi为多层感知器mlp第i层的偏置向量;δ表示激励函数,激励函数δ1使用relu函数,定义为:
relu=max(0,x)(4)
激励函数δ2使用softmax函数输出每个类别的匹配值如下:
具体实施方式六.本实施方式提出的是对前述实施方式中所述的一种基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法的进一步限定,本实施方式增加了对模型进行训练的步骤,具体训练方法为:
模型使用交叉熵损失函数对预测结果计算损失值如下:
其中,n为传入训练模型中样本的数,y为期望标签,p1为模型的预测输出,w2是权重的二范数正则化项,η是学习率;模型训练中,学习率为η=10-4,使用adamoptimizer优化方法对损失进行优化;为预防过拟合,在mlp训练阶段,随机选取70%神经元进行连接,按每次400个样例对参数进行一次更新,共训练1000轮。
具体实施方式七.本实施方式是在pan@clef2013抄袭源检索数据集上,对本发明所述的一种基于面向源检索的局部匹配卷积神经网络模型获得抄袭源文档的方法的效果进行验证的具体过程及验证结果。
验证的实验数据集使用了根据webis2012文本复用数据集webis-trc-2012构建的pan@clef2013抄袭源检索评测的训练数据pan2013trainingcorpus和测试数据pan2013testcorpus2。文献potthastm.,hagenm.,gollubt.,tippmannm.,kieselj.,rossop.,stamatatose.,&steinb.(2013).overviewofthe5thinternationalcompetitiononplagiarismdetection.inproceedingsofclef2013evaluationlabsandworkshop,valencia,spain,301–331.中详细描述了该数据集的构建和结构。该数据集的统计信息如表1所示。
表1实验数据集统计信息
根据pan的设置,本次实验选择clueweb09数据集作为抄袭源文档集合。clueweb09数据集合包含1,040,809,705个web页面,由10种语言组成,是当前trec(http://trec.nist.gov)评估会议上被广泛接受的评估检索模型的数据集。
本实验使用pan@clef定义的源检索的评价指标评价本发明所述的方法。
给定一篇可疑文档dplg,dplg包含了抄袭的文本片段,这些文本片段来源于源文档集合dsrc中的文档。设源检索算法的检索结果的文档集合为dret,pan@clef用f-score、精确率precision和召回率recall来评价源检索算法的性能。
由于dsrc来源于clueweb09数据集,clueweb09中包含了很多相同或相似的web文档,pan将这些文档称为“重复文档”(duplicatedocument),pan在评价源检索算法时,考虑了这些重复文档的影响。对于任一dret∈dret,评价指标计算方法使用一个重复文档检测器来判断dret是否是一个正确的检测结果,即,是否存在一个dplg的真正的抄袭源dsrc∈dsrc与dret为重复文档。对于文本对(dsrc,dplg),如果下面的条件满足,则可将dret视为一个正确的检测结果:
(1)dret=dsrc,
(2)dret和dsrc的3-gram的jaccard相似度大于0.8,或者5-gram的jaccard相似度大于0.5,或者8-gram的jaccard相似度大于0,
(3)已知dplg的片段是从dsrc复用来的,这些片段包含在dret中。
文献potthastm.,hagenm.,volskem.,&steinb.,(2013).crowdsourcinginteractionlogstounderstandtextreusefromtheweb,inproceedingsofthe51stannualmeetingoftheassociationforcomputationallinguistics,acm,sofia,bulgaria,2013,pp.1212–1221.详细描述了上述定义。本实验中,如果文档d1是d2的正确的检测结果,则记为positivedet(d1,d2)。
定义:
基于上述描述,pan将源检索的精确率precision和召回率recall定义为:
精确率表示检索到的确切的抄袭源与检索到的文档的比率,该指标评价了一个算法检索到正确抄袭源的能力。召回率表示检索到的确切的抄袭源与全部抄袭源的比率。高的精确率可以通过只保留具有高可信度为抄袭源的文档而获得,因此,一般情况下高精确率都以低召回率为代价。召回率与漏检率对应,类似的,高召回率可以通过牺牲精确率,保留大量的检索结果获得。因此,信息检索中提出了fβ这个指标来获得精确率和召回率的折中,fβ定义如下:
pan所定义的源检索指标f-score就是等式9,当β=1时的f-score,如公式10所示:
本发明的实验选择了williams方法作为基线方法。williams方法是pan抄袭检测评测中最成功的源检索方法,在pan2013和pan2014的评测中均获得了最高的f-score。
为了比较的目的,本实验方法和基线方法的源检索过程都参照了williams方法。williams方法的源检索过程遵循了pan总结的一般的源检索过程:查询生成、检索和检索结果过滤,具体过程为:
(1)查询生成。williams方法假设动词、名词和形容词更可能是查询词,因此,williams方法仅使用动词、名词和形容词构建查询。在williams方法中,可疑文档首先被划分为文本片段,每个文本片段由五个句子组成,然后使用斯坦福大学开发的词性标注工具stanfordpostagger分析每个文本片段中词的词性,仅保留动词、名词和形容词。然后,在每个文本片段上按所获得的动词、名词和形容词在原文中的顺序,每个文本片段提取三个查询,每个查询由十个词组成。
(2)检索。实验使用了chatnoir(pan提供及建议的搜索引擎,https://www.chatnoir.eu/doc/api/)作为检索抄袭源的搜索引擎,并依据chatnoir提供的api请求搜索引擎的返回结果信息和检索结果的快照信息,这些信息将用于获取特征。然后,依据查询生成的顺序,提交查询。对于每个查询,本发明方法和基线方法均保留了检索结果的前三个。
(3)检索结果过滤。对于williams方法,根据williams的报告,lda方法获得了最高的f-score。故本发明训练了一个lda分类器,将检索结果按照分类器的输出概率排序,然后在训练数据上以获得最优的f-score为目标学习一个阈值,用该阈值对检索结果过滤,保留大于该阈值的检索结果作为最终结果,将这种方法称为williamslda-prob。
对于本发明提出的pm-cnn方法,依次使用训练阶段学到的模型,获得每个源文档为抄袭源的概率,参考williams方法,在训练数据上以获得最优的f-score为目标学习一个阈值,用该阈值对检索结果过滤,保留大于该阈值的检索结果作为最终结果。
为了使实验结果与pan@clef的评测结果可比较,实验数据依据了pan的设置,以pan2013trainingcorpus数据集作为训练数据,在pan2013testcorpus2的数据上做测试。
实验结果如表2所示。
表2源检索的实验结果
表2的实验结果表明,以f-score为主要评价指标,本发明提出的pm-cnn模型较williams方法的性能获得了提升。对实验结果进行了单边成对t检验,验结果表明在p<0.05水平上提升具有统计显著性。
- 还没有人留言评论。精彩留言会获得点赞!