基于深度信息与尺度感知信息的单张图像人群计数方法与流程
本发明涉及计算机视觉技术,具体涉及一种基于深度信息与尺度感知信息的单张图像人群计数方法。
背景技术:
人群计数旨在通过输入一张图片,经网络模型处理后,输出该图片对应的人群密度图,最后对密度图上每个像素对应的人数概率求和得到最终的总人数。由于遮挡、视角变化、人群尺度变化和分布多样性等问题,人群计数任务充满了挑战。
早期的方法主要通过目标检测器定位人群中每一个行人,检测到的目标数量即为计数结果。但是这些方法使用手工特征进行分类器的训练,在高度拥挤的场景中表现较差。为了解决复杂场景人群计数问题,现有利用卷积神经网络生成人群密度图,通过捕获尺度变化改善计数的性能。
2016年zhang等人提出了mcnn算法来应对尺度变化,该算法由三个分支网络组成,每个分支网络采用不同大小的感受野对特征进行采样。对于给定的图片,分别经过三个分支网络处理,将得到的结果进行通道融合,最后通过1*1卷积得到最终的密度图。但是由于该设计方案仅仅涉及三个不同的尺度的卷积,每一类只能服务于一定的密度等级。然而,在实际的场景中存在着密集的变化,人群分布不均,不能严格将人群图片归于哪一个类别,所以mcnn算法的有效性被分支数目所限制。
2018年cao等人提出了sanet算法来改善尺度感知结构,使用inception结构集成尺度信息,在每一个卷积层上使用多个卷积核进行卷积操作,将各部分信息融合,充分共享了底层到顶层的信息。该网络中包括四个inception结构,并在每个inception结构后使用转置卷积进行尺度还原,使得生成的密度图与输入的密度图大小相同,可以进行像素级别的监督。但是人群计数场景中,受相机角度的影响,图像中远距离的行人表现为小目标。图像中这种小目标居多,且为主要的研究对象。使用inception结构虽然可以集成多尺度信息,但随着网络的前向传递,特征高度抽象化,小目标的细节特征丢失,导致最终小目标的预测能力下降。另外,使用转置卷积进行尺度还原,计算的复杂度高,在一定训练批次范围内,其性能没有突出优势。
技术实现要素:
本发明所要解决的技术问题是:提出一种基于深度信息与尺度感知信息的单张图像人群计数方法,提高预测能力并降低计算复杂度。
本发明解决上述技术问题采用的技术方案是:
基于深度信息与尺度感知信息的单张图像人群计数方法,包括以下步骤:
s1、对输入样本图片对应的人头中心坐标数据进行高斯映射,生成初步真值密度图,并基于深度估计算法得到的深度信息修正初步真值密度图,获得真值密度图;
s2、采用密度估计网络对输入样本图片进行人群密度图的预测,生成预测密度图,根据预测密度图与真值密度图计算损失误差,通过梯度反向传播调整网络参数,经过迭代,生成密度预测模型;
s3、在对单张图像进行人群计数时,利用密度预测模型生成此图像的预测密度图,通过计算获取此图像中的总人数。
作为进一步优化,步骤s1具体包括:
s11、将样本图片标签数据中的人头坐标点以固定尺寸的高斯核进行高斯分布映射,在图像的所有位置进行映射值的叠加,形成初步真值密度图f1(x);
s12、将样本图片标签数据中的人头坐标点以几何自适应高斯核进行高斯分布映射,在图像的所有位置进行映射值的叠加,形成初步真值密度图f2(x);
s13、采用单目深度估计算法提取输入样本图片中各个像素位置的深度信息,形成深度估计图depth(x);
s14、基于深度估计图depth(x)的信息,利用阈值分割算法确定最终的真值密度图:
其中,δ为预设的分割阈值,f1(i,j)表示初步真值密度图f1(x)中坐标(i,j)对应的值,f2(i,j)表示初步真值密度图f2(x)中坐标(i,j)对应的值,depth(i,j)表示depth(x)中坐标(i,j)处的深度值,m(i,j)表示最终的真值密度图在坐标(i,j)对应的值。
作为进一步优化,步骤s2中,所述密度估计网络包括:基础特征提取模块、多尺度捕获模块以及尺度转移模块;所述基础特征提取模块用于提取图片的纹理等低级特征;所述多尺度捕获模块用于图片特征的进一步提取、融合多尺度信息以及保存小目标的细节特征;所述尺度转移模块用于特征图的尺度还原,将特征图提升至输入图片的尺寸大小。
作为进一步优化,所述基础特征提取模块由vgg16网络中conv4_3之前的卷积层组成;所述多尺度捕获模块采用四层稠密连接层,每一层使用3×3卷积核提取特征,使用边缘填充保持特征图的分辨率不变,卷积的增长率设为256;所述尺度转移模块采用亚像素卷积进行特征图的尺度还原,将特征图的分辨率提升至输入图片大小。
作为进一步优化,步骤s2中,根据预测密度图与真值密度图计算损失误差,具体包括:
使用欧式距离作为损失函数度量预测密度图与真值密度图之间的误差,表达式为:
其中,f(xi;θ)是网络输出的预测密度图,θ表示网络中的学习参数,xi表示输入的第i张图片,
本发明的有益效果是:
(1)监督信息更为精确:
本发明利用深度信息指导真值密度图的生成,生成的真值密度图比以往单一方式生成的真值密度图更为精确。利用该信息指导网络训练,预测的密度图更接近真实值。
(2)能够捕获大范围的尺度变化:
本发明利用稠密连接构建适合当前场景的多尺度捕获模块,融合多尺度信息的同时,保留更多的小目标细节特征,将有助于提高网络对于多尺度目标的预测性能。
(3)以较低计算复杂度进行尺度还原:
本发明利用亚像素卷积模块进行尺度还原,避免使用双线性插值上采样而忽略图像自身特性的问题,同时避免了使用转置卷积上采样的计算复杂性。
附图说明
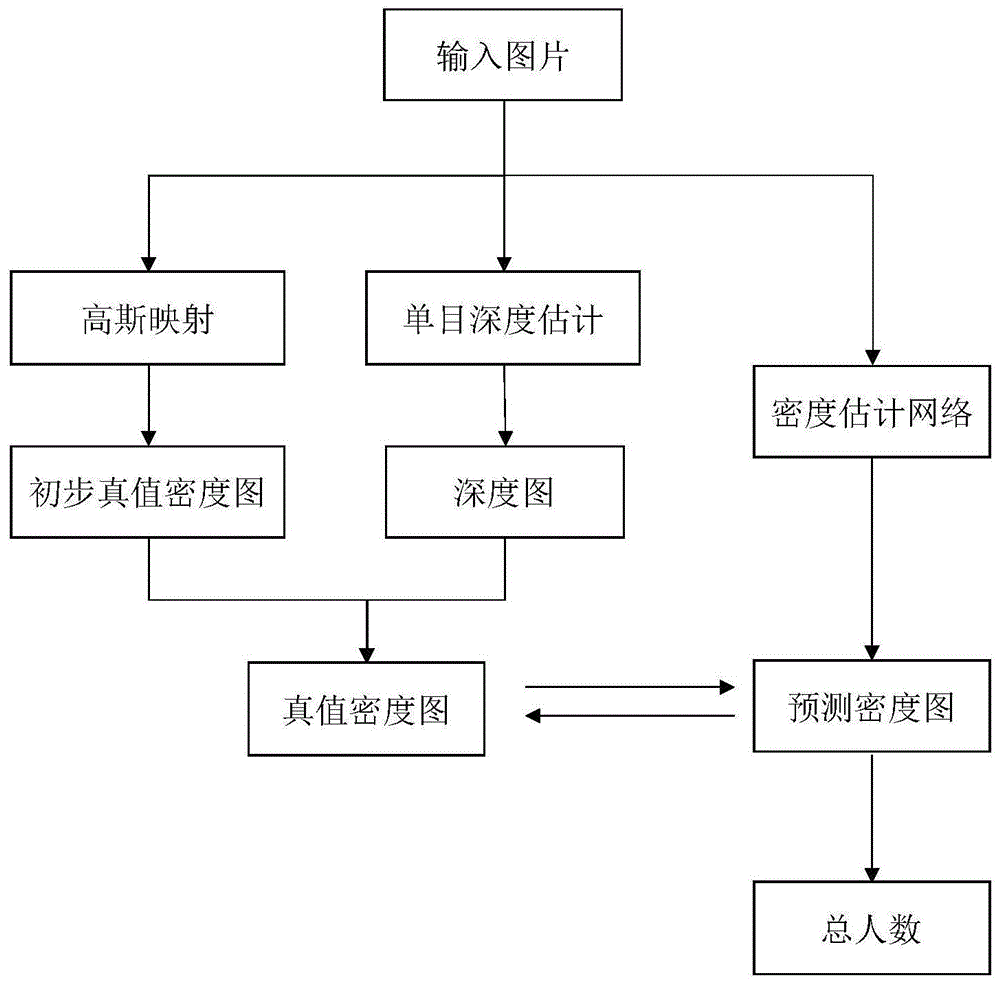
图1为本发明基于深度信息与尺度感知信息的人群计数算法流程图;
图2为真值密度图的生成过程图;
图3为密度估计网络生成预测密度图进行人群计数的过程图。
具体实施方式
本发明旨在提出一种基于深度信息与尺度感知信息的单张图像人群计数方法,提高预测能力并降低计算复杂度。其核心思想是:(1)训练预测模型:首先生成初步真值密度图,然后,基于深度估计算法得到的深度信息修正初步真值密度图,从而获得真值密度图,用于点对点监督密度估计网络产生的预测密度图,根据真值密度图与预测密度图之间的误差,通过梯度反传调整网络参数,经过迭代,从而产生最终的预测模型;(2)基于训练的预测模型来实现输入图片的密度图的预测,并计算图中的总人数。
本发明中真值密度图生成,并不是借助单一的固定高斯核映射或几何自适应高斯核映射,而是基于人群图片的来源分析,图片中距离相机近的目标尺寸大,目标之间距离较大。距离相机较远的目标受视角影响,目标较小、目标之间距离较小。鉴于此,引入图片的深度信息来指导真值密度图的生成,获取更为精确的密度图监督预测密度图的生成。
本发明中获取预测密度图的过程中,使用稠密连接结构,融合多尺度特征的同时充分保留小目标细节特征,解决了现有方法在捕获多尺度特征时丢失小目标细节特征的问题。为了提升预测图的分辨率,充分利用图像自身信息,使用通道信息填充维度信息的方法。避免了现有方法使用线性插值上采样引入的手工特征的影响,同时避免转置卷积方式带来的计算复杂度。
在具体实现上,如图1所示,本发明中的基于深度信息与尺度感知信息的人群计数算法流程包括以下步骤:
s1:获得输入样本图片的真值密度图:
为获得输入样本图片的真值密度图标签,需要对输入图片对应的人头中心坐标数据进行高斯映射,生成初步真值密度图。然后基于深度估计算法得到的深度信息修正初步真值密度图,得到的真值密度图标签用于点对点监督密度估计网络产生的预测密度图。
这里会利用两种高斯映射方式,分别为固定高斯核函数和几何自适应高斯核函数,由这两种方式生成的初步真值密度图再通过深度信息进行融合生成最终的真值密度图,具体过程如图2所示。
s11、固定高斯核映射方式:
假定一个头部标注点的坐标为xi,使用δ(x-xi)表示高斯分布位置,因此有n个人头的图片可以表示为
s12、几何自适应高斯核映射方式:
通过每个人与邻近对象的平均距离决定相关参数对于图片中的每个头部标记xi,标记其m个临近对象标记为
s13、深度估计图的提取:
本发明通过单目深度估计算法计算出输入样本图片对应的深度图,基于深度图的信息,利用阈值分割算法进行图片中每个位置的高斯映射值的修正,融合两种密度图信息形成最终的密度图。具体的,可以使用monodepth算法估计输入样本图片的深度信息,输入样本图片经过monodepth算法模型得到一张灰度图,该图上的每个像素值代表相机到物体表面的距离。
s14、利用深度信息融合s11、s12中生成的密度图:
假定输入图片为x∈rh×h×c,其中h表示图片的尺寸大小,c表示图片的维度,使用固定高斯核函数得到真值密度图f1(x)。对输入图片使用几何自适应高斯核函数映射,得到的真值密度图为f2(x)。将输入图片经monodepth模型处理,得到深度信息图depth(x)。基于深度信息对得到的两类真值密度图信息做进一步的处理,对于真值密度图f1(x)、f2(x),根据预设的深度阈值δ进行分割的操作如下:
其中f1(i,j)表示密度图f1(x)中坐标(i,j)对应的值,f2(i,j)表示密度图f2(x)中坐标(i,j)对应的值,depth(i,j)表示depth(x)中坐标(i,j)处的深度值,m(i,j)表示最终的真值密度图在坐标(i,j)对应的值。
s2、基于密度估计网络获取输入样本图片的预测密度图(密度估计图):
本发明中所采用的密度估计网络有三个主要部分组成:基础特征提取模块、多尺度捕获模块、尺度还原模块;其中,基础特征提取模块主要用于提取图片的纹理等低级特征;多尺度捕获模块用于特征的进一步提取、融合多尺度信息以及保存小目标的细节特征;尺度转移模块主要用于特征图的尺度还原,将特征图提升到输入图片的尺寸大小。
s21、基础特征提取模块:
该模型可以使用预训练的vgg模块中的层。以256×256大小的图片作为输入,分析vgg16中的卷积层,conv4_3层其感受野范围达到了172,已远远超出了大目标的尺度。当前场景下,大目标的尺度在图片中的占比不到二分之一,最终,本发明决定采用的基础特征提取模块由vgg16中conv4_3之前的卷积层组成。
s22、多尺度捕获模块:
为保留当前场景中小目标的细节特征,基础特征提取模块输出的特征信息通过多尺度模块依次向后传递,避免了现有研究方法丢失细节信息造成的性能瓶颈。与resnet的随机短连接不同,稠密连接在层与层之间保证了最大程度的信息共享。通过感受野分析,增加四层稠密连接,其感受野范围能够满足所有尺寸目标的语义信息的提取。为了保证该模块能够提取到足够的上下文信息,同时避免增长率过高,该模块每一层使用3×3卷积核提取特征,使用边缘填充保持特征图的分辨率不变,卷积的增长率设为256。由于基础网络的输出通道为512维,进入尺度捕获模块之前需要进行维度转换为256通道的特征图。
s23、尺度还原模块:
该模块基于亚像素卷积提升特征图的分辨率,由于基础特征提取部分使用三次池化操作将图片进行8倍下采样,大小变为原来的1/8。在多尺度捕获模块,需要将多层特征图进行通道连接,故使用边缘填充保持特征图大小不变。为了进行尺度还原,我们需要对特征图进行8倍上采样。由于亚像素卷积操作中低分辨率特征图的数量必须是上采样因子的平方数,所以,本文在多尺度捕获模块结构后增加一个1×1卷积,将特征图的通道数调整为上采样因子的平方数64。最后,使用通道特征进行特征图的维度填充。
基于上述结构的密度估计网络生成预测密度图的过程如图3所示,输入样本图片首先经过基础特征提取部分提取基础特征,然后进入多尺度特征捕获模块融合尺度信息,最后进行尺度还原生成预测密度图。
在生成输入样本图片的预测密度图后,根据预测密度图与真值密度图计算损失误差,通过梯度反向传播调整网络参数,经过迭代,生成密度预测模型;
在训练过程中,使用欧式距离作为损失函数训练人群密度估计算法,欧式损失主要用于计算像素级别的估计误差,其表达式为
密度预测模型的输入:用于训练的人群图片及标签数据
1、数据预处理:获取图片的初步真值密度图f1(xi)、f2(xi);取图片的深度图信息depth(xi);确定深度分割阈值δ;基于深度信息,得到最终的真值密度图m(xi);
2、模型参数初始化,然后训练模型,直至模型收敛:按批次载入图片;基础特征提取,更新特征图fi1∈rh1×h1×c1←xi∈rh×h×c;对特征图进行通道变换fi1∈rh1×h1×c2←fi1∈rh1×h1×c1;多尺度捕获,更新特征图fi2←fi1;对特征图进行通道变换
其中模型参数的初始化,除了参与训练的vgg部分,其余部分的卷积核参数均使用高斯函数进行初始化,其标准差设置为0.01。模型的优化使用adam算法代替常规的随机梯度下降算法,为了使得模型能够快速收敛,设置固定的学习率为1e-5。
在训练出稳定的密度预测模型后,就可以在实际应用中,利用此模型对输入图片生成此图像的预测密度图,在获得密度图之后,通过像素点求和即可获得图中的总人数,其为现有计算,这里不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!