一种基于协同引力搜索算法的造纸过程模型辨识方法与流程
本发明涉及造纸设备系统辨识技术领域,尤其涉及一种基于协同引力搜索算法的造纸过程多输入多输出模型辨识方法。
背景技术:
纸是人们日常生活中不可或缺的产品。为了更好的对造纸设备进行分析、预测以及控制,必须为造纸设备的造纸过程建立系统模型,同时辨识所建立模型的参数。为此,已经有不少学者提出的不同的辨识方法:如最小二乘法、梯度迭代法、神经网络法以及各种群智能算法等。
由于最小二乘法的辨识精度不够理想,在实际的生产中的辨识效果往往不尽如人意;梯度迭代法容易使辨识结果陷入局部最优,同时梯度迭代法还需要选择一个较为合适的迭代步长,迭代步长选择过大会导致辨识结果发散,迭代步长选择过小会导致辨识速度过慢;神经网络法所需要的数据量过大,不适合数据量较小的情况。
如何解决上述技术问题为本发明面临的课题。
技术实现要素:
本发明的目的在于提供一种基于协同引力搜索算法的造纸过程模型辨识方法;本发明提出的协同引力搜索算法是一种群智能算法,它有着较高的辨识精度,同时它还能较快的跳出局部最优的情况,而且该算法具有所需数据量较小的优点,能够较好地适用于对造纸过程的建模与参数辨识。
本发明是通过如下措施实现的:一种基于协同引力搜索算法的造纸过程模型辨识方法,其中,具体包括以下步骤:
步骤1)构建造纸生产设备的多输入多输出模型,根据所构建的系统模型获取造纸生产过程的辨识模型;
步骤2)构建协同引力搜索算法的辨识流程。
作为本发明提供的一种基于协同引力搜索算法的造纸过程模型辨识方法进一步优化方案,所述步骤1)的具体建模步骤如下:
步骤1-1)构建造纸过程的多输入多输出模型:如式(1),给出多输入多输出系统的一般形式,u(t)为系统的输入,y(t)为系统的输出,w(t)为有色噪声,其中,
a(z)y(t)=b(z)u(t)+ω(t)(1)
步骤1-2)根据式(2)、(3)可以得到输出y(t)与输入u(t),误差ν(t)之间的关系,其中,
γ(t):=[-yt(t-1),…,-yt(t-na),-ut(t-1),…,-ut(t-nb)]t∈rn,
作为本发明提供的一种基于协同引力搜索算法的造纸过程模型辨识方法进一步优化方案,所述步骤1)的模型为一般多输入多输出系统的模型。
作为本发明提供的一种基于协同引力搜索算法的造纸过程模型辨识方法进一步优化方案,所述步骤2)构建协同引力搜索算法的辨识流程的具体步骤如下:
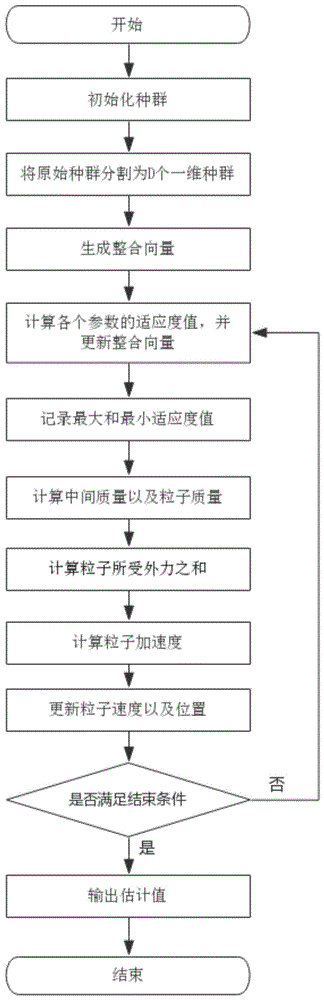
步骤2-1)初始化种群,生成一个有n个d维粒子的种群,其中任意粒子xi=[x(i,1),x(i,2),…,x(i,d)],d为所需辨识参数个数;
步骤2-2)将步骤2-1)中的种群按如下方法分割为d个一维种群:
步骤2-3)获取造纸设备的造纸材料总量以及蒸汽压力作为输入数据,造纸设备产生的水分以及基本重量为输出数据,记录数据;
步骤2-4)生成一个用于将d个种群的单个参数整合在一起的向量,所述向量定义为整合向量g=[g1,g2,…,gj,…,gd],其中gj为第j个种群中的某一个粒子;
步骤2-5)依次使用x(i,j)替换gj,从而生成一个新的整合向量g',并将g'代入适应性函数fitness(θ)计算其适应度值fitness(g'),若fitness(g')<fitness(g),则令g=g';
步骤2-6)将最大的适应度值记为fworst,将最小的适应度值记为fbest;
步骤2-7)根据式(4)、(5)计算中间质量mi(t)、粒子质量mi(t);
步骤2-8)根据式(6)、(7)计算两粒子之间的引力
其中,rij(t)为粒子i与粒子j之间的欧氏距离,ε为一个很小的常量,万有引力常量g(t)的计算方法如下:
其中,g0是引力常量初始值,α是个常数,β是当前迭代次数;
步骤2-9)根据式(9)计算粒子的加速度ad(t);
步骤2-10)根据式(10)、(11)更新粒子的速度
步骤2-11)判断是否达到最大迭代次数,若没有达到,程序跳转到步骤2-5),若达到,进入步骤2-12);
步骤2-12)输出结果,完成辨识。
与现有技术相比,本发明的有益效果为:使用本发明的协同引力搜索算法的造纸过程模型辨识方法进行的参数辨识结果可以看出,本方法的辨识精度较高,输出的估计误差值较小;同时,也说明本辨识方法对于本造纸设备模型有较好的适用性。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
图1为本发明的协同引力搜索算法流程图。
图2为本发明的造纸设备示意图。
图3为本发明的其中一个输出真实值与估计值之间的比较图。
图4为本发明的其中一个输出真实值与估计值之间的比较图。
图5为本发明辨识参数与真实值的误差示意图。
图6为本发明多输入多输出系统的一般模型示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。当然,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
实施例1
参见图1至图6,本发明提供其技术方案为,一种基于协同引力搜索算法的造纸过程模型辨识方法,其中,具体包括以下步骤:
步骤1)构建造纸生产设备的多输入多输出模型,根据所构建的系统模型获取造纸生产过程的辨识模型;
步骤2)构建协同引力搜索算法的辨识流程。
具体地,所述步骤1)的具体建模步骤如下:
步骤1-1)构建造纸过程的多输入多输出模型:如式(1),给出多输入多输出系统的一般形式,u(t)为系统的输入,y(t)为系统的输出,w(t)为有色噪声,其中,
a(z)y(t)=b(z)u(t)+ω(t)(1)
步骤1-2)根据式(2)、(3)可以得到输出y(t)与输入u(t),误差ν(t)之间的关系,其中,
γ(t):=[-yt(t-1),…,-yt(t-na),-ut(t-1),…,-ut(t-nb)]t∈rn,
具体地,所述步骤1)的模型为一般多输入多输出系统的模型。
具体地,所述步骤2)构建协同引力搜索算法的辨识流程的具体步骤如下:
步骤2-1)初始化种群,生成一个有n个d维粒子的种群,其中任意粒子xi=[x(i,1),x(i,2),…,x(i,d)],d为所需辨识参数个数;
步骤2-2)将步骤2-1)中的种群按如下方法分割为d个一维种群:
步骤2-3)获取造纸设备的造纸材料总量以及蒸汽压力作为输入数据,造纸设备产生的水分以及基本重量为输出数据,记录数据;
步骤2-4)生成一个用于将d个种群的单个参数整合在一起的向量,所述向量定义为整合向量g=[g1,g2,…,gj,…,gd],其中gj为第j个种群中的某一个粒子;
步骤2-5)依次使用x(i,j)替换gj,从而生成一个新的整合向量g',并将g'代入适应性函数fitness(θ)计算其适应度值fitness(g'),若fitness(g')<fitness(g),则令g=g';
步骤2-6)将最大的适应度值记为fworst,将最小的适应度值记为fbest;
步骤2-7)根据式(4)、(5)计算中间质量mi(t)、粒子质量mi(t);
步骤2-8)根据式(6)、(7)计算两粒子之间的引力
其中,rij(t)为粒子i与粒子j之间的欧氏距离,ε为一个很小的常量,万有引力常量g(t)的计算方法如下:
其中,g0是引力常量初始值,α是个常数,β是当前迭代次数;
步骤2-9)根据式(9)计算粒子的加速度ad(t);
步骤2-10)根据式(7)、(8)更新粒子的速度
步骤2-11)判断是否达到最大迭代次数,若没有达到,程序跳转到步骤2-5),若达到,进入步骤2-12);
步骤2-12)输出结果,完成辨识。
本实施例采用的造纸设备简图如图2所示。其中,u1(t)和u2(t)分别为原材料质量、蒸汽压力,y1(t)和y2(t)分别为水分、剩余材料及成品的基本重量。
通过上述提到的一般多输入多输出模型,可以将本实施例建立以下模型:
对比上述模型和步骤1),可得
c1=-0.12,c2=0.11,d1=0.15,d2=-0.12.
对于以上模型确定一个适应度函数fitness以便在协同引力搜索算法中使用,该适应度函数定义如下:
式中,
为了方便将所需辨识的参数代入协同引力搜索算法,将所需辨识的参数组成一个向量θ,假设所需辨识的参数如下:
则令所需辨识的参数向量
θ=[a1(a1),a2(a1),a3(a1),a4(a1),a1(a2),a2(a2),a3(a2),a4(a2),b1(b1),b2(b1),b3(b1),b4(b1),b1(b2),b2(b2),b3(b2),b4(b2),c1,c2,d1,d2]
根据步骤2-1)和步骤2-2)初始化种群,得到20个有n个个体的1维种群θ1,θ2,…,θ20;
根据步骤2-3)获得的输入输出数据以及步骤2-4)和步骤2-5)依次计算各个参数的适应度值fitness(g');
根据步骤2-6)将最大的适应度值记为fworst,将最小的适应度值记为fbest;
根据步骤2-7)计算中间质量mi(t)、粒子质量mi(t);
根据步骤2-8)计算两粒子之间的引力
根据步骤2-9)计算粒子的加速度ad(t);
根据步骤2-10)更新粒子的速度
根据步骤2-11)和步骤2-12)完成循环。
其中,种群中的个体数n、引力常量的初始值g0的设定需要考虑如下几个问题,种群中个体数过多会加大计算量,个体数过小会导致种群协作寻优效果不理想从而导致辨识结果精度过小,引力常量的初始值过大会导致每次迭代以后种群个体位置的变化量过大,最终导致辨识结果发散,引力常数过小则会导致每次迭代以后种群个体位置变化量过小,最终造成辨识速度过慢。
使用本发明的协同引力搜索算法的造纸过程模型辨识方法进行的参数辨识结果如图3、图4以及图5所示。可以看出,本方法的辨识精度较高,输出的估计值与真实值非常接近。同时,也说明本辨识方法对于本造纸设备模型有较好的适用性。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!