一种基于批次分块遮挡网络的行人再辨识方法与流程
发明涉及计算机视觉技术领域,具体是一种基于批次分块遮挡网络的行人再辨识方法。
背景技术:
行人再辨识旨在用于解决跨摄像场景行人身份再认的问题,即对不同监控场景中的行人进行身份再认,属于图像检索的一个分支。行人再辨识广泛应用于智能安防,无人超市,人机交互,相册聚类等领域。由于行人图像的分辨率变化大、拍摄角度不统一、光照条件差、环境变化大、行人姿态不断变化等原因,使得行人再识别成为目前计算机视觉领域一个既具有研究价值又极具挑战性的热点和难点问题。目前,行人再辨识领域研究工作主要分为以下几类:1.研究行人对象的特征表示方法,提取更加具有鲁棒性的鉴别特征对行人进行表示;2.基于局部特征的行人再辨识方法;3.使用距离度量学习方法,通过学习一个有判别力的距离度量函数,使得同一个人的图像间距离小于不同行人图像间的距离。
上述基于特征的方法都是使用标准距离(如曼哈顿距离、欧氏距离和巴氏距离等)进行相似性度量。然而同一身份行人在跨越多个无重叠区摄像头时,不同外貌特征受视角、光照等因素的影响不同,标准的距离度量方法平等的对待每一种特征,而不会摒弃那些独立使用时效果很差的特征。因此,研究者尝试通过距离学习的方法,获得一个新的距离度量空间,使得同一行人不同图像的距离小于不同人间的距离。距离学习方法一般在mahalanobis距离的基础上进行,通过学习一个投影矩阵,使得在投影空间中同类样本之间的距离较小,而不同类样本之间的距离较大。基于局部特征的行人再辨识方法,常用的提取局部特征的思路主要有图像切块、利用骨架关键点定位以及姿态矫正等等,图片切块是一种很常见的提取局部特征方式,其中将输入的特征图均匀水平分割为若干份更符合对人体的直观感受,度量学习(metriclearning)是广泛用于图像检索利于的一种方法。不同于表征学习,度量学习旨在通过网络学习出两张图片的相似度。在行人重识别问题上,具体为同一行人的不同图片相似度大于不同行人的不同图片。最后网络的损失函数使得相同行人图片(正样本对)的距离尽可能小,不同行人图片(负样本对)的距离尽可能大。常用的度量学习损失方法有对比损失(contrastiveloss)、三元组损失(tripletloss)、四元组损失(quadrupletloss)、难样本采样三元组损失(triplethardlosswithbatchhardmining,trihardloss)、边界挖掘损失(marginsampleminingloss,msml)。
随着深度学习研究的不断深入,各种基于深度学习的行人再辨识方法不断被提出。但行人再辨识仍面临诸多挑战,主要原因如下:①背景杂乱和遮挡;②同一行人在不同时间内有着不同的外表;③光照强度不同;④不同行人有着相似外表。基于卷积神经网络(convolutionalneuralnetworks,cnn)的识别方法主要把特征学习的重点放在人体的主干部分,而手、脚、脸等部分通常会被忽略。为此,基于姿态定位的方法是通过先定位不同的身体特征再使用对齐来改进识别性能,也有一些方法使用传统粗分割或选择注意网络方法来改进特征学习。但是这种基于姿态定位的方法通常会要求额外的姿态估计和语义信息,从而增加了问题的复杂度,为此,有必要发明一种批次分块遮挡网络来改进这些问题。
技术实现要素:
本发明的目的在于针对现有技术中存在的不足,提供一种基于批次分块遮挡网络的行人再辨识方法。这种方法识别能力强,提高了再辨识方法的性能。
实现本发明目的技术方案是:
一种基于批次分块遮挡网络的行人再辨识方法,包括如下步骤:
1)分集:将已知的行人再辨识数据集market-1501和dukemtmc-reid中的图像分为训练数据集和测试数据集;
2)预处理:将训练数据集和测试数据集中的所有图像进行统一尺寸裁剪,将完成裁剪后的训练数据集图像顺序打乱,测试数据集中的图像不做其余处理,为需要辨识的每个行人在训练数据集中随机选择k张图像,组成小训练批,其中k=32或64;
3)预训练:利用训练数据集对resnet-50网络进行预训练,初始化resnet-50网络中的参数,对输入的行人图像进行特征提取,预训练的步骤如下:
3-1)将步骤2)中完成裁剪的训练数据集图像输入到resnet-50网络中,训练数据集图像首先经过resnet-50网络中一个步长为2的7×7卷积和一个池化层,得到特征图1;
3-2)将特征图1输入resnet-50网络的第一卷积层,经过3个步长为1且内核大小为1×1的残差模块,输出特征图2;
3-3)将特征图2输入resnet-50网络的第二卷积层,经过4个步长为1且内核大小为3×3的残差模块,输出特征图3;
3-4)将特征图3输入resnet-50网络的第三卷积层,经过6个步长为1且内核大小为3×3的残差模块,输出特征图4;
3-5)将特征图4输入resnet-50网络的第四卷积层,微调resnet-50的网络结构,即在resnet-50网络的第四卷积层不使用下采样操作,所以经第四卷积层后特征图4大小不变,经过4个步长为1且内核大小为3×3的残差模块,输出特征图5;
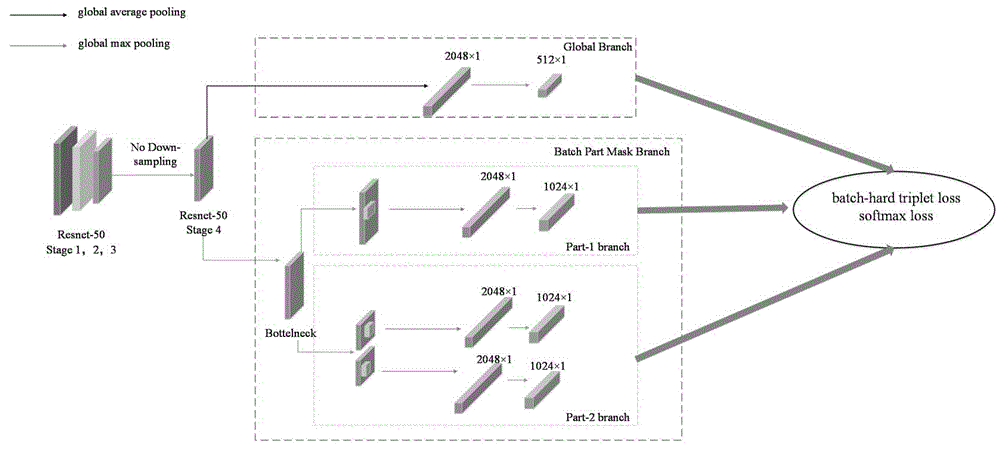
4)输入:resnet-50网络第四卷积层之后称为全局分支,将步骤3-5)中1/2数量的特征图5作为全局分支的输入,依次经过1×1卷积层、批处理归一化层和relu层得到特征图s;
5)构建批次分块遮挡模块:构建的批次分块遮挡模块由两个包含不同擦除模块的part1分支和part2分支组成,part1分支中的批量擦除层会随机擦除张量中的同一区域,将擦除区域内所有位置的值都归为0;part2分支则会先将输入的特征图均分成上下两块,然后在每一块中随机地遮挡一小块,即将遮挡区域内的所有值设为0,以步骤3-5)中另外1/2数量的特征图5作为批次分块特征遮挡模块的输入,然后利用全局最大池化得到2048维的特征向量,最后利用三元组损失和softmax损失将特征向量的维度从2048维降到1024维,设单批输入图像经part1分支在特征图上应用擦除处理后计算得到的特征图为t,设经part2分支在特征图上应用擦除处理后得到的特征图为t';
6)构建批次分块遮挡网络模型:在步骤3)的resnet-50网络的第四卷积层后添加一个批次分块遮挡模块,即完成批次分块遮挡网络模型的构建,批次分块遮挡网络模型即为行人再辨识网络模型;
7)训练行人再辨识网络模型:使用步骤4)的特征图s、步骤5)中的特征图t和特征图t'通过三元组损失和softmax损失函数对步骤6)中的批次分块遮挡网络模型进行优化,循环执行步骤7),直至损失值收敛;
softmax损失函数表示如下:
其中,b表示小训练批次样本数量,
三元组损失函数表示如下:
其中,
8)计算总训练损失:采用三元组损失函数和softmax损失函数计算总训练损失,总训练损失为三元组损失函数和softmax损失函数在全局分支和批次分块遮挡分支上的总和;
总训练损失表达式如下:
l=lg+λ1l1+λ2l2,
其中,lg表示全局分支上的损失,l1和l2分别代表特征删除分支上part1分支和part2分支的损失,λ1和λ2为控制part1分支和part2分支的权重,λ1和λ2均设置为1;
9)测试:将测试数据集输入到步骤7)训练后的行人再辨识网络模型中,行人再辨识网络模型读取测试数据集中的图像后,输出辨识结果,通过比较输出辨识结果与输入图像标签的泛化误差,来验证行人再辨识网络模型的训练效果和性能;
10)比较特征距离:从实时采集的视频中筛选出所有的行人图像组成候选库,并将候选库中的图像和待查询行人图像全部送入到批次分块遮挡网络模型中进行辨识分类,并比较它们之间的特征距离;
特征距离采用欧氏距离表示:
其中,x表示侯选库图像,y表示待查询行人图像,x1表示侯选库图像像素点的横坐标,x2表示侯选库图像像素点的纵坐标,y1表示待查询行人图像像素点的横坐标,y2表示待查询行人图像像素点的纵坐标;
11)完成再辨识:按照特征距离从小到大的顺序对实时采集的视频中筛选出所有的行人图像进行排序,排序从前到后相似性依次减小,即排位第一的训练图像是与待查询行人图像为同一行人的图像,找出指定对象的所有行人图像,从而完成行人再辨识。
本技术方案的方法使用resnet-50作为全局分支来提供全局特征表示,监督对特征删除分支的训练,并使特征删除分支应用于学习良好的特征映射,通过具有分块特性的特征遮挡分支来学习详细的特征,本技术方案的方法扩充了训练数据集的多样性,增强了深度神经网络对于行人的识别能力,提高了行人再辨识网络模型对于遮挡情境下行人再辨识方法的性能。
这种方法识别能力强,提高了再辨识方法的性能。
附图说明
图1为实施例中批次分块遮挡网络结构图;
图2为实施例中part1分支和part2分支的比较示意图;
图3为实施例中market-1501数据集上检索结果的可视化图;
图4为实施例中不同分块数量在market-1501上的对比示意图。
图中,rank-1表示第一匹配率精度,map表示平均率均值,part表示特征图分块的数量。
具体实施方式
下面结合附图和实施例对本发明的内容作进一步的阐述,但不是对本发明的限定。
实施例1:
一种基于批次分块遮挡网络的行人再辨识方法,包括如下步骤:
1)分集:将已知的行人再辨识数据集market-1501和dukemtmc-reid中的图像分为训练数据集和测试数据集,market-1501和dukemtmc-reid是两个大规模的行人再识别领域通用的数据集,market-1501数据集包含从6个摄像机视点观察到的1501个身份,包含751人的12936幅由dpm检测到的训练图像和750人的19732幅测试图像;dukemtmc-reid数据集包含702人的16522幅训练图像,702人的17661测试图像,它们共对应1404个不同的人,图片尺寸大小不一,因此本例训练数据集包括29458张图像,测试数据集包括37393张图像;
2)预处理:将训练数据集和测试数据集中的所有图像进行统一尺寸裁剪,本例尺寸剪裁为384×128,将完成裁剪后的训练数据集图像顺序打乱,测试数据集中的图像不做其余处理,为需要辨识的每个行人在训练数据集中随机选择k张图像,组成小训练批,其中k=32或64,本例k=64;
3)预训练:利用训练数据集对resnet-50网络进行预训练,初始化resnet-50网络中的参数,对输入的行人图像进行特征提取,如图1所示,预训练的步骤如下:
3-1)将步骤2)中完成裁剪的训练数据集图像输入到resnet-50网络中,训练数据集图像首先经过resnet-50网络中一个步长为2的7×7卷积和一个池化层,使得输出图像尺寸仅为输入图像尺寸的1/4,得到尺寸大小为96×32的特征图1;
3-2)将特征图1输入resnet-50网络的第一卷积层,经过3个步长为1且内核大小为1×1的残差模块,输出尺寸大小为96×32的特征图2;
3-3)将特征图2输入resnet-50网络的第二卷积层,经过4个步长为1且内核大小为3×3的残差模块,特征图2尺寸大小变成原来的1/2,输出尺寸大小为48×16的特征图3;
3-4)将特征图3输入resnet-50网络的第三卷积层,经过6个步长为1且内核大小为3×3的残差模块,特征图3尺寸大小变成原来的1/2,输出24×8的特征图4;
3-5)将特征图4输入resnet-50网络的第四卷积层,微调resnet-50的网络结构,即在resnet-50网络的第四卷积层不使用下采样操作,所以经第四卷积层后特征图4大小不变,经过4个步长为1且内核大小为3×3的残差模块,输出尺寸大小为24×8特征图5;
4)输入:resnet-50网络第四卷积层之后称为全局分支,将步骤3-5)中1/2数量的特征图5作为全局分支的输入,依次经过1×1卷积层、批处理归一化层和relu层得到特征图s;
5)构建批次分块遮挡模块:构建的批次分块遮挡模块由两个包含不同擦除模块的part1分支和part2分支组成,如图2所示,part1分支中的批量擦除层会随机擦除张量中的同一区域,将擦除区域内所有位置的值都归为0;part2分支则会先将输入的特征图均分成上下两块,然后在每一块中随机地遮挡一小块,即将遮挡区域内的所有值设为0,以步骤3-5)中另外1/2数量的特征图5作为批次分块特征遮挡模块的输入,然后利用全局最大池化得到2048维的特征向量,最后利用三元组损失和softmax损失将特征向量的维度从2048维降到1024维,设单批输入图像经part1分支在特征图上应用擦除处理后计算得到的特征图为t,设经part2分支在特征图上应用擦除处理后得到的特征图为t';
6)构建批次分块遮挡网络模型:在步骤3)的resnet-50网络的第四卷积层后添加一个批次分块遮挡模块,即完成批次分块遮挡网络模型的构建,本例批次分块遮挡网络模型即为行人再辨识网络模型;
7)训练行人再辨识网络模型:使用步骤4)的特征图s、步骤5)中的特征图t和特征图t'通过三元组损失和softmax损失函数对步骤6)中的批次分块遮挡网络模型进行优化,本例优化过程即为循环执行步骤7),直至损失值收敛;
softmax损失函数表示如下:
其中,b表示小训练批次样本数量,
三元组损失函数表示如下:
其中,
8)计算总训练损失:采用三元组损失函数和softmax损失函数计算总训练损失,总训练损失为三元组损失函数和softmax损失函数在全局分支和批次分块遮挡分支上的总和;
总训练损失表达式如下:
l=lg+λ1l1+λ2l2,
其中,lg表示全局分支上的损失,l1和l2分别代表特征删除分支上part1分支和part2分支的损失,λ1和λ2为控制part1分支和part2分支的权重,λ1和λ2均设置为1;
9)测试:将测试数据集输入到步骤7)训练后的行人再辨识网络模型中,行人再辨识网络模型读取测试数据集中的图像后,输出辨识结果,通过比较输出辨识结果与输入图像标签的泛化误差,来验证行人再辨识网络模型的训练效果和性能;
10)比较特征距离:从实时采集的视频中筛选出所有的行人图像组成候选库,并将候选库中的图像和待查询行人图像全部送入到批次分块遮挡网络模型中进行辨识分类,并比较它们之间的特征距离;
特征距离采用欧氏距离表示:
其中,x表示侯选库图像,y表示待查询行人图像,x1表示侯选库图像像素点的横坐标,x2表示侯选库图像像素点的纵坐标,y1表示待查询行人图像像素点的横坐标,y2表示待查询行人图像像素点的纵坐标;
11)完成再辨识:按照特征距离从小到大的顺序对实时采集的视频中筛选出所有的行人图像进行排序,排序从前到后相似性依次减小,即排位第一的训练图像是与待查询行人图像为同一行人的图像,找出指定对象的所有行人图像,从而完成行人再辨识,如图3所示。
实施例2:
步骤2)中k=32,其余步骤同实施例1。
下面使用实施例1的方法与现有方法进行性能比较,比较结果如下:
表1.本例方法与现有的行人再辨识方法的效果对比
表2.全局分支和特征删除分支在market-1501上的数据对比
其中,baseline包含全局分支,bdb包含全局分支+part1分支,本例方法包含全局分支+part1分支+part2分支。
由实验结果可以看出,本例方法有效的提高了网络的识别精度。
将实施例1与实施例2在market-1501上进行实验结果比较,如图4所示,当part=1时,遮挡模块学习特征是全局的,当part开始增加时,提高了检索的准确性,由图4行可知,检索的准确性并不总是随着part的增加而增加,当part增加到4部分以上时,无论是rank-1还是map都开始表现出轻微的下降,过度增加的part实际上损害了部分特征的鉴别能力,故在实际应用中,建议采用part=2,k=64的训练方式。
- 还没有人留言评论。精彩留言会获得点赞!