题目数字化处理方法和可读存储介质与流程
本发明涉及电子教学
技术领域:
,具体而言,涉及一种题目数字化处理方法,一种计算机可读存储介质。
背景技术:
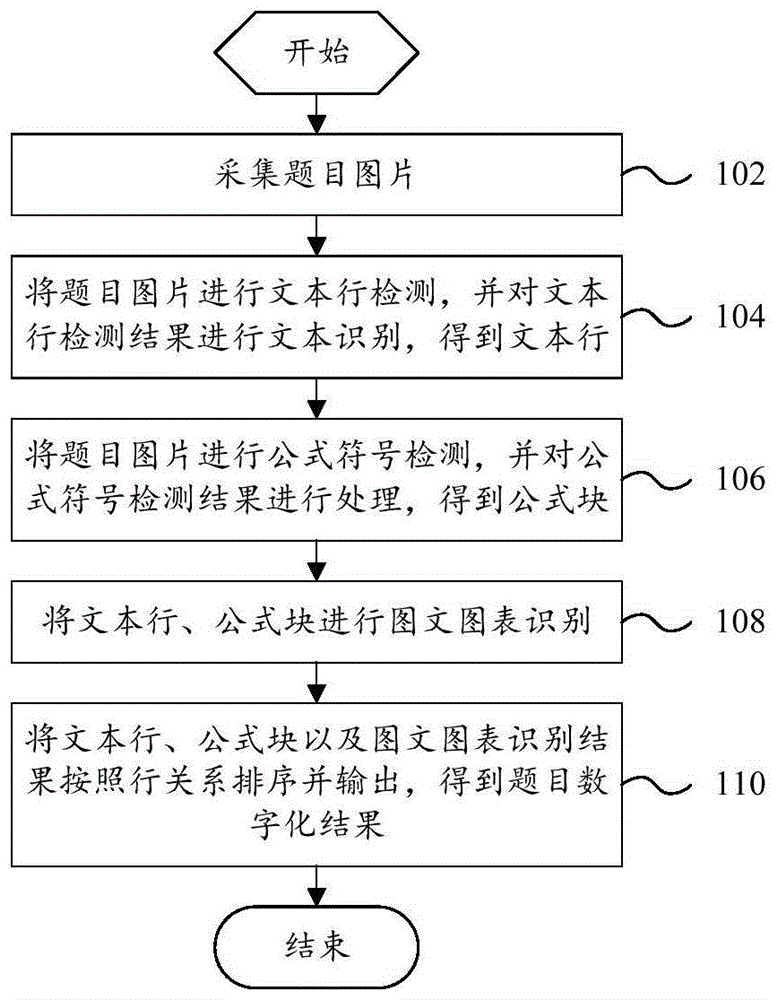
:随着互联网的发展,电子化教学越来越普及。电子化教学是使用现代化的设备、器材,通过对信息的储存、传输、调解和再现技术所进行的教学。相对于使用纸质书籍、黑板以及挂图等传统的教学模式,电子化教学能集图片,视频,音频,互动为一体,更加形象生动地进行知识的讲授,让学生能更快的掌握。老师制作电子教案时,往往需要搜集大量的试卷、题目、资料等纸质素材,要把纸质素材转为电子素材需要耗费老师的大量时间。技术实现要素:本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。为此,本发明的一个方面在于提出了一种题目数字化处理方法。本发明的另一个方面在于提出了一种计算机可读存储介质。有鉴于此,根据本发明的一个方面,提出了一种题目数字化处理方法,包括:采集题目图片;将题目图片进行文本行检测,并对文本行检测结果进行文本识别,得到文本行;将题目图片进行公式符号检测,并对公式符号检测结果进行处理,得到公式块;将文本行、公式块进行图文图表识别;将文本行、公式块以及图文图表识别结果按照行关系排序并输出,得到题目数字化结果。本发明提供的题目数字化处理方法,首先采集题目图片,通过拍照或者扫描的方式获得图片。然后对题目图片进行文本行检测,以及公式符号检测;通过文本行检测,实现文本行定位,对于检测到的文本行进行文本识别,从而得到文本行;对于公式符号检测结果进行公式逻辑处理,从而得到公式块;其中文本行检测与公式符号检测的执行顺序不分先后。然后对文本行以及公式块进行图文图表识别,从而得到图文图表识别结果,也就是题目中的除公式以及文本以外的图文图表。最后将文本行、公式块以及图文图表识别结果按照行关系排序,并输出结果,文本行输出为“文本”,公式块输出为“公式图片”,图文图表输出为“图文图表图片”,从而得到最终的数字化题目。通过本发明提供的题目数字化处理方法,对题目图片的识别抗干扰能力强,题目数字化处理的准确率更高,并且处理速度快,使用方便,提高了学习效率,并为教师节省大量时间,客户体验度高。根据本发明的上述题目数字化处理方法,还可以具有以下技术特征:在上述技术方案中,将文本行、公式块进行图文图表识别的步骤,具体包括:将文本行、公式块对应的图片区域进行空白化处理;空白化处理完成后,获取图片区域的连通域,并确定连通域对应的矩形框;基于矩形框的尺寸大于预设尺寸,且矩形框的坐标符合预设要求,则认定矩形框为图文图表。在该技术方案中,首先将文本行对应的图片区域进行空白化处理,以及将公式块对应的图片区域进行空白化处理,空白化处理后,获取图片区域的连通域,并确定该连通域对应的矩形框,当矩形框的尺寸大于预设尺寸,并且矩形框的坐标符合预设要求时,该矩形框即可认定为图文图表。其中,预设尺寸以及预设要求,可根据矩形框处于题目图片中的位置、以及矩形框与文本行的位置关系进行确定。通过本发明的技术方案,能够在文本识别、公式识别的基础上,对题目中的图文图表进行准确识别,从而得到数字化题目。在上述任一技术方案中,将文本行、公式块,以及图文图表识别结果按照行关系排序的步骤,具体包括:分别确定文本行、公式块,以及图文图表识别结果对应的矩形框的中心点坐标和横坐标;将文本行、公式块,以及图文图表识别结果按照矩形框的中心点坐标进行升序排序,得到行结果;将行结果按照矩形框的横坐标进行升序排序。在该技术方案中,对文本行、公式块、以及图文图表先按照各自矩形框的中心点坐标进行升序排序,得到行结果,再对行结果按照矩形框的横轴坐标进行升序排序,输出结果:文本行为“文本”,公式块为“公式图片”,图文图标识别结果为“图文图表图片”,得到最终的数字化题目。通过本发明的技术方案,能够对文本识别结果、公式识别结果以及图文图表识别结果按序排列别输出,从而得到题目的数字化处理结果。在上述任一技术方案中,将文本行、公式块对应的图片区域进行空白化处理的步骤,具体包括:将文本行、公式块对应的图片区域的像素值置为255。在该技术方案中,将检测识别到的文本行对应的图片区域的像素值置为255,将检测识别的公式块对应的图片区域的像素值置为255。在上述任一技术方案中,获取图片区域的连通域的步骤,具体包括:对图片区域按序进行灰度化、二值化,以及膨胀化处理;获取连通的区域,以及连通的区域的外轮廓,得到连通域。在该技术方案中,先对图片区域进行灰度化,再二值化,再做膨胀处理,然后取连通的区域,再取其外轮廓,即得到连通域,连通域的最大外接矩形框即为连通域对应的矩形框。在上述任一技术方案中,将题目图片进行文本行检测的步骤,具体包括:构建文本行检测模型;获取第一组互联网题目图片,对第一组互联网题目图片中的文本行的坐标进行标注;将标注好的数据划分为训练集与验证集;根据训练集对文本行检测模型进行训练,并采用验证集对训练结果进行验证;基于文本行检测模型的训练损失值小于第一预设阈值且收敛,得到训练好的文本行检测模型;根据训练好的文本行检测模型对题目图片进行文本行检测。在该技术方案中,首先搭建文本行检测模型;其次进行数据标注,具体而言,从互联网爬取一组题目图片,如10万份题目图片,对题目图片的文本行的坐标进行标注,标注结果如:(67,43,394,68)、(67,79,182,103)等;然后对文本行检测模型进行训练,具体而言,将标注好的数据按照一定比例(如9:1)划分为训练集和验证集,基于训练集对文本行检测模型进行训练,基于验证集对训练结果进行验证,从而确定出训练损失值,基于训练损失值小于第一预设阈值,且收敛了,最终得到训练好的文本行检测模型。其中,在对文本行检测模型进行训练之前,对题目图片进行增强,比如:增加对比度、减少对比度、添加随机噪点等,以获得更好的训练模型。通过本发明的技术方案,进行文本检测及识别,对复杂图像的识别抗干扰能力强,从而能够更加准确地将题目数字化。在上述任一技术方案中,将题目图片进行公式符号检测的步骤,具体包括:构建公式符号检测模型;获取第二组互联网题目图片,对第二组互联网题目图片中的公式符号的坐标及对应的类别进行标注;将标注好的数据划分为训练集与验证集;根据训练集对公式符号检测模型进行训练,并采用验证集对训练结果进行验证;基于公式符号检测模型的训练损失值小于第二预设阈值且收敛,得到训练好的公式符号检测模型;根据训练好的公式符号检测模型对题目图片进行公式符号检测。在该技术方案中,首先搭建公式符号检测模型;其次进行数据标注,具体而言,从互联网爬取一组题目图片,如2万份题目图片,标记出题目图片中公式符号的坐标及对应的类别,如公式符号为分数线,其标签为“frac”,根据该分数线在题目中的位置,标注结果如:343,230,355,237,frac。然后对公式符号检测模型进行训练,具体而言,将标注好的数据按照一定比例(如9:1)划分为训练集和验证集,基于训练集对公式符号检测模型进行训练,基于验证集对训练结果进行验证,从而确定出训练损失值,基于训练损失值小于第二预设阈值,且收敛了,最终得到训练好的公式符号检测模型。其中,在对公式符号检测模型进行训练之前,对题目图片进行增强,比如:增加对比度、减少对比度、添加随机噪点等,以获得更好的训练模型。通过本发明的技术方案,进行公式检测,准确率更高。在上述任一技术方案中,公式符号包括以下任一项或其组合:分数线、根号、大括号、小括号、绝对值符号、极限符号、求和符号、积分符号。在该技术方案中,公式符号包括但不限于以下任一项或其组合:分数线、根号、大括号、小括号、绝对值符号、极限符号、求和符号、积分符号。可以理解地,只要是教学中涉及的公式的符号,都是可以标注、检测以及通过对检测结果进行公式逻辑处理而得到公式图片。在上述任一技术方案中,文本行检测模型为ctpn场景文字检测模型;公式符号检测模型包括以下任一项:fpn特征金字塔网络,ssd单镜头多盒检测器,yolo模型,centernet模型,efficientdet模型,fasterr-cnn模型。在该技术方案中,文本行检测模型为ctpn场景文字检测模型,但不限于此;公式符号检测模型包括但不限于以下任一项:fpn特征金字塔网络,ssd单镜头多盒检测器,yolo模型,centernet模型,efficientdet模型,fasterr-cnn模型。根据本发明的另一个方面,提出了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如上述任一技术方案的题目数字化处理方法。本发明提供的计算机可读存储介质,计算机程序被处理器执行时实现如上述任一技术方案所述的题目数字化处理方法的步骤,因此该计算机可读存储介质包括上述任一技术方案所述的题目数字化处理方法的全部有益效果。本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。附图说明本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:图1示出了本发明的一个实施例的题目数字化处理方法的流程示意图;图2示出了本发明的另一个实施例的题目数字化处理方法的流程示意图;图3示出了本发明的再一个实施例的题目数字化处理方法的流程示意图;图4示出了本发明的实施例的将题目图片进行文本行检测的方法的流程示意图;图5示出了本发明的实施例的将题目图片进行公式符号检测的方法的流程示意图;图6示出了本发明的一个实施例的一张题目图片;图7示出了本发明的另一个实施例的一张题目图片;图8示出了本发明的又一个实施例的题目数字化处理方法的流程示意图。具体实施方式为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不限于下面公开的具体实施例的限制。本发明第一方面的实施例,提出一种题目数字化处理方法。图1示出了本发明的一个实施例的题目数字化处理方法的流程示意图。其中,该题目数字化处理方法,包括:步骤102,采集题目图片;步骤104,将题目图片进行文本行检测,并对文本行检测结果进行文本识别,得到文本行;步骤106,将题目图片进行公式符号检测,并对公式符号检测结果进行处理,得到公式块;步骤108,将文本行、公式块进行图文图表识别;步骤110,将文本行、公式块以及图文图表识别结果按照行关系排序并输出,得到题目数字化结果。本发明实施例提供的题目数字化处理方法,首先采集题目图片,通过拍照或者扫描的方式获得图片。然后对题目图片进行文本行检测,以及公式符号检测;通过文本行检测,实现文本行定位,对于检测到的文本行进行文本识别,从而得到文本行;对于公式符号检测结果进行公式逻辑处理,从而得到公式块;其中文本行检测与公式符号检测的执行顺序不分先后。然后对文本行以及公式块进行图文图表识别,从而得到图文图表识别结果,也就是题目中的除公式以及文本以外的图文图表。最后将文本行、公式块以及图文图表识别结果按照行关系排序,并输出结果,文本行输出为“文本”,公式块输出为“公式图片”,图文图表输出为“图文图表图片”,从而得到最终的数字化题目。通过本发明实施例提供的题目数字化处理方法,对题目图片的识别抗干扰能力强,题目数字化处理的准确率更高,并且处理速度快,使用方便,提高了学习效率,并为教师节省大量时间,客户体验度高。在该实施例中,步骤104与步骤106可以互换顺序。图2示出了本发明的另一个实施例的题目数字化处理方法的流程示意图。其中,该题目数字化处理方法,包括:步骤202,采集题目图片;步骤204,将题目图片进行文本行检测,并对文本行检测结果进行文本识别,得到文本行;步骤206,将题目图片进行公式符号检测,并对公式符号检测结果进行处理,得到公式块;步骤208,将文本行、公式块对应的图片区域进行空白化处理;空白化处理完成后,获取图片区域的连通域,并确定连通域对应的矩形框;基于矩形框的尺寸大于预设尺寸,且矩形框的坐标符合预设要求,则认定矩形框为图文图表;步骤210,将文本行、公式块以及图文图表识别结果按照行关系排序并输出,得到题目数字化结果。在该实施例中,首先将文本行对应的图片区域进行空白化处理,以及将公式块对应的图片区域进行空白化处理,空白化处理后,获取图片区域的连通域,并确定该连通域对应的矩形框,当矩形框的尺寸大于预设尺寸,并且矩形框的坐标符合预设要求时,该矩形框即可认定为图文图表。其中,预设尺寸以及预设要求,可根据矩形框处于题目图片中的位置、以及矩形框与文本行的位置关系进行确定。通过本发明的实施例,能够在文本识别、公式识别的基础上,对题目中的图文图表进行准确识别,从而得到数字化题目。图3示出了本发明的再一个实施例的题目数字化处理方法的流程示意图。其中,该题目数字化处理方法,包括:步骤303,采集题目图片;步骤304,将题目图片进行文本行检测,并对文本行检测结果进行文本识别,得到文本行;步骤306,将题目图片进行公式符号检测,并对公式符号检测结果进行处理,得到公式块;步骤308,将文本行、公式块对应的图片区域进行空白化处理;空白化处理完成后,获取图片区域的连通域,并确定连通域对应的矩形框;基于矩形框的尺寸大于预设尺寸,且矩形框的坐标符合预设要求,则认定矩形框为图文图表;步骤310,分别确定文本行、公式块以及图文图表识别结果对应的矩形框的中心点坐标和横坐标;将文本行、公式块,以及图文图表识别结果按照矩形框的中心点坐标进行升序排序,得到行结果;将行结果按照矩形框的横坐标进行升序排序,输出结果,得到题目数字化结果。在该实施例中,对文本行、公式块、以及图文图表先按照各自矩形框的中心点坐标进行升序排序,得到行结果,再对行结果按照矩形框的横轴坐标进行升序排序,输出结果:文本行为“文本”,公式块为“公式图片”,图文图标识别结果为“图文图表图片”,得到最终的数字化题目。通过本发明的实施例,能够对文本识别结果、公式识别结果以及图文图表识别结果按序排列别输出,从而得到题目的数字化处理结果。在上述任一实施例中,将文本行、公式块对应的图片区域进行空白化处理的步骤,具体包括:将文本行、公式块对应的图片区域的像素值置为255。在该实施例中,将检测识别到的文本行对应的图片区域的像素值置为255,将检测识别的公式块对应的图片区域的像素值置为255。在上述任一实施例中,获取图片区域的连通域的步骤,具体包括:对图片区域按序进行灰度化、二值化,以及膨胀化处理;获取连通的区域,以及连通的区域的外轮廓,得到连通域。在该实施例中,先对图片区域进行灰度化,再二值化,再做膨胀处理,然后取连通的区域,再取其外轮廓,即得到连通域,连通域的最大外接矩形框即为连通域对应的矩形框。图4示出了本发明的实施例的将题目图片进行文本行检测的方法的流程示意图。其中,该方法,包括:步骤402,构建文本行检测模型;步骤404,获取第一组互联网题目图片,对第一组互联网题目图片中的文本行的坐标进行标注;步骤406,将标注好的数据划分为训练集与验证集;步骤408,根据训练集对文本行检测模型进行训练,并采用验证集对训练结果进行验证;步骤410,基于文本行检测模型的训练损失值小于第一预设阈值且收敛,得到训练好的文本行检测模型;步骤412,根据训练好的文本行检测模型对题目图片进行文本行检测。在该实施例中,首先搭建文本行检测模型;其次进行数据标注,具体而言,从互联网爬取一组题目图片,如10万份题目图片,对题目图片的文本行的坐标进行标注,标注结果如:(67,43,394,68)、(67,79,182,103)等;然后对文本行检测模型进行训练,具体而言,将标注好的数据按照一定比例(如9:1)划分为训练集和验证集,设置模型训练轮数,如epochs=100000,基于训练集对文本行检测模型进行训练,基于验证集对训练结果进行验证,从而确定出训练loss值(训练损失值),基于训练loss值小于第一预设阈值,如训练loss值下降到0.02以下,且收敛了,则得到训练好的文本行检测模型。其中,在对文本行检测模型进行训练之前,对题目图片进行增强,比如:增加对比度、减少对比度、添加随机噪点等,以获得更好的训练模型。通过本发明的实施例,进行文本检测及识别,对复杂图像的识别抗干扰能力强,从而能够更加准确地将题目数字化。在本发明的一个实施例中,对图6所示的互联网题目图片中的文本进行标注的结果为:(67,43,394,68)、(67,79,182,103)。图5示出了本发明的实施例的将题目图片进行公式符号检测的方法的流程示意图。其中,该方法,包括:步骤502,构建公式符号检测模型;步骤504,获取第二组互联网题目图片,对第二组互联网题目图片中的公式符号的坐标及对应的类别进行标注;步骤506,将标注好的数据划分为训练集与验证集;步骤508,根据训练集对公式符号检测模型进行训练,并采用验证集对训练结果进行验证;步骤510,基于公式符号检测模型的训练损失值小于第二预设阈值且收敛,得到训练好的公式符号检测模型;步骤512,根据训练好的公式符号检测模型对题目图片进行公式符号检测。在该实施例中,首先搭建公式符号检测模型;其次进行数据标注,具体而言,从互联网爬取一组题目图片,如2万份题目图片,标记出题目图片中公式符号的坐标及对应的类别,如公式符号为分数线,其标签为“frac”,根据该分数线在题目中的位置,标注结果如:343,230,355,237,frac。然后对公式符号检测模型进行训练,具体而言,将标注好的数据按照一定比例(如9:1)划分为训练集和验证集,设置模型训练轮数,如epochs=200000,基于训练集对公式符号检测模型进行训练,基于验证集对训练结果进行验证,从而确定出训练loss值,基于训练loss值小于第二预设阈值,如训练loss值下降到0.01以下,且收敛了,则得到训练好的公式符号检测模型。其中,在对公式符号检测模型进行训练之前,对题目图片进行增强,比如:增加对比度、减少对比度、添加随机噪点等,以获得更好的训练模型。通过本发明的实施例,进行公式检测,准确率更高。在上述任一实施例中,公式符号包括以下任一项或其组合:分数线、根号、大括号、小括号、绝对值符号、极限符号、求和符号、积分符号。在该实施例中,公式符号包括但不限于以下任一项或其组合:分数线、根号、大括号、小括号、绝对值符号、极限符号、求和符号、积分符号。可以理解地,只要是教学中涉及的公式的符号,都是可以标注、检测以及通过对检测结果进行公式逻辑处理而得到公式图片。在本发明的一个实施例中,公式符号的类别定义如下表所示,需要说明的是,该表仅列出部分公式符号的类别定义。公式符号的类别定义表名称标签分数线frac根号sqrt大括号brace_big小括号brace_small绝对值符号abs_line极限符号limit求和符号sum积分符号integral......在本发明的一个实施例中,对图7所示的互联网题目图片中的公式符号进行标注的结果为:343,230,355,237,frac;129,269,189,295,sqrt;208,39,214,58,brace_small;96,38,121,56,limit。其中,公式逻辑处理,规则如下:1、若检测公式符号为frac,先用连通域方法得到分子,若成功再用连通域方法得到分母,将frac、分子、分母的矩形框坐标合并为大的矩形框,最终得到分数的检测坐标;2、若检测公式符号为abs_line,同时右边在设定的阈值内也有一个abs_line,则把二者合并成大的矩形框,最终得到绝对值的检测坐标;3、若检测公式符号为brace_big,同时右边存在高度大于设定的阈值的连通域,则将二者合并为大的矩形框,最终得到方程组的检测坐标;4、若检测公式符号为brace_samll,且高度大于设定的阈值,同时右边在设定的阈值内也有一个brace_samll,高度与前者一致,则把二者合并成大的矩形框,最终得到矩阵的检测坐标;5、若检测公式符号为sum,且在其右边存在连通域,则把二者合并成大的矩形框,最终得到求和的检测坐标;6、若检测公式符号为limit,且在其右边存在连通域,则把二者合并成大的矩形框,最终得到求极限的检测坐标;7、若检测公式符号为integral,且在其右边存在连通域,则把二者合并成大的矩形框,最终得到求积分的检测坐标。在上述任一实施例中,文本行检测模型为ctpn场景文字检测模型;公式符号检测模型包括以下任一项:fpn特征金字塔网络,ssd单镜头多盒检测器,yolo模型,centernet模型,efficientdet模型,fasterr-cnn模型。在该实施例中,文本行检测模型为ctpn场景文字检测模型,但不限于此;公式符号检测模型包括但不限于以下任一项:fpn特征金字塔网络,ssd单镜头多盒检测器,yolo模型,centernet模型,efficientdet模型,fasterr-cnn模型。图8示出了本发明的又一个实施例的题目数字化处理方法的流程示意图。其中,该题目数字化处理方法,包括:步骤602,采集图片;步骤604,使用预训练的ctpn文本行检测模型对图片进行文本行检测,再使用预训练的ocr光学字符识别模型对文本行进行文本识别,得到文本;步骤606,使用预训练的fpn公式符号检测模型对图片进行公式符号检测,再对检测结果进行公式逻辑处理,得到公式块;步骤608,对文本和公式块对应的图片区域进行空白化,再对空白化后的图片使用连通域方法进行图文图表识别;步骤610,将文本、公式块、图文图表识别结果按照行关系排序,输出结果。其中,连通域方法:先对图片进行灰度化,再二值化,再膨胀处理,取连通的区域,再取外轮廓,即为连通域,其最大外接矩形框即为其矩形框坐标。其中,图文图表识别:1、先将图片空白化处理:将检测到的文本行对应的图片区域的像素值置为255,将公式符号检测到的公式区域的像素值置为255;2、将空白化后的图片使用连通域方法得到候选的矩形框;3、矩形框的大小大于预设阈值,且坐标位置符合预设要求的,该矩形框即可认定为图文图表。其中,输出结果按照行关系排序:对文本行、公式、图文图表先按照矩形框的中心点坐标进行升序排序,得到行结果,再对行结果中矩形框的横轴坐标进行升序排序,得到最终的结果。输出结果:文本行为“文本”,公式为“公式图片”,图文图表为“图文图表图片”。其中,步骤604、步骤606可以互换顺序。通过本发明实施例提供的题目数字化处理方法,对题目图片的识别抗干扰能力强,题目数字化处理的准确率更高,并且处理速度快,使用方便,提高了学习效率,并为教师节省大量时间,客户体验度高。根据本发明的另一个方面实施例,提出了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如上述任一实施例的题目数字化处理方法。本发明实施例提供的计算机可读存储介质,计算机程序被处理器执行时实现如上述任一实施例所述的题目数字化处理方法的步骤,因此该计算机可读存储介质包括上述任一实施例所述的题目数字化处理方法的全部有益效果。在本说明书的描述中,术语“第一”、“第二”仅用于描述的目的,而不能理解为指示或暗示相对重要性,除非另有明确的规定和限定;术语“连接”、“安装”、“固定”等均应做广义理解,例如,“连接”可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1