一种毛竹胸径年龄联合分布动态模型的构建方法与流程
本发明涉及一种区域森林生物量估算动态模型的构建方法,特别是一种毛竹胸径年龄联合分布动态模型的构建方法。
背景技术:
毛竹是我国南方重要的一种森林类型,也是最重要、最典型的竹林资源类型,我国是竹林资源最丰富的国家之一,根据第8次全国森林资源连续清查结果,我国的竹林面积为600万hm2,是毛竹主产国,毛竹林面积为443万hm2,其面积占全国竹林面积的70%左右。
毛竹具有经济效益高、固碳功能强、一次造林可持续利用及择伐作业不破坏林相等经营优势(周国模,2004;陈双林,2004),近年来,随着全球气候变暖及产业结构的调整与加工技术的不断提高,一些地区大力发展毛竹产业,由于许多地方缺乏经营理论的指导与片面追求经济效益,使很多地方毛竹林分生产力与固碳功能出现衰退。
毛竹胸径年龄的二元概率分布对区域毛竹固碳量精确估算及现代毛竹经营活动起着非常重要的作用,它可以精确预估毛竹各径阶、各龄阶株数与生长量测定、产量预估、枯损量计算等,还对毛竹林的科学经营提供理论依据,故毛竹胸径年龄的二元概率分布的研究意义重大。
到目前为止,有关测树因子二元概率分布的研究已有不少(金星姬,2013;lietal.,2002;wangandrennolls,2007;hafleyetal.,1976;h.t.schreuderetal.,1977;fashengli,2002;mingliangwang,2007;emesgenetal.,2003;葛宏立,2008;刘恩斌,2010),但存在如下缺陷:
1)由于建模数据基本是测树因子的某期数据,因此不能建立联合概率分布函数参数与时间t的关系,故已报道的测树因子二元概率分布模型大多是静态模型,不能预测测树因子未来的联合分布(密度)值;
2)已有二元概率分布函数参数较多,如二元sbb函数有9个参数、估计精度较低的二元beta函数有3参数与5参数两种形式(刘恩斌,2010)、二元weibull分布函数有7个参数等,因此建立分布函数参数与时间t的函数关系需要很多期的数据,很难实现;
3)测树因子边缘分布(密度)值较容易获得,而其联合分布(密度)值较边缘分布(密度)值提供的信息更多更全面,有更高的实用价值,因此对区域森林生物量、树木各径阶、各龄阶株数与生长量等的估算精度更高,但已知测树因子边缘分布(密度)值,用常用二元分布(密度)函数不能得到联合分布(密度)值;
4)常用二元分布函数拟合参数时需要测树因子联合分布(密度)值,而测树因子的联合分布(密度)值比较难获得,如要研究某地某年份毛竹胸径年龄的二元联合分布,但从已有的数据资料,能获得每个样地各个径阶与各个龄级的毛竹分别有多少株,无法获得每个样地中的每一株毛竹的胸径与年龄数据,即只能得到某地毛竹胸径与年龄的边缘分布值,无法得到毛竹胸径与年龄的联合分布值,再如要研究某区域尺度的马尾松胸径树高联合分布,从各种文献获得满足该区域抽样精度的两套马尾松样本,一套样本只能得到马尾松的胸径分布值,另一套样本能获得其树高分布值,即不能得到马尾松胸径树高的联合分布值,以上两种情况,由于无法获得两测树因子的联合分布值,故不能使用常用二元分布函数构建测树因子的联合分布模型。
测树因子二元联合分布动态模型既可以精确预估某区域未来森林的生物量与生长量,又能反映出该区域测树因子随时间的动态变化趋势,从而为区域森林科学经营与规划提供理论基础,但使构建的测树因子联合分布动态模型有理论与实践意义,至少需要树种一个经营周期的数据,而很多树种由于其生长与经营周期太长,要获得该树种一个经营周期的数据难度非常大,再加之,常用二元分布函数的参数比较多,所以测树因子二元联合分布动态模型的构建很难实现。
毛竹是一种特殊的植物,其林分的经营周期为6年左右,与森林资源连续清查周期相同,且林分中高龄级的毛竹采用皆伐方式,从而为测树因子二元联合分布动态模型的构建提供了一个很好的试验样本,再加之,二元copula函数的参数少,且在建模时的灵活性和适用性方面有着无可比拟的优势,使得毛竹胸径年龄二元联合分布模型的构建成为可能。因此,毛竹胸径年龄联合分布动态模型的构建是目前区域森林生物量估算的一大热门研究方向。
技术实现要素:
本发明的目的在于,提供一种毛竹胸径年龄联合分布动态模型的构建方法。它具有不仅可精确预测区域尺度毛竹生物量,还能反应毛竹胸径年龄的动态变化,为毛竹林的碳交易与科学经营提供理论依据的优点。
本发明的技术方案:一种毛竹胸径年龄联合分布动态模型的构建方法,包括以下步骤:
步骤一,收集研究区域以5年为一个复查周期的3期毛竹连续清查样地数据;
步骤二,将研究区域每期毛竹样地的连续清查数据按株数汇总成毛竹胸径年龄二维统计数据;
步骤三,根据步骤二汇总的各期毛竹林胸径年龄二维统计数据,计算各期数据毛竹胸径的边缘分布值u与年龄的边缘分布值v;
步骤四,以各期数据毛竹胸径与年龄边缘分布值为自变量,采用极大似然法,分别拟合若干种二元copula密度函数,得每期数据的各二元copula密度函数的参数向量βi,j,其中,i为期数,取值为1、2、3,j为第j种二元copula密度函数;
步骤五,根据aic信息准则与确定系数得毛竹各期连续清查数据的胸径年龄最优二元copula密度函数均为二元gumbelcopula密度函数;
步骤六,根据步骤四与步骤五的计算结果,建立二元gumbelcopula密度函数参数β与期数t的线性回归关系,关系式为:
β=1.0926-0.0177t;
步骤七,由最优二元copula密度函数及步骤六的参数β与期数t的线性回归关系,得出毛竹胸径年龄联合分布动态模型为:
前述的一种毛竹胸径年龄联合分布动态模型的构建方法中,所述若干种二元copula函数包括二元正态copula函数、二元t-copula函数、二元claytoncopula函数、二元frankcopula函数及二元gumbelcopula函数。
前述的一种毛竹胸径年龄联合分布动态模型的构建方法中,所述步骤五中aic信息准则计算aic值的计算式为:
式中:d(ui,vi;β)为所选二元copula密度函数;β为所选二元copula函数参数向量;m为所选二元copula密度函数的参数个数;l为所选二元copula密度函数的极大似然函数;n为要拟合的原始数据的样本量,当所选模型为二元gaussiancopula、frankcopula、gumbelcopula、claytoncopula函数时,m等于1,所选模型为二元tcopula函数时,m等于2,ui,vi(i=1,2,…n)分别为原始样本的第i个数据统计得到的胸径与年龄边缘分布值。
前述的一种毛竹胸径年龄联合分布动态模型的构建方法中,所述步骤五中确定系数公式为:
式中yi为因变量的第i个实测值,
与现有技术相比,本发明通过森林资源连续清查体系收集以5年为一个复查周期的若干期森林连续清查数据,符合毛竹由于其特有的生物学特性,使得其经营周期为6年左右,对预测年份毛竹胸径年龄联合分布的预测精准;以二元copula函数作为研究工具,由于其参数只有1个,在已知毛竹胸径与年龄边缘分布值得情况下,能精确估算其联合分布值,既能反映某地毛竹经过3个经营周期后其胸径年龄分布的变化规律,又能精确拟合二元copula函数参数,还能反应出copula函数参数与期数t的变化规律,使得样本选取的科学性得以保证。
本发明的二元copula函数的自变量是胸径与年龄的边缘分布值,因此只需要知道每期数据胸径与年龄的边缘分布即可得到该期数据胸径与年龄的联合分布值,因此满足以下两种情况的样本也可以作为建模样本:1)从样本数据中只能获得各个测树因子的边缘分布值,不能得到测树因子的联合分布值;2)有满足抽样精度的两套样本,一套样本能得出一个测树因子的边缘分布值,另一套样本能得出另一个测树因子的边缘分布值,使得本发明的适用范围更广。
综上,本发明具有不仅可精确预测区域尺度毛竹生物量,还能反应毛竹胸径年龄的动态变化,为毛竹林的碳交易与科学经营提供理论依据的优点。
附图说明
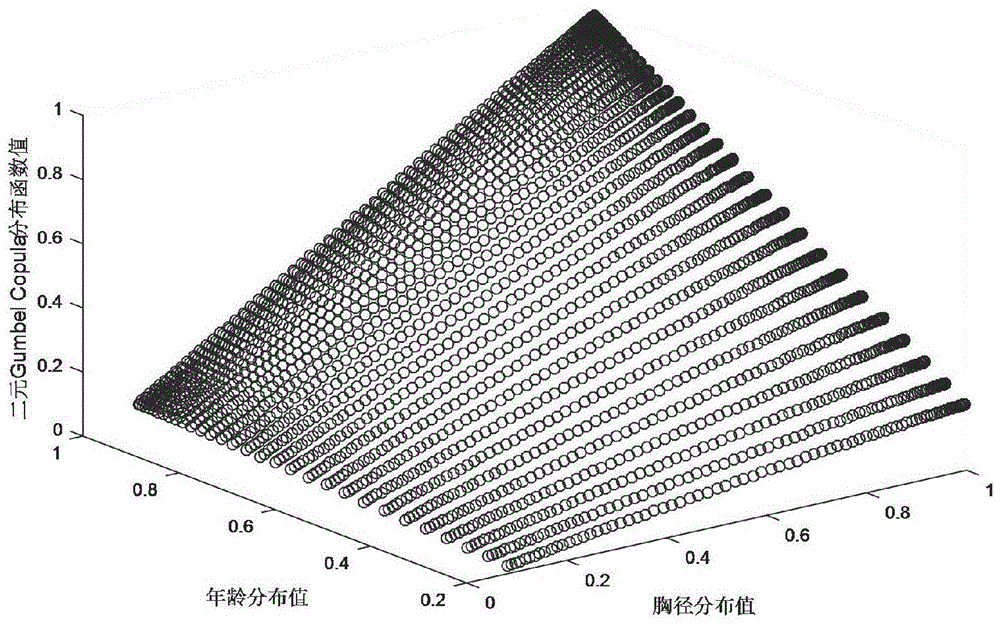
图1是2004年胸径年龄二元gumbelcopula联合分布图;
图2是2004年胸径年龄二元gumbelcopula联合密度图;
图3是2004年胸径年龄联合分布图;
图4是2004年胸径年龄联合密度图;
图5是2009年毛竹胸径年龄二维copula分布函数图;
图6是2009年二维gumbelcopula联合密度图;
图7是2009年毛竹胸径年龄的二元联合分布图;
图8是2009年毛竹胸径年龄的二元联合密度图;
图9是2014年胸径年龄二元gumbelcopula联合分布图;
图10是2014年胸径年龄二元gumbelcopula联合密度图;
图11是2014年胸径年龄联合分布图;
图12是2014年胸径年龄联合密度图;
图13是各期毛竹胸径weibull分布曲线;
图14是各期毛竹年龄weibull分布曲线;
图15是2019年胸径年龄二元gumbelcopula联合分布图;
图16是2019年胸径年龄二元gumbelcopula联合密度图;
图17是2019年胸径年龄联合分布图;
图18是2019年胸径年龄联合密度图。
具体实施方式
下面结合附图和实施例对本发明作进一步的说明,但并不作为对本发明限制的依据。
实施例:一种毛竹胸径年龄联合分布动态模型的构建方法,本方法的基本理论与方法:copula函数最早由sklar(1959)提出:将多个一维分布连接成多维分布的函数,同时每个边缘分布必须是均匀分布。
根据定义(nelsen,2006),二维copula函数定义如下:
(1)c(·,·)在每个维度空间的定义域均为[0,1];
(2)c(·,·)有零基面且二维递增的;
(3)对于任意的变量u,v∈[0,1],均满足c(u,1)=u,c(1,v)=v;
同时,对于定义域内的任意一点(u,v),都有0≤c(u,v)≤1。
根据定义可知,copula函数有如下性质:
边界条件:对任意二元变量(u,v)∈[0,1]×[0,1],均满足c(u,0)=0,c(0,v)=0,c(u,1)=u,c(1,v)=v,即只要有一个变量为0,copula函数值就为0,只要有一个变量为1,copula函数值由另一个变量决定。
递增性:copula函数在定义域内严格单调非递减,对于定义域内的变量u1,v1,u2,v2,且u1≤u2,v1≤v2,则c(u2,v2)-c(u2,v1)-c(u1,v2)+c(u1,v1)≥0,即如果u,v∈[0,1]的值同时增大,则copula函数值一定是非减少的,同理如果一个自变量不变,则copula函数值随着另一个变量值的增大而增大或不变。
frechet边界:任一个copula分布都有frechet上界c+(u,v)=max(u+v-1,0)与下界c-(u,v)=min(u,v),即c-(u,v)≤c(u,v)≤c+(u,v)。
sklar定理:令二维随机变量(x,y)的联合分布为h(x,y),边缘分布分别为f(x),g(y),则存在着一个copula函数c,使得:
h(x,y)=c(f(x),g(y))式(1)
若f(x)和g(y)是连续的,则c是唯一的,反过来,对任何概率分布f(x)和g(y)和copula函数c,则h(x,y)一定是一个联合分布函数,其边缘为f(x)和g(y)。
设d(u,v)是copula函数c(u,v)的概率密度函数,式(1)得:
令u=f(x),v=g(y),则
式(3)表明,一个联合概率密度函数h(x,y)拆解成两部分,前一部分d(u,v)为copula密度函数,能精确完整地描述随机变量之间的相关结构,后一部分f(x)g(y)则为边缘概率密度函数的乘积。
常用copula函数有正态copula函数、t-copula函数、阿基米德copula函数,其中gumbelcopula函数、claytoncopula函数、frankcopula函数为最常用的3种阿基米德copula函数(张蕾,2017),因此本发明采用这5种二维copula函数对毛竹胸径年龄的联合密度进行估计。
本发明动态模型的构建具体包括以下步骤:
步骤一,收集研究区域以5年为一个复查周期的3期毛竹连续清查样地数据;
浙江省于1979年建立了森林资源连续清查体系,以5年为一个复查周期。共设置固定样地4250个,样点格网为4km×6km,样地形状为正方形,边长28.28m,面积800m2。本发明利用2004年、2009年与2014年三期的森林连续清查数据,2004年毛竹样地数为249个,2009年清查了全省2/3的固定样地及其它样地(数量为固定样地的1/3、大小与固定样地相同),在2009年所有调查样地中基本属于毛竹纯林的样地数为176,2014年毛竹样地数为304个。2004年毛竹样地的基本情况为:毛竹株数为18~461,毛竹胸径为5~15cm,年龄1~4度以上(当年生竹记为1度竹;2-3a生竹记为2度竹,依此类推)。2009年毛竹样地的基本情况为:株数为22~538,其中有一个样地株数为897,样地毛竹胸径为5~16cm,年龄1~5度及以上。2014年毛竹样地的基本情况为:毛竹株数37~940不等,毛竹胸径为5~15cm,年龄1~5度以上。每期样地的调查因子包括土层厚度、坡向(1:北,2:东北,3:东,4:东南,5:南,6:西南,7:西,8:西北,9:无坡向即山顶)、坡位(1:脊部,2:上部,3:中部,4:下部,5:谷部,6:平地)、坡度、海拔(10m-1200m)、样地平均胸径、样地株数及样地内每株毛竹的胸径与年龄等。
步骤二,将研究区域每期毛竹样地的连续清查数据按株数汇总成毛竹胸径年龄二维统计数据;
步骤三,根据步骤二汇总的各期毛竹林胸径年龄二维统计数据,计算各期数据毛竹胸径的边缘分布值u与年龄的边缘分布值v;
步骤四,以各期数据毛竹胸径与年龄边缘分布值为自变量,采用极大似然法,分别拟合若干种二元copula密度函数,得每期数据的各二元copula密度函数的参数向量βi,j,其中,i为期数,取值为1、2、3,j为第j种二元copula密度函数;
步骤五,根据aic信息准则与确定系数得毛竹各期连续清查数据的胸径年龄最优二元copula密度函数均为二元gumbelcopula密度函数;
各期毛竹胸径年龄密度函数值的推导:
2004年毛竹胸径年龄联合分布估测:
采用aic值进行选取,二元正态copula函数、二元t-copula函数、二元claytoncopula函数、二元frankcopula函数及二元gumbelcopula函数aic值分别为:2.0000、-15.7985、-6.1155、-7.8266与-15.8317,由于二元gumbelcopula函数与二元t-copula函数的aic值相差甚微,为了与后面几期的copula函数相一致,选取二元gumbelcopula函数作为毛竹胸径年龄的最优联合分布函数,应用极大似然法进行拟合,得二元gumbelcopula函数参数为1.0760,此时r2=0.9379,此时,毛竹胸径年龄联合密度的估计值见下表:
表1毛竹胸径年龄联合密度实测值与对应的二元gumbelcopula函数估计值
从表1可以看出,二元gumbelcopula函数对毛竹胸径年龄联合密度的估计精度很高;
由表1得出毛竹胸径与年龄的边缘分布函数值,根据式(1)得出毛竹胸径年龄二维copula分布函数值,由matlab软件绘制毛竹胸径年龄二元gumbelcopula联合分布图如图1所示;
从图1可以看出,毛竹胸径年龄二元gumbelcopula函数分布函数值随着胸径与年龄边缘分布值得增大而增大,符合copula函数的性质,从如下2009年、2014年与2019年的二元gumbelcopula联合分布图也可以看出;
根据式(2),可由毛竹胸径年龄二维copula分布函数值推导出相应的二维copula密度函数值,再根据式(3),可得毛竹胸径年龄二维gumbelcopula密度函数值,由matlab软件绘制相应的图如图2所示;
从图2可以看出,浙江省毛竹胸径与年龄存在上尾相关性,从如下2009年、2014年与2019年的二元gumbelcopula联合密度图也可以看出;
常用胸径年龄二元分布(密度)函数的自变量是胸径与年龄,而胸径年龄二元copula分布(密度)函数的自变量是胸径与年龄的分布值,设d为胸径,a为年龄,u=f(d)为胸径的一元分布函数,v=g(a)为年龄的一元分布函数,则根据反函数d=f-1(u),a=g-1(v)可得对应的胸径与年龄值,由式(1)可得,胸径年龄二元copula联合分布值就是毛竹胸径年经二元联合分布值,与常用分布函数得出的胸径年龄联合分布值对应,这样可用matlab软件绘制毛竹胸径年龄的二元联合分布图,见图3;
根据式(3),由胸径年龄二元copula密度值、胸径的一元密度值与年龄的一元密度值可得胸径年龄二元密度值h(d,a),这样可用matlab软件绘制毛竹胸径年龄的二元联合密度图,见图4。
2009年毛竹胸径年龄联合分布估测:
二维tcopula、二维gumbelcopula概率密度函数的aic值与确定系数分别为-16.7989、-22.0251与0.9676、0.9841,所以二维gumbelcopula概率密度函数描述毛竹胸径年龄二元联合分布最好;
以胸径与年龄的累计分布为自变量,采用极大似然法拟合二维gumbelcopula概率密度函数参数为1.0550,此时毛竹胸径年龄联合密度函数的估计值,见下表2:
表2省域尺度毛竹实测概率及相应二元gumbelcopula概率密度函数的估计值
用2004年绘制胸径年龄二维概率分布(密度)图与二维copula分布(密度)函数图的方法,用matlab软件绘制2009年的联合分布(密度)图;
图5-图8分别为:2009年毛竹胸径年龄二维copula分布函数图、2009年二维gumbelcopula联合密度图、2009年毛竹胸径年龄的二元联合分布图和2009年毛竹胸径年龄的二元联合密度图。
2014年毛竹胸径年龄联合分布估测:
二元正态copula函数、二元t-copula函数、二元claytoncopula函数、二元frankcopula函数及二元gumbelcopula函数aic值分别为:2.0000、-8.4860、1.4953、0.4887、-10.8530,故二元gumbelcopula函数是2014年毛竹胸径年龄二元最优copula函数;
用二元gumbelcopula函数对2014年全省毛竹胸径年龄联合密度进行估计,具体数值见表3,此时copula函数参数为1.0406;
表32014年毛竹胸径年龄联合密度的估计值
用类似的方法做2014年的二元分布(密度)图,图9至图12分别为:2014年胸径年龄二元gumbelcopula联合分布图、2014年胸径年龄二元gumbelcopula联合密度图、2014年胸径年龄联合分布图和2014年胸径年龄联合密度图。
步骤六,根据步骤四与步骤五的计算结果,建立二元gumbelcopula密度函数参数β与期数t的线性回归关系,关系式为:
β=1.0926-0.0177t;
步骤七,由最优二元copula密度函数及步骤六的参数β与期数t的线性回归关系,得出毛竹胸径年龄联合分布动态模型为:
式中t为毛竹连续清查数据期数,t=1表示第1期,依次类推,β为最优二元copula分布函数参数,u,v分别为毛竹胸径与年龄的边缘分布函数值。
所述若干种二元copula函数包括二元正态copula函数、二元t-copula函数、二元claytoncopula函数、二元frankcopula函数及二元gumbelcopula函数。
所述步骤五中aic信息准则计算aic值的计算式为:
式中:d(ui,vi;β)为所选二元copula密度函数;β为所选二元copula函数参数向量;m为所选二元copula密度函数的参数个数;l为所选二元copula密度函数的极大似然函数;n为要拟合的原始数据的样本量,当所选模型为二元gaussiancopula、frankcopula、gumbelcopula、claytoncopula函数时,m等于1,所选模型为二元tcopula函数时,m等于2,ui,vi(i=1,2,…n)分别为原始样本的第i个数据统计得到的胸径与年龄边缘分布值。
所述步骤五中确定系数公式为:
式中yi为因变量的第i个实测值,
利用本发明动态模型对2019年毛竹胸径年龄联合分布进行预测:
具体预测时按如下步骤进行:
a、用3参数weibull概率分布函数分别拟合步骤二所得各期数据毛竹胸径与年龄的边际分布,结果表明拟合精度很高;
b、作步骤a中3期数据的毛竹胸径分布曲线与年龄分布曲线;
c、当t=4时,由步骤六得2019年毛竹胸径年龄二元gumbelcopula函数的参数值为1.0218;
d、根据步骤b中胸径分布曲线与年龄分布曲线的变化趋势,设置2019年毛竹胸径与年龄的weibull分布参数范围,用matlab软件编写程序,当某个胸径累计分布函数与另一个年龄累计分布函数对应的二元gumbelcopula函数的参数为1.0218时,即可得2019年毛竹胸径与年龄累计分布函数;
e、步骤d中得到的2019年毛竹胸径与年龄累计分布函数,即为2019年毛竹胸径年龄二元gumbelcopula函数的自变量,用极大似然法拟合,可得2019年毛竹胸径年龄联合密度值。
2019年毛竹胸径年龄联合分布函数参数及其边缘分布的推算时,设β为二元gumbelcopula分布函数参数,由以上计算得2004年、2009年与2014年毛竹胸径年龄二元gumbelcopula分布函数参数分别为1.0760、1.0550与1.0406,t为期数,并规定2004年对应的期数为1,2009年为2,2014年为3,2019年的期数为4,a与b分别为参数,则用β=a+bt拟合β与t,得参数a与b分别b=-0.0177,a=1.0926,此时r2=0.9890,拟合精度非常高,令t=4,可得2019年毛竹胸径年龄二元gumbelcopula分布函数参数为1.0218。
用weibull分布分别拟合3期数据的胸径与年龄累计分布值,具体见图13与图14,从图13可以看出,当胸径小于12cm时,2004年、2009年、2014年3期毛竹胸径累计分布值逐期依次减小,当胸径大于12cm时,各期胸径累计分布值变化不大,由此可以推出2019年毛竹胸径累计值也具有这种趋势,即2019年毛竹胸径累计分布曲线在2014年胸径累计分布曲线的下面,但具备这个条件的曲线有很多条。从图14可以看出,后期毛竹年龄累计分布曲线在前期的下面,由此可以推出2019年毛竹年龄累计分布曲线在2014年年龄累计分布曲线的下面,具备这个条件的曲线也有很多条。
能精确描述2019年毛竹胸径或年龄累计分布值的曲线,必须满足如下两个条件:1)2019年毛竹胸径或年龄累计分布曲线在2014年胸径或年龄累计分布曲线的下面,2)2019年胸径与年龄累计分布值对应的二元gumbelcopula函数的参数为1.0218,具体确定方法如下:
1)根据2004年、2009年及2014年毛竹胸径与年龄累计分布值,拟合weibull分布函数3参数,weibull分布对3期数据的胸径累计分布与年龄累计分布的拟合精度都非常高,r2都大于0.9870,由此可以判断3期数据的毛竹胸径与年龄累计分布符合weibull分布;2)假设2019年毛竹胸径与年龄累计分布符合weibull分布,根据3期毛竹胸径与年龄的weibull分布参数,设置2019年毛竹胸径与年龄的weibull分布参数范围,用matlab软件编写程序,当某条胸径累计分布曲线与另一条年龄累计分布曲线对应的二元gumbelcopula函数的参数为1.0218时,即可得2019年毛竹胸径与年龄累计分布曲线,此时毛竹胸径与年龄的一元weibull分布函数位置参数、尺度参数、形状参数分别为4.3610、5.4259、2.4972与-0.0034、2.9729、2.1009,具体见图13与图14。
最优copula函数的选取与胸径年龄联合密度的估计,采用aic值进行选取,二元正态copula函数、二元t-copula函数、二元claytoncopula函数、二元frankcopula函数及二元gumbelcopula函数aic值分别为:2.0000、1.6756、2.0000、1.8594、1.6844,由于二元gumbelcopula函数与二元t-copula函数的aic值相差很小,为了与前面几期的copula函数类型相统一,故选二元gumbelcopula函数为2019年毛竹胸径年龄二元最优copula函数,它对2019年毛竹胸径年龄联合密度的估计值见下表4:
表42019年毛竹胸径年龄联合密度的估计值
用类似的方法做2019年的二元分布(密度)图,图15至图18分别为:2019年胸径年龄二元gumbelcopula联合分布图、2019年胸径年龄二元gumbelcopula联合密度图、2019年胸径年龄联合分布图和2019年胸径年龄联合密度图。
毛竹胸径年龄联合分布动态模型不仅可精确预测区域尺度毛竹生物量,还能反应毛竹胸径年龄的动态变化,为毛竹林的碳交易与科学经营提供理论依据,结合本实施例,可得出如下结论:
1)二元gumbelcopula函数由于其参数少,适用范围广,在已知毛竹胸径与年龄边缘分布值得情况下,能精确估算其联合分布值;
2)毛竹由于其特有的生物学特性,使得其经营周期为6年左右,与毛竹连续清查周期相同,故利用2004年、2009年与2014年3期毛竹连续清查数据,可建立毛竹胸径年龄联合分布动态模型,进而对2019年毛竹胸径年龄联合分布(密度)进行了预测;
3)胸径大于5cm小于9cm的毛竹在2004-2019年的4期数据中所占比重依次减少,胸径大于10cm小于15cm的毛竹所占比重依次增加,1度竹在2004-2019年的4期数据中所占比重依次明显减少,4度及以上度竹依次明显增加,2度与3度竹所占比重变化不大;
4)低龄级且小径阶的毛竹在2004-2019年的4期数据中所占比重依次减少,高龄级且大径阶的毛竹则相反;
5)二元gumbelcopula函数得到的相关系数比pearson线性相关系数更能反映浙江省毛竹胸径与年龄的相互关系与裱花趋势。
- 还没有人留言评论。精彩留言会获得点赞!